
Anthropic 推出了「Claude 认证架构师(Foundations)」认证,旨在考察开发者使用 Claude Agent SDK、Claude Code、模型上下文协议等核心工具构建生产级应用的能力。这场考试满分 1000 分,及格线为 720 分,但其报名门槛却让不少开发者望而却步:你必须得是 Claude 的官方合作伙伴。
这引发了一个有趣的现象。一位名叫 @hooeem 的开发者在社交媒体上分享了他的做法:他并没有纠结于如何获得考试资格,而是直接将官方发布的考试指南彻底拆解,提炼出其中真正具有学习价值的知识体系,整理成一份详尽的学习路线图并免费公开。他的逻辑很清晰:证书或许只属于合作伙伴,但构建应用的知识与能力应该对所有人开放。只要你掌握了考试所要求的内容,实质上就已经具备了开发生产级 Claude 应用的能力。
下面,我们就来梳理这份由社区开发者整理的精华,看看这场“高门槛”认证究竟在考察什么,以及如何系统地掌握这些技能。
考试考什么?五大核心领域剖析
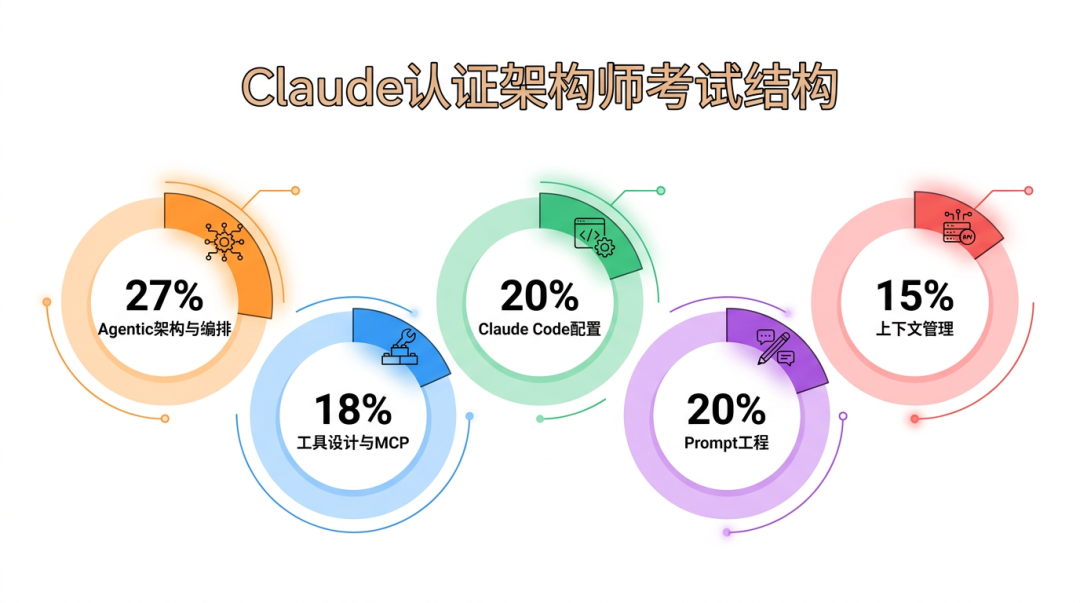
整个认证体系紧紧围绕五个核心领域展开,每个领域在考试中的权重各不相同:
| 领域 |
占比 |
核心技能 |
| Agentic 架构与编排 |
27% |
Agent 循环、多 Agent 协作、Session 管理 |
| 工具设计与 MCP 集成 |
18% |
工具描述优化、结构化错误、MCP 配置 |
| Claude Code 配置与工作流 |
20% |
CLAUDE.md 层级、自定义命令、CI/CD 集成 |
| Prompt 工程与结构化输出 |
20% |
少样本学习、JSON Schema 提取、批处理 |
| 上下文管理与可靠性 |
15% |
信息保留、升级触发、错误传播 |
这五个领域共同覆盖了六种典型的实战场景:客户支持 Agent、代码生成助手、多 Agent 研究系统、开发者效率工具、CI/CD 流水线自动化以及结构化数据提取任务。
领域一:Agentic 架构与编排 (占比27%,重中之重)
这是整个考试权重最高的部分,也是开发者最容易产生误解的地方。
最常见的三个设计错误:
- 依赖自然语言判断循环终止:例如,检查 Claude 的输出是否包含“我完成了”之类的语句。这是不可靠的。正确的做法是依赖 API 返回的
stop_reason 字段作为终止信号。
- 将循环次数上限作为主要停止机制:例如“最多执行10次循环”。这会导致两种问题:要么在有用工作完成前被强行中断,要么在任务完成后空跑多余循环。
stop_reason 才是权威信号。
- 假设子Agent自动继承上下文:认为子 Agent 能自动看到协调 Agent 的全部对话历史。实际上,每个子 Agent 都运行在完全隔离的上下文中,所有需要它知晓的信息都必须显式地通过 Prompt 传递进去。
构建多 Agent 系统的核心规则:
- 中心辐射式架构:采用一个协调 Agent 作为中枢,所有子 Agent 只与它通信,彼此之间不直接对话。协调 Agent 负责任务分解、上下文传递、结果聚合以及统一错误处理。
- 记忆隔离:子 Agent 不共享记忆。协调 Agent 需要精心设计传递给每个子 Agent 的 Prompt,确保包含完成任务所必需的全部信息。
安全关键场景:用 Hooks,而非 Prompt
当操作涉及财务、安全或合规性时,仅靠 Prompt 指令存在失败的风险(即使指令写得再好)。在这种场景下,应该使用程序化的 Hook(例如前置条件检查、工具调用拦截)来强制执行规则,而不是依赖模型的概率性判断。简单来说,Hook 提供的是确定性保障,而 Prompt 只是概率性引导——这个关键区别在考试中会被反复测试。
领域二:工具设计与 MCP 集成 (占比18%)
工具描述的质量至关重要
模型选择调用哪个工具,主要依据就是工具的描述。描述模糊或工具间描述重叠,会导致模型选择错误。
考试中有一个典型例子:get_customer 和 lookup_order 两个工具,如果描述都是“获取[实体]信息”,Agent 就经常用错。修复方法不是添加少样本示例或复杂路由,而是把描述写清楚:明确这个工具具体能干什么、接受什么格式的输入、在什么场景下应该用它而非其他工具。这是成本最低、效果最显著的优化手段。
控制工具数量
为每个子 Agent 分配 4-5 个与其角色紧密相关的工具是最佳实践。给单个 Agent 塞入 18 个工具会显著降低模型选择的可靠性。
掌握 tool_choice 的三种模式
"auto":模型自行决定是否调用工具,也可能直接返回文本。"any":模型必须调用工具,但具体调用哪个由它选择。{"type": "tool", "name": "xxx"}:强制模型调用指定的工具,常用于标准化工作流的第一个步骤。
MCP 配置的层级管理
- 项目级 (
.mcp.json):纳入版本控制,确保团队所有成员配置一致。
- 用户级 (
~/.claude.json):属于个人配置,不共享。
一个新加入的团队成员不会自动获得用户级配置——这是考试中常见的陷阱。务必确保团队协作所需的配置都放在项目级文件中。
领域三:Claude Code 配置与工作流 (占比20%)
这部分区分了“用过 Claude Code”和“真正会配置 Claude Code”的开发者。
CLAUDE.md 的三层配置体系
- 用户级 (
~/.claude/CLAUDE.md):仅对当前用户生效,不纳入版本控制。
- 项目级 (
.claude/CLAUDE.md):对该项目的所有协作者生效,必须纳入版本控制。
- 目录级 (子目录下的
CLAUDE.md):仅在该目录及其子目录下生效。
如果新团队成员抱怨没收到某些指令,很可能是你把指令错误地放在了用户级而非项目级配置里。
被低估的功能:路径特定规则
在 .claude/rules/ 目录下,可以使用 YAML frontmatter 配合 glob 模式来定义规则。例如,一条针对 **/*.test.tsx 的规则,可以让你对所有测试文件统一应用代码规范,无论它们分散在多少个目录中。这比在每个目录下单独配置要高效得多。
计划模式 vs. 直接执行
- 计划模式:适用于大规模重构、多文件迁移、架构决策等复杂场景,先探索方案再执行修改。
- 直接执行:适用于单文件 Bug 修复、范围明确且有限的改动。
CI/CD 集成必须记住的 flag
在自动化流水线中调用 Claude Code 时,务必加上 -p(非交互模式)标志。如果忘记加这个标志,CI 任务会一直挂起,等待用户输入。
提示:用同一个 Claude Code 会话生成代码后,立刻用它来评审这段代码,效果会打折扣——因为它还带着生成代码时的推理上下文,不利于进行批判性质疑。使用一个全新的、独立的会话进行代码评审,往往能发现更多问题。
领域四:Prompt 工程与结构化输出 (占比20%)
模糊指令无效,明确标准才行
考试反复验证了一点:像“保守一点报告”或“只报高置信度发现”这类模糊的置信度要求,并不能有效降低误报率。真正有效的方法是提供明确的标准,例如“仅当声称行为与实际代码行为存在矛盾时才报告”,并为每个严重等级配备具体的代码示例。
少样本学习是提升一致性的利器
提升模型输出一致性的最高效方法,往往不是写更长的指令,而是提供 2-4 个针对模糊边界场景的少样本示例。每个示例最好包含“为什么这样选择而不那样选择”的简要推理过程。模型从这些例子中学习泛化,而不是死记硬背规则。
tool_use + JSON Schema 能防格式错误,但防不了语义幻觉
JSON Schema 可以确保输出的数据结构符合预期,但无法阻止模型把值填错字段,或者对输入中不存在的信息进行“捏造”。防止幻觉的关键在于 Schema 的设计技巧:合理使用可空字段、设置 “unclear” 这类枚举值、或在固定选项外提供 “other” + 自由文本字段。
Batch API 的适用场景
- 优势:节省约50%成本,最长提供24小时处理窗口。
- 劣势:无延迟保证,不支持多轮工具调用。
- 适合场景:隔夜生成的报告、每周执行的审计任务。
- 不适合场景:代码合并前的检查、任何需要开发者同步等待结果的工作流。
领域五:上下文管理与可靠性 (占比15%)
这部分虽然权重最低,但其中涉及的问题会影响到所有其他领域。
渐进式摘要会“吃掉”关键细节
在对长对话历史进行压缩摘要时,像“用户要求退款 247.83 美元,订单号 8891,于3月3日下单”这样的关键信息,可能会被简化为“用户想退最近一笔订单的款”。解决方案是:将交易号、金额、日期等关键事实提取成独立的“事实块”,在每次请求中都原文带入,不参与摘要压缩过程。
警惕“迷失在中间”效应
模型对长输入的开头和部分处理得更可靠,埋在中间的关键信息容易被忽略。解决方法是将最重要的摘要或指令放在输入的开头,并用清晰的章节标题来分隔不同部分的内容。
有效的与无效的升级触发条件
- 有效的触发条件:
- 用户明确要求转接人工客服。
- 用户请求超出了既定的处理策略范围。
- Agent 尝试后确实无法推进问题解决。
- 应避免的触发条件:
- 情绪分析(用户沮丧不等于问题复杂)。
- 模型自我汇报的置信度(即使置信度高,模型也可能出错)。
如何系统学习?免费资源与路线
@hooeem 为上述每个考试领域都精心设计了专门的 Claude Prompt。你可以直接将这些 Prompt 粘贴给 Claude,让它扮演“该领域的专家讲师”,从基础知识一直讲到备考要点,并且每个知识点都配有实战场景练习。
此外,以下官方学习资源是构建知识体系的坚实基础:
核心总结
- 认证虽限,知识无界:Claude 认证架构师考试虽仅对合作伙伴开放,但其考核内容本身就是构建生产级 AI 应用的知识精华,完全值得所有开发者学习。
- 五大领域:重点掌握 Agentic 架构(27%)、工具与 MCP(18%)、Claude Code配置(20%)、Prompt工程(20%)和上下文管理(15%)。
- 关键心得:
- 子 Agent 记忆隔离,信息需显式传递。
- 安全关键逻辑用程序化 Hook,而非 Prompt 指令。
- 清晰的工具描述胜过复杂的路由分类器。
- CI/CD 集成时,别忘了
-p 标志。
- 最终目标:证书只是一张纸,真正理解并能在项目中应用这些架构与工程化思想,才是学习的根本目的。
对 AI 应用开发、Agent 架构设计感兴趣的朋友,可以来 云栈社区 的 人工智能 板块,与更多开发者一起交流 Claude、大型语言模型应用落地中的实战经验与 避坑指南。
参考链接
 发表于 2026-3-17 04:24:03
|
查看: 300|
回复: 0
发表于 2026-3-17 04:24:03
|
查看: 300|
回复: 0
