近日,YouTube技术博主Jeff Geerling发布了一篇详细的博文和视频,分享了他利用四台苹果Mac Studio搭建高性能AI集群的硬核实践。这项实验的核心,是探索苹果在最新macOS 26.2中引入的RDMA(远程直接内存访问)over Thunderbolt 5技术的实际应用潜力。

这一新特性让多台Mac Studio能够像共享同一块巨大的物理内存一样协同工作。简单来说,通过RDMA技术,集群内的机器可以直接在内存层面进行高速数据交换,绕过了传统的网络协议栈,从而将节点间的数据访问延迟从数百微秒大幅降低到几十微秒级别,显著提升了协同计算效率。
在此次构建的集群中,Jeff将4台配备统一内存的Mac Studio组合起来,形成了一个合计约1.5 TB的庞大内存池。对于需要处理超大规模参数的AI推理任务而言,这种内存融合技术带来了显著的性能提升,使得数据在集群间的交换更加流畅。
性能亮点与工具
- 超大模型支持:约1.5TB的统一内存池为运行参数巨大的AI模型提供了可能。
- 极低延迟:Thunderbolt 5 RDMA将机器间延迟降至极低水平,改善了多节点协同计算的效率。
- 关键工具:开源的 Exo 1.0 项目是管理集群内任务分配与内存共享、实现协作运行的核心工具。
配置、成本与性能对比
这套四机集群的硬件总成本接近4万美元,主要花费在Mac Studio本体上。值得注意的是,单台M3 Ultra Mac Studio在多项测试中就已展现出强劲的性能,不弱于一些专业服务器。
以下是博主进行的一些关键性能测试对比:
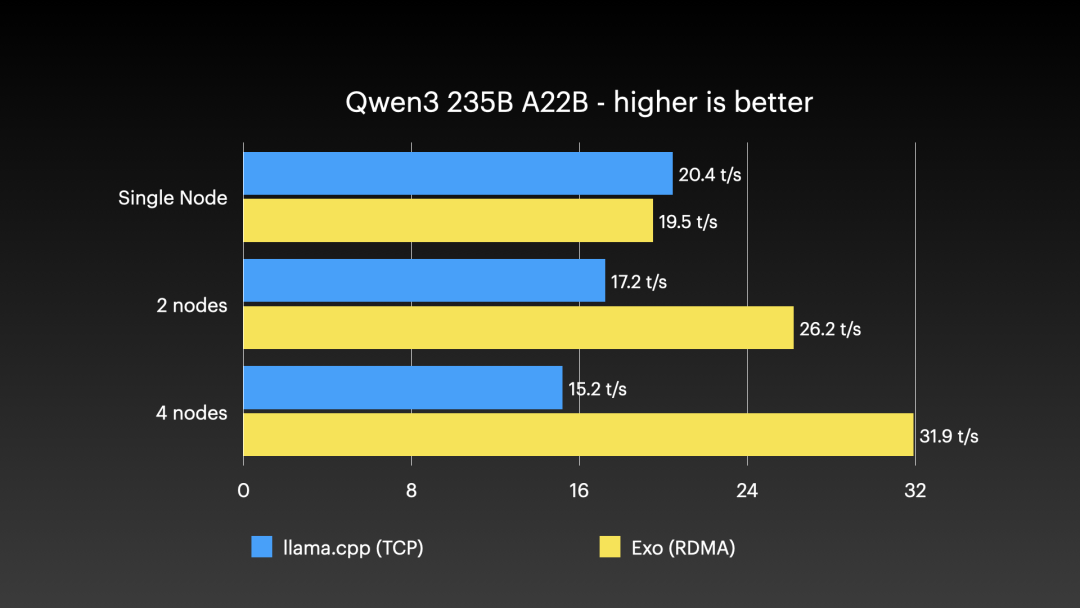
图表显示,在运行Qwen3 235B A22B模型时,随着节点数量增加,使用Exo(基于RDMA)的性能显著优于传统的llama.cpp(基于TCP)方式,证明了RDMA在分布式推理中的优势。
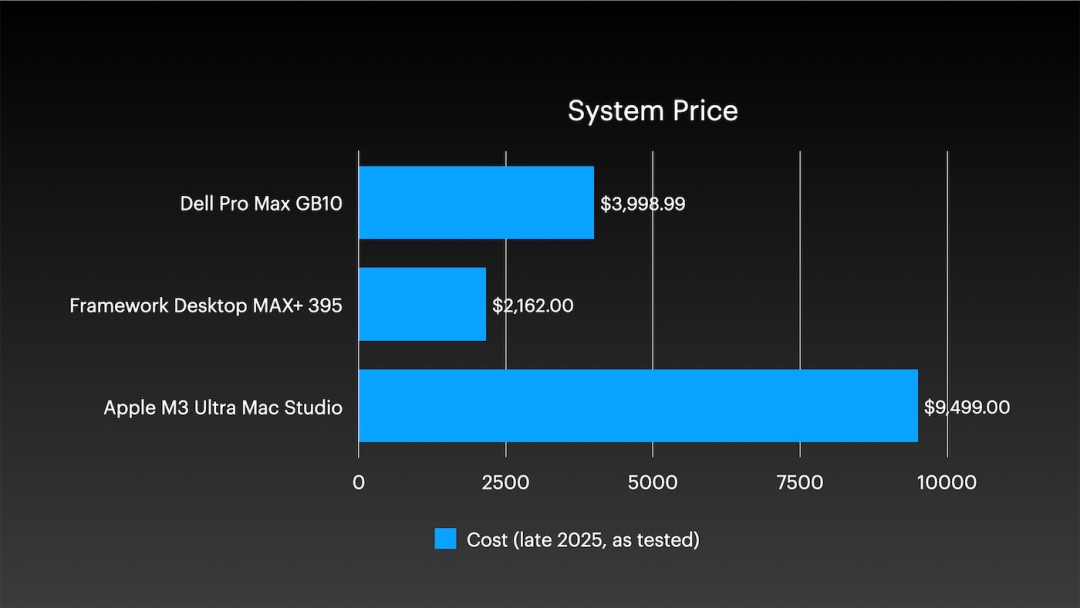
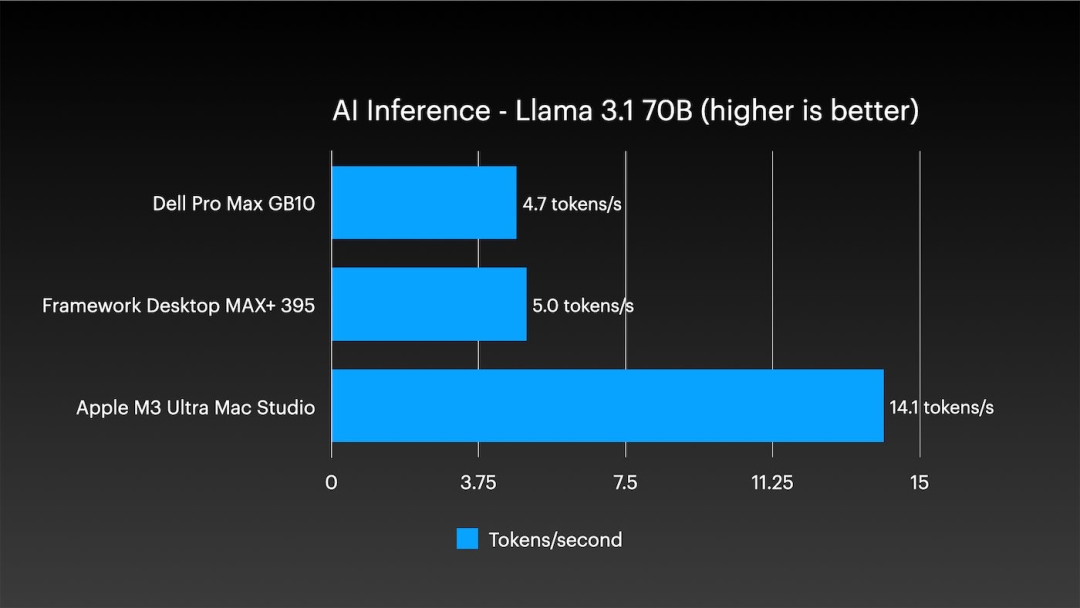
在针对Llama 3.1 70B模型的AI推理测试中,单台Apple M3 Ultra Mac Studio以14.1 tokens/s的成绩大幅领先于其他对比的桌面级系统,展示了其强大的单体计算能力,为构建更高性能的协同计算集群奠定了基础。
当前限制与未来展望
尽管RDMA over Thunderbolt 5是一项令人振奋的技术进展,但它目前仍处于早期阶段,存在一些限制:
- 手动配置:需要手动启用RDMA,设置过程较为繁琐。
- 拓扑限制:受限于Thunderbolt的连接方式,目前最多只能以点对点方式交叉连接4台设备。
- 成熟度:与传统企业级互连方案(如InfiniBand)相比,Thunderbolt在集群化应用的物理连接和管理上还不够成熟。
Jeff Geerling的这次实践,清晰地展示了在macOS平台上借助Thunderbolt 5 RDMA技术构建高性能、大内存AI计算集群的可行性。这为研究者和开发者提供了一种新思路:无需依赖庞大的GPU服务器农场,也能在相对紧凑的桌面级硬件上探索超大规模模型的运行。虽然仍有工程和生态上的挑战需要克服,但这一方向对于本地AI开发、高性能计算等领域都具有重要的参考价值。
本文内容编译整理自Jeff Geerling的分享,更多前沿技术实践与深度讨论,欢迎访问云栈社区。 |  发表于 2026-1-6 17:44:22
|
查看: 415|
回复: 0
发表于 2026-1-6 17:44:22
|
查看: 415|
回复: 0
