AI技术的浪潮,不仅重塑了应用层,也让底层基础设施,特别是网络,迎来了新的挑战与机遇。如今,互联网大厂们正积极投身于一个名为HPN(High Performance Network,高性能网络)的技术赛道。

大厂为什么要卷HPN?
首要原因在于,网工们所熟知的TCP协议,在GPU并行计算的世界里已经显得力不从心。并行计算要求网络能够高效协同分布式的内存与GPU显存,而会丢包的传统以太网、以及为此设计了复杂拥塞控制机制的TCP,在这个场景下都难以胜任。理想的网络必须是无损的,并且能够绕过操作系统内核冗长的协议栈,才能充分释放昂贵GPU的算力。
恰巧,最好的GPU与最适配的网络解决方案出自同一家公司,这种网络就是InfiniBand(IB)。

采用IB方案非常省心,只要预算充足,构建一套NVIDIA全家桶,后续的运维管理相对轻松。但这无疑将网络工程师的价值置于尴尬境地。是可忍孰不可忍,大厂的网络工程师们敏锐地察觉到了机遇:创造一个能够替代IB的方案,自身的价值不就能得到凸显了吗?
因此,大家的目标是向决策层传递一个明确信号:IB是可以被替代的,这只是一个工程问题。决策者们自然也乐见其成,IB生态相对封闭且价格高昂,如果自家团队有能力实现平替,无疑是明智之举。一边是业务需求倒逼技术升级,另一边是网络工程师自我驱动的技术革新,大厂的HPN竞赛就这样拉开了帷幕。

HPN的Scale-up与Scale-out之战
那么,具体竞争态势如何呢?目前的HPN技术已经分化为两个主要方向:用于超节点内部高速互联的 Scale-up,以及用于节点间互联、旨在替代IB的 Scale-out。这个技术框架同样是由行业领导者定义并引领的。
Scale-up网络
所谓Scale-up,最初指的是单台服务器内8张GPU通过NVLink进行的互联。从NVL72架构开始,NVLink技术从机箱内部扩展到了整个机柜,将所有GPU通过Scale-up网络互联的集群就被称为超节点(Superpod)。这类似于网络领域从盒式交换机演进到框式交换机的跨越,超节点对于大模型推理至关重要,因为它将内存语义通信的范围从8卡扩展到了数十甚至上百卡。
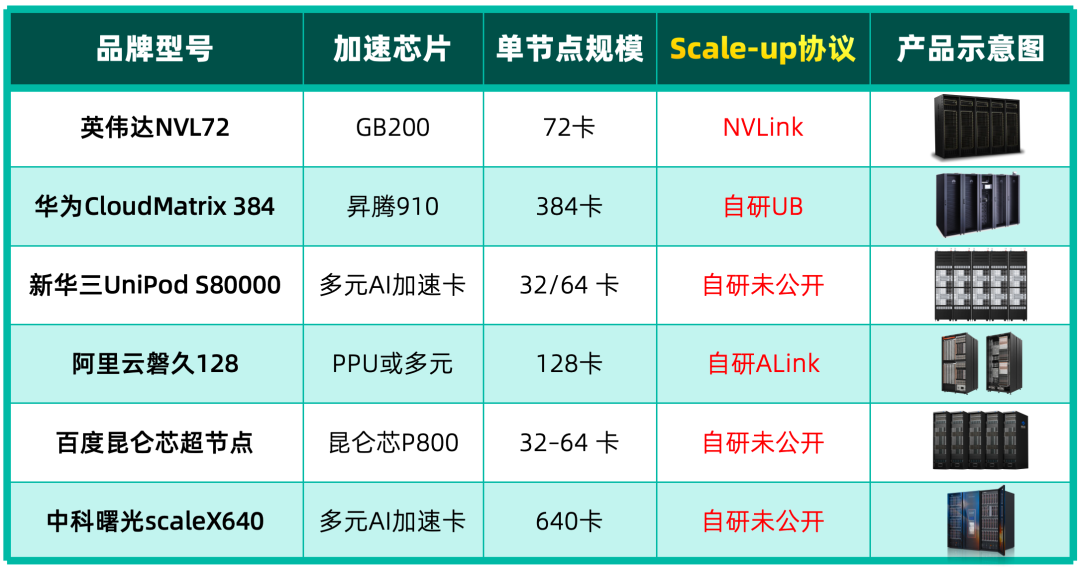
在Scale-up架构中,算力卡是内存I/O的源头,因此技术主导权基本掌握在算力卡厂商手中。从技术原理上看,各家方案大同小异,可以看作是向NVLink“抄作业”:
- 物理层:普遍采用成熟的以太网SerDes技术,产业链完善,供应稳定,开放度高。
- 链路层:同样沿用以太网的封装结构,这层与物理层耦合紧密,自研一套新标准需要面对整个产业生态的挑战。
- 网络层与传输层:这里是体现差异的地方。通常会引入上下游信用(credit)流控、固定信元长度、链路层重传等高级机制,旨在模拟CPU访问内存般的高可靠、低延迟网络。各家的实现细节有所不同。
- 控制面:NVIDIA采用IB的控制面,而其他厂商大多选择功能集大成的BGP协议。
- 标准与供应:UALink是一条由NVIDIA竞争对手主导的开放路线。此外,像华为的UB、以及其他开放以太网增强体系(如Eth+)也在积极发展,呈现出百家争鸣的局面,谁能率先获得重量级应用并扩大市场份额是关键。
对于强势的算力卡厂商,Scale-up是其不容他人染指的核心技术护城河。而规模较小的算力卡厂商则更灵活,能够适配各家的Scale-up方案,并拥有自己的方案去开拓传统行业等细分市场。最终,技术方案可能会像路由协议一样逐渐收敛。
Scale-out网络
GPU通过PCIe连接网卡,网卡再运行RDMA(无论是IB还是RoCE),这种模式就是Scale-out。两年前,Scale-out曾是HPN领域的宠儿,但随着超节点(Scale-up)的兴起,它的地位有所变化。

这种变化不只源于技术,Scale-out的火热与“缩放定律”(Scaling-law)的流行密切相关。该定律曾让许多从业者相信,只要筹集足够资金构建庞大的GPU集群,就能训练出卓越的模型。然而,像DeepSeek这样的模型在一定程度上动摇了这一定律的绝对性,促使更多业者转向推理场景寻求商业化,因此焦点也部分转移到了Scale-up上。当然,真正有雄心的大厂必须持续投入模型训练,Scale-out的研究依然是重点。
同样,在Scale-out领域,也可以将行业领先者作为参考:
- 将PCIe交换功能直接集成到智能网卡,使得GPU、CPU、NVMe等设备直接挂载在网卡上,摆脱对主板和CPU的依赖。
- 网卡直接支持多个物理网络接口,实现多平面网络,并对上层应用只呈现一个RDMA IP地址,屏蔽底层多链路的复杂性。
- 网卡接收端支持乱序报文处理,这在多路径网络中必不可少,借鉴iWARP的DDP(直接数据放置)等技术是合理的工程实践。
- 交换机支持将数据包均匀喷射(Spray)到多条ECMP链路上,或根据动态权重进行分发。
- 新的协议栈具备良好的拥塞控制(CC)算法,能够容忍一定程度的丢包,从而可以摒弃存在缺陷的PFC(优先级流量控制)机制。
Scale-out也是各大厂热闹的竞技场,几乎每家都有自己的RoCE魔改版本,运行在自研的DPU或智能网卡上。这个方向的灵感部分来源于Google的TPU(自带DPU I/O)和OCS(纯光交换)系统。
评价一个Scale-out方案的好坏,不能空谈技术,而要看实际“战功”:
- 拥塞控制算法是否有顶级论文(如SIGCOMM)支撑?
- 算法能否在商用网卡(如CX-7)上运行?
- 能否在不依赖特定高端网卡的情况下,达到相近的性能?
- 是否仅在实验室环境有效,有没有在实际生产网络部署?
- 实际部署的规模如何,头部应用是否将其作为主力方案?
- 使用该方案的头部应用本身是否成功?
自上而下,“战功”的含金量依次递增。

从技术角度看,Out和Up有共同点。例如“有损RDMA”(Lossy RDMA)旨在消除烦人的PFC,交换机最多运行ECN,甚至完全由端侧网卡通过测量时延变化来实施拥塞控制。简言之,高级的拥塞控制功能正从交换机向端侧网卡转移。
基于无PFC、容忍丢包的设计思路,设计这套CC算法的网络工程师很自然地会想到将Scale-out网络与传统的数据中心网络(DCN)合并。对于自带网络方案的强势算力卡厂商,Scale-out是其生态的一部分;而大厂的网络工程师们,则主要服务于那些没有自研网络的小算力卡或自研算力卡厂商。
一个实用的技术评价指标是:在丢包率为 a% 的网络中,能达到 b% 的传输效率。a+b 的值越接近100,说明这套魔改的RoCE协议栈性能越优秀。
Scale-out能和传统数据中心网络合并吗?
将Scale-out网络与数据中心前端(机头)网络合并,这个颇具想象力的想法在现实中并未大规模实现。主要技术原因是Scale-out所需的带宽和收敛比与传统DCN的需求并不完全一致,强行合并带来的改造和适配成本可能远超收益。
但机头DCN网络确实存在RDMA的需求,主要来自两个方面:云存储和AI推理。
先说存储:
当宿主机提供云盘挂载给云主机或容器时,宿主机访问后端存储集群是Underlay网络。在Underlay中运行RDMA,可以消除内核TCP协议栈的处理延迟,收益明确,这也是RDMA最早得到应用的场景之一。
而当云主机或容器直接访问云盘时,流量位于Overlay网络内。这就要求魔改的RoCE能够运行在Overlay里,这是近期的技术热点。
再说AI推理:
随着“训推分离”和“算存分离”被验证有效,不同任务可以使用不同的算力卡。任务间传递的KV(键值)对存储在HDFS等存储集群中,而任务运行在容器里。因此,容器访问HDFS中的KV数据,天然就是一个Overlay RDMA场景,这也推动了RDMA在DCN内的普及。
DCN内的RDMA将是各方技术展示的重要舞台,因为这里没有与特定算力卡的强绑定,是网络工程师们最能稳固发挥的“基本盘”。明确的需求已经出现,关键在于能否抓住机会,率先完成验证并扩大应用规模。

HPN最初源于HPC领域的RDMA网络,进入大厂后演变为IB与RoCE之争。随着NVLink技术突破机箱限制迈向机柜级互联,Scale-up网络兴起。原有的RDMA网络则被划分为Scale-out。而Scale-out的网络协议栈技术又开始尝试融合进入DCN领域,并在此获得了更自由的设计空间。当然,也有工程师设想将这几种协议栈最终融合,这仍需业务成果来检验。
最终的评价标准可以归结为两点:
- 你推出的HPN方案在大厂内部的覆盖率如何?如果不到10%,影响力自然有限。
- 有哪些模型训练或推理任务运行在你的HPN上?是自娱自乐的小型测试,还是日活百万、千万乃至上亿的核心应用?
达不到这两条硬性标准,无论技术宣传得多么天花乱坠,都显得虚浮。

技术探讨永无止境,欢迎在云栈社区继续交流高性能网络与基础架构的更多洞见。
 发表于 2026-1-13 00:39:49
|
查看: 200|
回复: 0
发表于 2026-1-13 00:39:49
|
查看: 200|
回复: 0
