最近看到一篇技术文章,标题直击痛点:Stop turning everything into arrays[1]。作者核心观点是,我们写 JavaScript 时太习惯用 .map().filter().slice() 这种链式调用了。虽然代码看着优雅简洁,但每一步都在创建新数组,做了许多不必要的额外工作。
起初我也对此持怀疑态度,毕竟这种写法已经成了肌肉记忆,真的会产生如此大的性能损耗吗?于是,我动手写了一个测试脚本,在几组不同场景下进行对比实验,结果确实有些出乎意料。
传统数组方法的问题所在
让我们从一个典型场景说起:你有一个较大的数据列表,需要先筛选出符合条件的项,然后进行某种转换,最后只取前10条用于展示。
const visibleItems = items
.filter(item => item.active)
.map(item => ({ id: item.id, doubled: item.value * 2 }))
.slice(0, 10);
这段代码逻辑清晰,没什么毛病。但在实际执行时,它的工作流程是这样的:
filter 遍历整个数组,创建一个包含所有 active 项的新数组。map 再遍历一遍 filter 生成的新数组,又创建了一个包含转换后对象的新数组。slice 最后从 map 生成的数组中取前10条,再次创建一个新数组。
假设原始 items 有10万条数据,而你最终只需要10条。但前两步却已经将10万条数据处理并创建了两个庞大的中间数组。这就是 “急切求值” (eager evaluation) 的典型问题:不管后续是否真的需要全部结果,它都会先把所有活干完。
Iterator Helpers 是什么?
Iterator Helpers 是 JavaScript 引入的新特性,它提供了一套基于 “惰性求值” (lazy evaluation) 的方法。关键在于:
- 传统数组方法:每一步都立即执行,生成新的中间数组。
- Iterator Helpers:每一步只是描述一个操作,只有在真正需要数据时才会执行。
它的用法非常直观:
const visibleItems = items
.values() // 将数组转为迭代器 (iterator)
.filter(item => item.active)
.map(item => ({ id: item.id, doubled: item.value * 2 }))
.take(10) // 惰性操作,只“取”10条
.toArray(); // 最终触发执行,并转为数组
核心差异体现在:
items.values() 返回一个迭代器,而非数组。filter 和 map 只是为迭代器附加了转换逻辑,并未立即执行。take(10) 告诉处理管道,我们只需要10条数据。- 直到调用
toArray() 时,整个处理流程才真正开始执行,并且一旦收集到10条数据就会停止。
实测性能对比
为了客观比较,我设计了一个测试脚本,从时间和空间两个维度进行测量。每组时间测试重复10次取平均值,内存测试使用 Node.js 的 process.memoryUsage() API 来测量堆内存的增长。
场景一:过滤 + 转换 + 取前10项
数据规模:100,000 条
// 传统数组方法
dataset
.filter(item => item.active)
.map(item => ({ id: item.id, doubled: item.value * 2 }))
.slice(0, 10);
// Iterator Helpers
dataset
.values()
.filter(item => item.active)
.map(item => ({ id: item.id, doubled: item.value * 2 }))
.take(10)
.toArray();
结果:

这个结果相当惊人。Iterator Helpers 在时间上快了80多倍,内存使用更是只有传统方法的约0.3%。原因很直接:传统方法处理了全部10万条数据,并创建了2个中间数组;而 Iterator Helpers 在找到第10条符合条件的数据后就停止了,且完全不创建中间数组。
场景二:嵌套数据扁平化
数据规模:10,000 个父项,每个包含10个子项(共 100,000 条子数据)
// 传统数组方法
dataset
.flatMap(parent => parent.children)
.filter(child => child.value > 50)
.slice(0, 20);
// Iterator Helpers
dataset
.values()
.flatMap(parent => parent.children)
.filter(child => child.value > 50)
.take(20)
.toArray();
结果:
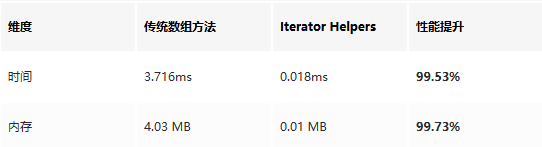
在 flatMap 场景下,优势更加明显。传统方法需要先将所有嵌套数据(10万条子项)展平为一个巨大数组,再进行过滤和切片,创建了2个中间数组。而 Iterator Helpers 可以在展平过程中进行过滤,并在满足数量要求时提前终止,内存消耗微乎其微。
场景三:查找第一个匹配项(公平对决)
数据规模:1,000,000 条
这个场景需要特别说明。很多对比测试会用 filter(...)[0] 来代表传统方法,但这并不公平。在实际开发中,大家都会直接使用 Array.find(),没人会先进行完整的 filter 遍历再取第一个元素。
因此,我们进行一场公平对决:Array.find() vs Iterator.find()。
// Array.find()(原生数组方法)
dataset.find(item => item.id === targetId);
// Iterator.find()
dataset.values().find(item => item.id === targetId);
我在数据的不同位置(头部、中部、尾部)测试了查找性能:
结果:

关键发现:
Array.find() 本身就是惰性的 —— 它在找到第一个匹配项时就会停止遍历。在这一点上,它并不需要 Iterator Helpers 来“拯救”。- Iterator 存在额外开销:每次迭代需要创建迭代器对象、调用
.next() 方法,这些开销在遍历大量数据时会累积起来。
- 头部查找时 Iterator 略快:这可能是因为数据量小,V8 引擎的即时编译优化策略产生了不同效果。
MDN 文档验证:
根据 MDN 官方文档[2],Array.find() 确实具备 短路求值 (short-circuit) 特性:
find() does not process the remaining elements of the array after the callbackFn returns a truthy value.
这意味着,Array.find() 和 Iterator.find() 在“找到即停”这一核心机制上是完全一样的。主要区别在于:
Iterator.find() 需要通过 .values() 将数组转换为迭代器,这会引入额外开销。- 只有在链式调用(例如
filter().map().find())的场景下,Iterator Helpers 才能通过避免创建中间数组来展现优势。
结论:对于纯粹的“查找第一个匹配项”场景,直接使用 Array.find() 即可,无需画蛇添足地使用 Iterator Helpers。
场景四:复杂链式调用
数据规模:50,000 条
// 传统数组方法
dataset
.filter(item => item.active)
.map(item => ({ ...item, doubled: item.value * 2 }))
.filter(item => item.doubled > 500)
.map(item => ({ id: item.id, final: item.doubled + 100 }))
.slice(0, 15);
// Iterator Helpers
dataset
.values()
.filter(item => item.active)
.map(item => ({ ...item, doubled: item.value * 2 }))
.filter(item => item.doubled > 500)
.map(item => ({ id: item.id, final: item.doubled + 100 }))
.take(15)
.toArray();
结果:

链式调用越复杂,传统方法创建的中间数组就越多。此场景包含4次操作(filter → map → filter → map),传统方法因此创建了4个中间数组,总共占用5.33 MB内存。而 Iterator Helpers 全程不创建中间数组,内存占用几乎为零。
何时该使用 Iterator Helpers?
基于实测结果,我总结了几个最适合应用 Iterator Helpers 的场景:
1. 只需要前 N 项数据
这是最直接的优势场景。例如无限滚动列表、分页加载、虚拟列表等。
// 虚拟列表仅渲染可见的20行
const visibleRows = allRows
.values()
.filter(isInViewport)
.take(20)
.toArray();
2. 流式数据处理
处理 API 分页、Server-Sent Events (SSE) 流或 WebSocket 消息时,Iterator Helpers 结合异步迭代器 (async iterator) 非常好用。
async function* fetchPages() {
let page = 1;
while (true) {
const res = await fetch(`/api/items?page=${page++}`);
if (!res.ok) return;
yield* await res.json();
}
}
// 惰性拉取,不会一次性加载所有分页数据
const firstTen = await fetchPages()
.filter(isValid)
.take(10)
.toArray();
3. 复杂的数据处理管道
当数据处理链路很长,包含多次 filter、map、flatMap 操作时,使用 Iterator Helpers 可以清晰表达逻辑,同时避免产生大量中间数组,这对于掌握现代 JavaScript 尤其是 ES6+ 新特性的开发者来说是一个很好的实践。
const result = data
.values()
.filter(step1)
.map(step2)
.flatMap(step3)
.filter(step4)
.take(100)
.toArray();
何时不该使用 Iterator Helpers?
Iterator Helpers 并非万能,以下情况使用传统数组方法更合适:
1. 需要随机访问
迭代器是单向的,不支持像 items[5] 这样的直接索引访问。如果需要随机访问元素,必须使用数组。
2. 数据量非常小
如果只有几十条甚至几百条数据,使用 Iterator Helpers 带来的性能收益微乎其微,反而会增加代码的认知复杂度。此时,传统的数组方法更加简单直观。
3. 需要对同一数据集进行多次遍历
迭代器是“一次性”的,一旦遍历完成就无法再次使用。如果需要对同一份数据做多次不同的处理,应该先将其转换为数组。
const iter = data.values().filter(x => x > 10);
// ❌ 错误:第二次遍历将得到空数组,因为迭代器已耗尽
const first = iter.take(5).toArray();
const second = iter.take(5).toArray(); // []
// ✅ 正确:先转换为数组,再多次使用
const filtered = data.values().filter(x => x > 10).toArray();
const first = filtered.slice(0, 5);
const second = filtered.slice(5, 10);
兼容性与注意事项
Iterator Helpers 在现代浏览器和 Node.js 22+ 中已得到支持。如果需要兼容旧环境,可以使用 core-js[3] 等 polyfill 库。详细的兼容性数据可以在 Can I Use[4] 上查询。
使用 Iterator Helpers 时,还需要注意以下几个“坑”:
1. 迭代器不是数组
这是最容易混淆的一点。迭代器没有 length 属性,也不支持索引访问 ([index]),直接 console.log 也看不到内容。
const iter = [1, 2, 3].values();
console.log(iter.length); // undefined
console.log(iter[0]); // undefined
console.log(iter); // Object [Array Iterator] {}
// 要查看内容,必须先转换为数组
console.log([...iter]); // [1, 2, 3]
2. reduce 不是惰性的
大多数 Iterator Helpers 方法都是惰性的,但 reduce 是个例外。因为它需要遍历所有数据才能计算出最终结果,所以会立即消费整个迭代器。
// reduce 会立即消费整个迭代器
const sum = data.values().reduce((acc, x) => acc + x, 0);
3. 调试相对不便
由于惰性求值,你无法在中间步骤(如 filter 之后)直接打断点查看数据状态。一个调试技巧是在关键步骤临时插入 toArray() 将其转换为数组进行检查。
const result = data
.values()
.filter(step1)
.toArray() // 调试用,查看 filter 后的结果
.values()
.map(step2)
.take(10)
.toArray();
总结与实践建议
Iterator Helpers 并非要取代传统数组方法,而是为我们提供了另一种更高效的选择。其核心思想可以概括为一句话:如果你不需要整个数组,就不要创建它。
根据实测结果,我们可以得出以下结论:
filter/map + take(N) 链式调用:这是 Iterator Helpers 的“杀手级”应用场景,时间和空间开销均可降低90%以上。- 单纯的
find 查找:Array.find() 自身已具备惰性(短路)特性,使用 Iterator.find() 反而会因为额外的迭代器开销而更慢(慢30%-70%)。
- 数据规模越大,优势越明显:在处理大规模数据集时,Iterator Helpers 在链式调用中的优势会呈指数级增长。
- 内存优势极为突出:传统方法产生的中间数组是内存消耗的大头,而 Iterator Helpers 几乎不占用额外内存。
基于以上分析,我个人的使用建议如下:
- 默认使用数组方法:对于大多数简单场景,传统的
.map、.filter、.find 依然是最简单、最不易出错的选择。
filter/map + slice 组合:当你只需要结果集中的前 N 项时,强烈考虑使用 Iterator Helpers 的 filter/map + take(N) 组合。- 单纯的查找:直接使用
Array.find() 或 Array.findIndex(),无需转为迭代器。
- 编写数据管道:如果数据处理链路很长、很复杂,使用 Iterator Helpers 可以使代码意图更清晰,并从根本上避免不必要的内存分配。
- 内存敏感型应用:在处理大型数据集、或在移动端等内存受限的环境中,使用 Iterator Helpers 可以显著降低内存压力,提升应用性能。
理解惰性求值与急切求值的区别,根据实际场景灵活选择最合适的工具,是每一位追求高性能前端开发者应该掌握的技能。希望本文的实测数据与分析能为你提供有价值的参考。如果你对 JavaScript 性能优化有更多想法,欢迎在云栈社区与大家交流探讨。
参考资料:
[1] Stop turning everything into arrays
[2] MDN Array.prototype.find()
[3] core-js polyfill for Iterator Helpers
[4] Can I Use - Iterator Helpers
 发表于 2026-2-1 19:13:48
|
查看: 204|
回复: 0
发表于 2026-2-1 19:13:48
|
查看: 204|
回复: 0
