当我们谈论显卡(GPU)的强大性能时,我们实际上是在谈论它内部成百上千个微小计算核心的协同工作。要真正理解 GPU 为何能驱动庞大的 AI 模型,我们需要把目光聚焦在 GPU 最基本的执行单元——流式多处理器(Streaming Multiprocessor,简称 SM)。
为了方便理解,我们先统一一下文中将频繁出现的几个核心术语:
名词科普
- SM(Streaming Multiprocessor):流式多处理器,GPU的核心计算单元。
- GPU(Graphics Process Unit):图形处理器单元,现已广泛用于通用计算和人工智能。
- GPC(Global Processor Cluster):全局处理器集群,包含多个TPC(纹理处理集群)和SM。
- Tensor Core:张量核心,专为加速矩阵运算而设计的专用硬件单元。
- SFU(Special Function Unit):特殊函数单元,用于处理超越函数(如sin,cos)。
SM 在 GPU 架构中的位置
如果把一颗 GPU 比作一座现代化的工业园区,那么 SM 就是其中最核心的“生产车间”。下面我们通过 NVIDIA GA100 架构的拆解图,由表及里地观察 SM 在 GPU 系统中的层级位置。
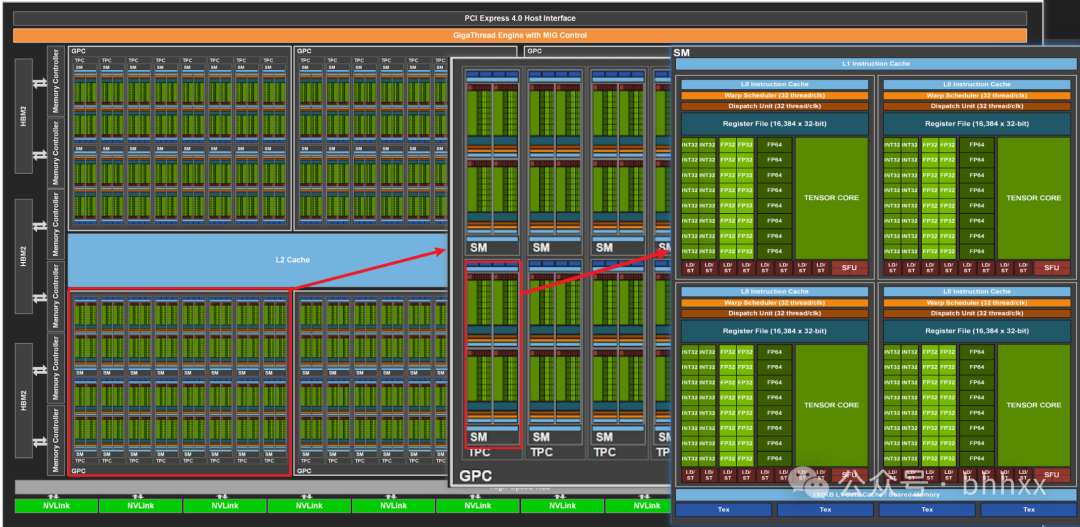
从上图可以看出清晰的架构递进关系:GA100 芯片整体 -> GPC(全局处理器集群) -> SM(流式多处理器)。从宏观上看,一颗GPU芯片中集成了数十乃至上百个这样的SM“车间”,它们是所有算力的源泉。
SM 内部构造:硬件排布与角色划分
走进这个“生产车间”,其内部构造极其精密。为了高效完成计算任务,SM 内部被划分为三大功能区(本文重点讨论其在通用计算和智能&数据&云场景下的作用)。
核心生产区 —— “流水线工人”
这是真正执行计算的地方,不同类型的核心各司其职:
- CUDA Cores(通用工人):执行整数(INT32)和浮点数(FP32/FP64)运算,是通用计算的骨干。
- Tensor Cores(AI 专家):专门用来加速深度学习中的矩阵乘法(如
A*B+C),是AI训练和推理性能飞跃的关键。
- SFU(数学家):高效处理超越函数(如
sin, cos, exp, log)等复杂数学运算。
指挥与调度区 —— “车间管理层”
光有工人不够,需要高效的管理层来分发任务,确保每个工人都忙起来:
- Warp Scheduler(调度工头):核心能力是 延迟掩盖(Latency Hiding)。当一组线程在等待数据时,它能瞬间切换到另一组准备好的线程去执行,保证硬件不闲置。
- Dispatch Unit(指令分发员):负责将调度器的指令翻译成具体的控制信号,分发给对应的计算单元。
- L0/L1 Instruction Cache(指令缓存):存放最近要执行的任务清单(指令),让调度器能瞬间拿到命令,无需从慢速存储中读取。
存储与物流区 —— “仓库与物流”
负责数据的存放和搬运,确保生产线“粮草充足”:
- Register File(寄存器):离“工人”最近、速度最快的私有存储,每个线程都有自己的一份。
- LD/ST Units(装卸工):负责数据搬运的专用单元,执行加载(Load)和存储(Store)操作。
- L1 Data Cache / Shared Memory(共享内存):这是 SM 内部的“片上内存”,速度比外部显存快数十倍,是优化 CUDA 程序性能的关键所在,容量通常为 192KB。
SM 如何执行指令:从任务下发到结果产出
了解了硬件布局后,我们来看当一个计算任务下发时,这座“工厂”究竟是如何高效运转的。
1. 组队进场:Warp(线程束)的诞生
在CPU的世界里,线程往往独立执行。但在GPU的SM工厂里,为了追求极致吞吐量,采用“集体行动”模式。
- 打包分组:任务到达后,SM会将每 32个线程(Threads) 打包成一个基本执行单元,称为 Warp(线程束)。
- 同步执行:同一个Warp内的32个“工人”在同一时刻,必须执行同一条指令(例如都做加法)。区别在于,他们各自处理的数据不同。这种设计极大地简化了调度和控制逻辑。
2. 流水线分发
调度器选定一个准备就绪的Warp后,Dispatch Unit会根据指令类型,将任务分发给对应的“生产小组”:
- 普通算术题:发给 CUDA Cores。
- 矩阵大运算:发给 Tensor Cores。它能在一个周期内完成一个小型稠密矩阵块(如
4x4)的乘加运算,效率远超通用核心。
- 复杂函数计算:发给 SFU。
- 存取数据:发给 LD/ST单元。
3. 核心魔法:延迟掩盖(Latency Hiding)
这是SM能够实现超高吞吐量的秘密武器。计算中最耗时的往往是“等待”,例如从显存读取数据可能需要数百个时钟周期。
SM的Warp Scheduler是这样解决问题的:
- 遇阻即切:当Warp A因读取数据而开始等待时,调度器会瞬间(零成本切换) 将执行资源切换到已准备好的Warp B。
- 无缝衔接:Warp B立刻使用刚才空闲下来的计算单元继续工作。
- 循环往复:如果Warp B也进入等待状态,就再切换给Warp C……如此循环,直到Warp A的数据到达,再切回来继续计算。
只要SM内部驻留的Warp数量足够多,调度器就能保证计算单元几乎永远处于忙碌状态,从而“掩盖”了漫长的内存访问延迟。
4. 结果回写
计算完成后,结果并非直接写回遥远的全局显存,而是优先存放到Register File或L1 Cache/Shared Memory中。这就像工人将半成品放在手边的周转箱里,便于下一道工序直接取用,极大减少了数据搬运的开销。
通过以上层层剖析,我们可以看到,SM作为GPU的“心脏”,其高度并行、精细分工、智能调度的设计哲学,是支撑现代高性能计算与人工智能应用的基础。理解SM的工作原理,对于在云栈社区进行更深层次的性能优化和算法设计至关重要。
引用链接
[1] GA100 架构白皮书: https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf |  发表于 2026-3-3 08:00:10
|
查看: 611|
回复: 0
发表于 2026-3-3 08:00:10
|
查看: 611|
回复: 0
