在后端架构设计中,“高性能”始终是核心目标。而要实现高性能,缓存设计是关键的一环。许多人在讨论高性能方案时,思维往往局限于“加一层 Redis”。虽然 Redis 能显著提升性能,但它如今已是基础技能。在架构设计或面试中,仅抛出“用了 Redis”的方案,难以体现技术深度。
今天,我们结合实战场景,深入探讨几种非常规但极具价值的缓存设计方案。这些方案不仅能解决实际性能瓶颈,也是你在面试求职中展示差异化能力的利器。
面试准备的正确姿势
谈论缓存时,切忌干巴巴罗列技术点。应将缓存方案作为提升系统性能的关键一环来阐述。一个优秀的缓存设计应围绕以下维度展开:
- 设计初衷:为什么标准方案(仅 Redis)满足不了需求?
- 命中率保障:如何保证缓存能被高效命中?
- 一致性取舍:引入缓存带来的一致性问题如何解决或权衡?
- 量化指标:方案实施后,响应时间(RT)降低多少?QPS 提升多少?
- 差异化竞争:相比通用的“Redis + 数据库”模式,独特之处在哪?
尤其是最后一点,是体现你架构思维的关键。常规方案面试官司空见惯,唯有结合具体业务特征的“出奇制胜”,才能给人留下深刻印象。
方案一:一致性哈希 + 本地缓存
我们先看一个经典组合:一致性哈希 + 本地缓存 + Redis 缓存。“本地缓存 + Redis”的二级缓存模式很常见,但在极致性能要求下可能力不从心。这里分享一个真实案例。
我们曾负责一个商品详情页的核心价格接口,要求毫秒级响应。初期仅用 Redis,性能达标,但大促期间并发激增,网络 IO 和序列化开销成为瓶颈。为压榨性能,引入进程内本地缓存(如 Caffeine)势在必行。
但单纯引入本地缓存会面临两个问题:
- 内存浪费:在集群中,由于负载均衡(如轮询),同一个热门商品请求可能被分到任意机器,导致所有机器内存都缓存同一份数据,造成巨大浪费。
- 命中率低下:请求分散导致本地缓存难以命中,无法发挥“极速”优势。
为解决此痛点,我们在客户端或网关侧引入了一致性哈希负载均衡算法。
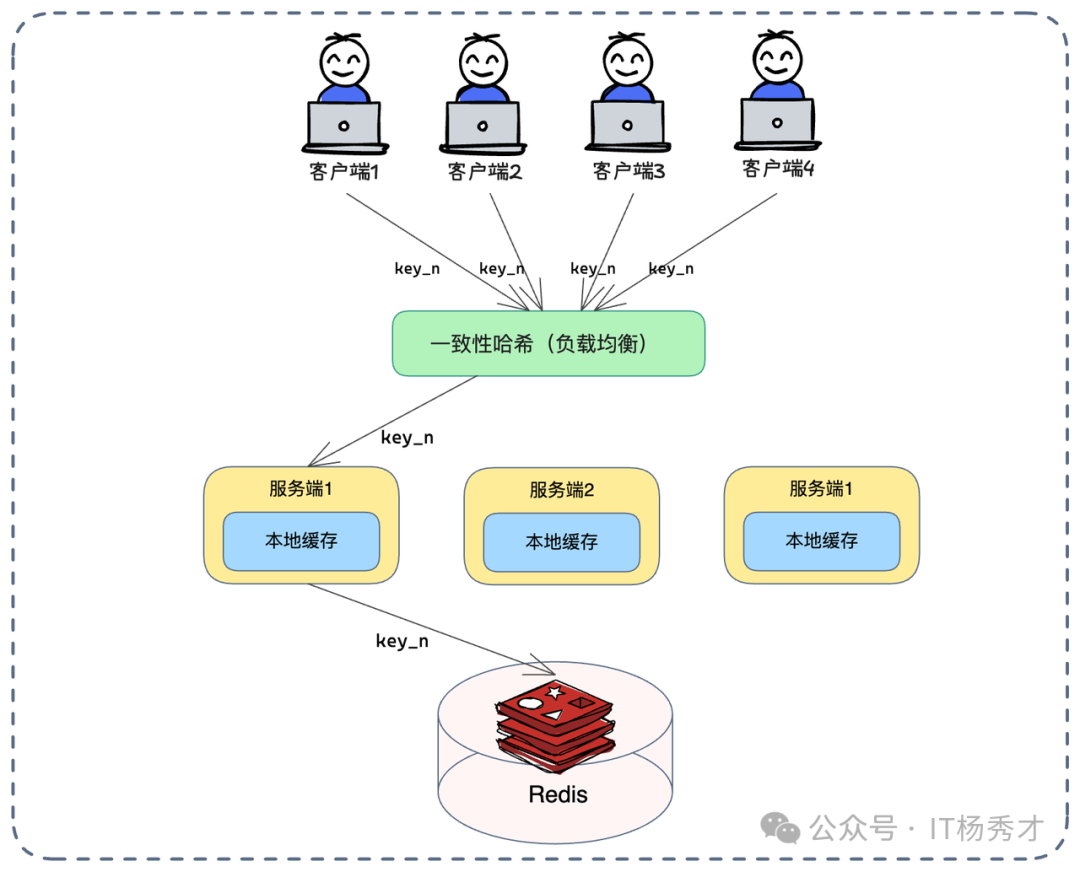
如上图所示,方案精髓在于流量调度:
- 流量定向:通过一致性哈希算法,确保对同一个业务 Key(如
product_id)的请求,总是路由到后端的同一台服务节点。
- 多级读取:服务端先查本地缓存。由于请求被“钉”在特定机器,热点数据的本地缓存命中率得到极大保障。
- 逐级回源:本地缓存未命中时,才查 Redis,最后是数据库。
- 回写策略:获取数据后,优先回写本地缓存,再异步或同步更新 Redis。
实战效果:经过改造,接口性能提升约 40%。一致性哈希不仅解决了命中率问题,还大幅减少了服务器间的冗余缓存。
注意点(面试加分项):主动谈到节点变动风险。服务节点扩容或缩容时,一致性哈希环发生漂移,导致部分 Key 路由到新机器,本地缓存失效,瞬间产生回源压力。需评估瞬时冲击并准备预案(如哈希环的虚拟节点优化)。
方案二:本地缓存兜底(高可用场景)
接下来看高可用场景。常规思维中,本地缓存是 Redis 的前置,为了更快。但在极端场景下,本地缓存可作为 Redis 的“备胎”用于保命。
通常防止 Redis 挂掉会搭集群或准备备用实例。但实际上,应用服务器自身的内存也是一种极佳的容错资源。方案核心思想:正常情况下,请求只走 Redis;只有当 Redis 崩溃时,才启用本地缓存。
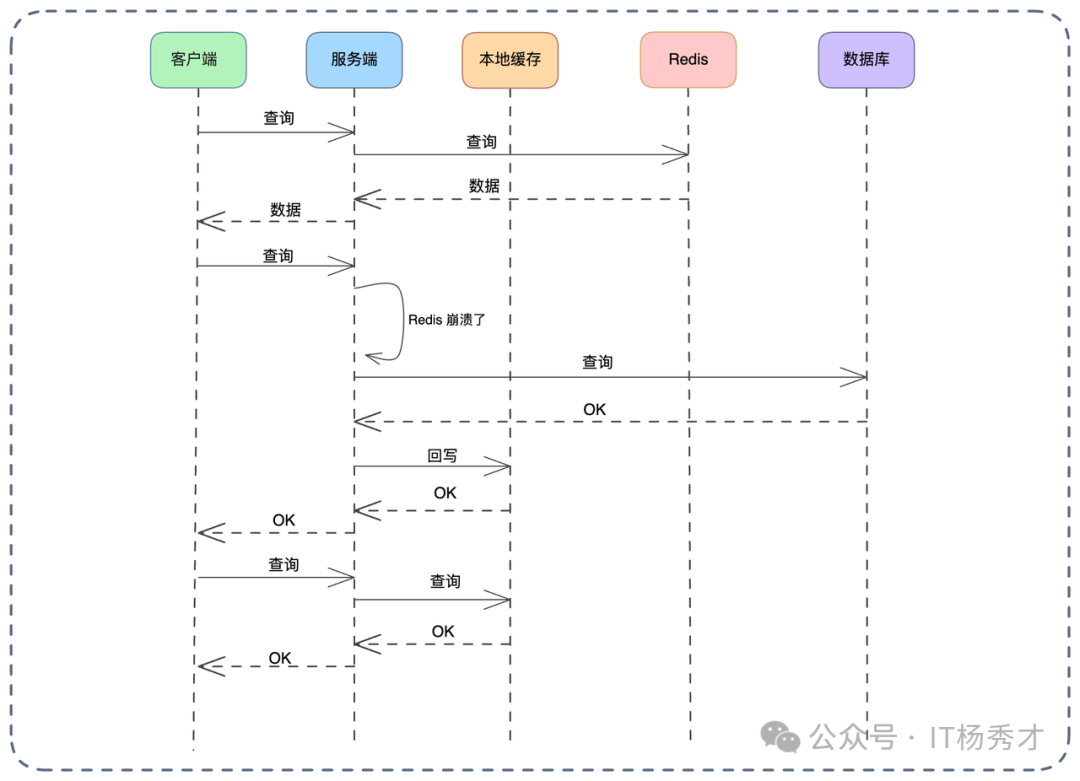
上图描述了 Redis 崩溃前后的切换逻辑:
正常状态(Normal State):
- 客户端查询,服务端直接请求 Redis。
- Redis 无数据则查库并回写。
- 关键点:此时本地缓存处于“休眠”状态,不参与核心读写链路,避免维护复杂的双重缓存一致性。
降级状态(Degraded State):一旦监控检测到 Redis 崩溃或连接超时,系统触发降级开关,查询逻辑翻转:
- 优先查本地:请求不再发往 Redis,优先查询本地缓存。
- 兜底查库:本地缓存没有,则查数据库。
- 回写本地:将数据库结果回写到本地缓存。
此方案“反其道而行之”,通常我们先查本地再查 Redis。但在此场景下,本地缓存的作用是保护数据库。当 Redis 突然不可用,海量 QPS 瞬间击穿数据库可能导致宕机。启用本地缓存,虽可能面临数据时效性问题(数据可能是旧的),但能挡住绝大部分流量,保住系统。
复原机制(Recovery):当 Redis 恢复后,不能立刻切回所有流量,因为 Redis 可能是空的(冷启动)。正确做法是:
- 灰度切流:逐步将流量转发回 Redis。
- 预热:或在切流前,异步将热点数据刷入 Redis。
方案三:请求级别缓存
有时性能损耗源于代码结构的“过度解耦”。在微服务设计中,我们强调边界。例如一个电商下单流程,涉及订单模块、支付模块和库存模块。这三个模块封装良好,都可能需要根据 user_id 获取用户信息(如用户等级)。
优化前的问题:
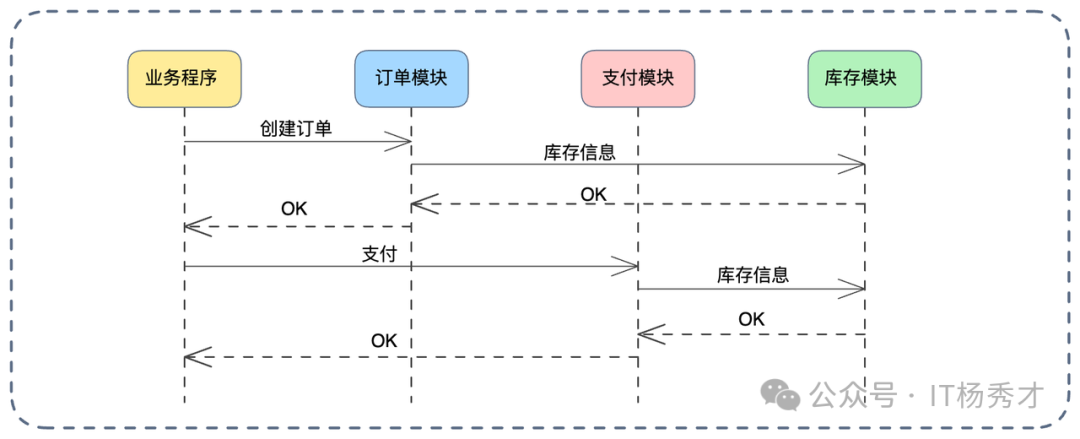
若无特殊处理,如上图所示:
- 订单模块调用一次用户服务。
- 支付模块又调用一次。
- 库存模块可能还要调一次。
同一请求链路中,同一份数据被重复查询三次,累积造成资源浪费和延迟。
优化后的方案:引入请求级别缓存(Request-Scope Cache)。其生命周期极短,仅存在于当前 HTTP 请求处理过程中,请求结束即销毁。
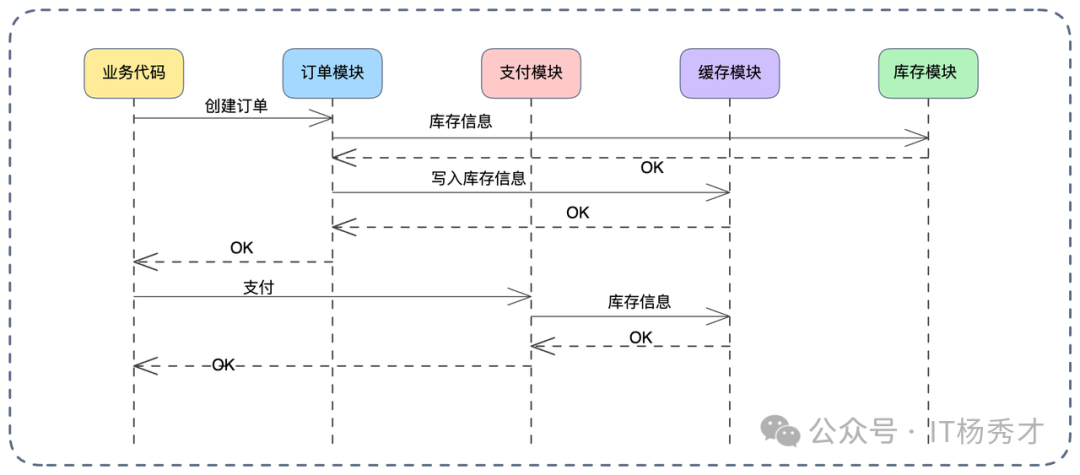
看上图改进流程:
- 构建上下文:请求进入时,利用 Java 的
Request-Scope Bean(Spring 支持)或 Go 的 context 存储临时数据。
- 一次查询,多次使用:订单模块首次查询用户信息后,将结果放入请求上下文缓存。
- 后续复用:支付模块等再需要用户信息时,直接从上下文中读取。
方案优势:最大优势在于几乎无需考虑数据一致性。缓存生命周期仅几百毫秒,期间数据变更影响业务的概率极低。这是一种低成本高收益的代码级优化。
方案四:会话级别缓存
将缓存生命周期拉长,就变成会话级别缓存。类似 Web 开发中的 Session,只要用户未退出或会话未过期,缓存数据就有效。此方案特别适合读取高频、修改极低频的数据,如用户的权限信息(RBAC)。
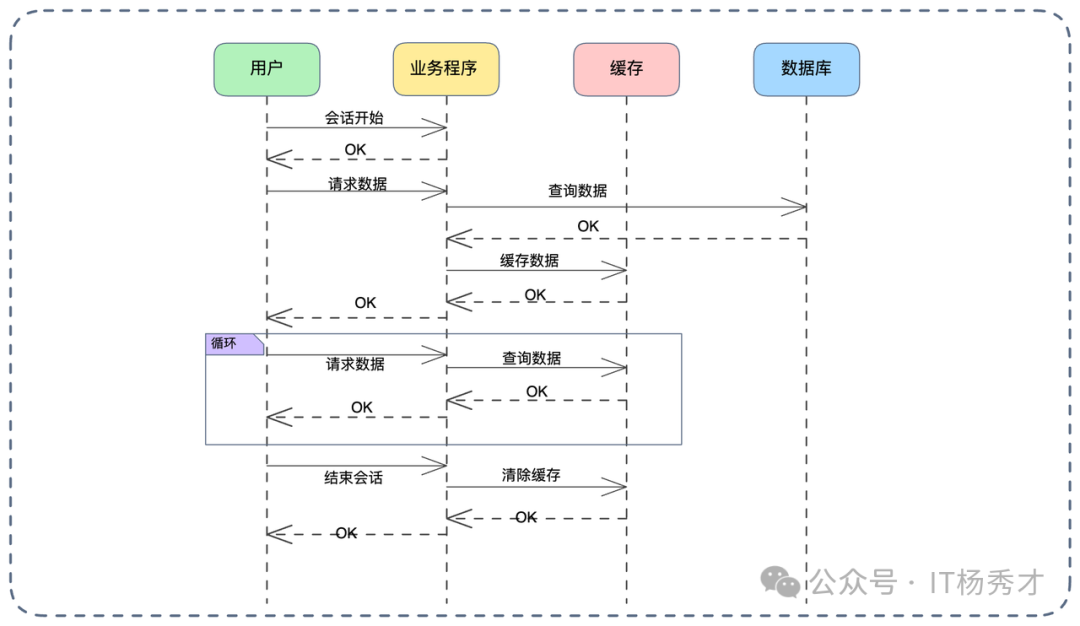
在一个后台管理系统优化案例中,鉴权逻辑频繁,但用户权限在一次登录会话期间几乎不变。我们引入会话级别缓存:
- 缓存建立:用户登录后,将其权限列表加载到会话缓存中(可以是服务端 Session 或 Redis 中的 Session 结构)。
- 读取:系统鉴权时优先从会话缓存读取,不存在时才调用权限模块。
- 一致性维护:监听“用户权限修改”消息队列。一旦管理员在后台修改权限,消费者直接强制清空该用户的会话缓存,迫使其下次操作时重新加载最新数据。
方案五:去中心化——客户端缓存
在微服务架构中,通常由服务端缓存数据。但若调用某个微服务的网络开销大,或对一致性要求不高,可考虑将缓存前置到调用方(客户端)。
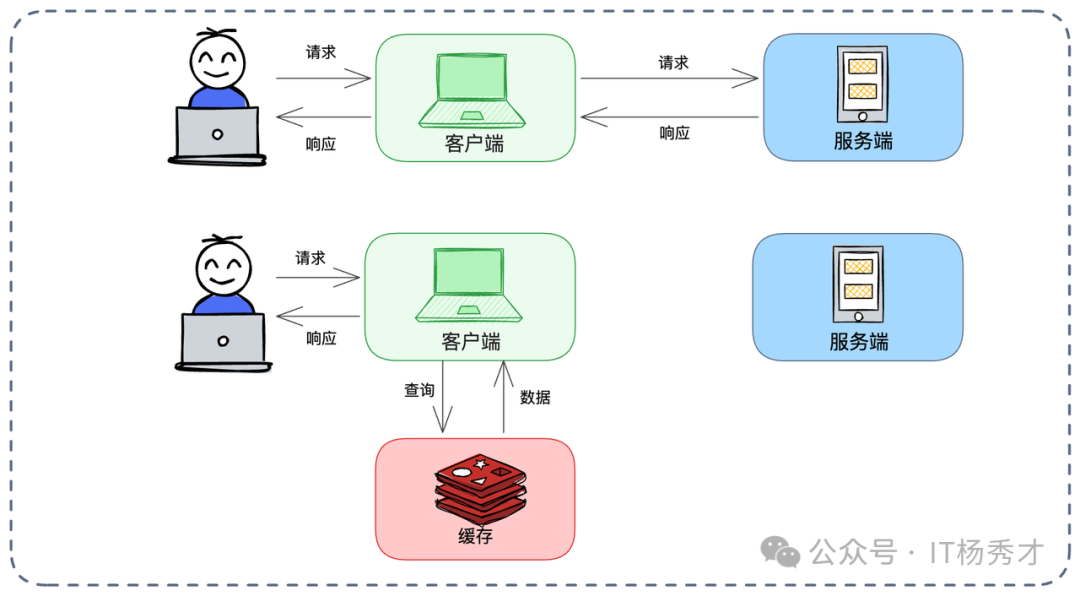
思路很简单:例如服务 A 需频繁调用服务 B 查询“商品详情”。服务 A 拿到数据后,将其缓存在本地内存中,设置较短过期时间(如 1 分钟)。下次需要时直接读本地,省去一次微服务调用的网络开销。
客户端缓存的独特优势:隔离性

如果共用服务端的 Redis 缓存,可能出现“吵闹的邻居”现象:
- 服务 B 流量大,疯狂写入数据。
- Redis 的 LRU 淘汰策略被触发。
- 结果把服务 A 需要的热点数据“挤”出去。
- 服务 A 访问热数据却总无法命中缓存。
而服务 A 使用客户端缓存,数据存在自己内存,淘汰策略完全自主,不受其他业务方影响。
痛点与反范式设计:
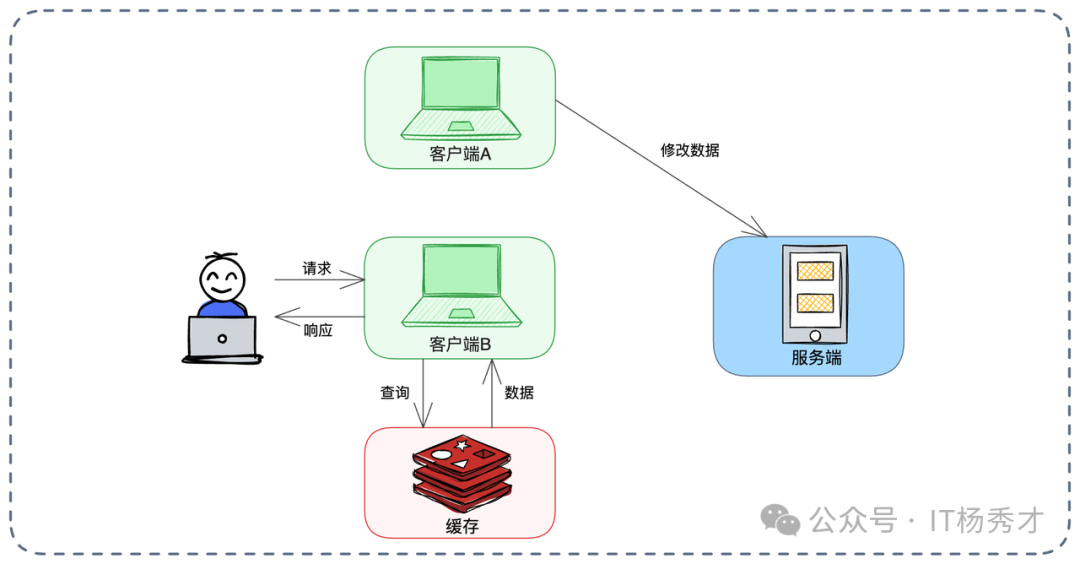
客户端缓存最大痛点是感知不到数据变更。如上图,其他客户端修改了数据,服务端已更新,但当前客户端缓存里还是旧值。
为解决此问题,可采用 “服务端依赖管理的客户端缓存” 模式。
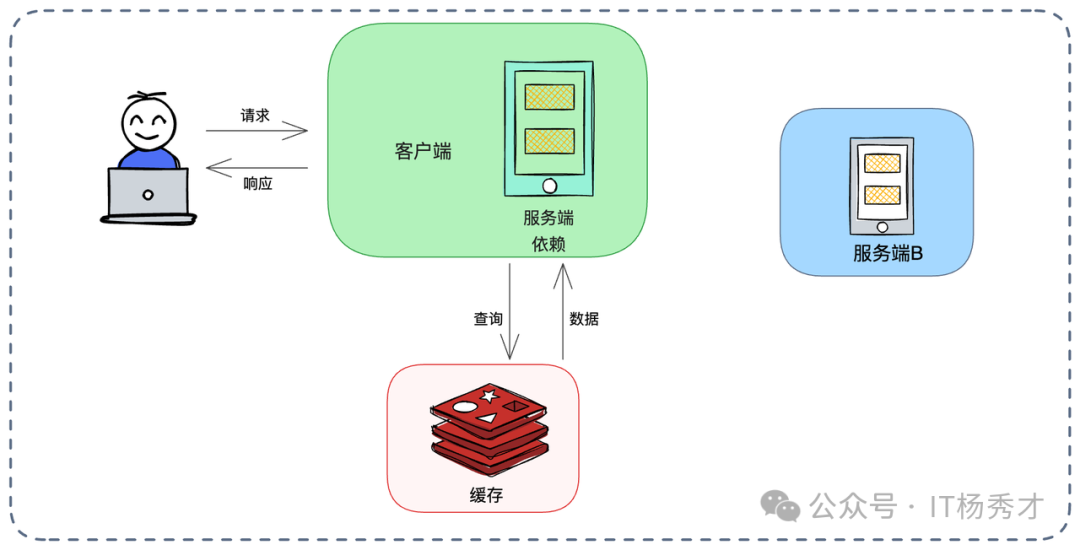
如上图,作为服务提供方(服务 B),可封装一个包含缓存逻辑的 SDK 给调用方(服务 A)使用。
- SDK 内部包含查询缓存、回源调用服务 B 的逻辑。
- 更高级做法是,SDK 内部订阅服务 B 的数据变更消息。当服务 B 数据变化时,发消息给 SDK,SDK 主动失效服务 A 本地的缓存。
这样既保留客户端缓存的性能优势,又由服务端控制逻辑统一性。
方案六:关联缓存预加载
这是一种“未雨绸缪”的高级策略:业务相关缓存预加载。需要对业务流程有深刻洞察。通常,用户执行操作 A 后,大概率会紧接着执行操作 B。利用此业务关联性,在处理 A 接口时,顺便把 B 接口需要的数据也加载到缓存中。
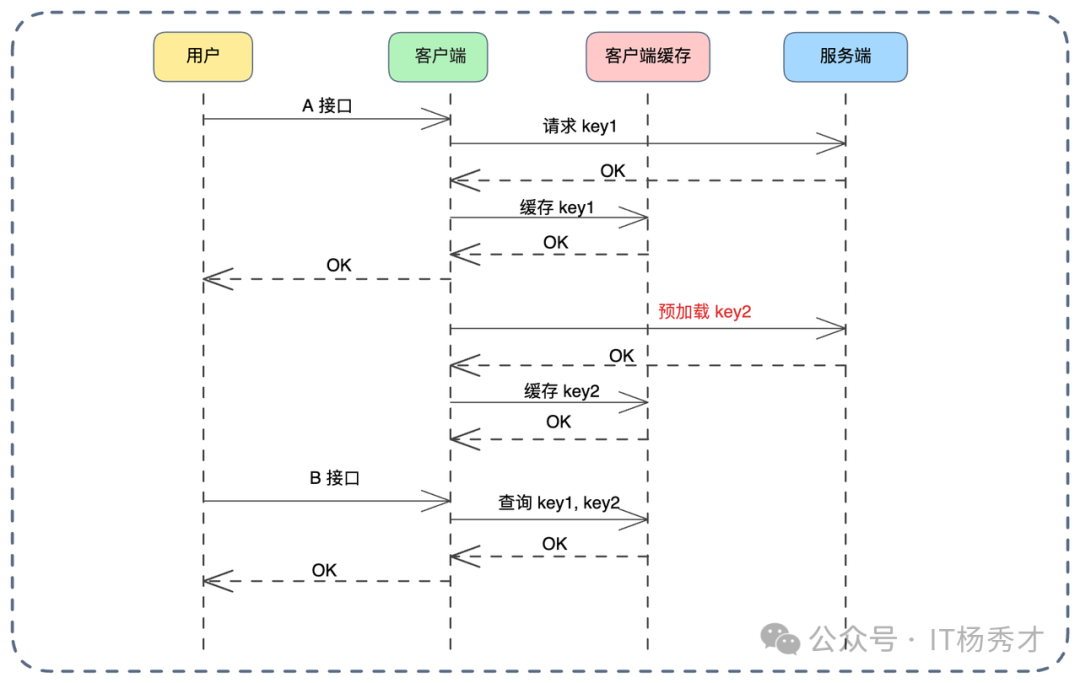
例如在电商场景,用户点击“提交订单”(接口 A),下一步大概率进入“收银台/支付页面”(接口 B)。
在处理“提交订单”接口时,除了完成订单创建,还可异步发起微服务调用,将该订单的支付详情、优惠券信息、支付渠道配置(图中的 Key2)等数据提前查询并放入缓存。当用户跳转到“支付页面”调用接口 B 时,数据已在缓存中,页面跳转极其顺滑。
当然,此方案可能造成一定资源浪费(用户万一没支付呢?),建议设置较短过期时间(如 5 分钟),既利用预加载优势,又控制资源消耗。
方案七:缓存预热与流量灰度
系统发布或重启时,本地缓存是空的。若立刻承接 100% 流量,大量请求会瞬间击穿缓存回源数据库,导致性能抖动甚至宕机。需引入缓存预热。
预热有两种思路:
- 启动加载:在应用启动阶段,主动加载配置类、字典类等热点数据。
- 流量灰度(基于权重的预热):更平滑的做法。
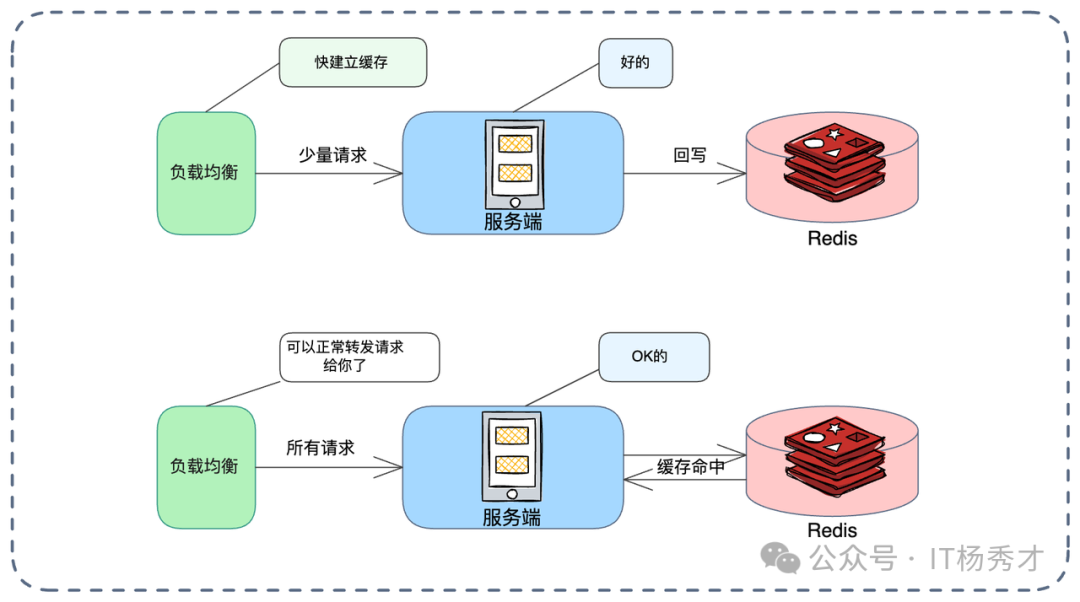
如上图,利用负载均衡器的权重机制:
- 冷启动阶段(图示上方流程):新节点刚启动时,将其权重调低(分配少量请求)。
- 温热阶段:少量请求让本地缓存逐渐建立,节点开始“热”。
- 全量阶段(图示下方流程):通过自动化脚本或注册中心心跳,逐步调高权重至 100%,承担正常流量。
这在面试中是一个很好的结合点,它将缓存话题自然引申到负载均衡策略,体现了你的架构全局观。
小结
说到底,缓存从来不是“上个 Redis 就完事”的组件,而是一套围绕流量削峰、延迟优化与高可用兜底的系统工程。成熟的方案,一定是多级缓存协同、本地与远程互补、预热与降级并存,在一致性、性能与复杂度之间做取舍。面试官想考察的,以及真实业务场景需要的,从来不是某个 API,而是当流量暴涨或节点故障时,你能否用一整套架构思维稳住系统——把缓存当成体系去设计,系统才扛得住真实世界的高并发冲击。更多关于系统设计与高可用的深度讨论,欢迎在云栈社区与同行交流。
 发表于 2026-1-31 16:44:45
|
查看: 181|
回复: 0
发表于 2026-1-31 16:44:45
|
查看: 181|
回复: 0
