智谱AI近日正式发布了其轻量级多模态OCR模型 GLM-OCR,并宣布将其开源。该模型参数规模仅为0.9B,却在复杂的文档理解、公式识别和表格解析等多个关键任务上实现了显著的性能突破,为OCR技术的应用带来了新的可能性。
其核心亮点可以概括为以下几点:
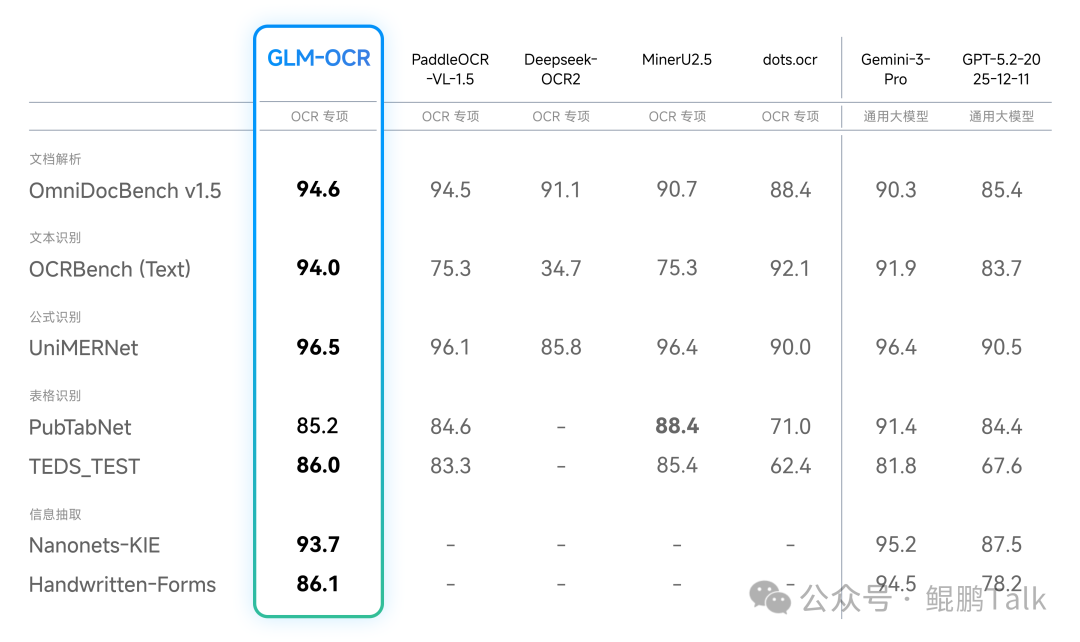
- 性能卓越:在权威文档解析基准OmniDocBench V1.5上综合得分达到94.62,位列榜首。
- 场景全面:专门针对手写体、印章、复杂表格、代码文档等传统OCR的痛点场景进行了优化。
- 性价比高:推理速度快,API调用成本约为传统方案的十分之一。
- 部署便捷:支持vLLM、Ollama等主流推理框架,可快速集成与调用。
性能表现:小模型展现大能力
得益于自研的 CogViT视觉编码器 与深度的场景优化策略,GLM-OCR在OmniDocBench V1.5榜单中以94.6分取得了SOTA性能。在文本识别、公式识别、表格识别及信息抽取四大细分领域,其表现均优于多款专项模型,综合性能直逼大参数量模型。
在实际处理效率与成本方面,该模型也表现突出:
- PDF处理吞吐量:1.86页/秒
- 图片处理速度:0.67张/秒
- API价格:0.2元/百万Tokens(约合1元钱可处理2000张A4扫描件)
实战场景解析:精准识别,不挑文档
GLM-OCR不仅在标准化测试中成绩优异,在面对真实多样的业务场景时同样表现出色。
通用文本与特殊内容识别
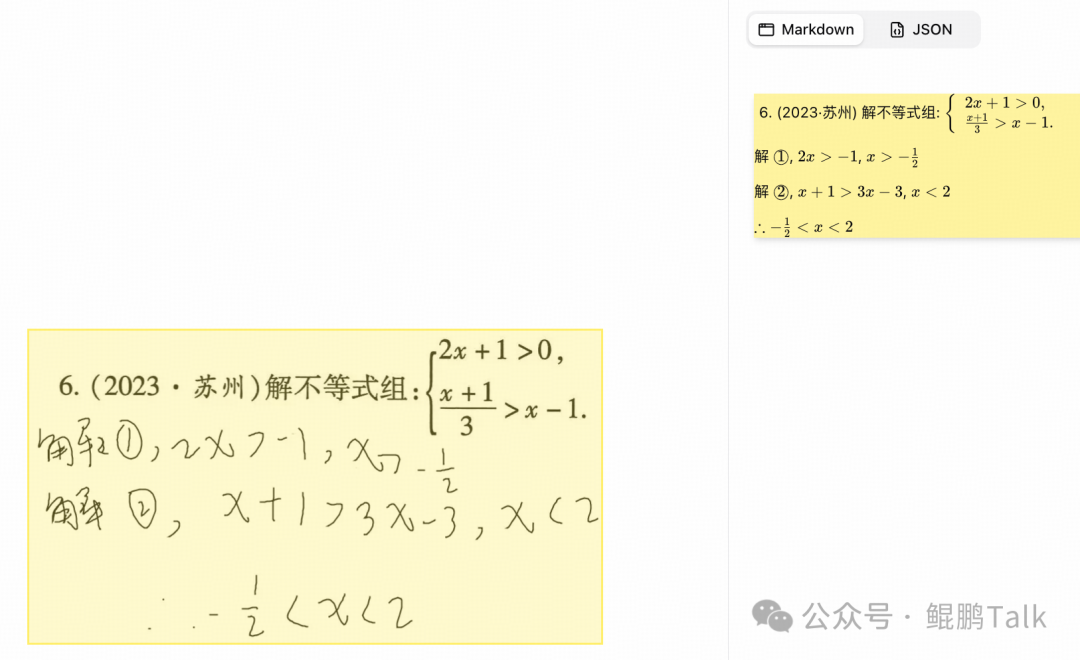
该模型能够处理照片、截图、扫描件等多种输入,并对手写体、印章、代码等特殊内容进行精准识别。
复杂表格解析
针对包含合并单元格、多层表头的复杂表格,GLM-OCR能够直接输出结构化的HTML代码。这意味着识别结果无需二次制表即可直接用于网页展示或数据导入,极大提升了流程效率。

信息结构化提取
模型能够从卡证、票据、报关单等文档中智能提取关键字段,并按预设的JSON格式输出,可无缝对接银行、保险、物流等业务系统。
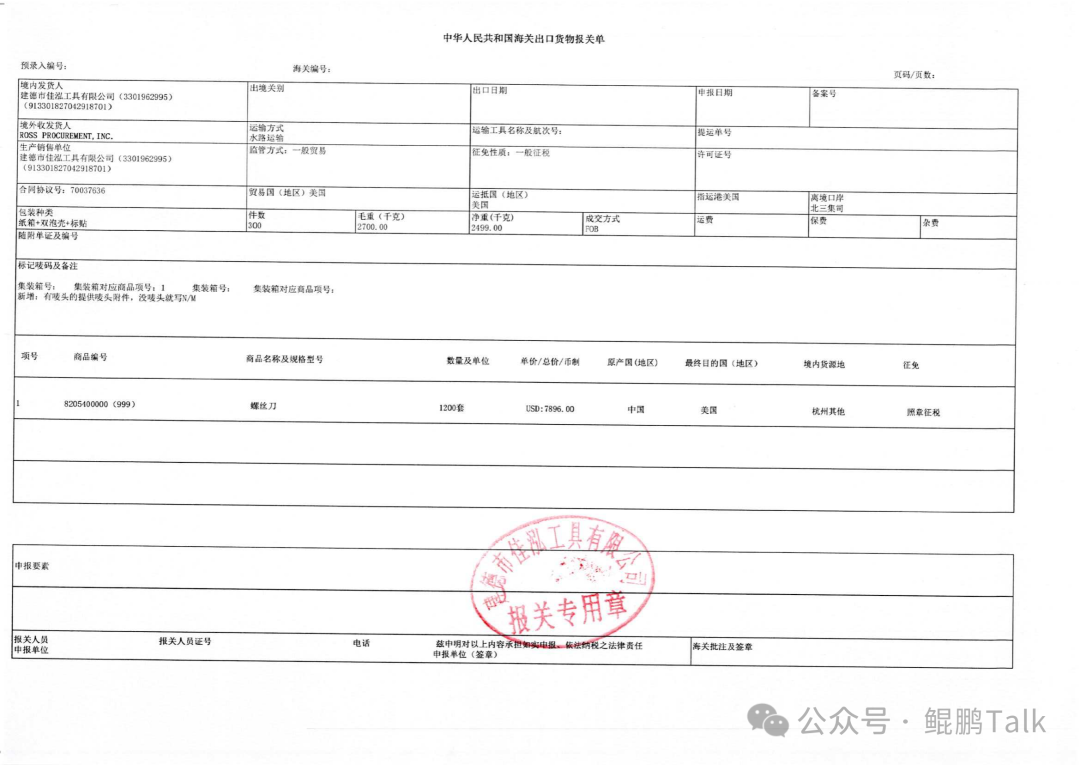
以下是一个从报关单中提取信息的完整示例:
输入图片:
用户Prompt(指令):
请按下列JSON格式输出图中信息:
```json
{
"标题": "中华人民共和国海关出口货物报关单",
"境内发货人": {
"名称":"",
"统一社会信用代码":"",
"10位海关代码":""
},
"出境关别": "",
"出口日期": "",
"申报日期": "",
"备案号": "",
"境外收货人": "",
"运输方式": "",
"运输工具名称及航次号": "",
"提运单号": "",
"生产销售单位": {
"名称":"",
"统一社会信用代码":"",
"10位海关代码":""
},
"监管方式": "",
"征免性质": "",
"许可证号": "",
"合同协议号": "",
"贸易国(地区)": "",
"运抵国(地区)": "",
"指运港": "",
"离境口岸": "",
"包装种类": "",
"件数": "",
"毛重(千克)": "",
"净重(千克)": "",
"成交方式": "",
"运费": "",
"保费": "",
"杂费": "",
"商品信息": [{
"项号": 1,
"商品编号": "",
"商品名称": "",
"数量": "",
"单价": "",
"总价": "",
"币制": "",
"原产国(地区)": "",
"最终目的国(地区)": "",
"境内货源地": "",
"征免": "",
"规格型号(申报要素)": ""
}, // 如果有多种商品,新建一个字典继续在列表中记录
]
}
模型输出结果:
```json
{
"标题": "中华人民共和国海关出口货物报关单",
"境内发货人": {
"名称": "建德市佳泓工具有限公司",
"统一社会信用代码": "913301827042918701",
"10位海关代码": ""
},
"出境关别": "",
"出口日期": "",
"申报日期": "",
"备案号": "",
"境外收货人": "ROSS PROCUREMENT, INC.",
"运输方式": "水路运输",
"运输工具名称及航次号": "",
"提运单号": "",
"生产销售单位": {
"名称": "建德市佳泓工具有限公司",
"统一社会信用代码": "913301827042918701",
"10位海关代码": ""
},
"监管方式": "一般贸易",
"征免性质": "一般征税",
"许可证号": "",
"合同协议号": "70037636",
"贸易国(地区)": "美国",
"运抵国(地区)": "美国",
"指运港": "美国",
"离境口岸": "北三集司",
"包装种类": "纸箱+双泡壳+标贴",
"件数": "300",
"毛重(千克)": "2700.00",
"净重(千克)": "2499.00",
"成交方式": "FOB",
"运费": "",
"保费": "",
"杂费": "",
"商品信息": [{
"项号": 1,
"商品编号": "8205400000(999)",
"商品名称": "螺丝刀",
"数量": "1200套",
"单价": "",
"总价": "7896.00",
"币制": "USD",
"原产国(地区)": "中国",
"最终目的国(地区)": "美国",
"境内货源地": "杭州其他",
"征免": "照章征税",
"规格型号(申报要素)": ""
}]
}
此外,GLM-OCR支持大批量文档的并行处理,其高精度的识别能力和规整的输出格式,为构建高质量的文档检索增强生成(RAG)系统提供了坚实的数据基础。关于更多人工智能领域的前沿应用,开发者社区常有深度讨论。
技术架构解析:性能背后的设计
GLM-OCR采用经典的“编码器-解码器”架构,其卓越性能源于以下几项关键的系统性设计:
- 多Token预测(MTP):率先将MTP损失函数引入OCR模型训练,增强了训练信号密度,有效提升了模型的学习效率。
- CogViT视觉编码器:一个拥有400M参数的强大视觉编码器,在数十亿规模的图文对上进行预训练,具备极强的版面布局与语义理解能力。
- 高效连接层:引入了4倍下采样策略,能够精准筛选关键视觉Token,显著减轻了解码器的计算负担。
- 两阶段处理范式:集成了PP-DocLayout-V3模型进行先行的版面分析,再配合并行识别,确保了在复杂版式文档下的高识别准确率。
快速上手:多种部署方式
GLM-OCR提供了完善的工具链,支持多种主流推理框架,方便开发者快速集成。
使用 Ollama 部署(最简便)
通过Ollama,可以像使用命令行工具一样快速调用模型。
ollama run glm-ocr
# 识别图片
ollama run glm-ocr "Text Recognition: ./image.png"
使用 vLLM / SGLang 部署(高性能)
适用于需要高并发、低延迟的生产环境。
vllm serve zai-org/GLM-OCR --port 8080
使用 Transformers 库(开发者友好)
适合在Python项目中灵活集成。
from transformers import AutoProcessor, AutoModelForImageTextToText
# 加载模型后,使用 apply_chat_template 即可快速调用
开源与获取方式
GLM-OCR已全面开源,社区开发者可以自由获取、使用与研究。
许可协议:模型权重基于MIT协议开源,版面分析模块遵循Apache 2.0协议。对于希望深入研究和复现的开发者,可以参考相关的技术文档与开源实战经验。欢迎在云栈社区分享你的使用心得或部署经验。
 发表于 2026-2-4 09:51:53
|
查看: 343|
回复: 0
发表于 2026-2-4 09:51:53
|
查看: 343|
回复: 0
