
近期,在备受关注的代码修复基准测试SWE-bench Verified榜单上,Trae国际版取得了70.6%的求解率。这一成绩在Claude 4模型发布前夕达到了当时的高点,目前仍仅次于Claude 4结合工具使用的表现。本文将深入分享我们为实现这一目标所进行的实验过程与方法论,也期待未来能持续突破。
单次补丁生成
我们为执行修复任务的智能体(Agent)配备了四种核心工具:
- str_replace_editor:使Agent能够浏览文件、编辑代码。
- Bash:允许Agent执行任意Shell命令。
- ckg_tools:为代码库构建知识图谱,支持高效的类搜索(
search_class)和函数搜索(search_function)操作。
- sequential_thinking_tool:辅助Agent进行分步的逻辑推理。
我们首先对比了不同大语言模型在“单次尝试、端到端生成补丁”这一场景下的表现。实验结果(图1)清晰地展示了各模型的能力差异:
- Claude 3.7 Sonnet 的求解率在 60.6% 到 62.6% 之间。
- Gemini 2.5 Pro 0506 的求解率在 52.4% 到 55% 之间。
- OpenAI o4 mini 的求解率在 54.4% 到 55.8% 之间。
因此,在单次机会的端到端求解中,模型的性能排序为:Claude 3.7 Sonnet > OpenAI o4 mini > Gemini 2.5 Pro 0506。
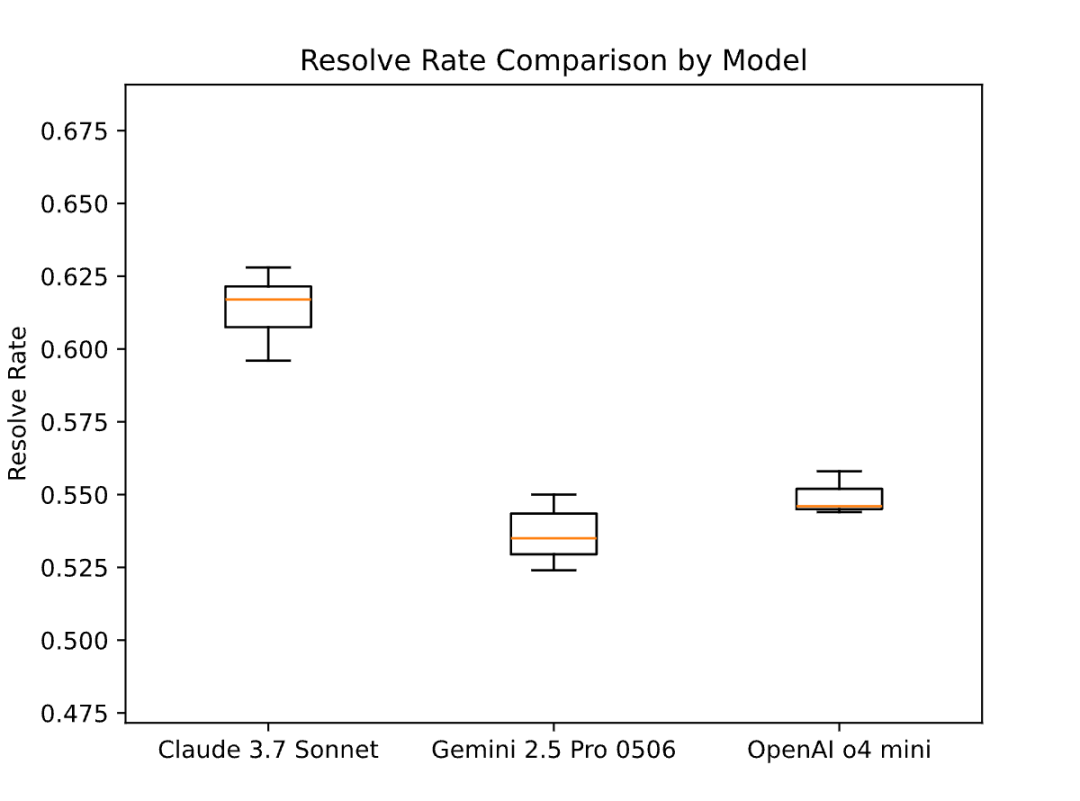
图1:不同模型在单次补丁生成任务上的求解率(Resolve Rate)对比
多次采样的补丁选择
单次生成的性能存在天花板,为了进一步提升成功率,我们探索了基于多次采样的选择策略。
LLM-as-a-Selector 初探
我们首先尝试了一种较为直接的选择方法。该方法集成了类似“Agentless”的回归测试模块,未通过回归测试的候选补丁会被直接过滤。随后,我们借鉴了 Agument Code 等开源项目的思路,使用 OpenAI o1 模型作为“选择器”从剩余的补丁中挑选最终答案,这种方法被称为“LLM-as-a-Selector”。
图2展示了随着采样空间(候选补丁数量)增大,LLM-as-a-Selector的成功率与理论最优率(Optimal Rate,即直接对所有补丁取并集)的变化趋势。我们从中观察到两个关键点:
- LLM-as-a-Selector 确实能超越单次生成的效果,这印证了“测试时扩展定律”(test-time scaling law)的存在。
- 然而,即使理论最优率在稳步上升,LLM-as-a-Selector的实际效果在采样空间为5和6时达到顶峰后便开始下降。当采样次数达到8和9时,其表现甚至不如在采样空间为3或4时。这表明,随着候选补丁数量的增加,简单的LLM选择器可能难以做出最佳判断。
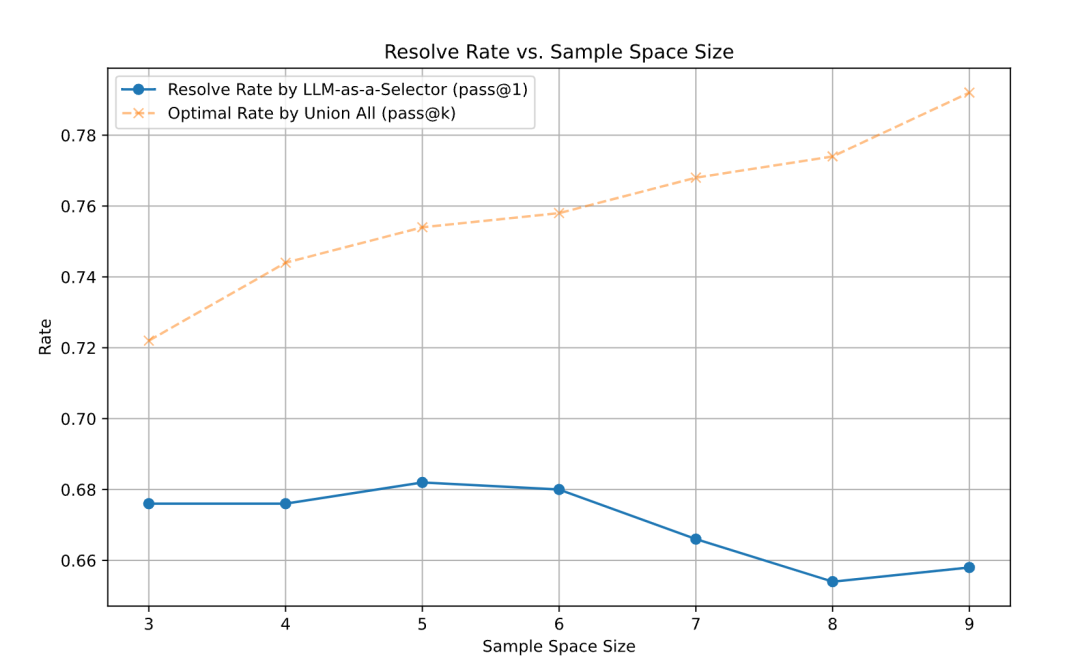
图2:LLM-as-a-Selector方法与理论最优率随采样空间增大的变化
基于上述发现,我们的新目标是在扩大采样空间的同时,设计一种更有效的选择机制,以维持甚至强化“测试时扩展定律”带来的收益。
Selector Agent:三阶段协同框架
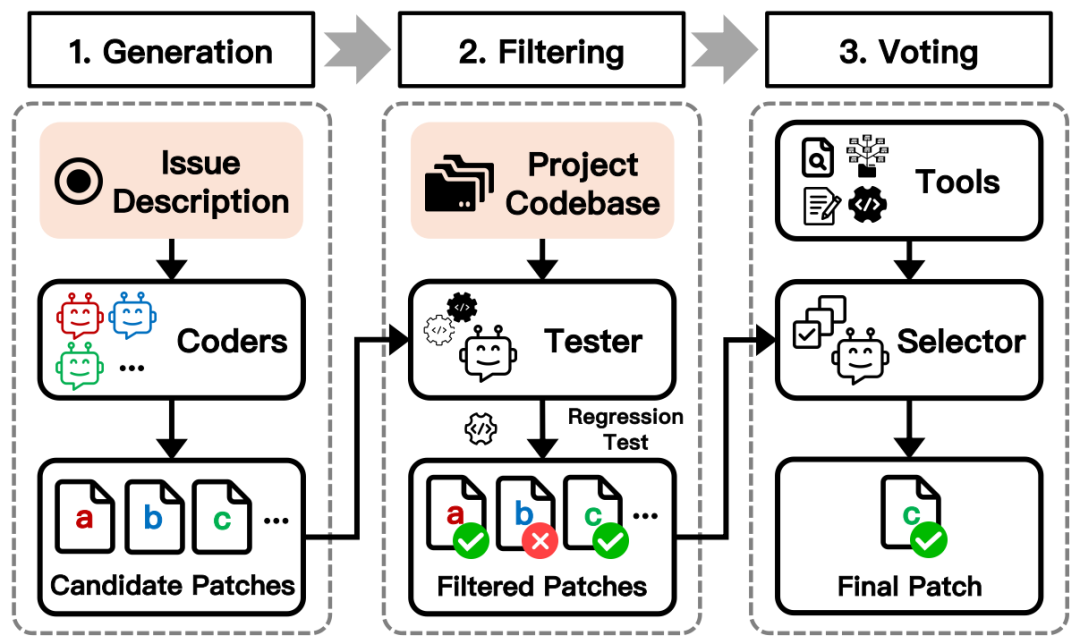
图3:包含生成、过滤、投票三阶段的总体框架
如图3所示,我们设计的方法主要包含三个阶段,其设计模式旨在通过分工协作提升整体效率与准确性:
-
生成阶段:在此阶段,我们利用多个“编码者智能体”(Coder agent)针对输入的Issue描述并行生成多样化的候选补丁。为了确保生成结果的多样性,我们同时使用了多种主流LLM(包括Claude 3.7 Sonnet、Gemini 2.5 Pro 和 o4 mini)作为Coder的核心模型。
-
过滤阶段:受Agentless启发,我们设计了一个“测试者智能体”(Tester agent),利用回归测试(regression test)来过滤掉无法通过基础测试的补丁。
- 具体流程是,Tester agent 会从项目代码库中自动检索出一部分与当前Issue解决相关的回归测试用例。我们严格遵守SWE-bench的提交要求,未使用任何隐藏的测试知识。
- 接着,Tester agent 会先用这些测试用例验证原始代码库,确保测试本身在原始环境下能正常运行。
- 最后,Tester agent 对所有候选补丁进行测试,剔除未通过全部回归测试的补丁,剩余补丁进入下一阶段。
- 需要说明的是,通过全部回归测试并不绝对等同于补丁正确,反之亦然。但在我们的实验中,能通过全部回归测试的补丁具有更高的正确概率,因此我们采用了这一过滤策略。如果所有候选补丁均未通过测试,则它们全部进入下一阶段。
-
投票阶段:过滤后的候选补丁被提交给“选择器智能体”(Selector agent),由其决定最终的输出。Selector agent内部的工作流程更为精细,如图4所示。
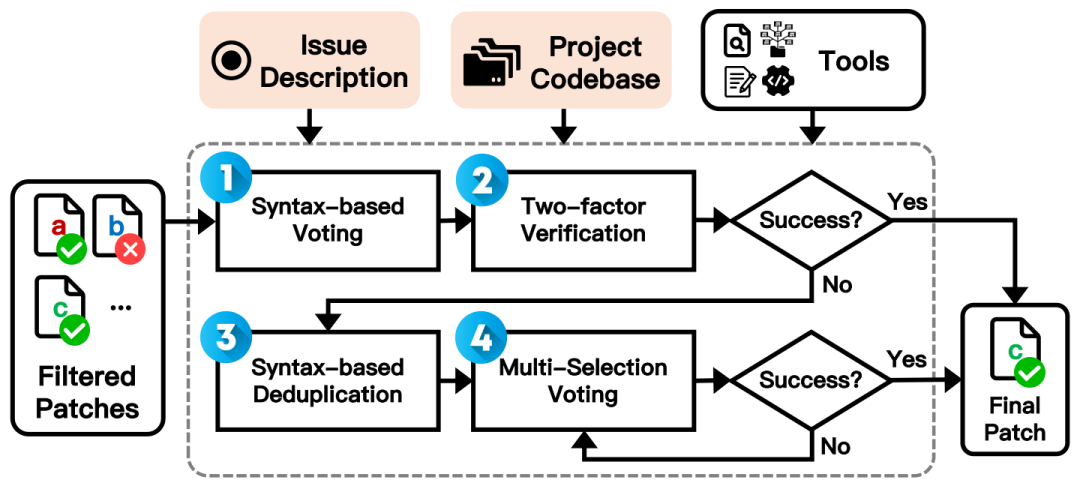
图4:Selector Agent内部基于语法投票和多选投票的详细决策流程
-
基于语法的投票:Selector agent首先执行基于语法等价性的投票。它将所有候选补丁分别应用到原始代码库,得到更新后的代码,然后利用程序分析工具tree-sitter将其转换为抽象语法树(AST)并移除注释。接着,根据AST的等价性对补丁进行聚类,选择聚类规模最大(即被最多Coder以严格语法等价方式生成)的补丁作为潜在解决方案。这种“共识”通常意味着更高的正确性概率。随后,Selector agent会利用问题描述、代码库上下文以及所有工具,对这个“共识补丁”进行双重验证。如果验证通过,则直接将其作为最终补丁输出。
-
多选投票:如果基于语法的投票未能产生一个能通过双重验证的确定结果,则进入多选投票模块。首先,利用上一步生成的AST对剩余候选补丁进行去重,仅保留语法不等价的补丁,这既能减少选择偏差,也能控制输入令牌长度。接着,部署多个Selector agent实例,每个实例从去重后的补丁集中独立选出其认为最可能正确的一个。最后,综合所有Selector agent的投票,选出得票最高的补丁作为最终结果。
结果:我们构建的这一多智能体协同框架,成功地将SWE-bench Verified的整体求解率提升至70.6%。更令人期待的是,该框架具备良好的扩展性——随着底层单个大模型求解率的提升,整个系统的性能还有望进一步增长。
下一步工作
我们的后续研究将聚焦于以下几个方向,并乐于在云栈社区与大家交流这些开源实战中的心得:
- 提升单次修复成功率:探索增强Agent在单次尝试中独立、准确解决问题的策略。
- 扩展采样空间:研究继续增大采样空间是否有助于模型发现更多潜在的正确答案。
- 选择器Agent优化:针对大规模样本空间,进一步优化Selector Agent的判别性能,使其能更精准地定位最佳补丁。
在FSE与ACL会议上的交流
我们将在FSE 2025会议上展示论文《AEGIS: An Agent-based Framework for General Bug Reproduction from Issue Descriptions》,并于6月27日组织一场 AI-IDE workshop。与会者可以在注册处附近找到我们的展台进行交流。
此外,我们的文章《SoRFT: Issue Resolving with Subtask-oriented Reinforced Fine-Tuning》已被ACL 2025主会接收,我们将在维也纳举行的ACL会议上展示这项工作。欢迎对软件工程与强化学习交叉领域感兴趣的学者前来探讨。
相关链接
|  发表于 2026-1-31 16:41:05
|
查看: 222|
回复: 0
发表于 2026-1-31 16:41:05
|
查看: 222|
回复: 0
