想象一下:电商大促期间,百万用户同时抢购商品,你的Redis缓存突然崩溃——购物车被清空,订单数据直接丢失,网站全面瘫痪……这并不是耸人听闻,而是不少电商平台遭遇过的真实灾难。该如何避免这种灭顶之灾?Redis主从复制正是解决方案的核心。
1. 背景说明:为什么需要主从复制?
电商平台的痛点:单点故障
在易购电商平台刚刚起步时,我们曾依靠单机Redis存储核心数据:
- 用户会话:用户登录状态、购物车信息
- 商品缓存:商品信息、价格、库存
- 秒杀库存:大促中的商品库存计数
一切运转良好,直到某天服务器硬盘发生故障:
- 下午3点:Redis服务器宕机
- 下午3:05:网站完全无法访问,用户无法下单
- 下午3:30:运维人员赶到机房排查
- 下午4:15:确认硬件故障,需要更换硬盘
- 下午5:45:从备份恢复数据,服务终于恢复
2小时45分钟的宕机,造成了500万订单的直接损失。这次事故让我们刻骨铭心地认识到:单点故障是电商平台的致命弱点。
专业描述:主从复制是Redis实现高可用性和数据冗余的核心机制。它将数据从一个Redis服务器(主节点)复制到一或多个Redis服务器(从节点),从而实现数据备份、读写分离与故障恢复。
现实世界类比
主从复制就像公司的文件备份制度:
- 主节点:总经理办公室的文件柜,存放所有原始文件
- 从节点:各部门的文件备份柜,定期同步总经理办公室的文件
- 读写分离:员工去部门备份柜查阅文件(读),但修改文件必须到总经理办公室(写)
- 故障恢复:若总经理办公室失火,部门备份柜可立即启用,作为新的主文件柜
主从复制解决的三大问题:
- 数据安全:数据在多个节点有备份,单点故障不会导致数据丢失
- 高可用性:主节点故障时,可从从节点快速恢复服务
- 读写分离:主节点负责写请求,从节点分担读请求,显著提升系统吞吐量
2. 核心概念:理解主从复制的基本要素
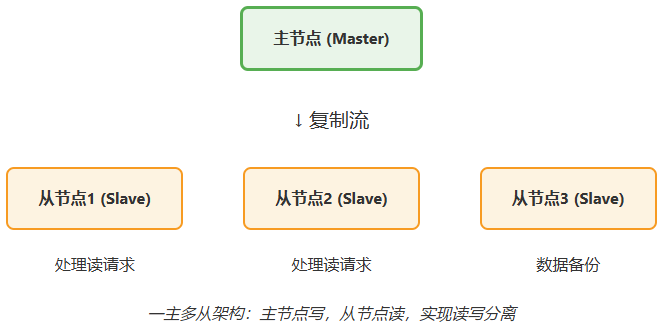
主从复制的三个核心角色
- 主节点(Master):唯一的写入口,处理所有写操作,并将写命令同步至从节点
- 从节点(Slave):只读节点,从主节点复制数据,可配置一或多个
- 复制流(Replication Stream):主节点向从节点发送的写命令序列
Redis主从复制基本架构
关键概念解析
- 复制ID(Replication ID):主节点的唯一标识。主节点重启或故障转移后,复制ID改变
- 偏移量(Offset):复制流中每个字节的位置标记,用以确定同步进度
- 复制积压缓冲区(Replication Backlog):主节点维护的固定大小缓冲区,存储最近的写命令
- 全量同步(Full Resynchronization):从节点首次连接或落后太多时,主节点发送完整数据快照
- 部分同步(Partial Resynchronization):从节点短暂断开后,仅同步断开期间丢失的命令
易购平台的架构选择
在易购平台,我们采用一主三从的架构:
- 主节点:专用于处理写操作(下单、支付、库存扣减)
- 从节点1:服务用户端读请求(商品展示、购物车查询)
- 从节点2:服务管理后台读请求(订单统计、用户分析)
- 从节点3:纯备份节点,不处理任何请求,专用于容灾
这样设计的好处是:
- 写性能不受读请求影响
- 读能力可通过增加从节点水平扩展
- 拥有完整的备份节点,数据安全性最高
- 不同业务使用不同从节点,避免相互干扰
3. 阶段1:初始化 - 全量同步
第一阶段:从零开始的完整数据同步
专业描述:当从节点首次连接主节点,或从节点缺失过多数据时,将触发全量同步。主节点生成当前数据的快照(RDB文件)发送给从节点,从节点会清空旧数据并加载此快照,实现数据的完整同步。
现实世界类比
全量同步就像搬家时的物品打包搬运:
- 你要从旧家搬到新家(从节点连接主节点)
- 把所有物品打包成箱子(主节点生成RDB快照)
- 搬家公司把所有箱子运到新家(传输RDB文件)
- 在新家拆箱,将物品摆放到位(从节点加载RDB)
- 搬家完成,新旧家物品完全一致(数据同步完成)
全量同步的详细步骤
步骤1:建立连接
从节点向主节点发送 SLAVEOF 命令,或在配置文件中指定 replicaof 指令。从节点会保存主节点的地址和端口。
步骤2:发送PSYNC命令
从节点向主节点发送 PSYNC 命令,携带自己的复制ID和偏移量。首次连接时,复制ID为"?",偏移量为-1。
步骤3:主节点响应
主节点收到 PSYNC 后发现从节点是首次连接,便回复 FULLRESYNC,并附上自己的复制ID与当前偏移量。
步骤4:生成RDB快照
主节点执行 BGSAVE 命令,在后台生成当前数据的RDB快照文件。与此同时,主节点继续处理客户端请求,新的写命令会临时存入复制缓冲区。
步骤5:传输RDB文件
RDB文件生成后,主节点将其发送给从节点。传输过程中,新写入的命令继续被缓存至复制缓冲区。
步骤6:从节点加载RDB
从节点清空自身旧数据,加载接收到的RDB文件,将数据恢复到内存中。
步骤7:同步缓冲区的命令
RDB加载完毕,主节点将复制缓冲区中累积的写命令发送给从节点,从节点执行这些命令,追赶主节点的最新状态。
全量同步的性能影响:
- 内存峰值:
BGSAVE 会fork子进程,数据集巨大时,fork操作可能阻塞主进程
- 磁盘I/O:生成RDB文件需要磁盘写入,可能影响性能
- 网络带宽:传输大型RDB文件会占用大量带宽
- 同步时间长:数据量越大,同步时间越长,期间从节点不可用
优化建议:尽量在业务低峰期执行全量同步。
易购平台的全量同步实战
在首次搭建主从复制时,我们面对的是15GB的Redis数据。
- RDB生成时间:约45秒
- RDB文件大小:约8GB(压缩后)
- 网络传输时间:约2分钟(千兆网络)
- 从节点加载时间:约1分钟
- 总同步时间:约4分钟
这4分钟内,从节点无法提供读服务。为降低影响,我们选择在凌晨2点用户访问量最低时执行同步。
4. 阶段2:运行中 - 增量同步
第二阶段:持续不断的数据同步
专业描述:全量同步完成后,主从节点进入命令传播阶段。主节点将每个写命令异步发送给所有从节点,从节点接收并执行相同命令以保持数据一致。此过程是异步的,主节点绝不会等待从节点确认。
现实世界类比
增量同步就像总经理的指令传达:
- 总经理签署文件(主节点处理写命令)
- 立即让秘书复印多份(主节点准备发送命令)
- 秘书将复印件分发给各部门经理(主节点异步发送)
- 各部门经理按复印件执行工作(从节点执行命令)
- 总经理不等部门执行就处理下一份文件(主节点不等待从节点)
增量同步的工作原理

复制积压缓冲区(Replication Backlog)
这是一个主节点维护的、固定大小的循环缓冲区(默认1MB),存储最近发送的写命令。它的核心作用就是支持部分重同步。

主从延迟问题
Redis主从复制是异步的,所以从节点数据可能稍落后于主节点,这就产生了主从延迟。延迟大小取决于网络状况、从节点负载等因素。
主从延迟导致的业务问题
在易购平台,我们曾遇到一件怪事:用户下单支付成功,可立刻查看订单状态时,页面却显示“未支付”。客服收到了大量“我刚付了钱,为什么没变化?”的投诉。
这究竟是怎么回事?原来,订单状态更新写入了主节点,但用户的查询请求被路由到了从节点,此时该从节点尚未同步到最新数据。
解决方案:
- 读写分离策略优化:对一致性要求高的读请求(如订单状态、支付结果),强制路由到主节点。
- 延迟监控:监控主从延迟,一旦超过阈值立即报警。
- 业务降级:延迟过大时,将所有读请求暂时全部切到主节点。
优化增量同步的建议:
- 调整复制积压缓冲区大小:根据业务写QPS计算,建议设置为
平均每秒写命令大小 × 最大允许断开时间 × 2。
- 监控主从延迟:使用
INFO replication 命令,观察 slave_repl_offset 和 master_repl_offset 的差值。
- 网络优化:将主从节点部署在同一机房或可用区,最大限度减少网络延迟。
- 从节点性能:从节点硬件配置不应低于主节点,避免其处理能力不足导致延迟。
5. 阶段3:异常恢复 - 断线重连与同步判断
第三阶段:网络异常后的智能恢复
专业描述:当从节点与主节点网络断开又重连时,Redis会智能判断采用全量同步还是部分同步。若从节点缺失的数据仍在主节点的复制积压缓冲区中,则进行部分同步;否则,只能进行全量同步。
现实世界类比
断线重连就像员工请假后的工作补全:
- 员工请假3天(从节点断开)
- 返岗后需补上这3天的工作(重新同步)
- 若这3天的工作记录全在会议纪要里,员工只需读纪要即可(部分同步)
- 若会议纪要只保留最近1天,而员工请假3天,他只好从头了解所有工作(全量同步)
断线重连的决策流程
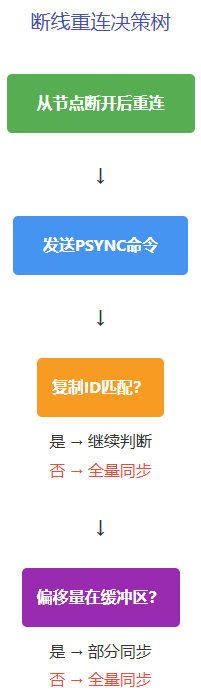
复制ID的作用
复制ID是主节点的唯一标识。当主节点重启或执行 SLAVEOF NO ONE 后,复制ID会发生改变。从节点重连时若发现主节点的复制ID变了,意味着对面已非原来的主节点,此时必须执行全量同步。
易购平台的断线恢复实战
我们遇到过多种断线场景,恢复方式与影响大相径庭:
| 断线场景 |
断线时间 |
同步方式 |
恢复时间 |
对业务影响 |
| 网络抖动 |
3秒 |
部分同步 |
1秒内 |
无感知 |
| 从节点重启 |
30秒 |
部分同步 |
2秒 |
短暂不可用 |
| 主节点切换 |
2分钟 |
全量同步 |
5分钟 |
从节点不可用5分钟 |
| 机房网络故障 |
10分钟 |
全量同步 |
15分钟 |
从节点不可用15分钟 |
经验总结:设置合理的复制积压缓冲区大小至关重要。我们根据业务峰值(每秒1万次写操作,平均每条命令100字节)和最大允许断线时间(5分钟)来计算:1万 × 100字节 × 300秒 = 300MB。最终我们将缓冲区设为512MB,确保5分钟内的断线均可通过部分同步恢复。
无盘复制(Diskless Replication)
Redis新版本引入无盘复制特性。在全量同步时,主节点不再将RDB文件写入磁盘,而是直接将数据流通过网络发送给从节点,以此彻底避免磁盘I/O瓶颈。
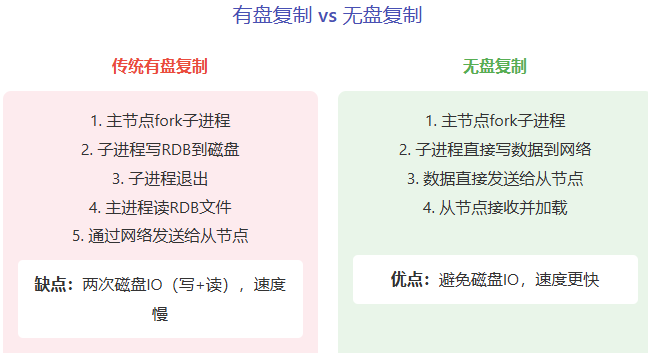
无盘复制的注意事项:
- 网络稳定性要求高:若传输中断,需重新开始全量同步。
- 内存占用:传输期间,RDB数据会占用子进程内存。
- 适用场景:磁盘速度慢,但网络带宽充裕的环境。
在易购平台,我们启用无盘复制后,全量同步时间从4分钟直接缩短到了2.5分钟。
6. 总结:主从复制的最佳实践
Redis主从复制的核心价值
- 数据高可用:多节点数据冗余,单点故障不丢数据
- 读写分离:提升系统整体吞吐量,完美适配读多写少场景
- 故障恢复:主节点故障时,可快速切换至从节点
- 数据备份:可在从节点执行备份,不影响主节点性能
主从复制部署建议
| 配置项 |
建议值 |
说明 |
| 从节点数量 |
2-5个 |
视读请求量而定,过多会加重主节点压力 |
| 复制积压缓冲区大小 |
512MB-1GB |
根据写QPS与允许的断线时间计算 |
| 主从网络延迟 |
< 1ms |
应部署在同一可用区,避免跨机房高延迟 |
| 从节点配置 |
不低于主节点 |
避免从节点成为性能短板 |
| 监控指标 |
主从延迟、同步状态 |
设置报警阈值,超限立即告警 |
易购平台的主从复制架构演进
经过3年持续迭代,我们的Redis主从架构已相当成熟:
- 第一代:一主一从,手动切换,仅用于数据备份
- 第二代:一主三从,读写分离,不同从节点服务不同业务
- 第三代:多套主从集群,按业务垂直拆分(用户会话、商品缓存、订单数据等)
- 第四代:主从+哨兵,实现自动化故障转移
当前的关键性能指标为:
- 主从延迟:平均1-5ms,峰值不超过50ms
- 数据一致性:99.99%的读请求能在1秒内读到最新数据
- 故障恢复时间:从节点故障恢复平均10秒,主节点故障切换30秒
- 系统可用性:从99.9%提升至99.99%
最后的话:主从复制不是万能药
Redis主从复制是构建高可用Redis架构的基础,但远非全部。它有效解决了数据备份和读写分离问题,却仍有其局限性:
- 写性能无法扩展:所有写操作仍然汇聚在主节点
- 存储容量无法扩展:所有节点都存储全量数据
- 故障切换需额外机制:需依赖Sentinel或手动操作
对更大规模的平台而言,还需要:
- Redis Cluster:解决数据分片与写扩展问题
- Redis Sentinel:实现自动故障转移
- 多级缓存架构:结合本地缓存与分布式缓存
- 异地多活:解决机房级故障
但无论如何,主从复制是所有高级Redis架构的基石。唯有深入理解主从复制,方能构建出稳定可靠的Redis系统。在云栈社区的技术交流中,我们也看到,许多看似复杂的线上问题,根源往往就在于对主从复制的基础原理认识不清。
 发表于 2026-4-30 19:57:15
|
查看: 80|
回复: 0
发表于 2026-4-30 19:57:15
|
查看: 80|
回复: 0
