notify_dispatch 函数是 DeepEP 框架中负责在分布式专家混合模型 (MoE) 前向传播前,进行跨节点元数据同步与路由规划的关键组件。
它的核心工作可以概括为以下两部分:
1. 在 sm_id == 0 上
- 进行全局等待并清理旧的
RDMA 状态。
- 在
RDMA/NVL 对称缓冲中构造 “混合计数块” ,并通过 RDMA 在节点间交换这些计数。
- 在本节点内进行多级规约(
per-expert、per-rank、全局)并计算前缀和。
- 将结果写入
host-mapped 计数器和接收前缀数组。
- 通过
NVL 缓冲区将 per-rank/per-expert 信息广播到节点内所有 GPU。
- 在末尾执行跨节点及节点内
barrier,形成 “元数据阶段完成” 的全局同步点。
2. 在 sm_id != 0 上
- 并行地按
channel 和 RDMA rank,利用 is_token_in_rank 重新统计每个 (global rank, channel) 的 token 数量。
- 将统计结果写入
gbl_channel_prefix_matrix 和 rdma_channel_prefix_matrix,并对每一行计算前缀和。
最终,该函数输出一整套 “谁要收多少、从哪里开始收、每个通道上分布如何” 的元数据,为后续的数据搬运内核(dispatch)提供了所有必需的路由与布局信息。
函数参数详解
这个函数的参数较多,但可以归纳为四大类:
1. 输入统计信息(per-rank / per-expert / per-token)
const int* num_tokens_per_rank:每个 global rank(节点×GPU)预期接收的初始 token 数量数组,长度为 num_ranks。int num_ranks:全局 rank 总数,通常等于 kNumRDMARanks * NUM_MAX_NVL_PEERS。const int* num_tokens_per_rdma_rank:每个 RDMA 节点要接收的 token 总数(按节点聚合),长度为 kNumRDMARanks。const int* num_tokens_per_expert:每个 expert 要接收的 token 数量数组,长度为 num_experts。int num_experts:全局 expert 总数。const bool* is_token_in_rank:一个展开的布尔矩阵,表示“token i 是否属于 global rank j”,用于按 token 维度重新统计各 rank/channel 的负载。逻辑上是 [num_tokens][num_ranks] 的线性展开。int num_tokens:本次 dispatch 的输入 token 总数。int num_worst_tokens:落入“最坏路径” (worst-path) 的 token 数量,用于判断是否启用 fast-path(直接写 counter)。int num_channels:将 token 空间划分为多少个“通信通道”,用于并行/流水线发送。int expert_alignment:每个 expert 的 token 数在最终分配时需要对齐的粒度(向上取整的倍数)。
2. 输出到 host-mapped 的统计与前缀和
int* moe_recv_counter_mapped:映射到 host/其他 stream 的单一计数器,表示所有 rank 总共要接收的 token 总数。int* moe_recv_rdma_counter_mapped:映射到 host 的 RDMA 级计数器,表示所有 RDMA 节点接收的 token 总和。int* moe_recv_expert_counter_mapped:映射到 host 的 per-expert 计数器数组,长度为 num_experts,表示每个 expert 要处理的对齐后的 token 总数。int* rdma_channel_prefix_matrix:线性展开的二维矩阵 [kNumRDMARanks][num_channels],记录每个 RDMA 节点在每个 channel 上要接收的 token 数,后续会就地转为前缀和。int* recv_rdma_rank_prefix_sum:RDMA 级前缀和数组,长度为 kNumRDMARanks,用于确定每个节点在接收大缓冲区中的区间。int* gbl_channel_prefix_matrix:线性展开的三维矩阵 [global_rank][num_channels],记录每个 global rank 在每个 channel 的 token 数。int* recv_gbl_rank_prefix_sum:按 global rank 计算的前缀和数组,长度为 num_ranks,用于为所有 token 分配一个连续 recv buffer 中的区间。
3. 缓冲区布局与清理参数
const int rdma_clean_offset:RDMA 对称缓冲区中,需要清零的数据区域的起始偏移(以 int 为单位)。const int rdma_num_int_clean:RDMA 缓冲区中,从 rdma_clean_offset 开始需要清零的 int 数量。const int nvl_clean_offset:NVLink 对称缓冲区中,数据区域清零的起始偏移(以 int 为单位)。const int nvl_num_int_clean:NVL 缓冲区中,从 nvl_clean_offset 开始需要清零的 int 数量。
4. 设备端缓冲区与同步资源
void* rdma_buffer_ptr:RDMA 对称缓冲区的基址(NVSHMEM 分配)。void** buffer_ptrs:节点内各 GPU 的 NVLink 对称缓冲区指针数组。buffer_ptrs[nvl_rank] 是本 GPU 的 NVL 缓冲区。int** barrier_signal_ptrs:用于实现节点内/块内 barrier 的信号数组。int rank:当前进程/线程块所在的 global rank ID(编码了 rdma_rank 和 nvl_rank)。const nvshmem_team_t rdma_team:NVSHMEM 的 team 句柄,表示一组要一起参与 nvshmem_sync 的 PE 集合。
SM 0 的专用通信与同步逻辑
在 DeepEP 的设计中,SM 0 专门负责核心的通信与同步任务。第一个 warp 用于节点内同步(NVLink),第二个 warp 用于节点间同步(RDMA)。我们首先关注 SM 0 的执行逻辑。
函数开始的几个变量初始化是关键:

其中,qps_per_rdma_rank 表示每个 rdma_rank(即一个物理节点)的 Queue Pair 数量。它通过 ibgda_get_state() 获取 IBGDA(NVSHMEM 实现 GPU 直接 RDMA 的底层机制)的全局状态。num_rc_per_pe 是每个 PE 上的 RC QP 数量,num_devices_initialized 表示节点内已初始化并参与通信的 GPU 数量。
一个典型的配置计算如下:
假设:
- num_rc_per_pe = 1 (每对GPU一个RC连接)
- num_devices_initialized = 8 (每节点8个GPU)
则 qps_per_rdma_rank = 1 × 8 = 8
含义:当前节点到另一个节点共有8个QP
紧接着,代码会循环等待所有 QP 上未完成的 RDMA 传输完成,以防止在旧传输完成前重写缓冲区。这里调用了底层的 nvshmemi_ibgda_quiet 函数。
随后,thread_id == 32 的线程(第二个 warp 的首个线程,即负责节点间同步的 warp)会执行 nvshmem_sync_with_same_gpu_idx。这个函数确保所有节点上具有相同 GPU 索引的进程(例如所有节点的 GPU 0)都到达此同步点,才能继续。其内部通过 RDMA 的原子操作实现。
然后是 barrier_block 调用,用于节点内 GPU 间的同步,确保节点内所有 GPU 都完成前述操作。它的实现原理是基于 barrier_signal_ptrs 和 IPC 共享内存的原子操作,其原理如下图所示:

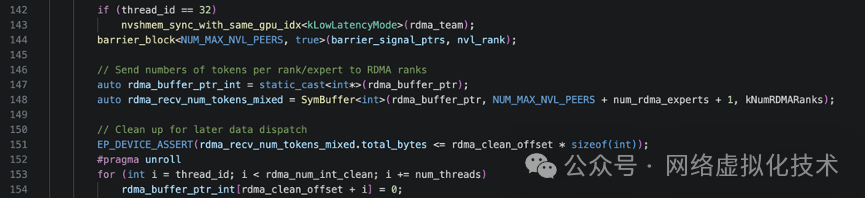
接下来,rdma_buffer_ptr_int 和 rdma_recv_num_tokens_mixed 被初始化,用于访问 RDMA 缓冲区的元数据区。为了理解后续操作,我们需要先了解 DeepEP 中 RDMA 缓冲区的布局。
假设有 4 个节点,每个节点有 8 个 GPU,每个 RDMA rank 负责 16 个专家。那么 RDMA 缓冲区由元数据区和数据区构成。每个 rdma rank 都有自己的一块元数据区,用于存放“从各个来源会收到多少 token”的信息,具体包括两部分:
- NVL 分布:
NUM_MAX_NVL_PEERS 个整数,表示从发送方节点内每个 GPU 会收到多少 token。
- 专家分布:
num_rdma_experts 个整数,表示本节点每个专家会处理多少来自发送方节点的 token。
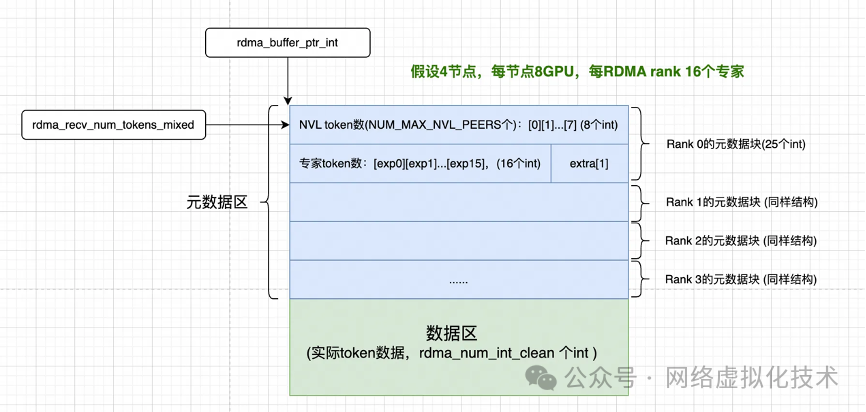
rdma_recv_num_tokens_mixed 就是用来描述这个元数据区的数据结构,它是一个 SymBuffer 对象。
SymBuffer:对称缓冲区抽象
SymBuffer(Symmetric Buffer,对称缓冲区)是 DeepEP 中用于管理跨节点共享内存(对称内存)的抽象数据结构。在 C/C++ 这类底层编程中,这类抽象对于管理复杂的并行内存布局至关重要。NVSHMEM 中的对称内存是指所有参与通信的节点都分配了布局和大小相同的内存区域,每个节点可以通过相同的偏移量访问其他节点的对应内存。
其定义如下:
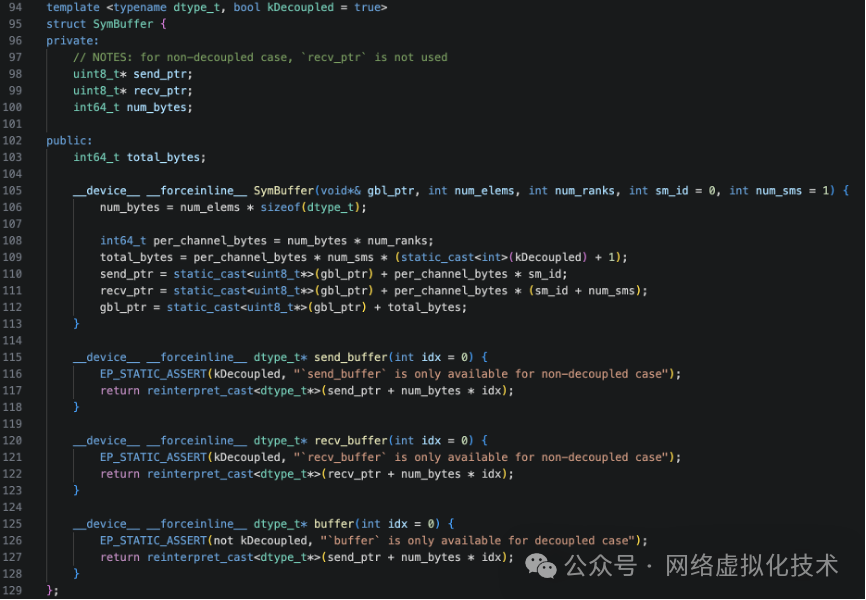
结合 rdma_recv_num_tokens_mixed 的创建来理解:
auto rdma_recv_num_tokens_mixed = SymBuffer<int>(rdma_buffer_ptr, NUM_MAX_NVL_PEERS + num_rdma_experts + 1, kNumRDMARanks);
模板参数 kDecoupled = true(默认)表示发送和接收缓冲区分离。其参数与成员计算关系如下(以 4 节点、每节点 8 GPU、每 RDMA rank 16 专家为例):

根据传入参数,内部计算如下:
num_bytes = 25 * 4 = 100 字节(每个 rank 的数据大小)per_channel_bytes = 100 * 4 = 400 字节(所有 rank 的发送区或接收区大小)total_bytes = 400 * 1 * 2 = 800 字节(发送区 + 接收区)
其对应的内存布局如下图所示:

SymBuffer 提供了便捷的访问接口:
- 发送数据(写入
send_buffer)
// 准备发给 RDMA Rank 1 的数据
rdma_recv_num_tokens_mixed.send_buffer(1)[0] = gpu0_tokens; // NVL 分布
rdma_recv_num_tokens_mixed.send_buffer(1)[8] = expert0_tokens; // 专家分布
- RDMA 发送(从本地
send_buffer 到远程 recv_buffer)
nvshmemi_ibgda_put_nbi_warp(
rdma_recv_num_tokens_mixed.recv_buffer(rdma_rank), // 远程目标:对方的 recv_buffer[我的 rank]
rdma_recv_num_tokens_mixed.send_buffer(i), // 本地源:我的 send_buffer[对方 rank]
...
);
nvshmemi_ibgda_put_nbi_warp 是 NVSHMEM 的 warp 级非阻塞 RDMA PUT 操作。
- 接收数据(读取
recv_buffer)
// 读取来自 RDMA Rank 2 的数据
int tokens_from_rank2 = rdma_recv_num_tokens_mixed.recv_buffer(2)[0];
回到主线代码,在初始化 SymBuffer 后,会有一个循环并行地将 RDMA 缓冲区的数据区域清零,清零的起始位置和长度由参数 rdma_clean_offset 和 rdma_num_int_clean 指定。
接下来的代码进入元数据准备阶段,负责将本地计算的 token 分布信息组织成适合 网络/系统 层面 RDMA 传输的格式。

具体流程如下:
- 复制每个 rank 的 token 数量:
i / NUM_MAX_NVL_PEERS 计算目标 RDMA rank(节点),i % NUM_MAX_NVL_PEERS 计算目标 NVL rank(节点内 GPU)。
- 复制每个专家的 token 数量:
i / num_rdma_experts 计算专家所在的 RDMA rank,i % num_rdma_experts 计算专家在节点内的索引,NUM_MAX_NVL_PEERS + ... 偏移到专家区域。
- 复制每个 RDMA rank 的总 token 数量。
元数据的RDMA发送与同步
准备完数据后,代码开始将元数据实际发送给其他节点。这是一个典型的并行发送过程:
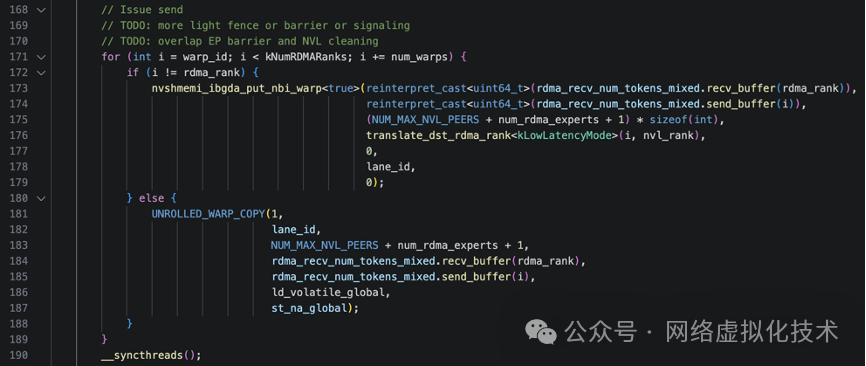
循环变量 i 代表目标 RDMA rank(目标节点)。这里采用了 warp-stride loop 模式,让多个 warp 并行处理不同的目标节点以提高效率。例如,在 4 个节点、2 个 warp 的情况下:
warp_id=0: i = 0, 2 (处理节点0和节点2)
warp_id=1: i = 1, 3 (处理节点1和节点3)
在循环体内:
- 如果
i != rdma_rank(目标不是本节点),则调用 nvshmemi_ibgda_put_nbi_warp 发起非阻塞 RDMA PUT 操作。该函数参数包括远程目标地址、本地源地址、数据大小、目标 PE、QP 索引、lane_id 等。
- 如果
i == rdma_rank(目标是本节点),则调用 UNROLLED_WARP_COPY 进行本地内存拷贝,将数据从发送缓冲区拷贝到接收缓冲区。
发送操作后,需要确保所有 RDMA 操作完成,并进行全局同步,保证所有节点都已收到元数据。这里的同步分为两步:
-
等待发送完成 (quiet):只有前 kNumRDMARanks 个线程参与,每个线程等待到某个特定目标节点的所有未完成 RDMA 操作完成。发送时是 warp 并行(提高内存访问效率),而等待是 thread 并行(等待操作轻量,可以同时检查更多节点)。
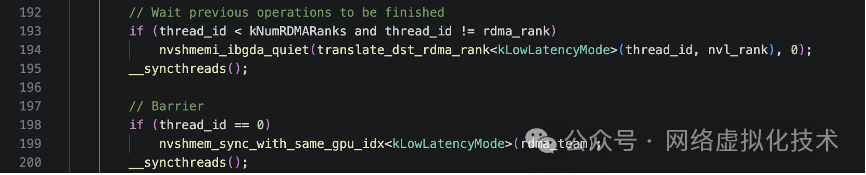
quiet 确保本节点发出的 RDMA PUT 已经到达目标内存,但不关心其他节点的状态。
-
全局同步 (sync):由 thread_id == 0 的线程执行 nvshmem_sync_with_same_gpu_idx。sync 是一个全局“会合点”,确保所有节点(或特定 team 内的节点)都到达此点,但不保证数据已到达,只保证进程同步。这两步的结合(先 quiet 再 sync)是确保数据可靠交换的常见模式。整个流程的时间线如下图所示:

节点内NVLink缓冲区的设置与规约
跨节点元数据交换完成后,工作重心转向节点内。代码开始设置 NVLink 缓冲区,用于节点内 GPU 间的通信与数据规约。
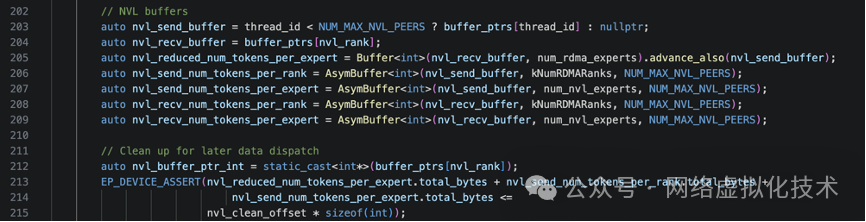
我们通过一个具体例子来理解:假设有 2 个节点,每节点 4 个 GPU (GPU0-3),当前是节点 0 的 GPU2 (nvl_rank=2)。
nvl_send_buffer:指向目标 GPU 的缓冲区(用于写入)。例如,thread 0/1/2/3 的缓冲区分别指向 GPU0/1/2/3。nvl_recv_buffer:指向自己的缓冲区(用于接收)。所有线程都指向 GPU2 的缓冲区。
接下来的步骤是:
- 每个 GPU 统计自己的发送计划:包括发给每个
global rank 的 token 数 (nvl_send_num_tokens_per_rank) 和发给本节点内每个专家的 token 数 (nvl_send_num_tokens_per_expert)。
- 通过 NVLink 交换,收集所有 GPU 的发送计划:形成
nvl_recv_num_tokens_per_rank 和 nvl_recv_num_tokens_per_expert,使得每个 GPU 都能看到其他 GPU 的计划。
- 规约汇总:例如,GPU0 可以汇总整个节点要发给其他节点的
token 总数。
GPU2 的 NVL 缓冲区布局示意如下:
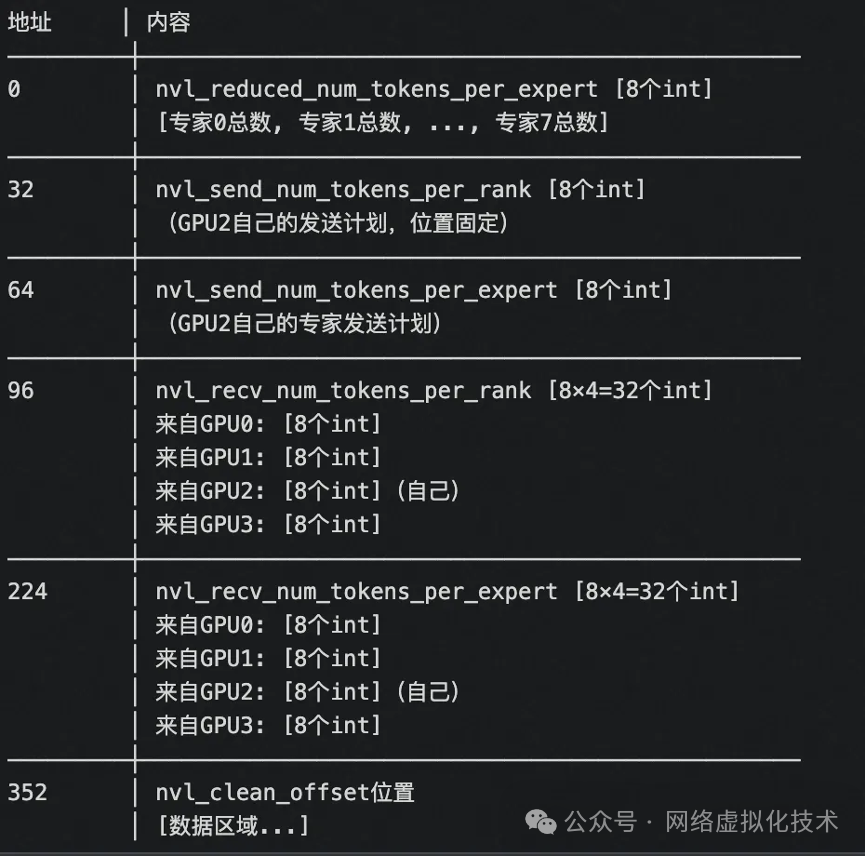
有了缓冲区布局的基础,后续的代码逻辑就清晰了:
- 并行清零
NVLink 缓冲区的数据区域。
- 规约专家
token 数量:每个线程负责一个专家,汇总来自所有 RDMA rank 的 token 数,并将结果写入 NVL 发送缓冲区。
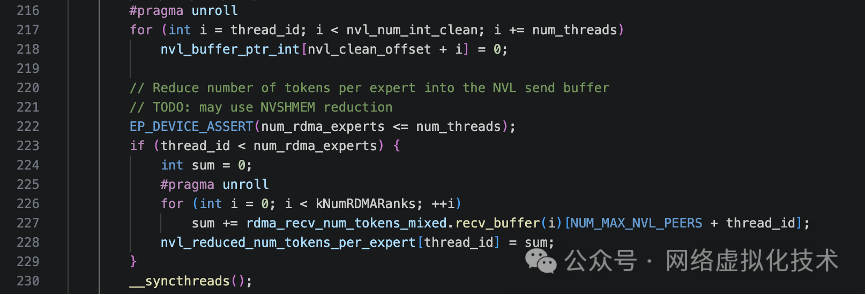
- 将已汇总的
RDMA 级别统计信息,重新分发/转置到每个 GPU 自己的 NVLink 缓冲区中,组织成 (NVL rank, RDMA rank) 和 (NVL rank, expert) 的视图,方便后续按 GPU 维度处理。
前缀和计算与Host侧信息更新
接下来,代码开始计算前缀和,并将关键统计信息更新到 host-mapped 的内存中,供 CPU 侧或其他流使用。
首先,计算按 global rank 的前缀和 (recv_gbl_rank_prefix_sum)。这个前缀和数组非常重要,它使得后续的数据接收和布局阶段,每个 global rank 可以在一个大的连续接收缓冲区中拥有自己的一段确定区间 [ recv_gbl_rank_prefix_sum[i-1], recv_gbl_rank_prefix_sum[i] ),从而实现高效的连续存储和定位。
然后,将计算得到的所有 rank 的 token 总数 (sum) 写入 host-mapped 的全局计数器 moe_recv_counter_mapped。写入前会通过 spin 等待该位置被重置(值为 -1),避免覆盖旧值。这个计数器用于让主机端或其他内核知道本次 dispatch 总共需要接收多少 token,以便提前分配或检查缓冲区。
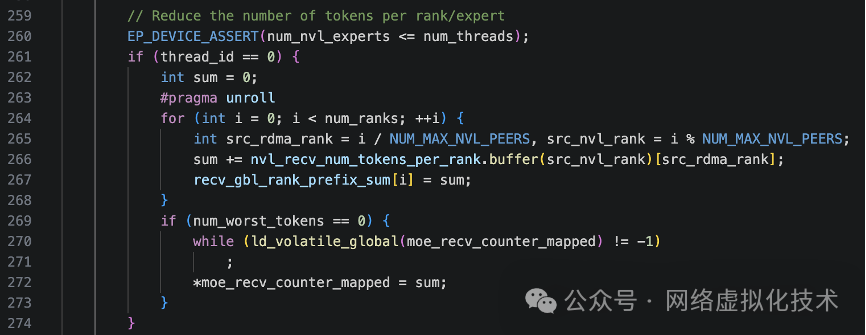
接着,进行节点级的“按专家规约”。每个线程负责本节点上的一个专家,将该专家在所有 GPU 上要处理的 token 数进行加和,得到节点级汇总,然后写入 host-mapped 的 per-expert 计数器 (moe_recv_expert_counter_mapped)。
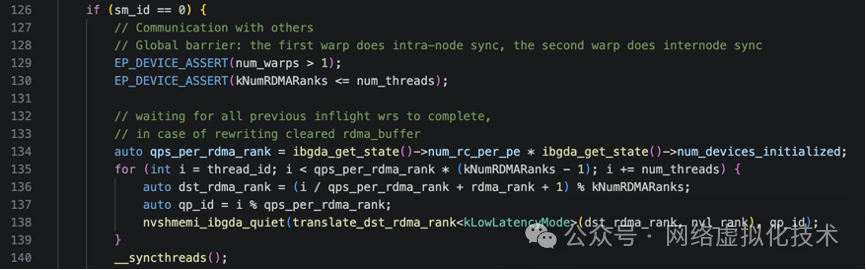
最后,只让一个特定的线程(thread_id == 32)调用 NVSHMEM 的跨节点同步和节点内 barrier,结束 SM 0 的所有工作。这避免了同一个 GPU 上多个线程重复调用集合通信操作。
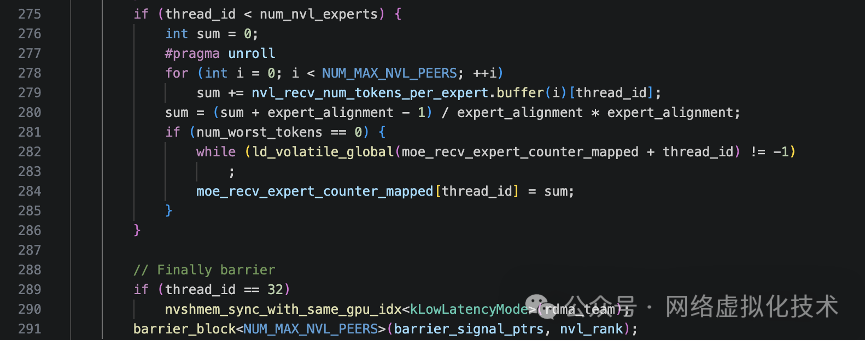
非 SM 0 的并行统计逻辑
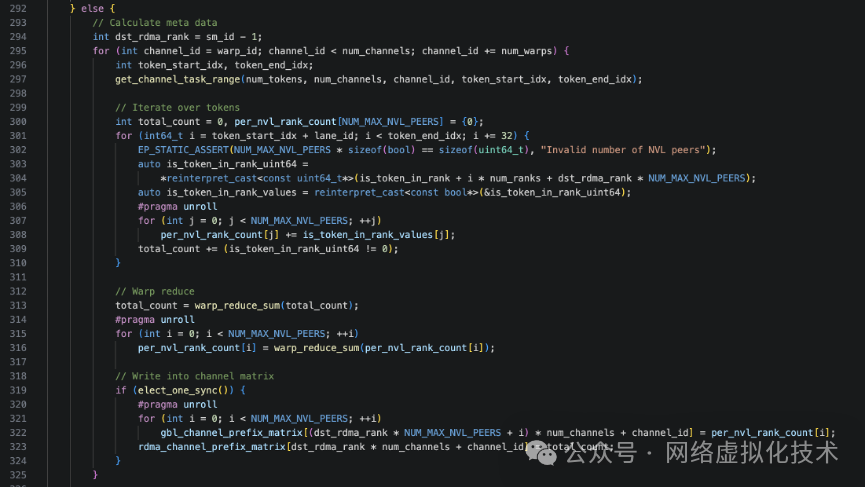
SM 0 负责核心的通信和全局规约,而其他 SM(sm_id != 0)则并行地负责更细粒度的、面向通道 (channel) 的统计工作,这对于构建高性能的后端 & 架构至关重要。
首先,当前 SM 的编号 sm_id 被映射到一个目标 RDMA rank(例如 dst_rdma_rank = sm_id - 1),这意味着不同的 SM 负责统计不同节点的数据。
接着,每个 warp 以 warp-stride 模式遍历分配给它的一组 channel。对于每个 channel:
- 调用
get_channel_task_range(...) 获取该 channel 负责的 token 区间 [token_start_idx, token_end_idx)。
- 利用展开的布尔矩阵
is_token_in_rank,统计当前 channel 内,对目标 dst_rdma_rank 有效的 token 总数 (total_count),以及对这些 token 按目标节点内各个 NVL rank 的分布 (per_nvl_rank_count)。
- 在
warp 内进行规约后,由一个代表线程将结果写入两个矩阵:
gbl_channel_prefix_matrix[global_rank, channel_id]:精确到每个 global rank。rdma_channel_prefix_matrix[dst_rdma_rank, channel_id]:聚合到 RDMA rank 维度。
最后,还需要将通道级的统计结果就地转换为前缀和形式,为后续的数据搬运提供偏移量信息。这由专门的代码段完成:
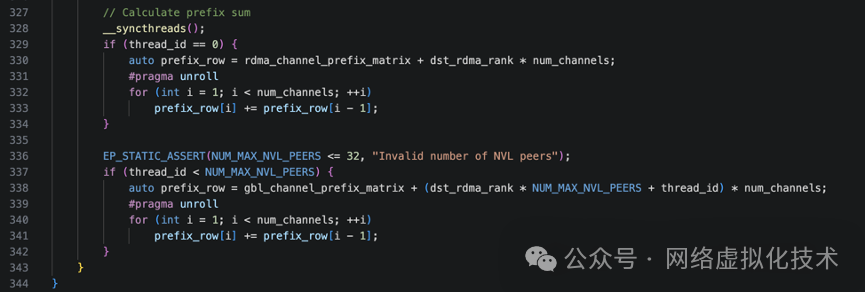
至此,notify_dispatch 的所有工作宣告完成。在主机 CPU 侧,代码会基于映射内存中的 moe_recv_counter 等统计信息,得到节点需要接收的总 token 数量,从而为接收数据分配内存,然后启动后续的 internode_dispatch 数据搬运内核。从整体逻辑看,notify 阶段是一个相对轻量级的“登记”任务,它为后续的重量级数据移动规划好了所有路线。
kLowLatencyMode 的影响
在整个 notify_dispatch 函数中,低延迟模式 (kLowLatencyMode) 主要通过两个内联辅助函数间接影响执行逻辑,主要体现在两个方面:
1. 影响 RDMA 目标 PE 的映射(地址路由)
在等待/清空 QP 或发起 RDMA PUT 时,代码会调用 translate_dst_rdma_rank<kLowLatencyMode>(dst_rdma_rank, nvl_rank)。

kLowLatencyMode = true:将目标 PE 映射为 (rdma_rank * NUM_MAX_NVL_PEERS + nvl_rank),这是一种“每 GPU 一个 PE”的模式。RDMA 操作直接精确发送到目标节点的特定 GPU,避免了先发送到节点代表再通过 NVLink 转发的额外延迟,更适合小批量、延迟敏感的场景。kLowLatencyMode = false:直接使用 dst_rdma_rank,即传统的“每节点一个 PE”模式。RDMA 只发送到节点代表,节点内再通过 NVLink 或共享内存进行转发和规约。这种方式管理的 QP 和连接数更少,利于大规模高吞吐传输。
2. 影响 NVSHMEM 同步接口的选择(全局 vs team)
函数中多处同步调用 nvshmem_sync_with_same_gpu_idx<kLowLatencyMode>(rdma_team)。

kLowLatencyMode = true:调用 nvshmem_sync(rdma_team),仅在给定的 team(例如所有节点上相同 GPU 索引的进程组成的纵向链)内同步。参与同步的 PE 更少,减少了集合通信的开销,对延迟敏感阶段有利。kLowLatencyMode = false:调用 nvshmem_sync_all(),对所有 NVSHMEM PE 进行全局同步。在 PE 数等于节点数的高吞吐模式下,全局同步的成本相对可控。
通过这种灵活的配置,DeepEP 能够在延迟和吞吐之间做出权衡,以适应不同的模型规模和性能需求。这类深度优化正是像云栈社区这样的技术论坛中,开发者们热衷于探讨和学习的开源实战精华。
备注:文中分析的源码对应 commit 3fcf25ed1b50f8abab6bac71e792432f7158fc26。
 发表于 2026-2-2 06:00:57
|
查看: 248|
回复: 0
发表于 2026-2-2 06:00:57
|
查看: 248|
回复: 0
