上一次用kubeadm部署K8S还是在2023年,那时应该是K8S v1.22版本。虽然当时容器运行时已经变成了containerd,但我还是习惯用docker,所以第一次部署大概花了2天左右,踩了不少坑。
这次心血来潮,想重新部署一下最新版K8S v1.35。本来想装逼一把,用二进制部署,结果搞到证书部分就懵了,装逼失败,卒。遂改成kubeadm部署,原本以为会很快,毕竟之前部署过好几次,算是轻车熟路。但没想到这次前前后后搞了5天左右才搞定,因此记录一下自己的踩坑记录,应该算全网最细节的踩坑实录了。只要照着我贴出来的命令,基本100%可以在45分钟内完成部署,且不需要翻墙。
节点规划
- 操作系统:Ubuntu 24.03
- 三台虚拟机:
- 1台 master: 192.168.36.101
- 2台 node:
- node01: 192.168.36.102
- node02: 192.168.36.103
- K8S版本:1.35(stable)
部署详细步骤
整个部署过程分为三个阶段:第一阶段主要对三个节点进行基础配置,安装containerd(K8S从1.20版本开始正式使用containerd来替换docker作为容器运行时,集成在K8S内)。第二阶段在master01服务器上配置控制平面,第三阶段将其余节点加入集群。
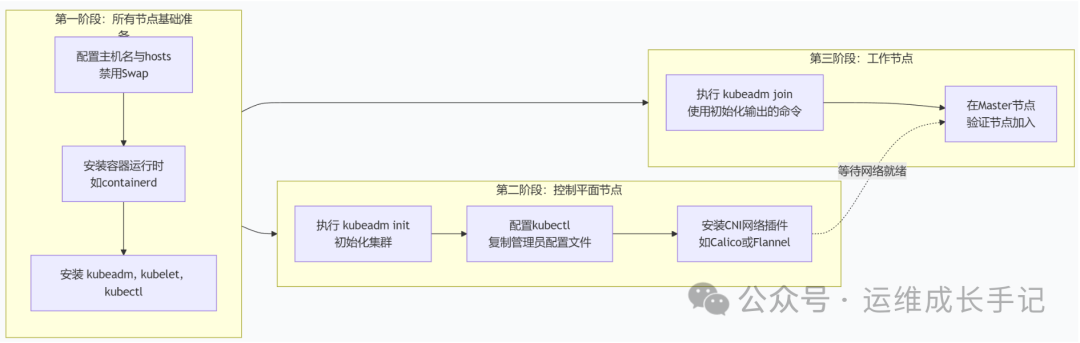
第一阶段:所有节点通用准备 (Master & Worker)
这些操作需要在集群中的所有节点上执行。
1. 关闭交换分区并配置内核
Kubernetes要求禁用交换分区,并启用内核模块。
# 临时禁用交换分区
swapoff -a
# 永久禁用,注释掉/etc/fstab中swap相关的行
sed -i.bak '/\sswap\s/d' /etc/fstab
# 加载内核模块
modprobe overlay
modprobe br_netfilter
# 设置系统参数
cat <<EOF | tee /etc/sysctl.d/99-kubernetes-cri.conf
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
2. 安装容器运行时
推荐使用 containerd。
# Ubuntu/Debian 系统
apt-get update
apt-get install -y containerd
# 生成默认配置文件并启用systemd cgroup驱动
mkdir -p /etc/containerd
containerd config default | tee /etc/containerd/config.toml
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
systemctl restart containerd
systemctl enable containerd
这里有一个不得不讲的点,关系到后面对K8S组件镜像的管理,就是 crictl 和 ctr 两个命令。
简单来说,crictl 是专门为 Kubernetes 设计的,而 ctr 是 containerd 自身的通用管理工具。
- 面向用户与场景
crictl:主要供 Kubernetes 集群管理员和开发者 使用,用于在节点上调试容器运行时、查看 Pod 状态、检查容器日志等,是 K8s 环境下的标准调试工具。ctr:更偏向 容器运行时维护者和高级用户,用于对 containerd 进行底层的操作和排错,例如管理快照、直接操作镜像内容等。
- 与 Kubernetes 的集成
crictl 与 Kubernetes 的集成更紧密,它的许多命令输出格式(如 crictl pods)与 kubectl 的视图类似,便于对照。ctr 不感知 Kubernetes。例如,Kubernetes 通过 crictl 拉取的镜像默认存放在 k8s.io 命名空间,而 ctr 如果不在命令中明确指定 -n k8s.io,则默认拉取到 default 空间,这会导致 crictl 和 kubelet 看不到这些镜像。
3. 安装 kubeadm, kubelet, kubectl
必须使用Kubernetes官方的新软件包仓库 pkgs.k8s.io。这里以安装 v1.35 稳定版为例,请根据需要替换为最新的稳定版本号(如v1.36)。
# Ubuntu/Debian 系统
# 添加Kubernetes官方仓库
mkdir -p /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.35/deb/Release.key | gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.35/deb/ /" | tee /etc/apt/sources.list.d/kubernetes.list
# 安装并锁定版本
apt-get update
apt-get install -y kubelet kubeadm kubectl
apt-mark hold kubelet kubeadm kubectl
第二阶段:初始化控制平面 (仅在Master节点执行)
1. 初始化集群
选择一个与后续网络插件匹配的Pod网段(CIDR)。
# 创建时可指定Pod网段
kubeadm init --pod-network-cidr=10.10.0.0/16 --kubernetes-version stable
重要:命令执行成功后,会输出用于加入集群的 kubeadm join ... 命令,请务必完整保存。
天坑一号:
在大多数的K8S部署步骤里,初始化往往就是上面一条命令,但对于很多新手来说,却是第一道不可逾越的鸿沟。因为默认的镜像仓库在国内根本访问不了,需要通过其他方式进行预下载。所以一般需要用如下步骤,放弃思考,只要贴!贴!贴!
1) 检查k8s需要部署的镜像版本
root@master01:~# kubeadm config images list
registry.k8s.io/kube-apiserver:v1.35.0
registry.k8s.io/kube-controller-manager:v1.35.0
registry.k8s.io/kube-scheduler:v1.35.0
registry.k8s.io/kube-proxy:v1.35.0
registry.k8s.io/coredns/coredns:v1.13.1
registry.k8s.io/pause:3.10.1
registry.k8s.io/etcd:3.6.6-0
2)利用crictl从国内源下载k8s镜像
crictl pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.35.0
crictl pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.35.0
crictl pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.35.0
crictl pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.35.0
crictl pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.13.1
crictl pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.10.1
crictl pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.6.6-0
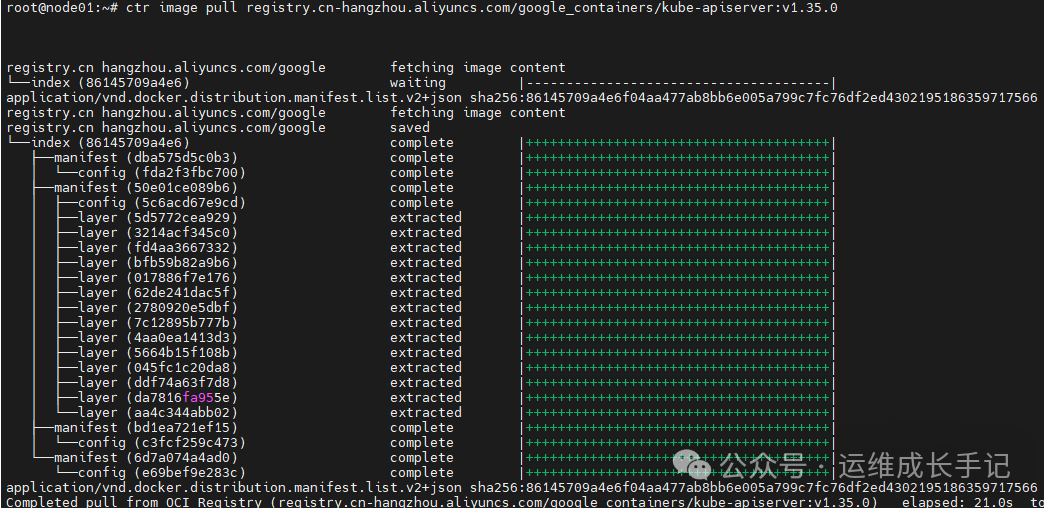
3)利用ctr重新打tag,使镜像被k8s识别
ctr -n k8s.io images tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.35.0 registry.k8s.io/kube-apiserver:v1.35.0
ctr -n k8s.io images tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.35.0 registry.k8s.io/kube-controller-manager:v1.35.0
ctr -n k8s.io images tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.35.0 registry.k8s.io/kube-scheduler:v1.35.0
ctr -n k8s.io images tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.35.0 registry.k8s.io/kube-proxy:v1.35.0
ctr -n k8s.io images tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.13.1 registry.k8s.io/coredns/coredns:v1.13.1
ctr -n k8s.io images tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.10.1 registry.k8s.io/pause:3.10.1
ctr -n k8s.io images tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.6.6-0 registry.k8s.io/etcd:3.6.6-0
4) 检查确认
crictl image list | grep k8s
root@master01:~# crictl image list | grep k8s
WARN[0000] Config "/etc/crictl.yaml" does not exist, trying next: "/usr/bin/crictl.yaml"
WARN[0000] Image connect using default endpoints: [unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.
register.k8s.io/etcd 3.6.6-0 0a108f7189562 23.6MB
registry.k8s.io/etcd 3.6.6-0 0a108f7189562 23.6MB
register.k8s.io/pause 3.10.1 cd073f4c5f6a8 320kB
registry.k8s.io/pause 3.10.1 cd073f4c5f6a8 320kB
registry.k8s.io/coredns/coredns v1.13.1 aa5e3ebc0dfed 23.6MB
registry.k8s.io/kube-controller-manager v1.35.0 5c6acd67e9cd1 27.7MB
registry.k8s.io/kube-proxy v1.35.0 32652ff1bbe6b 25.8MB
registry.k8s.io/kube-scheduler
GO~GO~GO~ 重新回到第一步,一把过!
kubeadm init --pod-network-cidr=10.10.0.0/16 --kubernetes-version stable
5) 消除crictl的warning(可选)
root@node02:~# crictl image list
WARN[0000] Config "/etc/crictl.yaml" does not exist, trying next: "/usr/bin/crictl.yaml"
WARN[0000] Image connect using default endpoints: [unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.
如果你也不喜欢报错,可以参考如下内容,创建一个 /etc/crictl.yaml 文件。
root@master01:~# cat /etc/crictl.yaml
runtime-endpoint: unix:///var/run/containerd/containerd.sock
image-endpoint: unix:///var/run/containerd/containerd.sock
timeout: 10
debug: false
pull-image-on-create: true
disable-pull-on-run: false
部署成功后的输出内容如下:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.36.101:6443 --token zjg02r.81m6chikxqoj2uxf \
--discovery-token-ca-cert-hash sha256:bf104617ac122706d8198fa17771fcdf1246634f6be6a651bdac7db1a401ffb5
2. 配置kubectl
使当前用户可以管理集群。
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
3. 安装Pod网络插件
这是集群能用的关键一步。必须安装一个CNI插件,Pod才能跨节点通信。以安装Calico为例:
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.1/manifests/tigera-operator.yaml
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.1/manifests/custom-resources.yaml
等待几分钟,使用 kubectl get pods -n calico-system -w 观察,直到所有Pod状态变为 Running。
天坑二号:
OK,不出意外,calico的安装就是第二个天坑了。虽然短短的几条命令,但是我却花了8个小时,最后无疾而终。主要还是calico对应的镜像组件URL地址在国内访问不稳定,有一次就只差一个镜像文件了,但还是失败了。无奈放弃了Calico,转战稍微简单一点的Flannel网络插件。
具体步骤如下,还是只要贴!贴!贴!
首先是Flannel的yaml文件,内容有点多(可以从官方获取),唯一有一处需要修改,就是 Network 要修改为你在用 kubeadm init 时候指定的Pod网络地址段。
net-conf.json: |
{
"Network": "10.10.0.0/16",
"EnableNFTables": false,
"Backend": {
"Type": "vxlan"
}
}
Flannel涉及的网络插件镜像组件地址至少我可以下载。如果你还是下不了,就参考前面K8S组件镜像的方式,用 crictl 和 ctr 的组合。组件就如下3个:
root@master01:~# cat flannel.yaml | grep image
image: ghcr.io/flannel-io/flannel-cni-plugin:v1.8.0-flannel1
image: ghcr.io/flannel-io/flannel:v0.27.4
image: ghcr.io/flannel-io/flannel:v0.27.4
等待一段时间,估摸在5-10分钟(一杯咖啡的时间),顺利的话就OK了,我是一把过的。毕竟前面两个坑花了我差不多10多个小时,已经算是百般折磨了。状态变成 Running 后,就算OK了。
root@master01:~# kubectl get pod -n kube-flannel -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-flannel-ds-4c4tr 1/1 Running 4 (8m13s ago) 3d17h 192.168.36.101 master01 <none> <none>
kube-flannel-ds-mh9ks 1/1 Running 4 (7m22s ago) 3d17h 192.168.36.102 node01 <none> <none>
kube-flannel-ds-prjqz 1/1 Running 3 (7m19s ago) 3d17h 192.168.36.103 node02 <none> <none>
踩坑完毕,继续 GO~GO~GO~
第三阶段:加入工作节点 (在所有Worker节点执行)
在每个工作节点上,运行第一阶段保存的 kubeadm join 命令。
kubeadm join <控制平面节点的IP:6443> --token <令牌> --discovery-token-ca-cert-hash sha256:<哈希值>
依次在我的 Node01 和 Node02 两个节点上执行,没啥难度。token就是之前部署成功后输出的命令。
kubeadm join 192.168.36.101:6443 --token zjg02r.81m6chikxqoj2uxf \
--discovery-token-ca-cert-hash sha256:bf104617ac122706d8198fa17771fcdf1246634f6be6a651bdac7db1a401ffb5
验证与测试
回到 Master节点,执行以下命令验证:
# 查看所有节点状态,应都为 Ready
kubectl get nodes
# 部署一个测试应用
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
# 查看服务,获取NodePort端口
kubectl get svc nginx
访问任意节点的IP地址和NodePort端口(如 http://<节点IP>:30080),应能看到Nginx欢迎页。
天坑三号:
这应该是我碰到的最无语的坑了。如果没有配置镜像加速,你会发现你连一个最简单的Nginx的Deployment都无法创建。这就是containerd镜像加速的坑。如果是用docker的话,镜像加速很简单,地球人都会。
# Docker镜像加速方法:
cat <<EOF | tee /etc/docker/daemon.json
{ "registry-mirrors": [
"https://docker.xuanyuan.me" ]
}
EOF
但是说实话,containerd就不咋会了,摸索了很久,在containerd v1.x和v2.x之间来回踩坑。最后梳理一下步骤:
1)确认containerd版本
root@master01:~# kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master01 Ready control-plane 6d17h v1.35.0 192.168.36.101 <none> Ubuntu 24.04.3 LTS 6.8.0-90-generic containerd://2.2.0
node01 Ready <none> 6d17h v1.35.0 192.168.36.102 <none> Ubuntu 24.04.3 LTS 6.8.0-90-generic containerd://2.2.0
node02 Ready,SchedulingDisabled <none> 6d17h v1.35.0 192.168.36.103 <none> Ubuntu 24.04.3 LTS 6.8.0-90-generic containerd://2.2.0
2)修改配置文件
containerd v1.x版本是直接在 /etc/containerd/config.toml 文件内修改的,v2.0则做了优化,采用了外挂Plugin的方式。
cat /etc/containerd/config.toml
...
[plugins.'io.containerd.cri.v1.images'.registry]
config_path = '/etc/containerd/certs.d'
...
从配置文件可以看到,具体配置镜像加速需要在 /etc/containerd/certs.d 下创建目录。从查询结果总结,在 certs.d 下需要创建对应的镜像仓库域名目录,比如 docker.io 的镜像就需要创建一个 docker.io 的目录。另外可以创建一个 _default 目录,用于默认镜像加速的地址。
可参考结构如下,单个目录下需要创建一个 hosts.toml 文件,注意是hosts,不是host,不要问我为什么要注意:
root@master01:/etc/containerd/certs.d# tree
.
├── _default
│ └── hosts.toml
└── docker.io
└── hosts.toml
具体命令如下:
mkdir /etc/containerd/certs.d/_default
touch /etc/containerd/certs.d/_default/hosts.toml
cat <<EOF | tee /etc/containerd/certs.d/_default/hosts.toml
server = "https://registry-1.docker.io"
[host."https://docker.m.daocloud.io"]
capabilities = ["pull", "resolve"]
EOF
mkdir /etc/containerd/certs.d/docker.io
touch /etc/containerd/certs.d/docker.io/hosts.toml
cat <<EOF | tee /etc/containerd/certs.d/docker.io/hosts.toml
server = "https://registry-1.docker.io"
[host."https://docker.m.daocloud.io"]
capabilities = ["pull", "resolve"]
EOF
在配置文件过程中,我发现最终折腾我的地方是通过日志回溯发现的:我之所以无法启用镜像加速,原因竟是配置文件里有看不见的特殊字符,应该是我从网页上copy paste的时候失误了!这个问题大概困扰了我3个小时!
如果有问题需要排查,可以用如下命令查看containerd的日志,这也是一个基础的运维排错技巧。
journalctl -u containerd -f

填完坑以后,再看一下Nginx的实例状态,终于变成 Running 了。请记得在两台Node节点上同样配置镜像加速,同样的,不要问我为什么知道这个问题。
root@master01:~# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-56c45fd5ff-gnzhg 1/1 Running 2 (37m ago) 27h 10.10.1.6 node01 <none> <none>
查看svc信息:
root@master01:~# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6d17h <none>
nginx NodePort 10.110.67.9 <none> 80:31984/TCP 22h app=nginx
验证Nginx访问,此处应有掌声~~~~
root@master01:~# curl -L 10.110.67.9
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
后续关键操作提醒
- 令牌管理:初始化时生成的加入令牌默认24小时后过期。过期后,可在Master上用
kubeadm token create --print-join-command 生成新命令。
- 集群升级:不可直接使用
apt upgrade。必须使用 kubeadm upgrade 进行规划式升级,并依次升级控制平面和工作节点。
- 生产加固:考虑配置高可用控制平面、启用RBAC、设置网络策略等。
后面计划搭建一个NFS Server的虚机,通过NFS提供PVC功能,然后基于PVC建设私有镜像仓库Harbor。如果你对本文涉及的配置细节或踩坑过程有更深入的交流需求,欢迎到 云栈社区 的技术板块一起探讨。
 发表于 2026-2-2 05:54:31
|
查看: 206|
回复: 0
发表于 2026-2-2 05:54:31
|
查看: 206|
回复: 0
