你是否在开发中遇到过百万级延迟任务堆积导致调度卡顿?传统定时调度框架的性能瓶颈又让你头疼不已?本文将通过深入剖析 Kafka 时间轮的源码底层,为你拆解其实现百万级任务毫秒级调度的核心奥秘,助你彻底掌握这款高性能定时调度工具的设计精髓。
从订单超时取消到消息重试,再到定时缓存失效,在复杂的分布式系统中,延迟任务调度是一个非常普遍且关键的场景。传统基于堆的定时任务调度框架,例如 JDK 自带的 ScheduledThreadPoolExecutor,其增删任务的时间复杂度为 O(log n)。当任务量飙升到百万级别时,性能便会急剧下降。而 Kafka 采用的时间轮算法,通过巧妙的分层设计,将调度操作的时间复杂度成功降到了 O(1),从而成为处理海量延迟任务场景的优先选择方案。
Kafka 的时间轮实现位于 org.apache.kafka.common.utils.Timer 包下,其核心架构由以下几个部分构成:
- TimerTask:延迟任务的抽象类,封装了任务的具体执行逻辑和延迟时间。
- TimerWheel:时间轮的层级结构,每一层都包含固定数量的槽位(Slot),每个槽位内存储一个任务链表。
- TaskQueue:到期任务队列,用于存放已经到期的任务,等待由线程池异步执行。
- 分层时间轮:由多个不同时间刻度(
tickDuration)的 TimerWheel 嵌套组成,用以高效处理不同延迟范围的任务。
在默认配置下,Kafka 的时间轮分为 3 层:
- 第一层:
tickDuration = 1 ms,wheelSize = 500,覆盖 0 ~ 500 ms 的延迟范围。
- 第二层:
tickDuration = 500 ms,wheelSize = 500,覆盖 500 ms ~ 250 s。
- 第三层:
tickDuration = 250 s,wheelSize = 500,覆盖 250 s ~ 125,000 s(约 34 小时)。
这种设计使得短延迟任务能在小刻度的时间轮中被快速调度,而长延迟任务则进入大刻度时间轮,避免了无效的频繁扫描,从而大幅提升了整体的调度效率。
核心源码解析:任务添加流程
任务添加是时间轮工作流程的起点,我们从 Timer 的 add 方法开始看,这是对外的调用入口:
// 源码来自 org.apache.kafka.common.utils.Timer
public void add(TimerTask task) {
long delay = task.delayMs;
// 处理延迟时间为负数的情况,直接视为立即执行
if (delay < 0)
delay = 0;
// 计算任务的过期时间:当前时间 + 延迟时间
long expiration = time.hiResClockMs() + delay;
// 将任务和过期时间封装为 TimerTaskEntry
TimerTaskEntry entry = new TimerTaskEntry(task, expiration);
// 调用内部添加逻辑
add(entry);
}
这个方法的核心逻辑是计算出任务的绝对过期时间,并将其封装为内部数据结构 TimerTaskEntry,然后交由内部的 add 方法处理。
真正的核心逻辑藏在 TimerWheel 的 add 方法中:
// 源码来自 org.apache.kafka.common.utils.TimerWheel
private void add(TimerTaskEntry entry) {
long delay = entry.expirationMs - time.hiResClockMs();
// 如果任务已经过期,直接加入到期队列
if (delay <= 0) {
entry.timerWheel = null;
taskQueue.add(entry);
return;
}
// 计算任务应该放在哪个层级的时间轮
TimerWheel currentWheel = this;
long remainingDelay = delay;
// 关键:寻找合适层级。若当前层能覆盖的时间范围小于剩余延迟,则升级到上一层
while (remainingDelay > currentWheel.wheelSize * currentWheel.tickDurationMs) {
currentWheel = currentWheel.nextWheel;
remainingDelay = delay;
}
// 计算任务在当前时间轮的具体槽位
int slot = (int) ((time.hiResClockMs() + remainingDelay) / currentWheel.tickDurationMs % currentWheel.wheelSize);
// 计算任务的剩余圈数(需要经过多少个完整的轮次才能到期)
int remainingRounds = (int) (remainingDelay / currentWheel.tickDurationMs / currentWheel.wheelSize);
entry.remainingRounds = remainingRounds;
entry.timerWheel = currentWheel;
// 将任务添加到对应槽位的链表中
currentWheel.buckets[slot].add(entry);
}
这段代码揭示了时间轮设计的三个关键点:
- 过期任务预判:在添加时即判断任务是否已过期,若是则直接送入到期队列执行,避免无效的调度开销。
- 层级匹配算法:通过循环向上查找,确保每个任务都被放置在能覆盖其延迟时间的最小粒度的时间轮中,这是保证短延迟任务响应迅速的基础。
- 槽位与剩余圈数:通过取模运算定位槽位,通过除法计算“剩余圈数”,这个“圈数”机制是时间轮能够以
O(1) 复杂度管理长延迟任务的灵魂所在。
时间轮推进与到期任务处理
时间轮的运转依赖于 advanceClock 方法。此方法会被一个后台线程定时调用,每次调用都使时间轮前进一个最小时间刻度(tickDuration),并扫描当前指针所指槽位中的任务。
// 源码来自 org.apache.kafka.common.utils.TimerWheel
public void advanceClock(long timeMs) {
// 计算当前时间对应的槽位索引
int currentTick = (int) (timeMs / tickDurationMs % wheelSize);
int bucketIndex = (currentTick + wheelSize - expiredTicks) % wheelSize;
TimerTaskList bucket = buckets[bucketIndex];
expiredTicks++;
// 遍历当前槽位链表中的所有任务
TimerTaskEntry entry = bucket.head;
while (entry != null) {
TimerTaskEntry next = entry.next;
// 关键步骤:任务剩余圈数减1
entry.remainingRounds--;
// 判断:如果剩余圈数 <= 0,说明任务已到期
if (entry.remainingRounds <= 0) {
// 从当前槽位链表中移除该任务
bucket.remove(entry);
entry.timerWheel = null;
// 加入到期任务队列,等待执行
taskQueue.add(entry);
}
entry = next;
}
}
推进过程的核心逻辑清晰明了:
- 定位当前槽:根据流逝的时间计算出当前应该检查的槽位。
- 更新任务状态:遍历该槽位链表中的每一个任务,将其“剩余圈数”减 1。
- 触发到期逻辑:若某个任务的“剩余圈数”减为 0 或负数,则将其从链表中摘下,放入
TaskQueue,由独立的工作线程池异步执行其具体逻辑。若圈数仍大于 0,则任务保留在原槽位,等待下一轮扫描。
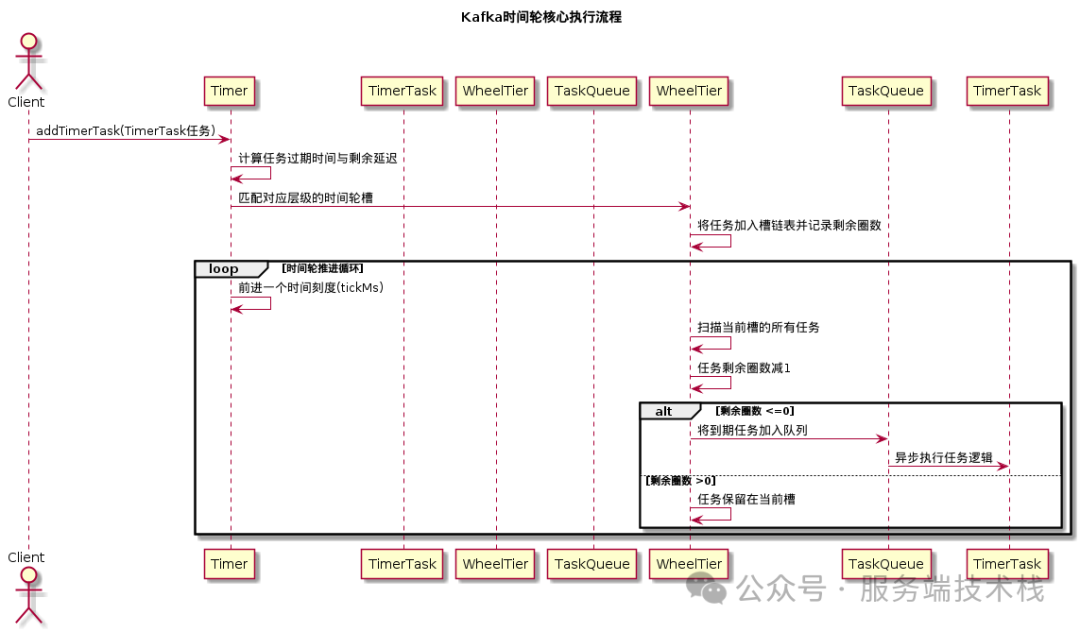
核心执行流程可视化
为了更直观地理解上述添加与推进流程的协作,可以参考以下时序图,它清晰地展示了从客户端提交延迟任务到任务最终被异步执行的全过程:
源码细节亮点与实战优化思路
除了主流程,Kafka 时间轮的实现还包含了许多值得称道的设计细节:
- 高效的任务取消:
TimerTaskEntry 自身维护了链表的前后节点引用,取消任务时仅需进行 O(1) 复杂度的链表节点删除操作。
- 并发安全控制:在关键的
add 和 advanceClock 方法中使用了锁(ReentrantReadWriteLock)来保证多线程环境下的数据一致性。
- 高可用设计:分层结构使得各层级相对独立,即便某一层出现异常(理论上极少),也不会波及其他层级的任务调度。
在实际应用中进行源码分析与调优时,可以考虑以下几点:
- 定制化层级参数:根据业务中延迟任务的分布特征,调整各层的
tickDuration 和 wheelSize。例如,如果业务 99% 的延迟任务都在 1 秒内,可以适当减少高层级轮子的粒度或大小,让更多任务在低层级快速周转。
- 优化执行线程池:
TaskQueue 的消费速度取决于后端线程池。需要根据任务的平均执行耗时和峰值数量来合理设置线程池大小和队列容量,防止执行端成为瓶颈。
- 批处理优化:对于大量同质化的到期任务(如批量更新状态),可以在
TimerTask 的执行逻辑中引入批处理机制,合并操作,减少数据库或网络 I/O 压力。
实战场景:百万级订单超时调度
以电商场景中经典的“订单超时自动取消”为例。传统方案可能采用 Redis 的 Sorted Set (ZSet) 存储订单超时时间戳,再通过定时任务周期性扫描。当订单量达到百万级时,每次全量扫描的 O(n) 复杂度会带来显著性能压力和延迟。
而采用 Kafka 时间轮方案后,每个订单在创建时便生成一个延迟任务(例如 30 分钟后执行),并以 O(1) 的复杂度添加到时间轮中。时间轮会精准地在 30 分钟后将此任务放入执行队列,由线程池触发取消逻辑。根据测试,该方案能轻松应对百万乃至更高量级的延迟任务调度,且平均调度延迟可稳定控制在毫秒级别。
希望这篇从源码出发的深度解析,能帮助你透彻理解 Kafka 时间轮的设计哲学与实现细节。如果你在实践中使用了类似的高性能调度组件,或者对延迟任务的处理有其他见解,欢迎在云栈社区的技术论坛与我们交流探讨,共同精进。
 发表于 2026-4-13 04:55:28
|
查看: 118|
回复: 0
发表于 2026-4-13 04:55:28
|
查看: 118|
回复: 0
