Docker 已然成为构建现代大型应用架构的必备技能。它远不止是一个简单的打包工具,其背后是一套精巧的Linux内核技术组合。今天,我们就深入内核层面,详解构成Docker容器的三大核心技术支柱。
许多初学者的一个常见误解是,Docker在“虚拟一台机器”。实际上,它并没有创建完整的虚拟机,而是巧妙地利用了Linux内核已有的能力,将一组进程“隔离”起来,并为其挂载一套特殊的文件系统。这种轻量级的实现方式,正是Docker高效率的根源。
Namespaces:进程视图隔离的基石
Namespace 提供了内核级别的资源视图隔离。它的作用是为容器内的进程创造一个“独立的视觉世界”,让它们看不到宿主机或其他容器的特定资源,从而实现安全边界。主要包括以下几种类型:
- PID Namespace: 隔离进程ID,容器内可以有自己独立的进程树,其PID 1进程在宿主机上可能对应着另一个PID。
- NET Namespace: 隔离网络设备、IP地址、端口、路由表等,每个容器拥有独立的网络栈。
- MNT Namespace: 隔离文件系统挂载点,容器内对文件系统的改动不会影响宿主机。
- UTS Namespace: 隔离主机名和域名。
- IPC Namespace: 隔离进程间通信资源,如信号量、消息队列和共享内存。
- User Namespace: 隔离用户和用户组ID,允许在容器内以root身份运行进程,而在宿主机上映射为普通用户。
通过将进程绑定到独立的Namespace,容器实现了进程间的有效隔离。例如,你在容器内执行 ps aux,看到的只会是容器内部的进程,而不是宿主机上成百上千的进程。
Control Groups (cgroups):资源的看守者
仅有视图隔离还不够,如果某个容器内的进程疯狂消耗CPU或内存,依然会拖垮整个宿主机。这时就需要 cgroups(控制组) 出场了。
cgroups 用于对进程组使用的系统资源进行限制、分配、统计和控制。它可以精细化管理以下资源:
- CPU: 限制CPU使用时间份额或绑定到特定CPU核心。
- Memory: 限制内存使用量,包括物理内存和交换空间。
- Blkio: 限制块设备(磁盘)的I/O带宽。
- Network: 限制网络带宽(通常结合TC实现)。
借助cgroups,运维人员可以为每个容器设定明确的资源上限(如 --memory=500m),确保多个容器共享宿主机资源时的公平性与稳定性,防止因单个容器异常导致系统雪崩。
联合文件系统 (UnionFS) 与镜像分层:高效的基石
Docker 的镜像为何如此轻量,且能实现秒级启动?奥秘就在于 联合文件系统(Union File System,如 Overlay2、AUFS) 和镜像分层机制。
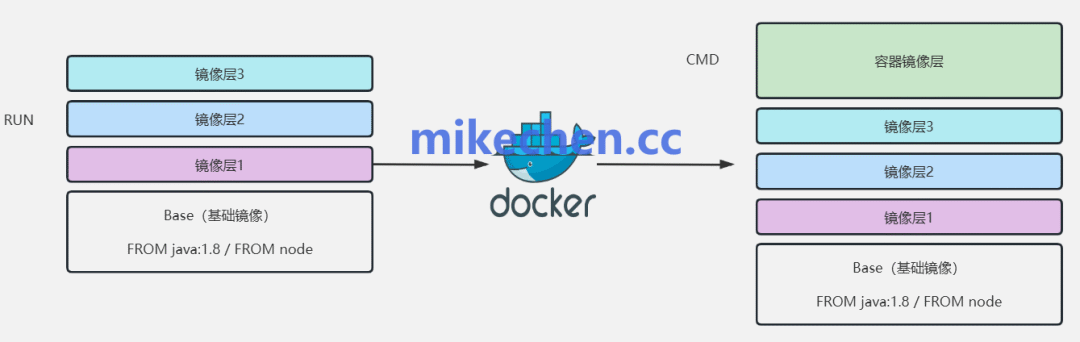
一个Docker镜像由一系列只读层(Layer) 叠加而成,每一层对应Dockerfile中的一条指令(如 FROM, RUN, COPY)。
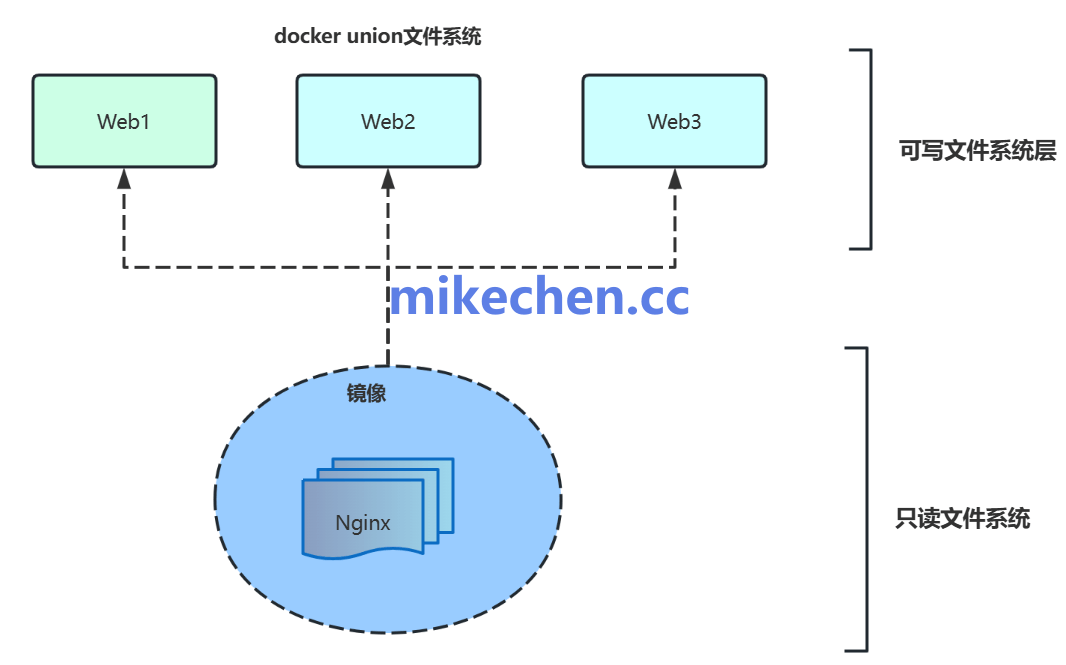
这种设计带来了巨大优势:
- 写时复制 (Copy-on-Write): 当容器启动时,Docker会在只读的镜像层之上添加一个可写的“容器层”。所有对文件的修改都发生在这个可写层,底层镜像内容保持不变。这极大节省了空间,因为所有容器共享相同的基础镜像层。
- 高效构建与传输: 构建镜像时,如果某层及之前的内容未改变,则直接使用缓存,加速构建。拉取镜像时,只需下载本地缺失的层,复用已有层。
- 易于管理: 分层结构使得镜像的版本管理、回滚和分享变得非常清晰和高效。
三者如何协同工作?
现在,让我们把这三项技术串联起来,看看一个Docker容器是如何诞生的:
- 镜像准备:当你执行
docker run 时,Docker首先检查本地是否有指定的镜像。镜像本身就是一个由UnionFS组织的多层只读文件系统。
- 创建容器层:Docker在镜像顶层创建一个新的可写层(容器层)。
- 分配Namespace:Docker调用内核API,为即将运行的进程创建一组独立的Namespace(PID, NET, MNT等)。
- 设置cgroups:Docker根据命令参数(或默认配置)创建cgroups,并设置好CPU、内存等资源限制。
- 启动进程:最后,Docker在准备好的隔离环境(Namespace)和资源限制(cgroups)下,启动指定的应用程序进程。这个进程看到的是由UnionFS提供的、包含底层只读镜像和顶层可写层的完整文件系统视图。
至此,一个轻量、隔离、资源受限的“容器”就运行起来了。它没有虚拟硬件,而是通过Namespace拥有了独立的视角,通过cgroups被限制了资源消耗,并通过UnionFS获得了一个高效、可分层的文件系统。理解这底层原理,能帮助开发者更好地设计应用、排查故障和优化性能。
|  发表于 2026-1-31 16:37:18
|
查看: 154|
回复: 0
发表于 2026-1-31 16:37:18
|
查看: 154|
回复: 0
