在 AI Agent 开发中,如何让其动态获取新的能力,而无需修改核心代码,是一个普遍存在的架构挑战。本文将深入解析开源项目 Clawdbot(或称为OpenClaw)中的 Skill(技能)插件系统,探讨其如何通过 Markdown 文件这一简单形式,构建出强大且智能化的能力扩展机制。
什么是 Skill?
在 Clawdbot 中,Skill(技能) 是一种可插拔的能力扩展单元。其核心设计在于,每个 Skill 都是一个 Markdown 文件,它直接告诉 AI Agent:“你现在拥有了这项能力,具体操作方法是这样的。”

例如,一个 github 技能,其核心作用是让 AI 学会使用 gh 命令行工具与 GitHub 进行交互。其文件内容大致如下:
---
name: github
description: "使用 gh CLI 与 GitHub 交互..."
metadata: {"openclaw":{"requires":{"bins":["gh"]}}}
---
# GitHub Skill
使用 `gh` CLI 与 GitHub 交互。
## Pull Requests
检查 PR 的 CI 状态:
gh pr checks 55 --repo owner/repo
这种设计思路非常巧妙:通过让 AI 阅读 Markdown 文档来学习新技能,将能力定义与代码实现解耦,极大地降低了扩展门槛。
核心架构设计
Clawdbot 的 Skill 系统采用了一种经典而有效的 分层加载 与 条件过滤 相结合的架构。
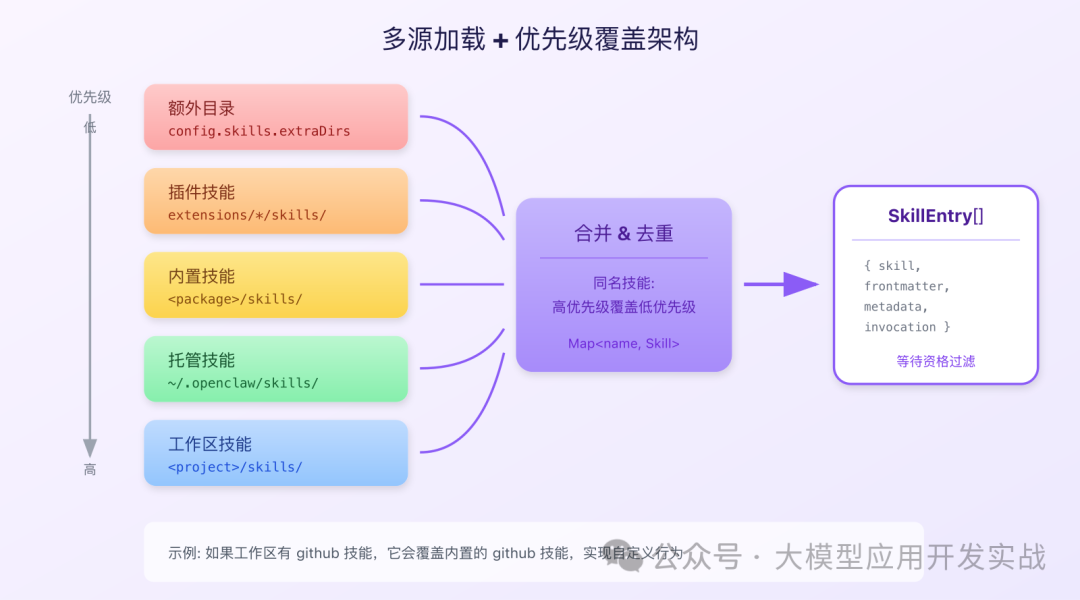
1. 多源加载与优先级覆盖
系统会从多达 5 个不同的目录加载技能文件,并且遵循严格的优先级规则:后加载的同名技能会覆盖先加载的。
| 优先级 |
来源 |
路径 |
| 最高 |
工作区技能 |
<project>/skills/ 目录 |
| ↓ |
托管技能 |
~/.openclaw/skills/ |
| ↓ |
内置技能 |
安装包内的 skills/ |
| ↓ |
插件技能 |
各插件的 skills/ 目录 |
| 最低 |
额外目录 |
配置中的 extraDirs |
这样的设计赋予了用户极大的灵活性:你可以在自己的工作区目录中创建同名技能文件,从而轻松覆盖任何内置或托管的默认技能,实现深度的个性化定制。
2. Frontmatter 元数据解析
每个 Skill 文件(SKILL.md)的头部都是一个 YAML 格式的 Frontmatter 区块,其中包含了驱动整个技能系统的关键元数据。
---
name: github
description: "与 GitHub 交互"
metadata: {
"openclaw": {
"emoji": "🐙",
"requires": {
"bins": ["gh"], # 需要的命令行工具
"env": ["GITHUB_TOKEN"] # 需要的环境变量
},
"install": [
{"kind": "brew", "formula": "gh"}
]
}
}
---
系统在加载时会精确解析这些元数据,为后续的“资格判定”提供依据。
3. 智能的资格判定系统
这是整个 Skill 系统中最精妙的设计之一——并非所有被扫描到的技能都会最终呈现给 AI。系统会进行一系列严格的资格检查,确保 AI 只“看到”它当前环境真正有能力使用的技能。
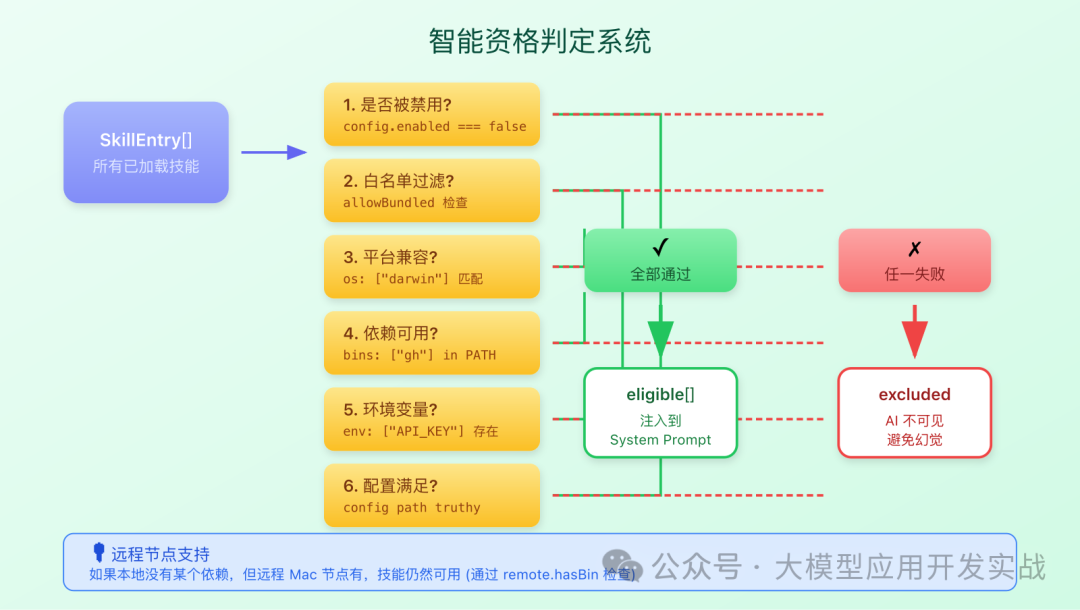
资格判定的维度包括:
- 依赖检查:如果技能声明需要
gh 命令,系统会扫描 PATH 环境变量来确认该命令是否已安装。若未安装,此技能将被过滤掉。
- 环境变量检查:例如,技能需要
OPENAI_API_KEY,若该变量未设置,则技能对 AI 不可见。
- 平台兼容性:技能声明仅支持 macOS(
os: [“darwin”])?那么在 Linux 系统上运行时,该技能会被自动过滤。
- 配置开关:用户可以通过配置手动禁用某些技能。
这种设计的哲学非常清晰:只向 AI 提供其上下文环境中切实可用的能力,从而从根本上避免 AI 因“知道”某个功能但无法调用而产生的“幻觉”或错误承诺。
一个简化的依赖检查函数示例如下:
function hasBinary(bin: string): boolean {
const pathEnv = process.env.PATH ?? "";
const parts = pathEnv.split(path.delimiter);
for (const part of parts) {
const candidate = path.join(part, bin);
if (fs.accessSync(candidate, fs.constants.X_OK)) {
return true;
}
}
return false;
}
4. 远程节点支持
更进一步,Clawdbot 的 Skill 系统还支持 远程技能代理。这意味着即使本地环境缺少某个必要的工具(如 gh),只要网络中的另一台被信任的节点(例如一台 Mac 电脑)上安装了该工具,系统就可以将技能的调用路由到远程节点去执行。
type SkillEligibilityContext = {
remote?: {
platforms: string[];
hasBin: (bin: string) => boolean;
note?: string;
};
};
这个特性打破了单机环境的限制,例如,可以让运行在 Linux 服务器上的 AI Agent,通过远程的 Mac 节点来使用那些依赖于 macOS 专属工具链的技能,极大地扩展了AI Agent的能力边界。
执行流程全景
当用户与 AI 开始一次会话时,Skill 系统在后台的完整工作流程可以概括为以下五个步骤:
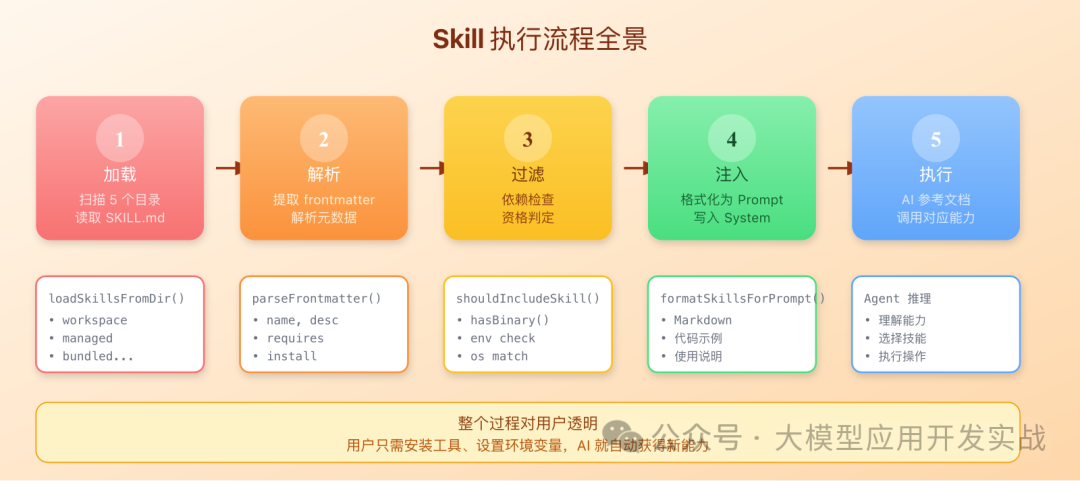
- 加载:系统从上述 5 个优先级目录中扫描并收集所有
SKILL.md 文件。
- 解析:提取每个文件的 Frontmatter 元数据,并解析其调用策略和文档内容。
- 过滤:依据依赖、环境变量、操作系统平台等条件,对所有加载的技能进行智能筛选。
- 注入:将通过过滤的“合格技能”格式化(通常转换为清晰的 Markdown 说明),并注入到 AI 的 System Prompt(系统提示词)中。
- 执行:AI 根据用户的请求,参考已被注入的技能文档,理解并选择调用对应的工具或操作来完成任务。
整个过程对终端用户是完全透明的。用户只需要按照指引安装好必要的命令行工具(如 gh),并设置好环境变量(如 GITHUB_TOKEN),AI 便会自动“获得”相应的新能力,无需任何额外的配置或代码修改。
用户调用机制
除了被 AI 自主调用外,Skill 也支持用户通过类似斜杠命令的方式直接触发:
/github 帮我看看 PR #123 的 CI 状态
系统内部会将技能名称(name)转换为合法的命令名(最长 32 字符,仅保留字母、数字和下划线),并妥善处理可能出现的命名冲突:
function sanitizeSkillCommandName(raw: string): string {
return raw
.toLowerCase()
.replace(/[^a-z0-9_]+/g, "_")
.replace(/_+/g, "_")
.slice(0, 32);
}
设计亮点总结
回顾 Clawdbot Skill 系统的整个架构,有几个关键的设计理念非常值得在构建类似的插件架构时借鉴:
- 声明式定义:使用 Markdown + YAML 这种对人类和机器都友好的格式来定义能力,极大降低了创建和共享新技能的门槛。
- 智能环境感知:通过运行时检查,只加载当前环境真正可用的技能,这是保证 AI Agent 可靠性和避免幻觉的关键。
- 灵活的分层覆盖:多级目录和优先级设计,让用户可以从全局到项目级进行不同粒度的自定义,覆盖默认行为。
- 渐进式依赖管理:技能可以声明其安装方式(如
brew install gh),引导用户或自动化脚本补齐运行时依赖。
- 网络化能力扩展:通过远程代理支持,实现了跨设备、跨平台的能力共享,突破了单机环境的束缚。
这套架构清晰地展示了一种优雅的 AI Agent 能力扩展模式:让 AI 通过阅读文档来学习技能,让系统通过感知环境来决定能力的边界。如果你正在设计或开发自己的 AI Agent 系统,希望这个来自真实开源项目的案例分析能为你带来切实的启发。
项目信息
(本文关于Clawdbot Skill架构的技术解析,旨在分享一种优秀的设计模式。更多深入的开发者讨论与实践交流,欢迎关注 云栈社区。)
 发表于 2026-2-2 06:03:26
|
查看: 273|
回复: 0
发表于 2026-2-2 06:03:26
|
查看: 273|
回复: 0