我们已经对计算机的整个存储结构有了一个基本的认识。那么,高速Cache究竟是干嘛的?
简单来说,高速Cache是CPU和主存之间的一个数据缓冲层。由于CPU和主存的速度差异极大——可能相差几十甚至上百倍——而运行的程序和数据都加载在主存中,CPU每次获取指令或数据都需要访问主存。如果没有缓冲,CPU就不得不经常等待,无法满负荷运转。于是,肩负重任的 高速缓存 便横空出世了!

那么,这个家伙是如何协调CPU和主存工作的呢?
当我们点击程序时,程序会以指令和数据的形式被加载到内存中。

按照传统方式,CPU获取指令只能去内存中读取。但现在,我们在CPU内部加入了高速缓存(示意图仅为逻辑展示)。

工作流程随之改变:
- CPU需要获取某条指令。
- 首先在Cache中查找。
- 如果找到(命中),直接返回。
- 如果未找到(不命中),再去主存中查找,并将找到的指令存入Cache。
听起来是不是很简单?

不不不,这里面的门道可不少。比如:
- 怎么判断内容在Cache中?
- Cache容量小,必然要不断替换数据,那替换策略是什么?
别担心,原理其实并不复杂。我们先来了解Cache的组成,它分为两部分:
- 存储器:负责存储数据。
- 控制部分:正是解决我们上述疑惑的关键——如何判断命中以及如何替换数据。
好,进入今天的第一个核心环节:如何判断内容在Cache中?
是直接匹配指令内容吗?比如CPU要找这条指令:LOAD R1, #8,然后Cache就直接去内容里搜索?

当然不可能!这属于倒果为因。CPU在执行前根本不知道指令内容,它只知道一个指令地址。CPU中有一个程序计数器PC,专门存放当前待执行指令的地址。程序加载到内存时,PC默认指向第一条指令。
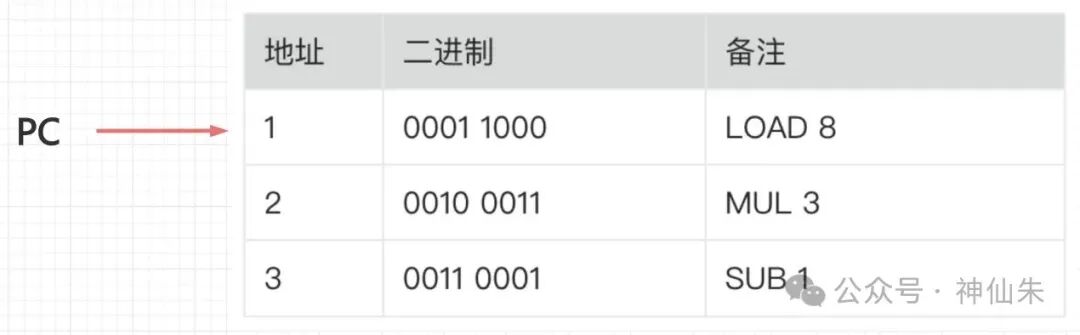
然后,CPU才试图通过这个地址去获取指令内容。因此,CPU最多给Cache一个地址,Cache自身也不知道地址里的内容。所以,Cache只能围绕地址来做文章。
这就引出了 地址映像 的概念,即主存地址与Cache地址之间的映射关系。具体怎么对应,主要有三种方式:
直接映像
Cache和主存被等分成大小相同的块,多个主存块映射到同一个Cache块。
这里的“等分”是指每块大小相等,比如约定每块1KB,双方都按此大小切割自己。
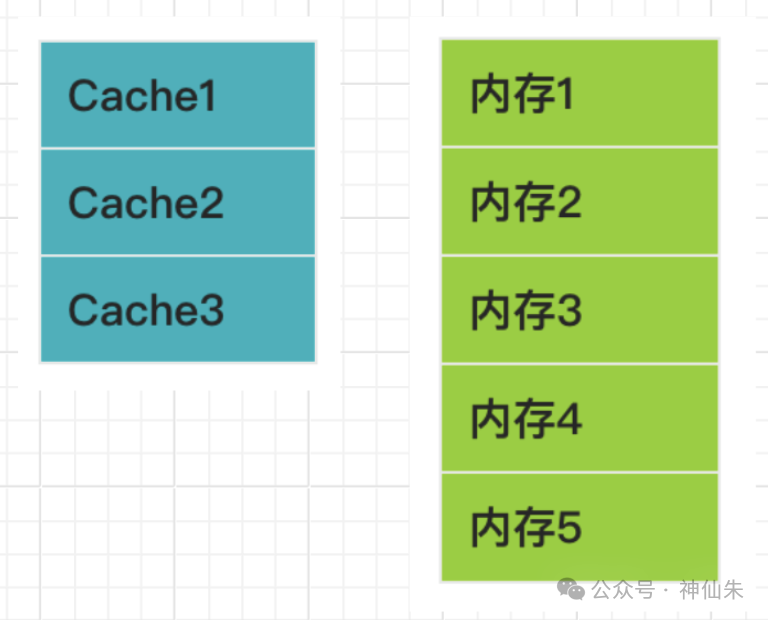
你可能会问:“块数不对等怎么办?” 答案是:多对一映射。具体通过取模运算实现:
i = j mod C
其中,i是Cache块号,j是主存块号,C是Cache的总块数。
例如,Cache有3块(编号0-2),主存有5块(编号0-4),则公式为 i = j mod 3。
- 主存块0,余0,放入 Cache块0
- 主存块1,余1,放入 Cache块1
- 主存块2,余2,放入 Cache块2
- 主存块3,余0,放入 Cache块0
- 主存块4,余1,放入 Cache块1
由此可见,主存块与Cache块是多对一,且关系固定。这带来了一个明显问题:Cache无法被充分利用。因为映射关系固定,即使对应的Cache块已满,而其他Cache块空闲,主存块也无法使用空闲块。

同时,这容易引发块冲突。实际上可能几十个主存块映射到同一个Cache块,冲突率很高。但其优点是查找极其简单,几乎没有额外开销。
全相联映像
同样进行等分,但不固定对应关系,任何一个主存块可以被调入任何一个空闲的Cache块中。
如果说直接映像是“包办婚姻”,那么全相联映像就是“自由恋爱”。那如何知道谁对应谁呢?答案是:给存入的Cache块打上标记。
例如,主存块2存入了Cache块1,就会在Cache块1上标记“主存块2”。
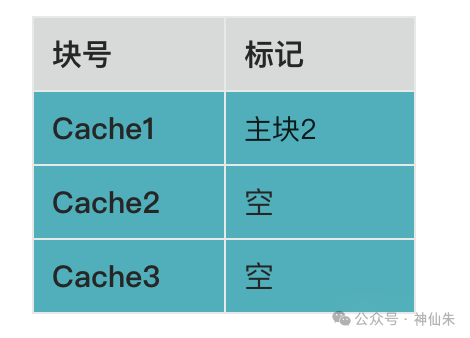
当需要查找时,Cache会遍历所有块,检查标记。这个过程类似于这样一段逻辑:

相比直接映像,全相联的查找难度和开销更大(Cache块越多,遍历代价越高),但它能充分利用Cache空间。
组相联映像
这是直接映像与全相联映像的结合体,旨在取长补短。
- 直接映像的缺点:空间利用率低。
- 全相联映像的缺点:查找开销大。
具体做法是:同样进行等分,但将Cache分组。
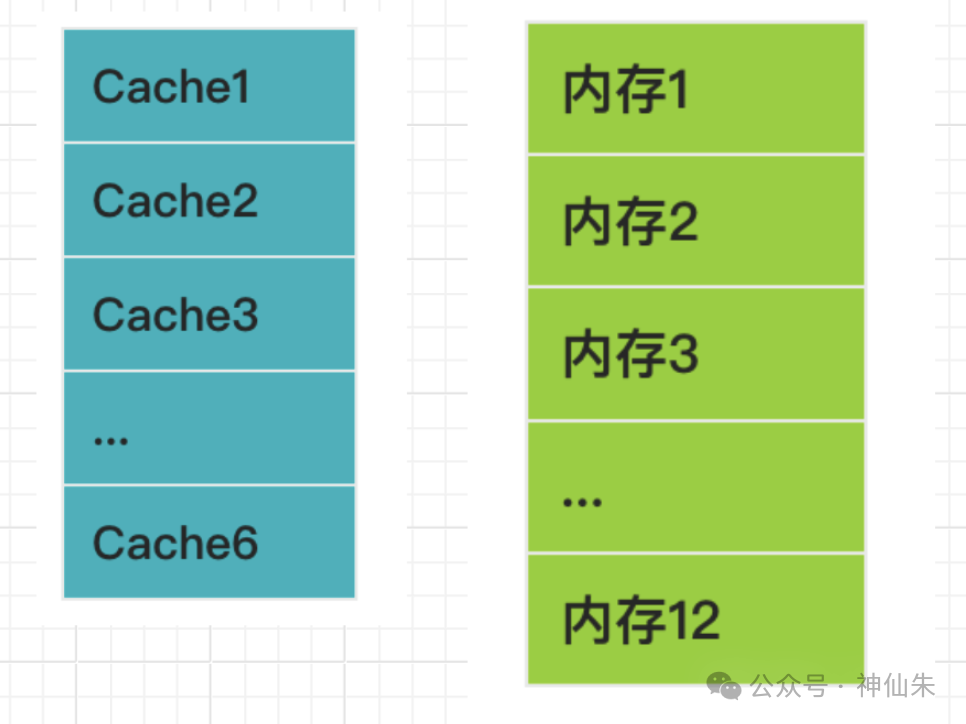
例如,Cache分成3组,每组2块:
- 组0:包含 Cache块0、Cache块1
- 组1:包含 Cache块2、Cache块3
- 组2:包含 Cache块4、Cache块5
映射分两步:
第一步:直接映像(确定组号)
组号 = j mod 组数 (例如 组号 = j mod 3)
- 主存块0,余0,放入 Cache组0
- 主存块1,余1,放入 Cache组1
- 主存块2,余2,放入 Cache组2
- 主存块3,余0,放入 Cache组0(以此类推)
第二步:全相联(组内任意放置)
确定组后,主存块可以放入该组内的任意一个空闲Cache块中。这样就将全相联需要遍历的范围从全体Cache缩小到了一个组内,完美平衡了查找开销和空间利用率。
了解完三种地址映像方式,又产生一个新问题:为什么都是按“块”操作,但CPU取指令时访问的是一个具体地址呢?
这利用了局部性原理。当CPU访问某条指令时,很可能会在不久后访问其相邻指令(空间局部性)或再次访问该指令(时间局部性)。因此,Cache会一次性将该指令所在的整个主存块调入,用较小的容量捕获较高的访问命中率,达到“四两拨千斤”的效果。
随之而来的问题是:CPU只想访问一条指令,但Cache调入了整个块,如何定位到块内具体的指令呢?例如,一个Cache块里存有多条指令:
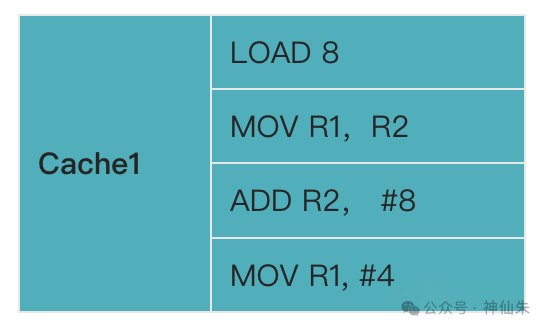
答案是:通过地址格式。我们以直接映像为例思考一下。
已知:
- 一个Cache块对应多个主存块。
- 一个Cache块存入某个主存块后,包含该主存块的多条指令。
要找到主存块X中的某条指令Y,我们需要知道:
- 它属于哪个Cache块?(通过取模计算)
- 它是哪个主存块?(因为一个Cache块可能对应多个主存块)
- 它在该主存块内的具体位置(块内地址)?
因此,直接映像下的指令地址格式可以理解为:主存块号 + Cache块号 + 块内地址。更严谨的术语是:区号 + 页号 + 页内地址。
其他两种方式的地址格式:
- 全相联映像:
主存页标记 + 页内地址。无需Cache块号,通过遍历查找标记。
- 组相联映像:
主存页标记 + 组地址 + 页内地址。先定位到组,再在组内通过标记查找具体块。
那么,这个主存地址格式是什么时候确定的?答案是在硬件设计阶段就已经确定,选定了地址映像方式,也就固化了地址格式。
解决了“如何找”的问题,我们来看第二个核心问题:Cache如何更新(替换)?
Cache容量远小于内存,当Cache已满而又有新的主存块需要调入时,就必须替换掉某个旧块。替换算法的目标是:尽可能保证高命中率,踢掉那些“占着位置不干活”的块。这套算法,可以戏称为“裁员算法”。
随机替换
正如其名,随机选择一个Cache块替换。就像抽签,点到谁就是谁(实现上使用随机数生成器)。
- 优点:实现简单,硬件复杂度低。
- 缺点:可能替换掉频繁使用的“核心员工”,导致命中率不稳定。
先进先出
先调入的Cache块先被替换。算法只需记录每个块的调入时间即可。
- 优点:系统开销小。
- 缺点:可能替换掉虽然调入早但依然频繁使用的块,命中率未必比随机替换高。
最近最少使用
替换掉最久未被访问过的Cache块。即裁掉“最闲”的员工。
- 实现方式:
- 时间戳法:每个块关联一个时间戳,访问时更新,替换时选择最早的时间戳。
- 链表法:将块组织成双向链表,被访问的块移到链表头(最近使用),链表尾就是最久未使用的块,替换时直接淘汰尾部。
- 优点:通常能获得较高的命中率,因为它基于过去的访问历史做出了更合理的预测。
- 缺点:算法相对复杂,需要维护时间戳或调整链表,系统开销较大。
最优替换
这是一个理论模型,它替换掉“未来最长时间内都不会被访问”的块。这需要对未来访问序列有预知能力,现实中无法实现。
- 作用:作为性能评估的“理想上限”,用于衡量其他实际算法的效率。例如,若OPT命中率为90%,LRU为80%,则LRU的效率约为理想情况的89%。
这些替换算法同样是在硬件设计阶段确定,并固化在芯片电路中的。
总结一下,我们探讨了Cache的地址映像与替换算法,这两者的核心目的都是为了提高Cache的命中率。如果CPU的每次数据请求都能在Cache中找到,就能极大提升工作效率。
然而,影响Cache命中率的最关键因素之一,其实是程序本身是否具有良好的局部性。因为Cache正是依据局部性原理来调入数据块的。因此,在编程时,我们可以有意识地优化:
- 利用空间局部性:尽量使用连续的内存访问模式(如顺序访问数组),避免跳跃式的内存访问。
- 利用时间局部性:避免重复计算,缓存中间结果,让近期用过的数据更可能被再次使用。
掌握这些计算机基础原理,不仅能帮助我们理解系统底层的工作机制,更能指导我们写出对缓存更友好的高性能代码。如果你对这类底层技术话题感兴趣,欢迎到云栈社区与其他开发者一起深入交流。
 发表于 2026-2-2 06:32:17
|
查看: 206|
回复: 0
发表于 2026-2-2 06:32:17
|
查看: 206|
回复: 0
