又一次在线上遇到了数据损坏(data corruption)问题,借此机会来梳理一下这类问题的分析与处理过程,希望能为大家提供一些排查思路。
问题现象
这个报错相信很多 PostgreSQL DBA 都见过,在查询时系统提示无法访问事务状态,即 clog 不存在。
postgres=# explain analyze select * from user_info where id < 51219961;
ERROR: could not access status of transaction 127045588
DETAIL: Could not open file "pg_xact/0079": No such file or directory.
postgres=# \errverbose
ERROR: 58P01: could not access status of transaction 127045588
DETAIL: Could not open file "pg_xact/0079": No such file or directory.
LOCATION: SlruReportIOError, slru.c:938
postgres=#
我们先来看看这个问题的危害:首先,报错的这张表将只能操作部分数据,因为任何尝试访问涉及损坏元组的查询都会失败。其次,这个问题会阻塞 autovacuum 进程,导致整个实例的事务 ID(XID)回收变慢,长此以往可能引发 XID 回绕的风险。
处理此类问题,最保守和稳妥的方案当然是使用备份进行恢复。如果可以接受丢失一部分数据,那么也可以尝试手动补齐缺失的 clog 文件来让查询继续。
问题分析
面对数据损坏,第一步通常是定位损坏的起始点。常规做法是使用一些辅助函数,或者在数据量不大时通过手动折半查找(二分法)来定位损坏的数据行。但这种方法往往耗时较久。
DO $$
DECLARE
rec record;
BEGIN
FOR rec in SELECT ctid,* FROM tablename LOOP
raise notice 'Parameter is: %', rec.ctid;
raise notice 'Parameter is: %', rec;
END LOOP;
END;
$$
LANGUAGE plpgsql;
-
如何快速定位到报错的 ctid?
更高效的方法是通过调试来定位。给报错的函数 SlruReportIOError 设置断点,当程序执行到此处时,查看调用堆栈。通常我们会进入 HeapTupleSatisfiesVisibility 函数,此时可以观察到 tup->t_self 的值,例如 {ip_blkid = {bi_hi = 48, bi_lo = 53101}, ip_posid = 2}。
计算 48 << 16 | 53101 得到 3198829,因此损坏元组的 ctid 为 (3198829, 2)。

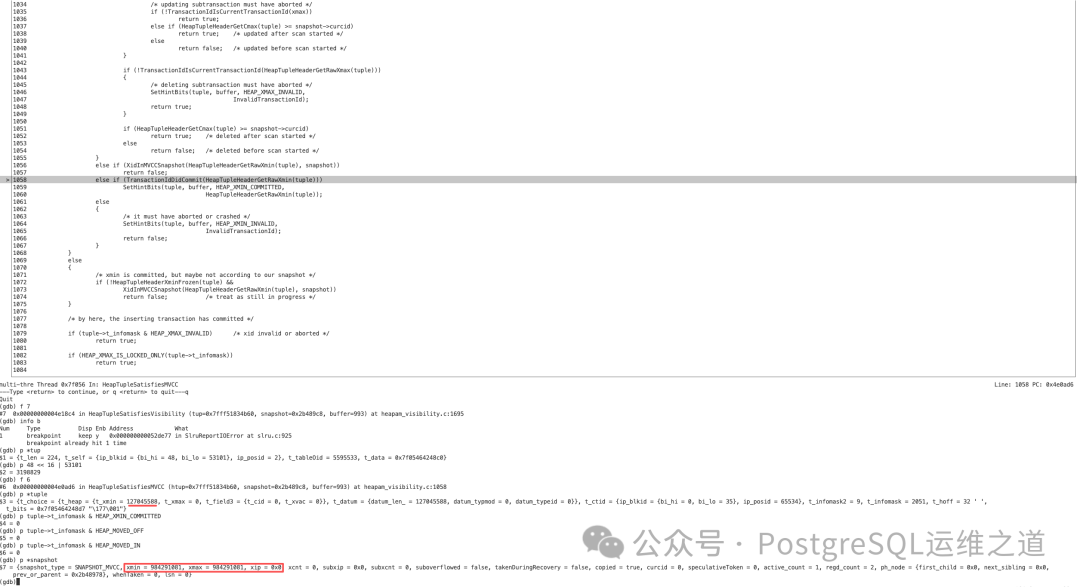
至此,我们可以梳理出 PostgreSQL 判断一个元组是否可见的逻辑:首先通过 t_infomask 标志位进行快速判断。如果元组对应的 infomask 没有 committed 标志,且未处于 vacuum full 过程中,也非当前事务,同时不在活跃事务快照中。这就意味着当前元组对应的 xmin 是一个已经结束的“过去的事务”,但其最终状态(提交或回滚)未知,因此需要查询 clog(事务提交日志)来做出最终判断。
-
事务 ID 127045588 和文件 pg_xact/0079 是什么关系?
在 TransactionIdDidCommit 函数中,TransactionLogFetch(transactionId) 会根据传入的事务 ID 来计算并读取对应的 clog 文件。
经过计算,事务 ID 127045588 对应的 clog 文件正是 0079(计算方式:127045588 / 2048 / 16 / 32 的结果转换为十六进制)。而这个文件在当前系统中确实不存在。

-
clog 的保留和清理策略是怎样的?
clog 的清理工作主要由 vacuum 或 autovacuum 进程负责,其大致的调用流程如下:
┌─────────────────┐
│ do_autovacuum │
│ / │
│ vacuum │
└─────────┬───────┘
│
▼
┌─────────────────┐
│ vac_update_ │
│ datfrozenxid │
└─────────┬───────┘
│
▼
┌─────────────────┐
│ vac_truncate_ │
│ clog │
└─────────┬───────┘
│
▼
┌─────────────────┐
│ TruncateCLOG │
└─────────┬───────┘
│
▼
┌─────────────────┐
│ SimpleLruTruncate│
└─────────┬───────┘
│
▼
┌─────────────────┐
│ SlruScanDirectory│
└─────────┬───────┘
│
▼
┌─────────────────┐ ┌─────────────────────────┐
│ (callback) │───▶│ SlruScanDirCbDeleteCutoff│
│ SlruScanDirCb │ └─────────┬───────────────┘
│ DeleteCutoff │ │
└─────────────────┘ ▼
┌─────────────────────────┐
│ SlruInternalDeleteSegment│
└─────────┬───────────────┘
│
▼
┌─────────────────┐
│ unlink │
│ (删除文件) │
└─────────────────┘
TruncateCLOG(frozenXID, oldestxid_datoid) 可以看作是 vacuum 清理 clog 的入口。它会根据 frozenXID 和 oldestxid_datoid(即当前实例所有数据库中记录的最老的 datfrozenxid)来计算出一个截止事务 ID。凡是该 ID 所在的 clog 文件之前的文件,都会被 unlink 系统调用删除。
查询当前实例的 frozenXID:
postgres=# SELECT min(datfrozenxid::int) FROM pg_database;
min
-----------
335599317
(1 row)
postgres=#
经过计算,开始保留的 clog 文件编号为 0x140(即十进制 320),所以在此编号之前的 clog 文件(例如 0079)都应当已被清理。
(gdb) p/x 335599317 / 2048 / 16 / 32
$14 = 0x140
(gdb)
-
为什么会出现 clog 文件被误删,但仍有元组需要查询它的场景?
可能的原因有几种:一是早期 PostgreSQL 版本中可能存在相关的 BUG(可以在官方 Bug List 中检索确认);二是硬件故障(如磁盘坏道)导致文件损坏或丢失;三是实例异常崩溃(Crash)后,clog 的清理逻辑与数据页的状态出现了不一致。
处理方案
再次强调,如果有可用的备份,使用备份恢复是最推荐、风险最低的方案。
如果经过评估,可以接受丢失 ctid 为 (3198829, 2) 的这一行(及可能存在的、依赖同一缺失 clog 的其他行)数据,那么可以尝试手动补齐缺失的 clog 文件,然后对表执行 vacuum full 来回收空间并修复表。
# 生产环境请慎重操作,注意核对路径
dd if=/dev/zero of=$PGDATA/pg_xact/0079 bs=256k count=1
# 在数据库连接中执行
vacuum full user_info;
注意:vacuum full 会锁表并重写整个表,在大表上操作需要谨慎规划时间窗口,并评估对业务的影响。这属于一种 运维 层面的应急修复手段。
小结
本篇记录了一起典型的 PostgreSQL 数据损坏案例,核心现象是查询时报错 “clog 不存在”。我们详细分析了其危害,并通过调试手段定位到具体的损坏数据行。文章深入解释了 PostgreSQL 的元组可见性判断逻辑、事务 ID 与 clog 文件的映射关系,以及 clog 的自动清理机制,并探讨了问题产生的可能原因。
处理此类问题没有银弹,务必根据业务的数据重要性、恢复时间目标(RTO)和数据恢复点目标(RPO)来谨慎选择方案。扎实的原理理解和清晰的排查思路,是快速解决问题的关键。如果你在数据库运维中遇到了其他棘手问题,也欢迎到 云栈社区 交流讨论。
 发表于 2026-2-2 03:59:25
|
查看: 227|
回复: 0
发表于 2026-2-2 03:59:25
|
查看: 227|
回复: 0
