
随着AI大模型训练进入“万卡”时代,计算集群的架构正从单系统纵向扩展,转向由数万个节点横向互联的复杂形态。在这种性能高压下,网络互联技术的重要性被重新推至台前,而“RDMA国产化”也再度成为业界热议的焦点。
RDMA(Remote Direct Memory Access),即“远程直接内存访问”,本质上是一种旨在提升效率的网络通信协议。它允许一台计算机绕过操作系统内核,直接访问另一台计算机的内存。这种机制极大地解放了CPU的工作压力,有效降低了通信延迟,并显著提升了数据传输速率与整体计算性能。
从网络协议的具体实现来看,RDMA主要分为三大技术路线:InfiniBand(IB)、RDMA over Converged Ethernet(RoCE)以及Internet Wide Area RDMA Protocol(iWARP)。
目前,IB是高性能计算领域公认的顶级解决方案,但其技术生态长期由Mellanox(现已被英伟达收购)主导,国内厂商获取核心技术和生态支持存在较高门槛。RoCE则被视为IB的一种“高性价比”替代方案,国内众多厂商正致力于基于RoCE追赶IB的网络性能,但其核心网关芯片同样依赖博通等海外厂商。iWARP基于TCP/IP协议,性能相对较弱,本文不做深入讨论。
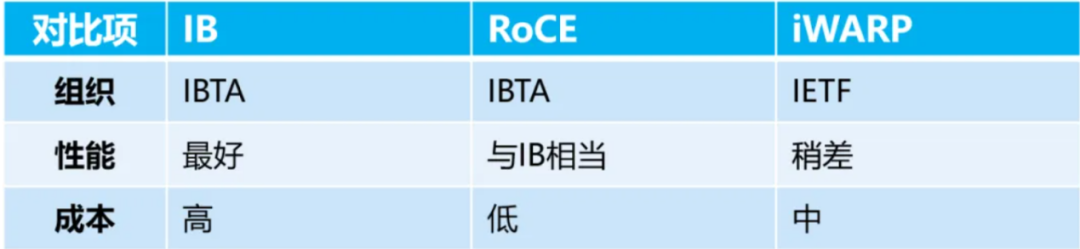
近年来,超大规模智算集群的扩展需求爆发式增长,以IB和RoCE为代表的两大主流网络技术路线,在实际性能上的差距日益凸显。尤其是在面向万卡级计算系统的高速互联场景下,后者作为IB的“低成本替代品”,所承受的网络性能压力巨大。尽管国内不乏RoCE的重要参与者,却始终难以完全替代IB的地位。
究其根本,这两条技术路线在设计上就存在本质差异:
InfiniBand (IB):作为专为高性能计算设计的网络通信标准,IB天生具备极高的吞吐量和极低的延迟。它主要用于服务器间、服务器与存储系统间的直接或交换互连,是一种RDMA原生的网络协议。IB网络需要通过专用硬件来实现最优性能,这也导致了较高的设备成本,且其技术生态长期被海外阵营垄断,成为国产厂商难以企及的“白月光”。
RoCE:这更像是一种“曲线救国”的折中方案。RoCE基于以太网链路层协议,其v1版本在网络层仍使用了IB规范,而v2版本则使用了UDP+IP,使得数据包可以被路由。RoCE被认为是IB的“低成本解决方案”,可以将IB报文封装成以太网包进行收发。由于RoCE v2可以使用标准的以太网交换设备,过去在国内企业中的应用相对广泛。但在相同场景下,其性能相比IB有明显损失,这也成了国产算力扩展中一个难以回避的痛点。
具体而言,RoCE与IB在以下几个关键维度上存在显著差距。当面对万亿参数模型和万卡计算集群成为主流的今天,这种性能鸿沟已变得难以承受。
- 带宽:目前市场上最新一代IB网络是NDR(400G),而国内RoCE网络最高仅能提供200G带宽的产品,两者之间已拉开整整一个代差。
- 延迟:IB交换机可以实现“存储转发”或更优的“直通”模式,交换延时可低至100ns量级。而RoCE交换机通常需要先存储再转发,交换延时普遍在300ns~500ns,在短消息频繁交互的训练场景中,这种差距会被急剧放大。
- 流控机制:IB网络采用基于信用(Credit-based)的流控方案,能够保证报文不会因为接收端资源不足而被丢弃,实现了真正意义上的无损网络。RoCE网络则基于无损以太网的PFC(优先级流控制)暂停机制,该方案在实际大规模组网中仍有较大的丢包风险,对于追求稳定性的长时间训练任务而言,这是很难接受的。
- 拥塞控制:RoCE网络严重依赖拥塞控制机制来避免因拥塞导致的丢包,厂商通常会强制要求用户开启此功能。但其拥塞控制算法(如DCQCN)中水线(Threshold)的调整,与网络拓扑结构及具体应用流量模型紧密相关,非常依赖运维人员的经验。IB网络得益于其优秀的流控机制,拥塞控制并非必须选项;即便开启,其效果也不依赖于复杂的人工水线调整,使得整个网络系统的使用和维护更为简单。
- 组网规模:目前IB网络已被验证可支持数万节点以上规模的组网,且在整个集群范围内都能保持极佳的性能一致性,因此在顶级超算和智算场景中获得了广泛认可。RoCE网络虽然在理论上也支持较大规模组网,但由于其在跨POD(性能域)通信时性能衰减较为明显,厂商通常不建议进行大规模的跨POD通信,更适用于中小规模的集群组网。
此外,在实际的网络部署与运维层面,IB网络通常配置简单,接近于“即插即用”。而RoCE作为以太网络的一种增强,其配置过程相对复杂,涉及PFC、ECN、DCQCN等诸多参数的调优。这导致RoCE的用户需要在集群运行过程中持续观察网络状态并进行针对性配置,运维成本较高。IB网络则需要在前期掌握其专用管理指令,一旦配置完成,后续的维护工作反而相对轻松。
伴随着超大规模智算集群建设不断提速,网络互联性能已成为释放庞大算力效能的关键瓶颈。受限于RoCE与IB之间的种种差距,发展国产高性能RDMA技术的呼声日益高涨。近期业内亦有消息称,已有头部计算厂商将目光投向了追求原生无损特性的国产IB网络路线。
但需要正视的是,相较于已在国内市场有广泛应用的RoCE方案,IB路线的国产化生态起步较晚。对于部分用户而言,可能仍需通过IPoIB(IP over InfiniBand)功能来运行某些基于IP协议的传统应用,在特定场景下的性能表现可能面临挑战。
当然,IB技术本身符合IBTA开放标准,协议生态相对开放,且能与主流技术路线兼容,其应用价值与市场前景毋庸置疑。
事实已经证明,真正的RDMA高性能体验,很难通过基于以太网的RoCE方案来完美模拟或替代。对于志在跑赢万卡时代的中国AI产业而言,进军高性能的原生IB技术路线,似乎已成为一道必须跨越的战略隘口。
期待国内厂商能够持续攻坚,在高性能网络与云原生算力基础设施领域取得突破,真正补全中国AI计算产业链中的这关键一环。对此话题有更多见解或实践经验,欢迎在云栈社区这样的技术论坛与广大开发者交流探讨。 |  发表于 2026-3-10 02:20:45
|
查看: 397|
回复: 0
发表于 2026-3-10 02:20:45
|
查看: 397|
回复: 0
