过去几年,向量检索技术早已不是搜索与推荐系统的专属后台组件,它正演变为支撑各类智能应用的通用数据基础设施。特别是在 RAG(Retrieval-Augmented Generation) 范式兴起之后,开发者的目标也不再局限于为搜推广场景构建向量系统,而是希望为任何知识问答、语义理解或智能助手轻松嵌入一套“语义记忆”模块。与此同时,向量检索的技术栈正从云端向终端设备(如PC、手机)下沉,这背后有几个关键驱动力:
- 开发者门槛降低:得益于 LangChain 这类框架的普及,向量检索的使用门槛被大大降低,向量能力正逐渐成为现代开发者的技术标配。
- 终端设备算力提升:在边缘AI的大趋势下,端侧设备的计算能力持续增强,已足以支持本地的向量计算与存储需求。
- 数据隐私与低延迟刚需:医疗、金融等行业对数据本地化处理有严格要求,而AR、自动驾驶等场景则对响应延迟有着近乎苛刻的需求。
以一个典型的终端应用场景——PC或手机端的本地RAG助手为例,我们可以更清晰地看到需求痛点。设想用户在没有网络的环境下,希望通过自然语言直接查询本地的代码库、技术文档或会议记录。这套系统需要同时存储向量和标量(如时间戳、文件类型、标签等)数据,并提供向量检索以及基于这些标量属性的混合过滤能力。随着本地文件的增删改,知识库需要动态更新,这就要求系统具备完整的 CRUD 能力。作为终端应用的一部分,其内存和后台资源占用必须有严格的限制,并且能在进程崩溃或强制退出后可靠地恢复数据。此外,启动与查询响应速度必须足够快,才能真正融入开发者的日常工作流。
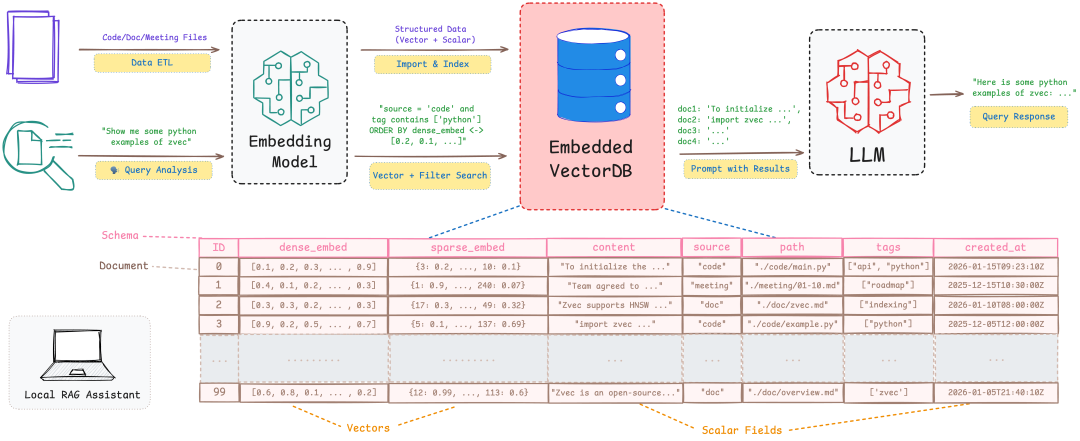
然而,当你尝试为上述场景寻找一个现成的技术方案时,会发现现有选项都存在不同程度的适配缺口:
- 纯索引库(如Faiss):这类库通常缺乏标量属性存储、混合查询、完整CRUD以及崩溃恢复等数据库级能力。若想将其用于生产,开发者需要围绕它进行大量外围工程开发,工程成本非常高。
- 嵌入式方案(如DuckDB-VSS):其向量功能往往受限,例如索引类型单一、不支持量化压缩,且在运行时对内存等资源的控制力较弱。在PC端应用中,这可能因内存或CPU占用过高而影响整个系统的性能。
- 服务化方案(如Milvus):这类方案依赖独立的进程和网络通信,架构复杂、资源开销大,难以直接嵌入到CLI工具、桌面应用或移动客户端中,其运维负担也与终端场景存在天然冲突。
什么是 Zvec?
为了填补上述技术方案的空白,我们开源了 Zvec。它是一个类 SQLite 的轻量级 嵌入式向量数据库,其核心理念是以嵌入式架构,提供极致性能、零依赖、生产可用的向量能力,目标是让向量检索变得和SQLite一样简单、可靠,并且能够轻松嵌入任何环境。
Zvec 的核心设计目标是 让高质量的向量能力触手可及,其设计宗旨主要体现在三个方面:
- 嵌入式:纯本地运行,无需网络或独立服务,真正做到零配置、快速启动。它在运行时对资源(如内存)有着可控的边界,接口设计简洁,易于集成和扩展,可以无缝嵌入终端应用、CLI工具、AI框架或其他数据库系统。
- 向量原生:全栈面向向量工作负载设计,提供丰富的高质量索引与量化能力,以适应不同资源约束下的需求,并深度适配各类硬件平台。它支持多样化的向量检索模式,全面覆盖 RAG、多模态搜索等应用场景。
- 生产就绪:以稳定性为核心,通过持久化存储、线程安全访问与崩溃自动恢复等机制,确保在手机、CLI、车载等无人运维的终端环境中也能长期可靠运行,避免因异常退出导致数据丢失或状态不一致。
为何选择 Zvec?
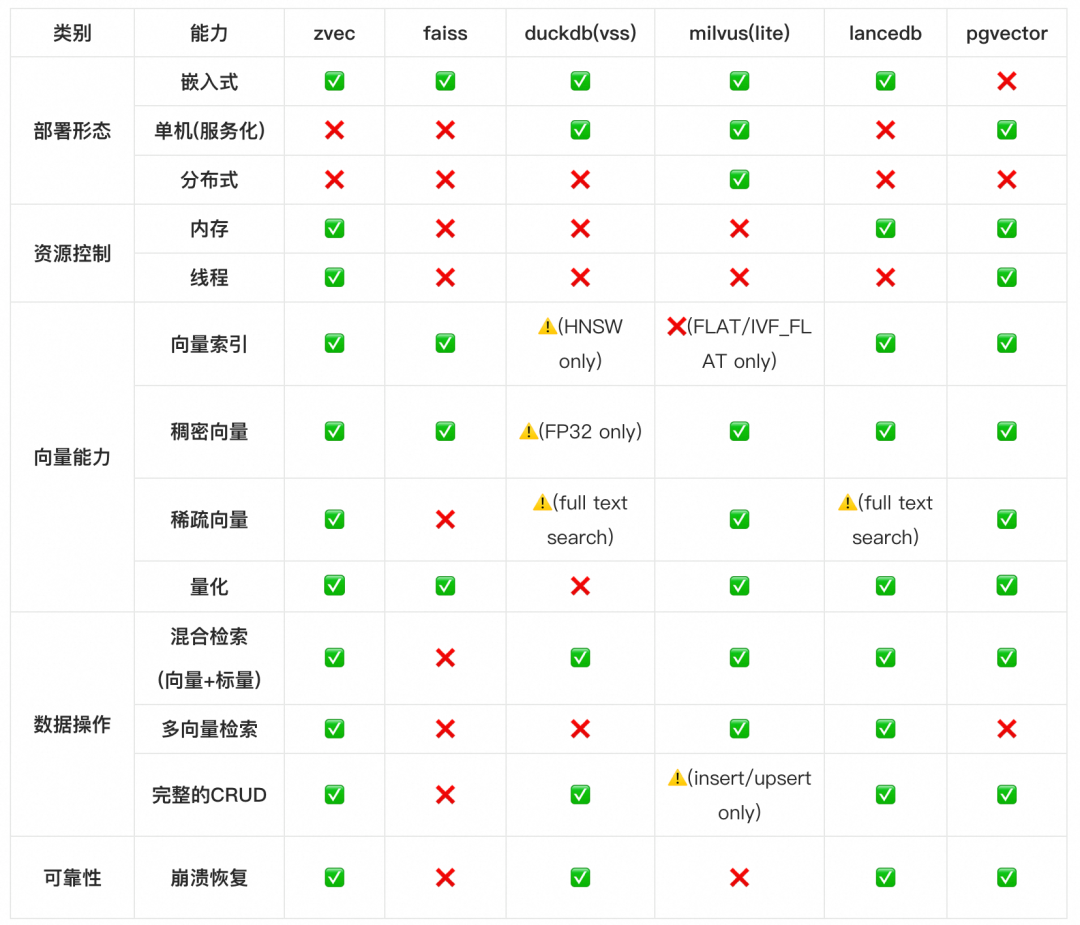
在确保极简易用性的同时,相比于其他面向端侧的向量数据库方案,Zvec 提供了更完整的检索功能、更强的资源管控能力以及更出色的检索性能。以下是与其他方案的简要对比:
3.1 开箱即用:一分钟搭建向量检索应用
凭借一键安装(无需部署服务,依赖极少)以及极简的API设计,Zvec 提供了 开箱即用 的极致体验。对于Python用户,只需一行命令 pip install zvec 即可将向量能力直接嵌入到你的应用中。通过创建集合(create_and_open)、插入文档(insert)、发起查询(query)这三个核心API,你就能快速构建一个本地语义搜索原型,整个过程从安装到运行通常不超过一分钟。
Zvec Python SDK(v0.1.0)现已发布,欢迎开发者即刻体验。
一键安装
pip install zvec
一分钟示例
import zvec
# 定义集合的Schema
schema = zvec.CollectionSchema(
name="example",
vectors=zvec.VectorSchema("embedding", zvec.DataType.VECTOR_FP32, 4),
)
# 创建并打开集合
collection = zvec.create_and_open(path="./zvec_example", schema=schema,)
# 插入文档
collection.insert([
zvec.Doc(id="doc_1", vectors={"embedding": [0.1, 0.2, 0.3, 0.4]}),
zvec.Doc(id="doc_2", vectors={"embedding": [0.2, 0.3, 0.4, 0.1]}),
])
# 基于向量相似度进行搜索
results = collection.query(
zvec.VectorQuery("embedding", vector=[0.4, 0.3, 0.3, 0.1]),
topk=10
)
# 结果:按相关性排序的列表,包含 'id', 'score' 等信息
print(results)
3.2 极致性能:满足端侧实时交互需求
Zvec 底层基于阿里巴巴通义实验室自研的高性能向量引擎 Proxima,通过 多线程并发、内存布局优化、SIMD 指令加速、CPU 预取 等一系列深度优化策略,显著提升了索引构建与查询流程的计算效率,实现了低延迟、高吞吐的向量检索能力,即使在端侧资源受限的场景下也能保证实时交互体验。
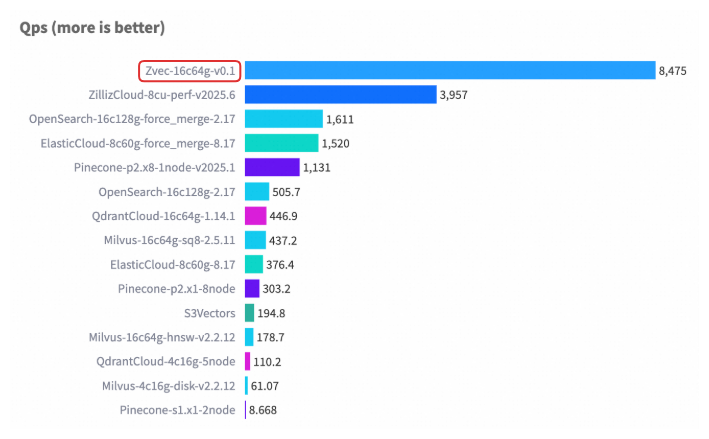
在权威向量数据库基准测试 VectorDBBench 的典型场景(Cohere 10M 数据集)中,Zvec 在相近硬件配置以及对齐召回率(Recall)水平的前提下,其检索吞吐(QPS)超过了 8000,是此前榜单首位(ZillizCloud)的 2 倍以上,同时数据加载(构建)延迟也大幅缩短,展现出全面领先的性能优势。
Cohere 10M 数据集性能案例
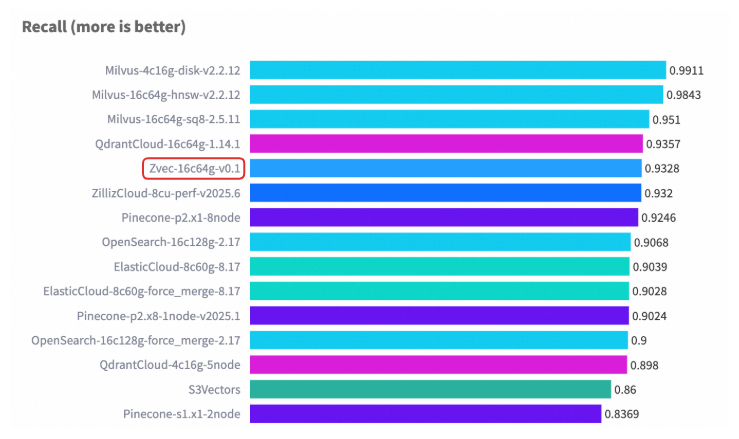
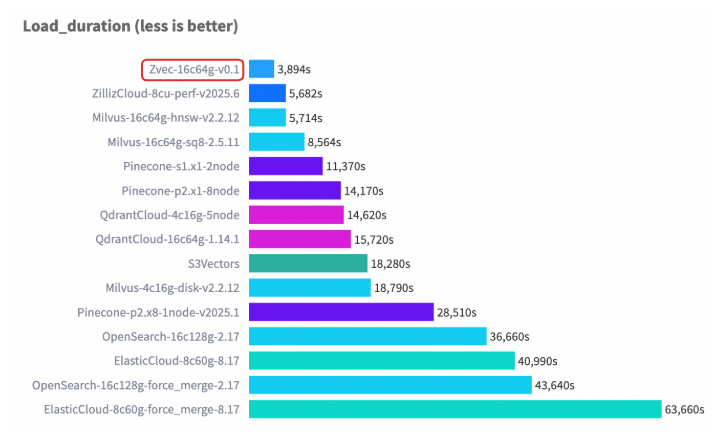
Cohere 1M 数据集性能案例
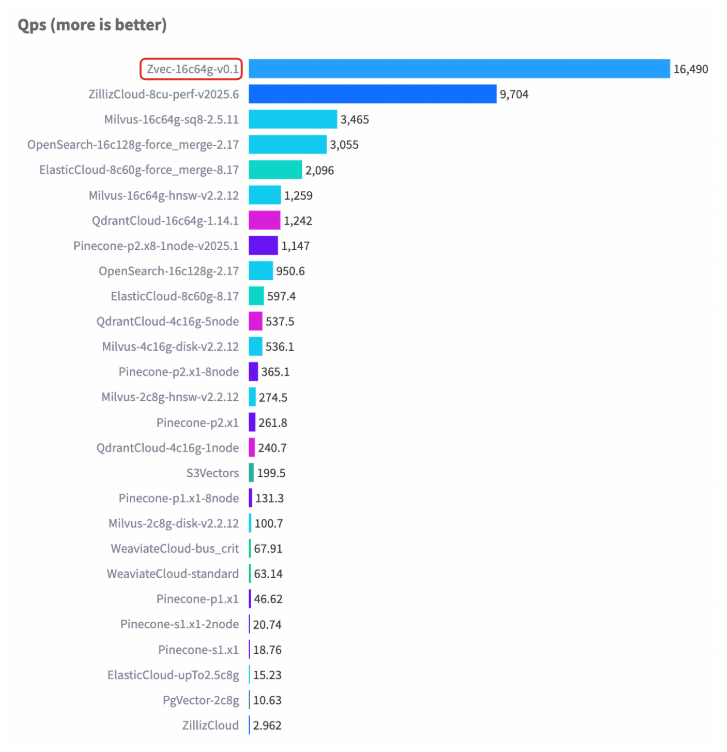
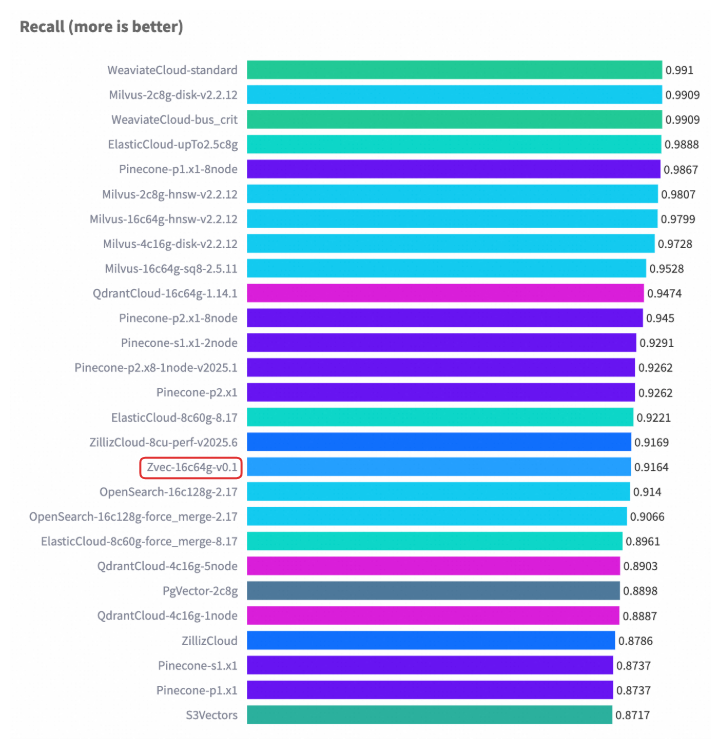
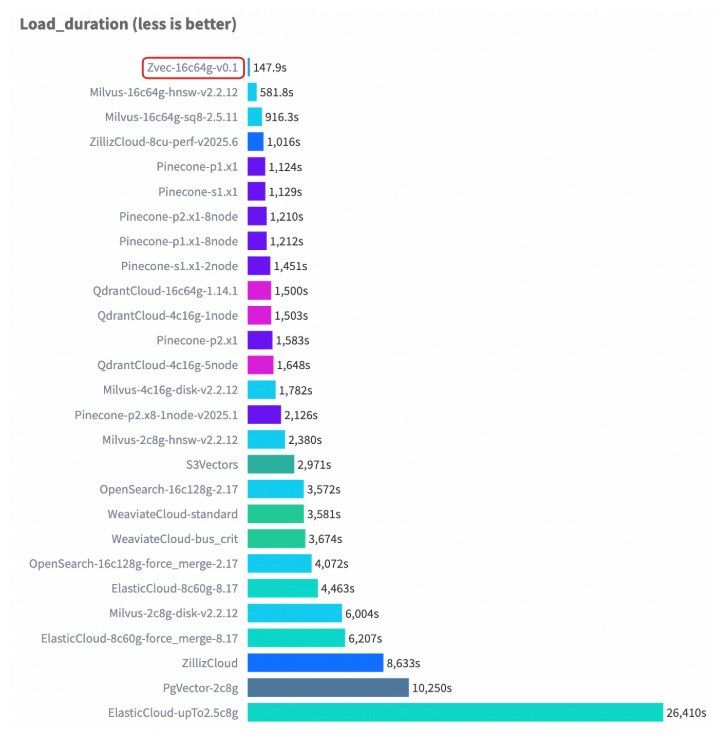
3.3 资源可控:适配 CLI、移动端等资源受限环境
在移动端、Serverless 函数或 CLI 工具等资源受限的环境中,向量系统必须对内存与 CPU 的使用设定明确边界。否则,极易因资源超限导致应用崩溃或触发系统干预(如 Linux 的 OOM Killer 或 Android 的 ANR)。Zvec 从架构层面内置了资源约束机制,确保在有限资源下也能稳定运行。
内存控制:向量索引适配有限内存,避免 OOM
HNSW 等图索引在构建或查询阶段,可能会瞬时占用数倍于原始数据的内存。为了避免这种不可控的内存消耗行为,Zvec 提供了三层内存管理机制:
- 流式分块写入:数据写入时默认采用 64MB 大小的分块进行流式处理,避免全量数据一次性驻留内存,在保证写入效率的同时严格控制内存占用。
- mmap按需加载:支持通过设置参数
enable_mmap=true 来启用内存映射模式。在此模式下,向量与索引数据由操作系统按需换入物理内存,即使总数据量超过了可用的物理 RAM,也能有效避免 OOM。
- 强内存管控 [实验性功能]:当未启用
mmap 时,Zvec 会进入强内存管控模式。它会维护一个隔离的、进程级的内存池,用户可以通过 memory_limit_mb 参数显式地设定该内存池的预算上限。
并发控制:避免线程资源侵占,保障主线程响应性
在 GUI 应用(如桌面工具、手机 App)中,无约束的向量计算可能会启动大量后台线程,耗尽 CPU 资源,导致 UI 卡顿或受到系统调度器的惩罚。Zvec 提供了细粒度的并发调控能力:
- 索引构建并发控制:所有索引创建接口都支持
concurrency 参数,用于指定构建阶段的并行线程数。同时,可以通过全局参数 optimize_threads 来限制进程内最大的索引构建并发度,防止后台任务过度抢占前台资源。
- 查询并发控制:通过
query_threads 全局参数,用户可以限定查询阶段所能使用的最大并发线程数。
3.4 应用就绪:RAG场景下向量能力全覆盖
Zvec 从设计之初就将 RAG 场景作为首要目标,其向量能力完整覆盖了 RAG 应用的全生命周期,具体体现在以下几个核心方面:
动态知识库管理
- 提供了完整的 CRUD 能力(增、删、改、查),允许用户实时更新私有知识库,满足知识动态演进的需求。
- 支持 Schema 变更(列的增删改、索引的创建与删除),便于根据元数据的演进或查询模式的变化,动态选择最优的索引策略。
多路召回与融合
- 原生支持多向量联合查询,可以轻松实现 RAG 中的多路语义召回,或“语义+关键词”混合召回。
- 内置了默认的重排序器(支持加权融合与 RRF 等策略),能够自动完成多路结果的融合与最终排序,无需应用层再进行复杂的手动合并逻辑。
标量-向量混合查询
- 支持将标量过滤条件(如“创建时间在最近一周”、“文件类型为PDF”)下推至向量索引的执行层,避免在高维向量空间进行全量扫描,从而显著提升混合查询的效率。
- 标量字段可以选择性地建立倒排索引,进一步加速等值匹配或范围过滤,优化混合检索的性能。
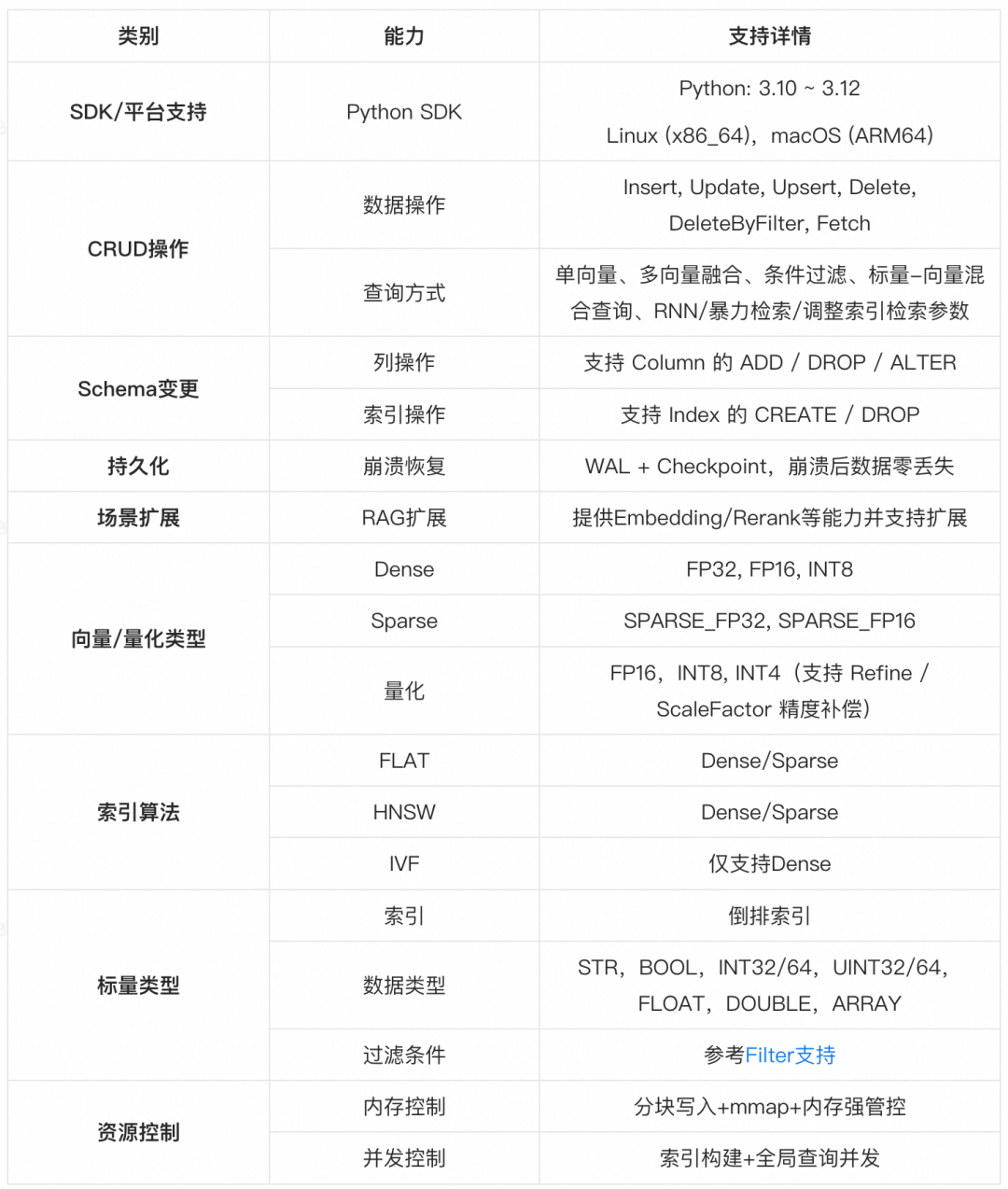
3.5 能力总览
后续规划
一个真正“随手可用”的向量数据库,离不开持续的迭代与打磨。接下来,Zvec 团队将聚焦于以下四个方向进行持续建设:
- 开发体验优化:完善 CLI 工具和多语言 SDK(如 Rust),深度集成 LangChain / LlamaIndex 等主流 AI 框架,并针对典型应用场景提供更完善的扩展支持。
- 能力纵向扩展:持续增强向量索引的核心能力,打造分组查询等向量特色功能,并持续在主流性能基准榜单(如 VectorDBBench)中保持竞争力。
- 生态协同共建:积极推进与 DuckDB、PostgreSQL 等流行数据系统的向量扩展集成,增加对外部数据格式(如 Parquet、CSV)的支持,积极参与开源数据生态的共建。
- 场景闭环验证:与 ISV(独立软件供应商)、硬件厂商展开合作,共同打磨在 iOS、Android、Nvidia Jetson 等端侧硬件上的真实交付案例,验证其稳定性和性能。
加入我们
Zvec 采用宽松的 Apache 2.0 协议开源,其目标就是让高质量的向量能力变得触手可及——轻量、可靠、无许可壁垒。
无论你是开发者、用户还是生态伙伴,我们都非常欢迎你的参与:
- 代码贡献:参与 C++ / Python / Rust 的核心开发、测试编写或性能优化工作。
- 文档完善:帮助编写教程、丰富示例,或完善 API 注释。
- 场景分享:分享你在 RAG、智能推荐、端侧AI应用等方面的实践经验。
- 生态建设:推动 Zvec 与 LangChain/LlamaIndex 的集成,或联动 DuckDB/PostgreSQL 等生态伙伴。
项目刚刚起步,我们期待与你一同打造真正好用、可靠的嵌入式向量数据基础设施。
如果你对 嵌入式架构、SQLite 的设计哲学,或如何为资源受限环境构建高性能数据系统感兴趣,欢迎在云栈社区的相关板块与我们交流探讨。
 发表于 2026-2-4 09:48:55
|
查看: 363|
回复: 0
发表于 2026-2-4 09:48:55
|
查看: 363|
回复: 0
