在AI技术向千亿参数、万卡集群规模飞速演进的当下,网络已从传统的数据传输通道,升级为制约算力能否被彻底释放的核心枢纽。传统网卡(NIC)受限于其架构设计,往往难以适配AI训练与推理两者之间差异化的严苛需求。而NVIDIA最新推出的ConnectX-8 800G SuperNIC,以“超越网卡的智能互联ASIC”这一全新定位,正在重构高性能计算的网络底层逻辑。

一、从“组件拼接”到“一体化互联中枢”
传统数据中心往往采用“CPU、GPU、存储、网卡各司其职”的离散架构。在这种模式下,网卡仅承担数据包封装与有序交付的基础功能,导致组件间的协同效率低下,形成了显著的性能瓶颈。ConnectX-8的诞生,彻底打破了这一桎梏,它构建了一个“硬件加速+软件协同+生态整合”的一体化智能互联架构。
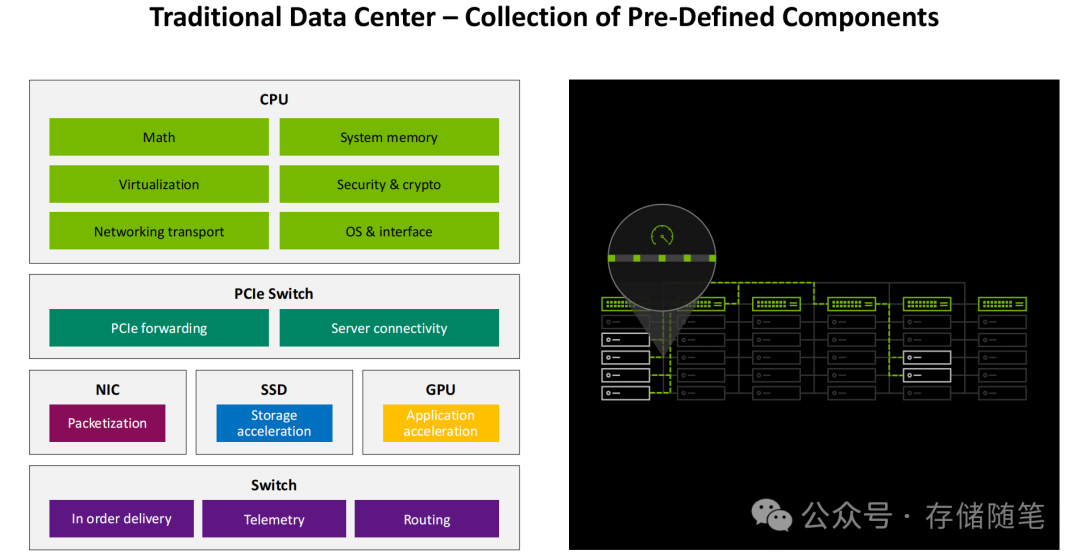
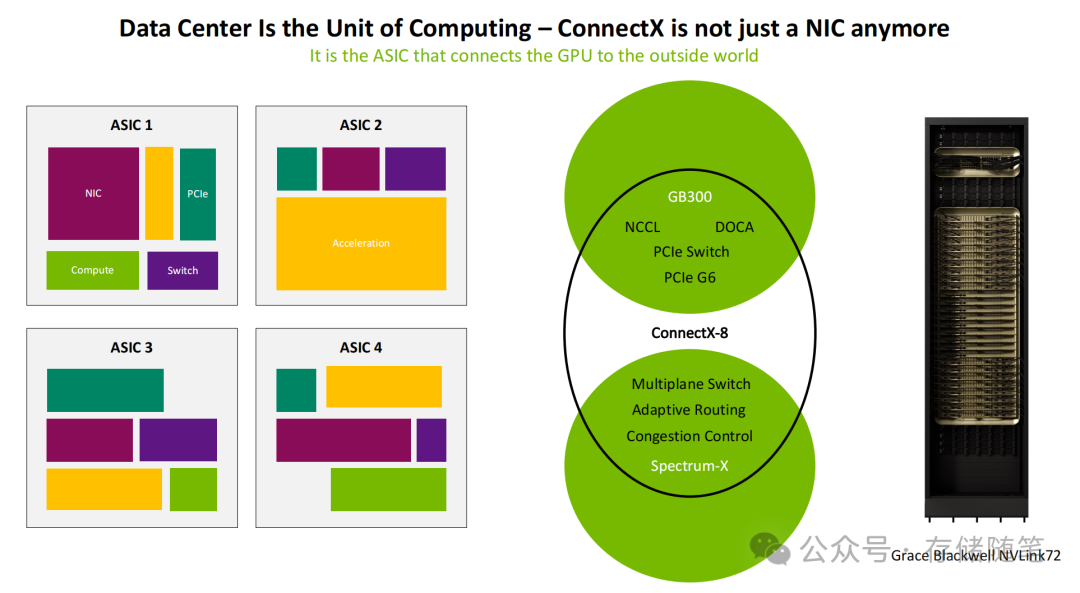

其核心由六大关键模块协同构成,共同定义了新一代AI网络的硬件基石:
- 多协议网络接口层:支持800Gb/s InfiniBand XDR与2x400G以太网双模接入,最多可扩展至8个端口,完美适配不同数据中心的网络架构选择。其中InfiniBand XDR保障极致低延迟,以太网则兼顾生态兼容性与部署灵活性,真正实现了“一卡适配全场景”。

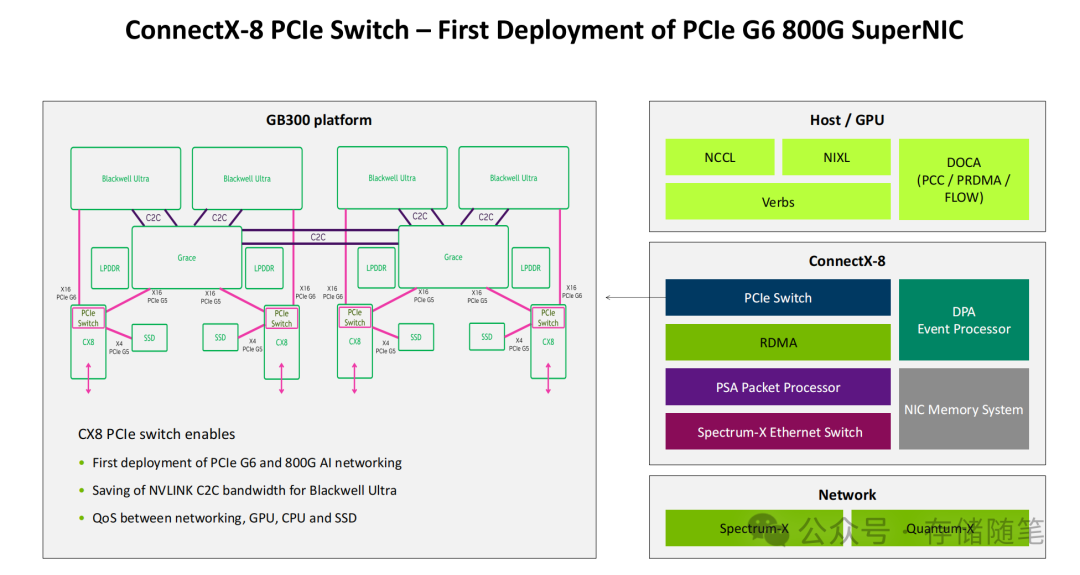
- 高速Host/IO接口层:搭载48通道PCIe Gen6接口,理论双向带宽达128GB/s,是PCIe Gen5的2倍,彻底消除了主机接口的带宽瓶颈。更重要的是,其集成了PCIe交换机,实现了GPU、CPU、SSD与网络的直接互联与高效资源调度。在GB300平台中,这一设计能有效避免不同设备间的带宽争抢。
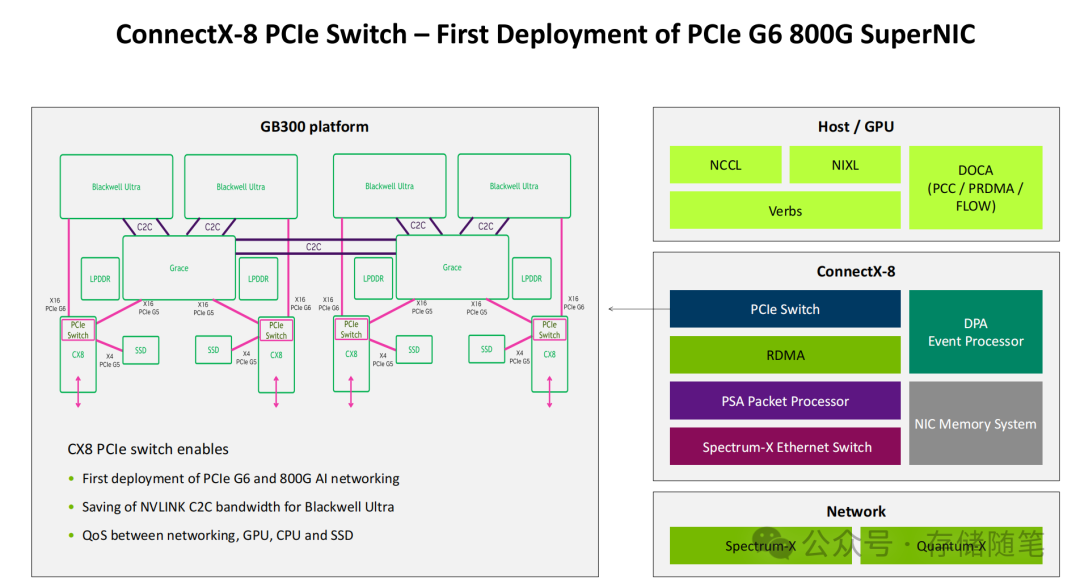
- 增强型RDMA传输层:采用线速RDMA传输架构,支持乱序交付、可编程拥塞控制与智能重传,能够绕过CPU直接实现GPU/CPU内存访问。通过硬件级优化,数据包传输时间低至2ns,网络往返时间(RTT)控制在5-10us,为AI集群的同步通信提供了坚实的底层保障。
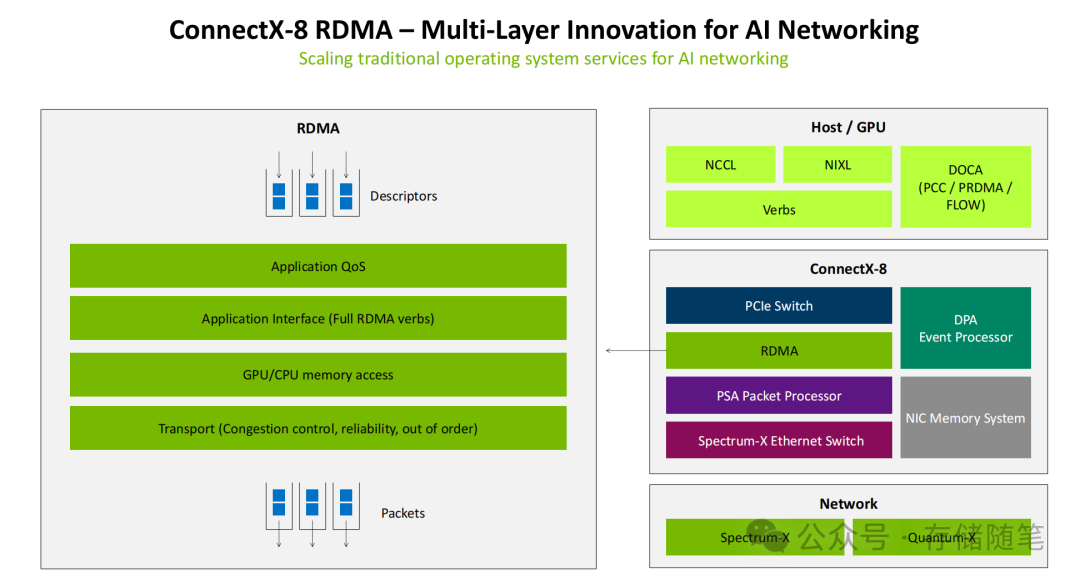

- 智能数据包处理层:集成PSA多线程包处理器,支持线速网络加密、多租户隔离与可编程路由。在保障数据安全的同时,可根据AI任务特性动态调整路由策略,灵活满足训练任务的大规模数据传输与推理任务的高频小数据包交互需求。
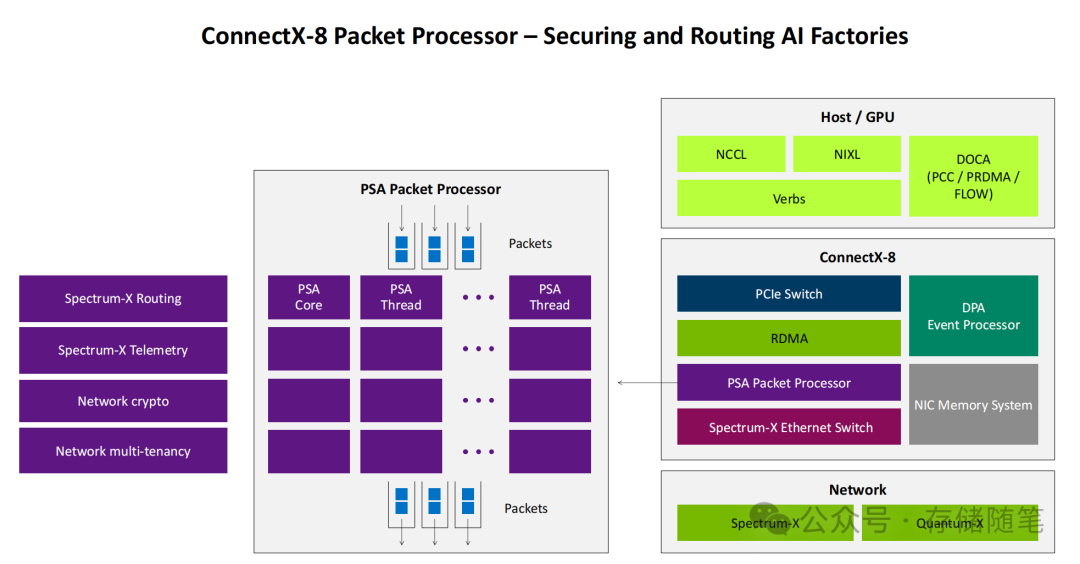
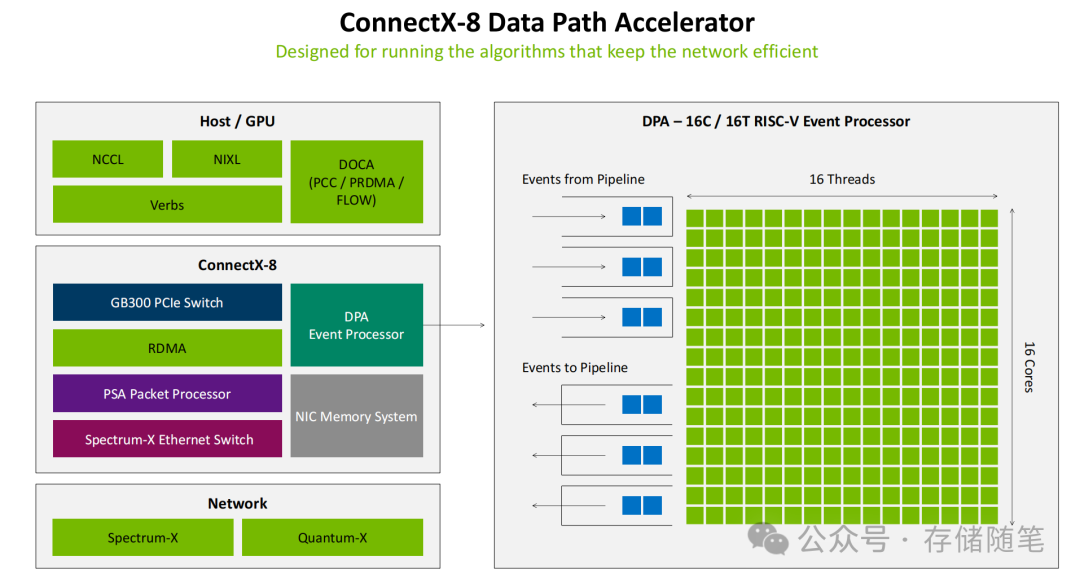
- 硬件可编程加速层:搭载DPA 16核16线程RISC-V事件处理器,专门用于运行实时网络优化算法。通过硬件级的并行处理,可以实现微秒级的拥塞状态感知与路由动态调整,其响应速度较CPU干预提升百倍,且完全不占用主机宝贵的计算资源。
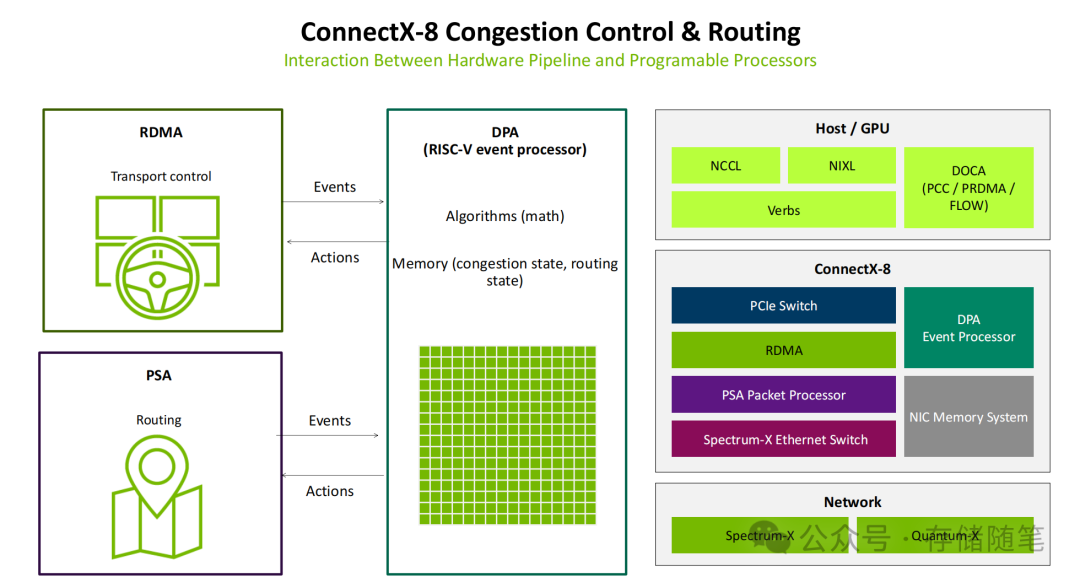
核心逻辑:“硬件执行+软件智能”的协同
传统网络设备的拥塞控制与路由往往是“固定的硬件逻辑”,难以适配AI场景下瞬息万变的复杂需求。而ConnectX-8通过DPA的可编程能力,实现了一种革命性的协同模式:
- 硬件层(RDMA/PSA)负责“执行”:RDMA硬件通道负责高速数据传输控制,PSA则负责数据包的路由决策。两者会将实时网络事件(如拥塞、链路状态变化)传递给中间的DPA处理器,并快速执行DPA下发的优化动作指令。
- 软件层(DPA算法)负责“智能决策”:DPA作为基于RISC-V的“网络大脑”,运行着拥塞控制、路由优化等核心算法,并存储着当前的网络状态。它通过“接收事件→计算决策→下发动作”的闭环流程,动态协调RDMA和PSA的工作。
- 生态协同软件层:提供DOCA-PRDMA、DOCA-PCC、DOCA-FLOW等专用软件接口,并与NCCL(NVIDIA Collective Communications Library)、NIXL、RDMA Verbs深度兼容。尤其是与NCCL的协同优化,让AllReduce、AllToAll等AI核心通信操作的性能得以最大化。
最终,ConnectX-8达成了“既能跑满极限带宽,又能动态优化延迟、智能避免拥塞”的效果——这正是它能支撑超大规模AI集群稳定、高效运行的关键。
此外,面对AI训练与推理工作负载的显著差异,ConnectX-8通过软硬件协同设计,实现了“一款硬件覆盖全场景”的灵活性:
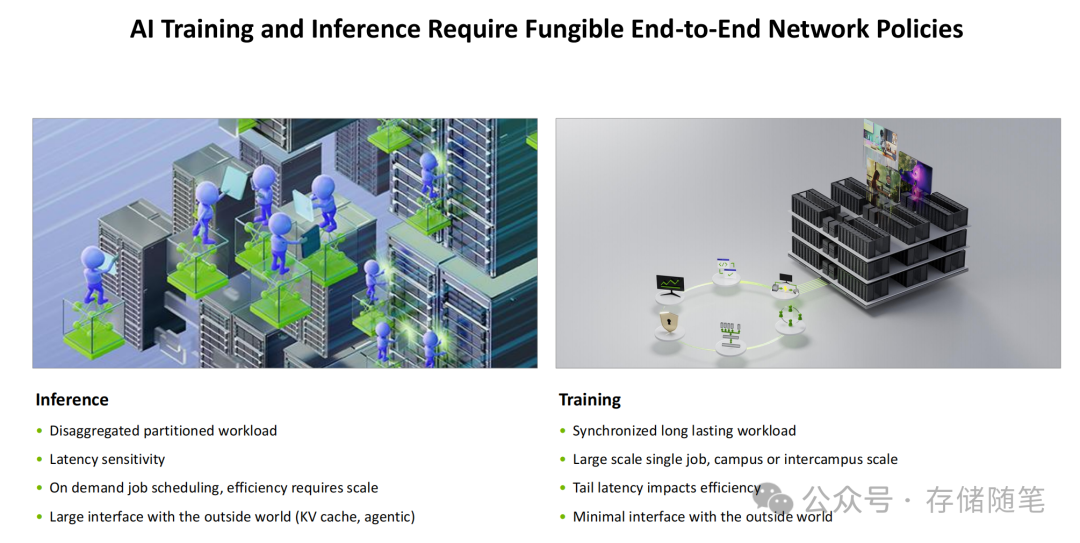
(1)AI训练场景:同步大规模任务的专属优化
针对训练任务“同步长期运行、跨园区规模、尾延迟敏感”的特点,ConnectX-8提供了大规模集体通信优化、多平面网络架构支持以及最小化外部接口干扰的能力,通过硬件隔离确保训练任务的绝对稳定性。
(2)AI推理场景:离散型任务的高效响应
面对推理任务“离散分区、低延迟需求、按需调度”的特性,ConnectX-8凭借其低延迟数据传输、灵活的任务调度支持以及硬件级的多租户隔离,能够完美满足用户交互、Agentic等场景对实时响应与安全共享的需求。
二、破解AI网络三大核心痛点
AI训练与推理对网络提出了“高带宽、低延迟、大规模”的三重极致诉求。ConnectX-8通过一系列针对性技术创新,实现了三大核心突破:
1. 带宽突破:800G线速传输,无瓶颈适配算力需求
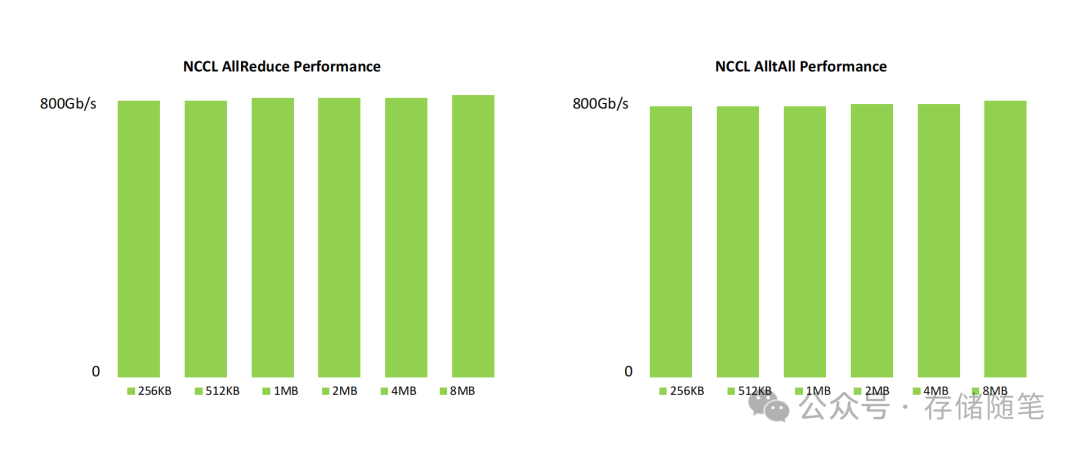
ConnectX-8的RDMA传输层与PCIe Gen6接口形成了完美协同。实测显示,从256KB到8MB不同大小的数据块,其NCCL AllReduce与AllToAll操作均能稳定达到800Gb/s的线速。这意味着单卡即可支持8倍于传统100G网卡的数据传输能力,完美匹配Blackwell Ultra GPU等新一代算力硬件的输出需求,从根本上避免了“算力强、网络弱”的错配问题。
2. 零尾延迟设计,保障同步计算效率
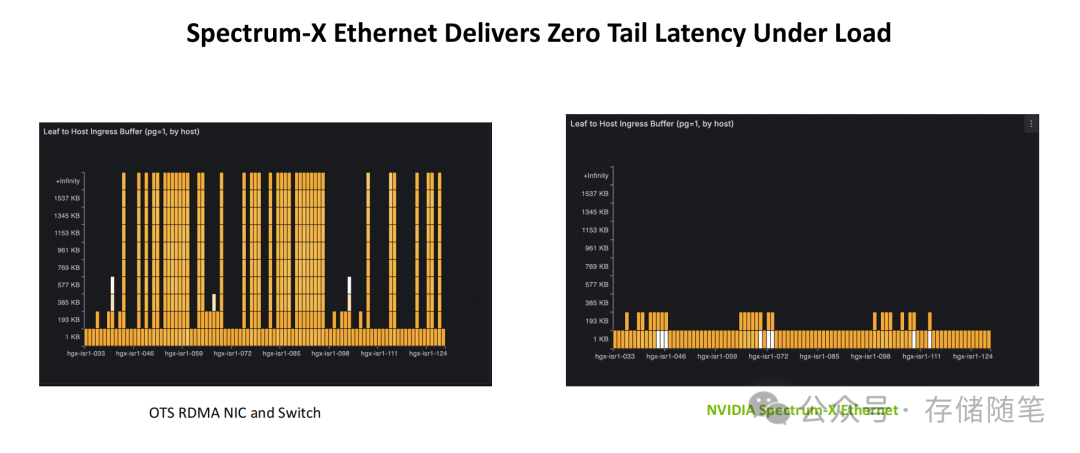
AI训练的同步特性使其对尾延迟(即集群中最慢的数据传输延迟)高度敏感,微小的延迟差异会被集群规模放大,导致整体效率急剧下降。ConnectX-8通过三重技术实现精准的延迟控制:RDMA乱序交付避免了有序传输导致的等待累积;Spectrum-X自适应路由能够实时规避拥堵链路;DPA硬件加速的拥塞控制可实现微秒级的传输策略调整。实测数据表明,在多任务负载下,其Leaf到Host的入口缓冲区占用量趋近于零,真正实现了“零尾延迟”运行。
3. 从2K到128K,GPU集群的弹性伸缩
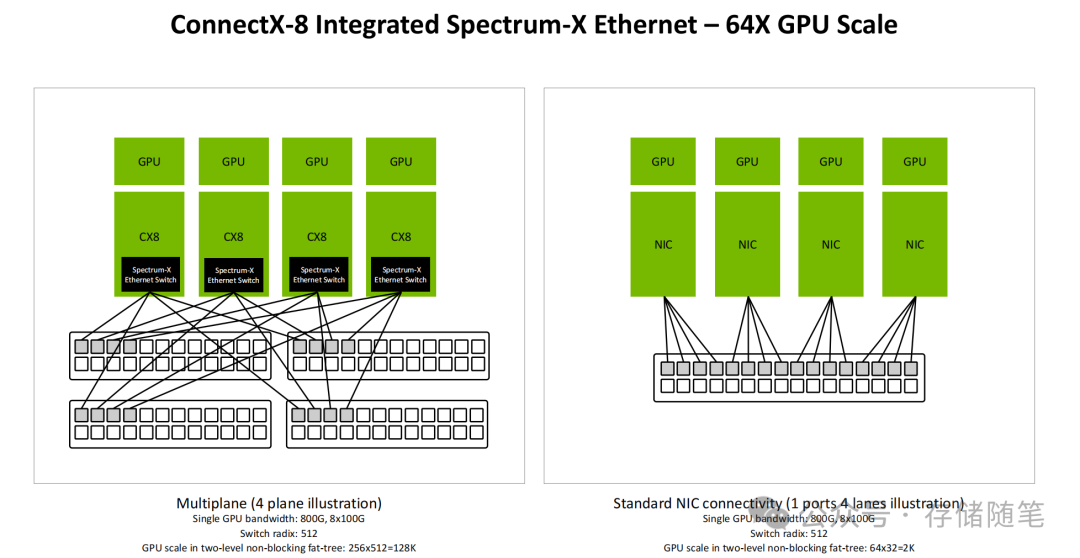
在传统的NIC+交换机方案中,受限于架构,两层无阻塞胖树拓扑下的GPU集群规模上限通常仅为2K。而ConnectX-8在集成Spectrum-X以太网交换机后,通过创新的多平面设计,单交换机的端口密度(radix)可达512,使得两层架构即可支持高达128K的GPU集群规模。同时,其集成的智能负载均衡与故障自愈能力,确保了即使部分链路发生故障,系统也能快速重分配数据流,保障大规模训练任务不中断。
三、性能实测:数据见证革命性提升
来自NVIDIA的实测数据直观地展现了ConnectX-8结合Spectrum-X网络所带来的性能优势。与传统RDMA网卡加商用交换机方案相比,其核心提升体现在三个方面:
1. 训练效率大幅提升
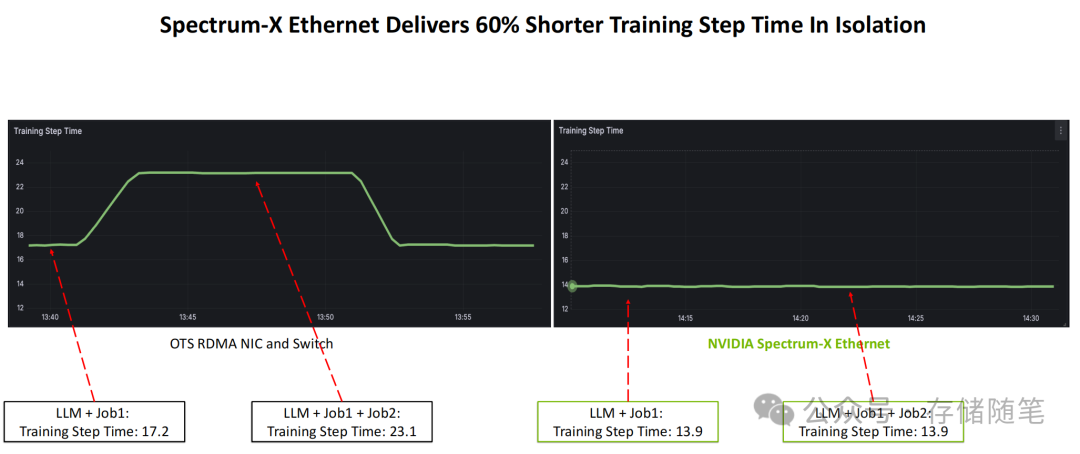
在大型语言模型(LLM)的训练场景中,传统方案在运行单任务(LLM+Job1)时,训练步长时间为17.2秒;当增加一个并发训练任务(LLM+Job1+Job2)后,步长时间会因网络干扰飙升至23.1秒。而采用ConnectX-8+Spectrum-X的方案,在单任务和多任务负载下,训练步长时间均稳定在13.9秒。这意味着在多任务负载下,训练效率提升了约60%,极大加快了模型的迭代速度。
2. 带宽与通信性能突破
- 有效带宽提升1.6倍,实现了对全部网络链路资源的高效利用。
- 集体通信带宽提升1.3倍,更好地适配大规模集群协同计算。
- AllReduce带宽提升2.2倍,显著加速了模型参数的同步过程。
- AllToAll带宽提升1.3倍,优化了分布式训练中数据洗牌(shuffle)的效率。

3. 运维与可靠性升级
网络遥测(Telemetry)数据的收集速度提升了1000倍,使得运维系统能够实时获取链路利用率、延迟、拥塞状态等关键信息,为网络的动态优化提供了数据支撑。同时,其智能负载均衡与故障自愈能力,能有效消除网络热点,避免因单点链路故障而导致整个训练任务中断,实现了网络运行的“弹性可靠”。
四、生态协同:构建AI网络的完整解决方案
ConnectX-8的核心竞争力不仅在于其颠覆性的硬件创新,更在于其背后由NVIDIA构建的端到端软硬件生态协同:
- 硬件层面:与Blackwell GPU、Grace CPU、Spectrum-X/Quantum-X交换机、高性能SSD深度适配,形成了从计算、互联到存储的“一体化解决方案”。
- 软件层面:全面兼容SONiC、Cumulus等主流开源网络操作系统,并支持NetQ、Air等高级管理工具,大幅降低了超大规模AI集群的运维复杂度。对于开发者,DOCA SDK提供了统一的编程接口,支持自定义网络功能与策略,以灵活适配不同行业多样化的AI场景需求。
结语:SuperNIC定义AI网络新范式
ConnectX-8 SuperNIC的推出,标志着网络设备从“被动的数据传输者”向“主动的算力赋能者”的战略转型。它不再是数据中心里一个简单的辅助组件,而是进化为连接GPU与外部世界的核心ASIC。通过800G极限带宽、零尾延迟保障、128K集群弹性扩展等突破性能力,它系统地破解了AI时代的网络性能瓶颈。
对于致力于AI前沿探索的企业与机构而言,ConnectX-8不仅能极大提升现有算力集群的利用率与任务完成效率,更能降低超大规模AI集群的总体部署与运维成本,从而加速大模型、生成式AI等尖端技术的产业化落地。
随着AI技术向更深层次、更广范围渗透,网络作为“算力动脉”的重要性将持续凸显。ConnectX-8所定义的“可编程、高带宽、低延迟、全生态”智能网络新范式,有望成为未来AI数据中心的标准配置,推动AI算力从“单点突破”迈向“集群协同”的全面释放。
本文深入探讨了AI网络基础设施的最新进展。想了解更多关于云计算、高性能计算及前沿硬件技术的深度解析与社区讨论,欢迎访问云栈社区,与广大开发者共同交流成长。
 发表于 2026-1-22 08:11:36
|
查看: 341|
回复: 0
发表于 2026-1-22 08:11:36
|
查看: 341|
回复: 0
