1. MySQL MVCC 原理与实现方式
1.1 MVCC 基本概念
MVCC(Multi-Version Concurrency Control,多版本并发控制)是一种数据库并发控制技术。其核心思想是在系统中维护数据的多个版本,让读操作不会阻塞写操作,写操作也不会阻塞读操作,从而大幅提升数据库的并发性能。
1.2 MySQL InnoDB 的 MVCC 实现
1.2.1 核心数据结构
InnoDB 为每一行记录都悄悄添加了几个隐藏字段,它们是 MVCC 的基石:
-- 隐藏字段(每行记录包含)
DB_TRX_ID -- 最近修改的事务ID(6字节)
DB_ROLL_PTR -- 回滚指针,指向Undo Log(7字节)
DB_ROW_ID -- 行ID(6字节,当没有主键时自动生成)
1.2.2 Undo Log(回滚日志)
Undo Log 是 MVCC 的核心组件,存储着数据被修改前的“旧版本”。它主要分为两类:
- Insert Undo Log:记录 INSERT 操作,仅在事务回滚时用于删除新插入的行。
- Update Undo Log:记录 UPDATE 或 DELETE 操作,不仅用于事务回滚,更是构建一致性读视图(Read View)的关键。
1.2.3 Read View(读视图)
Read View 定义了在某个瞬间,一个事务能看到哪些数据版本。它的结构可以抽象理解为:
class ReadView:
m_ids: list # 活跃事务ID列表
min_trx_id: int # 最小活跃事务ID
max_trx_id: int # 最大活跃事务ID
creator_trx_id: int # 创建Read View的事务ID
1.2.4 版本链(Version Chain)
一行数据的多个版本是如何串联起来的?答案是通过 DB_ROLL_PTR 指针构成的版本链:
当前行记录 (DB_TRX_ID=200, DB_ROLL_PTR→)
↓
Undo Log v1 (DB_TRX_ID=150, DB_ROLL_PTR→)
↓
Undo Log v2 (DB_TRX_ID=100, DB_ROLL_PTR=null)
1.3 MVCC 可见性判断规则
对于一行记录,判断它对当前事务是否可见,通常遵循以下逻辑:
- DB_TRX_ID < min_trx_id:说明修改该行的事务早已提交,可见。
- DB_TRX_ID >= max_trx_id:说明修改该行的事务在当前事务之后才开始,不可见。
- min_trx_id ≤ DB_TRX_ID < max_trx_id:说明修改该行的事务与当前事务在时间上有重叠。
- 如果 DB_TRX_ID 在
m_ids(活跃事务列表)中,表示该事务仍活跃,不可见。
- 如果 DB_TRX_ID 不在
m_ids 中,表示该事务已提交,可见。
1.4 隔离级别与 MVCC
不同的隔离级别下,MVCC 的行为和 Read View 的生成时机也不同:
| 隔离级别 |
MVCC 行为 |
脏读 |
不可重复读 |
幻读 |
| READ UNCOMMITTED |
不使用MVCC |
可能 |
可能 |
可能 |
| READ COMMITTED |
每次查询创建新Read View |
不可能 |
可能 |
可能 |
| REPEATABLE READ |
事务开始时创建Read View |
不可能 |
不可能 |
InnoDB不可能 |
| SERIALIZABLE |
使用锁机制,不使用MVCC |
不可能 |
不可能 |
不可能 |
2. MySQL 是否会产生类似 Oracle ORA-01555 的快照过旧问题?
2.1 Oracle ORA-01555 问题原理
Oracle 用户对 ORA-01555 "snapshot too old" 错误应该不陌生,它通常在以下场景发生:
- 一个长事务需要读取某个时间点的一致性快照。
- 但构建快照所需的 Undo 数据已被新事务覆盖(因 Undo 表空间不足或
UNDO_RETENTION 设置过短)。
- 最终导致无法重建一致性读视图,查询失败。
2.2 MySQL 的差异与优势
2.2.1 Undo Log 管理机制不同
我们先看下 MySQL 的相关配置:
-- MySQL InnoDB Undo 配置
SHOW VARIABLES LIKE 'innodb_undo%';
/*
innodb_undo_directory -- Undo文件存储路径
innodb_undo_tablespaces -- Undo表空间数量
innodb_undo_log_truncate -- 自动截断Undo Log
innodb_undo_logs -- Undo Log数量
*/
2.2.2 MySQL 不会产生 ORA-01555 的原因
MySQL InnoDB 能规避 ORA-01555 快照过旧问题的核心,在于其 Purge 机制与 Read View 的精密协作设计:
-
1. Purge 线程的保守清理策略
MySQL 的 Purge 线程绝不轻率地清理 Undo Log,它会执行严格的安全检查:
// InnoDB Purge 核心逻辑(简化)
bool can_purge(trx_id) {
// 获取当前所有活跃事务的最小 ID
min_active_trx_id = get_min_active_trx_id();
// 只有当 undo 记录的 trx_id 小于所有活跃事务的 min_trx_id 时才能 purge
// 这确保了长事务需要的所有历史版本都不会被清理
return trx_id < min_active_trx_id;
}
关键在于:Purge 会计算 active_trx_min_id(当前所有活跃事务的最小ID)。一个 Undo 记录,只有当它的 DB_TRX_ID 比这个最小ID还要小时,才被认为是“所有活跃事务都看不见”的,从而安全地清理。
-
2. Read View 与事务生命周期绑定
| 特性 |
Oracle |
MySQL InnoDB |
| 快照获取时机 |
每次 SELECT 语句开始时 |
事务开始时创建 Read View |
| 快照基准 |
SCN (System Change Number) |
活跃事务 ID 列表 (m_ids) |
| 快照有效期 |
语句级别 |
事务级别 |
MySQL 的设计更保守:只要事务没结束,它的 Read View 就持续有效,其所需的历史版本自然也就不能被清理。
-
3. 长事务的保护机制
即使存在长事务,MySQL 也不会丢失它需要的旧版本数据:
-- 即使存在长事务,MySQL 也不会丢失历史版本
-- 场景说明:
-- 事务 A (trx_id=100) 开启了 REPEATABLE READ
-- 事务 B (trx_id=101) 在事务 A 运行期间修改了数据并提交
-- 事务 A 仍然可以看到 trx_id=101 提交前的数据
-- 原因:事务 A 的 Read View 中 m_ids=[101, ...],101 在活跃列表中
-- 因此 101 修改的旧版本对事务 A 可见
-- 并且该旧版本不会被 Purge,因为 101 仍在 m_ids 中
-
4. Undo Log 的分段管理
MySQL 的 Undo Log 按 rseg(Rollback Segment)管理,支持多表空间,分散 I/O 压力:
-- 配置建议
SET GLOBAL innodb_undo_tablespaces = 4; -- 多个表空间分散IO
SET GLOBAL innodb_undo_log_truncate = ON; -- 启用自动截断
SET GLOBAL innodb_max_undo_log_size = 1G; -- 单个Undo文件最大1G
-
5. 与 Oracle 的本质差异
让我们用一个流程对比来直观感受两者的不同:
Oracle 快照过旧流程:
1. SELECT 启动 → 获取当前 SCN
2. 需要读取 undo 中 SCN=T1 的旧版本
3. 但该 undo 已被覆盖(Retention 策略或空间不足)
4. → ORA-01555 错误
MySQL 规避流程:
1. 事务启动 → 创建 Read View,记录活跃事务列表 [100, 101, 102]
2. 需要读取 trx_id=50 的旧版本
3. Purge 线程检查:50 < min([100,101,102])=100? 是,可以清理
4. 但如果 50 是长事务需要读取的版本呢? → 检查 Read View
5. 该旧版本仍然保留,因为可能对活跃事务可见
6. → 不会出现"找不到历史版本"的问题
总结:MySQL 通过“活跃事务列表 + min_trx_id 门限”的双重保护,确保了长事务所需的历史版本永远不会被误清理,从根本上规避了 ORA-01555 问题。
2.2.3 可能出现的类似问题
虽然 MySQL 没有 ORA-01555,但在极端情况下,长事务可能会引发锁相关的问题:
-- 长事务导致的问题
ERROR 1205 (HY000): Lock wait timeout exceeded
-- 或
ERROR 1213 (40001): Deadlock found
3. MySQL MVCC 是否会产生类似 PostgreSQL 的数据膨胀问题?
3.1 PostgreSQL 数据膨胀问题
PostgreSQL 的 MVCC 实现有其自身特点,也带来了广为人知的数据膨胀挑战:
- 多版本共存于主表:更新一行就是在主表中插入一个新版本,老版本成为“死元组”。
- 依赖 VACUUM 清理:必须通过
VACUUM 操作来回收死元组占据的空间,否则表会无限膨胀。
- HOT优化杯水车薪:尽管有 Heap Only Tuple 优化来减少索引更新,但还是治标不治本。
3.2 MySQL InnoDB 的差异
3.2.1 存储架构优势
MySQL InnoDB 的存储结构从一开始就为分离式MVCC而生:
表空间 (.ibd文件)
├── 聚簇索引 (主键索引)
│ ├── 行数据 (包含隐藏字段)
│ └── 版本链指针
└── 二级索引
└── 主键引用
3.2.2 不会产生严重数据膨胀的原因
- Undo Log 分离存储:旧版本数据安放在独立的 Undo Log 区域,不在主表中,从物理上杜绝了主表膨胀。
- Purge 线程自动清理:专门的后台线程持续清扫不再被任何事务需要的 Undo Log,实现自动化管理。
- 版本链回溯机制:通过指针回溯旧版本,无需在表中复制整行数据。
- 页内空间复用:表中被删除记录的空间,可被新记录直接利用。
3.2.3 可能的空间问题
通过以下命令,我们可以检查各表的空间使用情况:
-- 检查表空间使用情况
SELECT
TABLE_SCHEMA,
TABLE_NAME,
DATA_LENGTH/1024/1024 AS data_mb,
INDEX_LENGTH/1024/1024 AS index_mb,
DATA_FREE/1024/1024 AS free_mb
FROM information_schema.TABLES
WHERE TABLE_SCHEMA NOT IN ('mysql', 'information_schema', 'performance_schema')
ORDER BY DATA_LENGTH DESC LIMIT 10;
3.3 性能对比
| 特性 |
PostgreSQL MVCC |
MySQL InnoDB MVCC |
| 版本存储位置 |
主表(Heap) |
Undo Log(分离) |
| 清理机制 |
手动/自动 VACUUM |
自动 Purge 线程 |
| 数据膨胀 |
较严重,需定期维护 |
轻微,自动管理 |
| 写放大 |
较高(更新整行) |
较低(只写变化) |
| 读性能 |
需要遍历版本链 |
版本链优化较好 |
4. MySQL 的 Undo 空间限制机制与长事务影响
4.1 Undo 表空间的配置限制
MySQL 通过明确的配置参数来设定 Undo 表空间的“天花板”:
-- 查看当前 Undo 配置
SHOW VARIABLES LIKE 'innodb_max_undo_log_size'; -- 单个 Undo 表空间最大大小(默认 1GB,可动态调整)
SHOW VARIABLES LIKE 'innodb_undo_tablespaces'; -- Undo 表空间数量(默认 2,范围 2-127,可动态调整)
SHOW VARIABLES LIKE 'innodb_undo_log_truncate'; -- 是否自动截断(默认 ON,可动态调整)
SHOW VARIABLES LIKE 'innodb_undo_directory'; -- Undo 文件存储路径
关键配置说明:
innodb_max_undo_log_size:这是一道硬性限制,当单个 Undo 文件达到此大小时,会触发空间管理机制。innodb_undo_tablespaces:配置多个 Undo 表空间可以循环使用,避免单点压力。innodb_undo_log_truncate:启用后,系统可以自动回收已被清理的 Undo 空间,至关重要。
4.2 长事务是否会导致 Undo 无限制增长?
4.2.1 理论上的持续增长
从理论上看,是的。只要一个长事务还没结束,它的 Read View 就要求所有更早的版本必须保留。在此期间,任何数据修改都会产生新的 Undo 记录,导致 Undo Log 不断膨胀。
4.2.2 实际中的限制机制
但 MySQL 拥有一套“组合拳”来防止真正的“无限”增长:
-
1. 空间切换与事务阻塞机制
# Undo 空间管理简化逻辑
def handle_undo_space():
if current_undo_file.is_full():
if has_available_undo_tablespace():
# 切换到下一个可用的 Undo 表空间
switch_to_next_undo_tablespace()
else:
# 所有表空间都满了,需要等待 Purge
if purge_thread.can_catch_up():
wait_for_purge_completion()
else:
# 长事务阻塞了 Purge,事务将阻塞
new_transaction.wait()
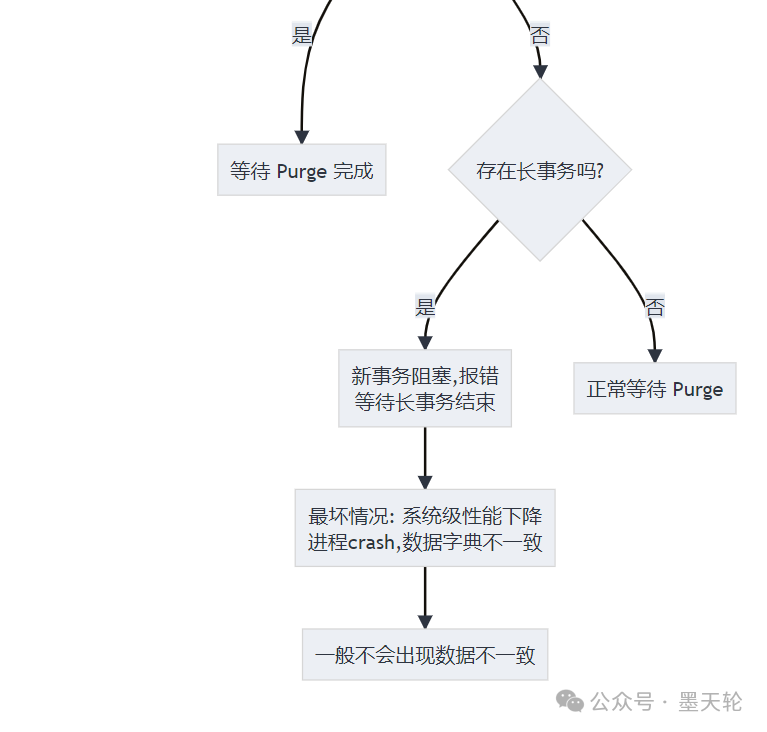
当所有 Undo 表空间都“满载”且长事务阻碍了清理时,系统并不会崩溃或产生数据不一致,而是干脆地阻塞新来的事务。
-
2. 事务阻塞场景
当空间耗尽且无法清理时,会出现以下结果:
- 新事务阻塞并报错:你会看到
Error 3871: Undo tablespace is full 或 Error 1114: The table is full。
- 系统吞吐量下降:系统仍在运行,但像被勒住了缰绳。
- 数据一致性得到保证:这是与 Oracle ORA-01555 的关键区别,MySQL 优先保障了数据一致。
-
3. InnoDB 内部限制
- 每个 Undo 表空间最多 128 个 Rollback Segment。
- 每个 Rollback Segment 有固定数量的 Undo Slot。
- 物理磁盘空间是最终的硬限制。
4.3 Undo 空间增长对数据库性能的影响
与 PostgreSQL 的数据膨胀直接影响存储和查询不同,MySQL Undo 空间的增长主要通过系统资源竞争来影响性能。
4.3.1 I/O 性能影响
- 版本链回溯开销:当版本链变长,一个查询可能需要多次访问 Undo Log 才能找到可见版本,直接增加读取延迟。
- Purge 扫描成本:Purge 线程需要扫描更长的 Undo 链来决定哪些可以清理,自身也变得昂贵。
- Buffer Pool 污染:大量对 Undo 页面的读写操作,可能会把本该待在内存里的热数据挤出 Buffer Pool。
4.3.2 CPU 和内存影响
-
1. Purge 线程 CPU 消耗
你可以通过以下命令观察 Purge 线程的工作状态:
-- 监控 Purge 线程状态
SHOW ENGINE INNODB STATUS\G
-- 查看 Purge 相关部分:
-- "BACKGROUND THREAD" -> "srv_purge_thread"
-- "History list length" 表示待清理的记录数
一个糟糕的循环就此形成:
大事务 → Undo 快速增长 → History List 增长 →
Purge 线程忙不过来 → 更多 Undo 堆积 →
Purge 线程更忙(恶性循环)
-
2. Buffer Pool 竞争
# 简化版 Buffer Pool 竞争模型
Total_Memory = Buffer_Pool_Size + Undo_Buffer_Size
# 如果 Undo 占用过多内存(通过文件系统缓存),
# Buffer Pool 中的热数据可能被换出到磁盘
4.3.3 事务性能影响
-
1. 事务启动延迟
# 事务启动时的额外开销
def start_transaction():
# 1. 创建 Read View
read_view = create_read_view()
# 2. 如果 Undo 很大,需要更多时间来扫描活跃事务
# 活跃事务越多,扫描时间越长
scan_active_transactions()
# 3. 版本链指针初始化
init_version_chain_pointers()
-
2. 查询性能下降
当版本链很长时,一个看似简单的查询也可能陷入泥潭:
-- 版本链遍历示例
-- 当版本链很长时,即使简单的查询也可能变慢
EXPLAIN SELECT * FROM users WHERE id = 100;
-- 实际执行时可能需要遍历:
-- 当前版本 (trx_id=200) -> Undo v1 (trx_id=150) ->
-- Undo v2 (trx_id=100) -> Undo v3 (trx_id=50) -> ...
4.3.4 性能监控矩阵
| 性能指标 |
正常范围 |
警告阈值 |
严重阈值 |
监控命令 |
| History List Length |
< 1000 |
1000-5000 |
> 5000 |
SHOW ENGINE INNODB STATUS |
| Undo 空间使用率 |
< 50% |
50%-80% |
> 80% |
(见下方监控脚本) |
| Purge 滞后(records) |
< 100 |
100-1000 |
> 1000 |
(见下方监控脚本) |
| 事务平均时长 |
< 1s |
1s-5s |
> 5s |
SELECT AVG(TIME_TO_SEC(... |
| Undo 读延迟 |
< 1ms |
1ms-5ms |
> 5ms |
(见下方监控脚本) |
4.3.5 性能优化策略
-
1. 配置优化
# my.cnf 性能优化配置
[mysqld]
# Undo 性能优化
innodb_purge_threads = 4 # 增加 Purge 线程数
innodb_purge_batch_size = 300 # 增大批次大小
innodb_max_purge_lag = 100000 # 设置 Purge 滞后阈值
innodb_max_purge_lag_delay = 5000 # 最大延迟毫秒数
# I/O 优化
innodb_flush_log_at_trx_commit = 2 # 平衡性能与持久性
innodb_flush_method = O_DIRECT # 直接 I/O,减少 OS 缓存
innodb_io_capacity = 2000 # 提高 IO 能力
innodb_io_capacity_max = 4000
-
2. 架构优化
从更高层面解决问题:
-- 1. 读写分离,减少主库长查询
-- 2. 分库分表,分散 Undo 压力
-- 3. 使用缓存层,减少数据库直接访问
-- 4. 大事务拆分为小事务
-- 示例:大事务拆分
-- 不推荐:
START TRANSACTION;
UPDATE large_table SET status = 'processed' WHERE created_at < '2026-01-01';
COMMIT;
-- 推荐:
SET autocommit = 0;
UPDATE large_table SET status = 'processed' WHERE created_at < '2026-01-01' LIMIT 1000;
COMMIT;
UPDATE large_table SET status = 'processed' WHERE created_at < '2026-01-01' LIMIT 1000;
COMMIT;
-- ... 循环直到完成
-
3. 查询优化
-- 使用覆盖索引减少回表
-- 版本链回溯时,如果只需要索引列,可以减少 Undo 访问
CREATE INDEX idx_covering ON users (id, name, email);
-- 查询时明确指定需要的列
SELECT id, name FROM users WHERE id = 100; -- 优于 SELECT *
-- 避免在长事务中进行范围查询
-- 范围查询可能锁定大量行,产生大量 Undo
4.3.6 与 PostgreSQL 数据膨胀的性能对比
| 性能影响维度 |
PostgreSQL 数据膨胀 |
MySQL Undo 增长 |
| 存储空间 |
直接影响:主表膨胀,空间浪费严重 |
间接影响:Undo 表空间占用,但可配置上限 |
| 查询性能 |
直接影响:表膨胀导致需扫描更多页面 |
间接影响:版本链遍历增加读取延迟 |
| 写性能 |
直接影响:VACUUM 操作本身带来开销 |
间接影响:Purge 线程压力,可能阻塞写入 |
| 维护成本 |
高:需定期执行 VACUUM,可能影响业务高峰 |
中:自动 Purge,但需要合理配置和监控 |
| 可预测性 |
低:膨胀程度难以精确预估 |
高:有明确的 Undo 空间上限 |
4.4 Undo 表空间满了的连锁反应
4.4.1 标准处理流程
当 Undo 表空间满了,MySQL 会按如下逻辑进行决策:
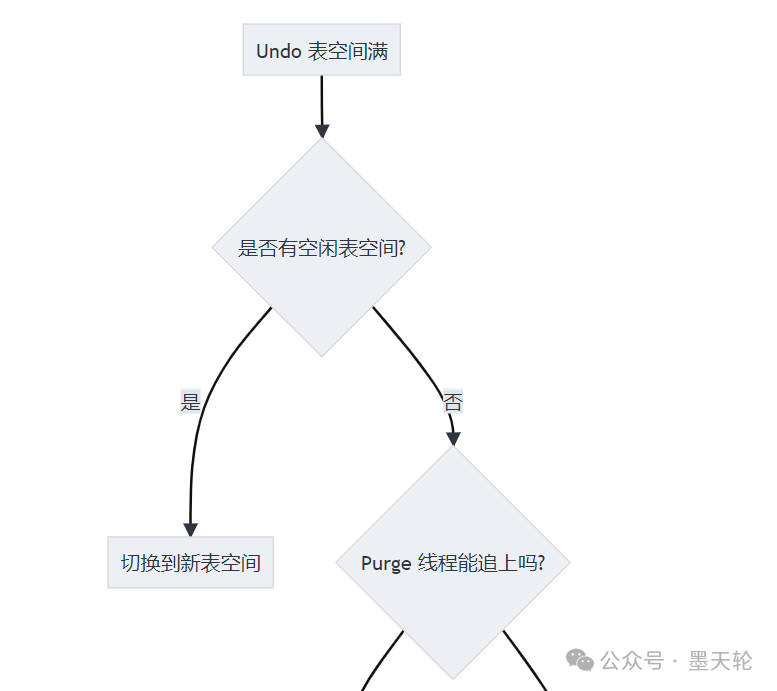
接着,系统会进入一个更细致的判断循环:
4.4.2 几个数据库的对比
| 特性 |
Oracle |
MySQL InnoDB |
PostgreSQL |
| 限制类型 |
时间限制 (UNDO_RETENTION) |
空间限制 (innodb_max_undo_log_size) |
年龄限制 + 空间限制 |
| 满后错误 |
ORA-01555 快照过旧 |
事务阻塞,无数据不一致 |
文件系统耗尽(事务ID回卷时)或性能严重下降 |
| 长事务影响 |
可能导致后续查询失败 |
可能导致系统性能下降 |
VACUUM清理失效,表膨胀、查询变慢,增加事务ID回卷风险 |
| 清理机制 |
SMON 自动清理 |
Purge 线程 + 自动截断 |
Autovacuum(自动清理)配合手动VACUUM |
| 运维复杂度 |
需要精细的 Retention 调优 |
相对简单,空间换时间 |
中等:需配置Autovacuum参数 |
5. MySQL MVCC 的优缺点与最佳实践
5.1 优点
- 数据一致性优先:宁可阻塞新事务,也不破坏现有快照的一致性。
- 配置简单直观:基于空间大小的限制比 Oracle 基于时间的 Retention 策略更容易理解和配置。
- 可预测的行为:达到配置上限后的事务阻塞行为是可预期的。
- 高度自动化管理:Purge 线程和自动截断功能极大地减少了人工干预。
5.2 缺点
- 可能导致系统性阻塞:一个“流氓”长事务可能拖慢甚至阻塞整个系统。
- 需要足够的磁盘空间:必须为 Undo 表空间预分配充分的磁盘空间。
- 运维监控要求高:DBA 需要主动持续地监控长事务和 Undo 使用率。
- 版本链遍历开销:在极端情况下,过长的版本链会影响读性能。
- Purge 延迟风险:海量更新操作可能导致 Purge 线程跟不上,造成滞后。
5.3 核心结论:
- MySQL 的 Undo 机制确实会导致其随着长事务而增长。
- 但这个增长有明确的配置上限,不会真正无限制扩张。
- 达到上限后的表现是系统性能下降或事务阻塞,而非数据不一致。
- 这体现了 “可用性 vs 一致性” 的经典设计取舍,而 MySQL 坚定地选择了一致性优先。
5.4 最佳实践
5.4.1 配置优化
# my.cnf 推荐配置
[mysqld]
# Undo 空间配置(请根据磁盘空间调整)
innodb_max_undo_log_size = 4G # 单个 Undo 文件最大 4GB
innodb_undo_tablespaces = 8 # 8 个 Undo 表空间循环使用
innodb_undo_log_truncate = ON # 启用自动截断
innodb_purge_rseg_truncate_frequency = 64 # 更频繁的回收
# 事务超时控制
innodb_lock_wait_timeout = 30 # 锁等待超时 30 秒
innodb_rollback_on_timeout = ON # 超时自动回滚
# 监控优化
performance_schema = ON
innodb_monitor_enable = all
5.4.2 监控脚本
主动监控是防范问题的关键。以下是一些实用的监控脚本,可以帮助你及时发现并处理潜在风险。
-- 监控MVCC相关指标
SELECT
'当前事务数' AS metric,
COUNT(*) AS value
FROM information_schema.INNODB_TRX
UNION ALL
SELECT
'长事务数(>60s)',
COUNT(*)
FROM information_schema.INNODB_TRX
WHERE TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) > 60
UNION ALL
SELECT
'Undo Log大小(MB)',
ROUND(SUM(size)/1024/1024, 2)
FROM information_schema.INNODB_TABLESPACES
WHERE name LIKE '%undo%';
-- 自动检测和处理长事务
DELIMITER //
CREATE PROCEDURE monitor_and_handle_long_transactions()
BEGIN
DECLARE v_count INT;
-- 检测超时事务
SELECT COUNT(*) INTO v_count
FROM information_schema.INNODB_TRX
WHERE TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) > 600; -- 10分钟
IF v_count > 0 THEN
-- 记录到日志表
INSERT INTO sys.long_transaction_alert
(alert_time, long_transaction_count, details)
SELECT
NOW(),
COUNT(*),
GROUP_CONCAT(CONCAT('TRX:', trx_id, ' User:', trx_mysql_thread_id))
FROM information_schema.INNODB_TRX
WHERE TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) > 600;
-- 这里可以扩展:发送告警、尝试安全终止等操作
-- 注意:在生产环境中终止事务需要非常谨慎
END IF;
END//
DELIMITER ;
-- 创建调度任务
CREATE EVENT check_undo_and_transactions
ON SCHEDULE EVERY 5 MINUTE
DO CALL monitor_and_handle_long_transactions();
-- 监控 Undo 空间使用情况
SELECT
ROUND(SUM(TOTAL_EXTENTS*EXTENT_SIZE)/1024/1024, 2) AS total_mb,
round(sum(TOTAL_EXTENTS*EXTENT_SIZE-FREE_EXTENTS*EXTENT_SIZE)/1024/1024, 2) AS used_mb,
ROUND(SUM(TOTAL_EXTENTS - FREE_EXTENTS) * 100 / SUM(TOTAL_EXTENTS), 2) AS used_percent,
COUNT(*) AS num_tablespaces
FROM INFORMATION_SCHEMA.FILES
WHERE FILE_NAME LIKE '%undo%' ;
-- 监控 Purge 滞后情况 (MariaDB或Percona Server也适用)
SELECT
'Innodb_history_list_length' AS metric,
VARIABLE_VALUE AS value
FROM performance_schema.global_status
WHERE VARIABLE_NAME = 'Innodb_history_list_length'
UNION ALL
SELECT
'Innodb_purge_lag',
VARIABLE_VALUE
FROM performance_schema.global_status
WHERE VARIABLE_NAME = 'Innodb_purge_lag'
UNION ALL
SELECT
'Long Transactions (>300s)',
COUNT(*)
FROM information_schema.INNODB_TRX
WHERE TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) > 300;
5.4.3 运维建议
- 避免长事务:在应用层面设置事务超时,并时刻警惕未提交的事务。
- 定期监控:建立对 Undo Log 使用率和 History List 长度的持续监控。
- 合理设计索引:减少全表扫描,从而降低大范围锁和大量 Undo 的产生。
- 批量操作优化:将大的批处理任务拆分成多个小事务执行。
- 版本链清理:定期检查表结构,
OPTIMIZE TABLE 可以重建表,清理过长的历史版本链(注意会锁表)。
6. 总结
6.1 核心结论
- MySQL MVCC 实现:基于 Undo Log + Read View + 版本链,设计精巧高效。
- 对比 Oracle:由于 Purge 线程的“保守清理”和 Read View 的生命周期绑定,MySQL 不会产生 ORA-01555 错误。
- 对比 PostgreSQL:得益于 Undo Log 的分离存储与自动清理机制,MySQL 不会出现严重的主表空间膨胀问题。
- Undo 空间管理:增长有上限,行为可预测,彻底杜绝了无限制增长,但需要合理规划与监控。
- 性能影响:主要通过 I/O 和 Purge 线程的 CPU 资源竞争来影响系统,而非直接的存储膨胀。
6.2 技术选型建议
- 高并发读场景:MySQL MVCC 表现出色,是理想选择。
- 长事务处理:需要格外注意监控和优化,或将此类逻辑移至专门的分析库。
- 存储敏感场景:相比 PostgreSQL,MySQL 有更高的空间利用率。
- 维护成本:MySQL 的自动管理特性使其在运维上是成本更低的。
- 性能监控:务必重点关注 Undo 空间使用率和 Purge 的滞后指标。
参考资料:
- MySQL 官方文档 - InnoDB Multi-Versioning
- 《高性能 MySQL》 - MVCC 实现原理
如果您正在社区中寻找关于 MySQL 及各类数据库技术的深度讨论,或者系统架构设计的实战经验,云栈社区 上聚集了众多一线开发者,或许能带来一些启发。
 发表于 2026-4-30 20:24:53
|
查看: 100|
回复: 0
发表于 2026-4-30 20:24:53
|
查看: 100|
回复: 0
