机器人在厨房里倒茶,手已经伸到杯口边上;另一边,湿实验室的机械臂正准备把试管放回架子。这个时候,模型如果还在慢慢生成一大串 reasoning,再等控制头吐出动作,现场就会很尴尬。茶会洒,试管会歪,机械臂还可能在半空中抖一下。
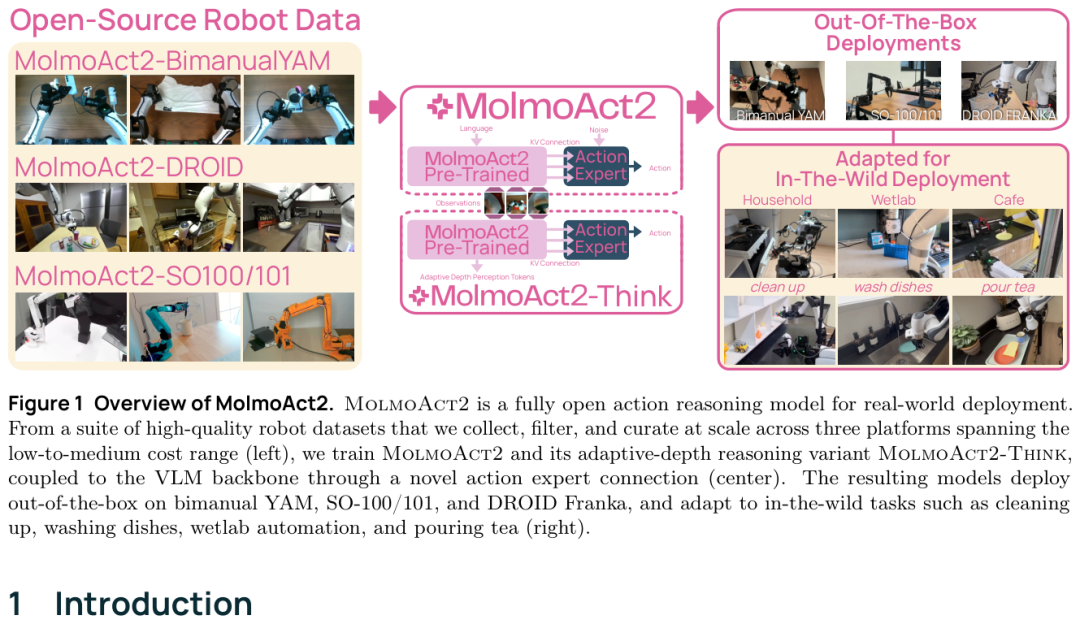
这也是我读 MolmoAct2 时最在意的点。它讨论的不是一个更会聊天的 VLM,而是一个必须把语言、视觉、空间判断和连续动作塞进同一条实时链路里的机器人系统。AI2 这次把 MolmoAct2 做成 fully open:weights、data、code 都开放。我的判断是,它最有价值的地方不是某个榜单第一,而是把机器人 VLA 从“可下载模型”往“可复现、可改造、可部署”推了一步。
物理世界对模型很不客气。屏幕上的 agent 调错工具,还能撤回重跑;机械臂把杯子碰倒,地上就真有水。语言模型慢半秒,用户顶多觉得卡;机器人慢半秒,控制策略可能已经错过抓取时机。MolmoAct2 抓住的就是这道缝:VLA 不能只会理解任务,还要在限定延迟内把理解变成动作。
开源权重救不了厨房里的机器人
机器人 VLA 这条路,过去最容易让人误判的地方,是把 open weights 当成 open system。权重能下载,当然比完全封闭好。但真要接到一台 Franka、一套 SO-100/101,或者一台双臂 YAM 上,马上会碰到更琐碎也更致命的问题:训练数据从哪来,动作怎么表示,tokenizer 能不能复现,相机角度变了怎么办,模型想得太慢会不会把控制频率拖死。
MolmoAct2 的动作比较重。它不只给一个模型文件,还放出三套机器人数据。BimanualYAM 有 34.5k demonstrations、超过 720 小时双臂遥操作轨迹;DROID 和 SO-100/101 也各自做了质量过滤。这里我觉得 720 小时这个数字很关键,因为双臂任务的难点不只是夹取,还包括两只手协作、物体遮挡、桌面布局变化。没有这种数据,开源实战中常见的 VLA 很容易停在别人看得到、自己跑不动的状态。
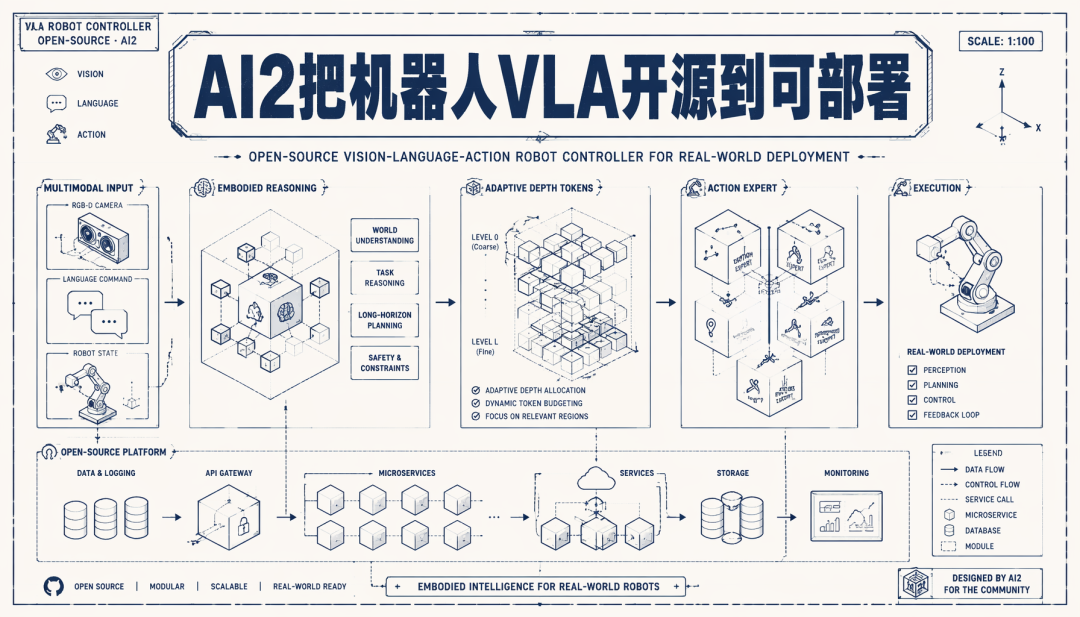
图里左边是数据,右边是 household、wetlab、cafe 这类部署场景。重点不是图画得多热闹,而是它把“开放”落在了机器人系统真正缺的几块拼图上:数据、action 表示、模型连接、推理优化。这些拼图少一块,别人都很难复现到自己的机器上。
OpenFAST Tokenizer 也在这条线上。它负责把连续动作压成 VLM 能学习的 action tokens,而且同样 open-weight、open-data。这个部件很容易被普通读者忽略,但我反而觉得它很重要。机器人动作不是一句话,不能只靠语言 token 硬凑。action tokenizer 如果是黑盒,后面所有复现都会卡在门口。
还有一点值得单独拎出来:数据过滤。DROID 和 SO-100/101 本来就不是没有数据,难的是数据质量参差不齐。机器人轨迹里有停顿、失败、空动作、相机遮挡,这些噪声会直接教坏 policy。MolmoAct2 把数据清洗写进系统方案里,我觉得这比单纯喊“更多数据”更接近真实训练。机器人数据不是网页文本,坏样本会变成坏动作。
让模型会动,关键是别让它重新猜上下文
VLM 看懂“把糖果分到正确盒子里”,和机械臂真的把糖果放进去,中间隔着一条很长的沟。看懂指令只是开始,机器人还要把画面、语言、当前关节状态,变成一串平滑的连续动作。MolmoAct2 在人工智能领域的核心设计,是把一个 continuous action expert 接到离散 token VLM 后面,让它专门负责生成可执行轨迹。
我第一眼看架构时,最值得停下来的不是 flow matching 这个词,而是 per-layer KV connection。简单说,VLM 每一层 attention 已经在组织“该看哪里、哪个物体和指令相关、当前上下文怎么对齐”。MolmoAct2 没有只拿最后一层结果糊给动作头,而是把每层 KV cache 经过投影,送到 action expert 的对应层里。这样 action expert 生成动作时,不必重新猜 VLM 到底看懂了什么。
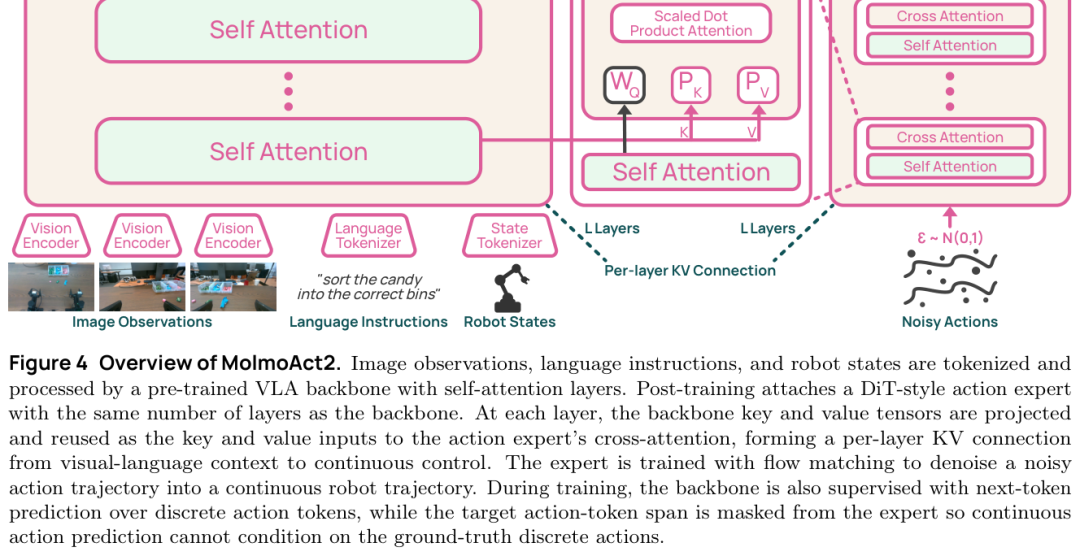
这张图里最该看中间那条 KV connection。它像一条信息捷径,把视觉语言模型内部的注意力状态直接接到连续控制模块。我的反应是:这个设计不花哨,但很像工程里会真正起作用的改法。少绕一层弯,机器人就少一次把“理解”翻译成“动作”时出错的机会。
这类连接还有一个隐含好处:它没有强迫 VLM 自己直接输出高精度连续控制。VLM 擅长把图像、语言和上下文组织起来,action expert 擅长把这些上下文变成轨迹。两个模块分工清楚,比让一个自回归模型从头到尾包办动作更稳。我读到这里才反应过来,MolmoAct2 的设计并不是追求一个万能头,而是在承认机器人控制很专门之后,把专门模块接到 VLM 最有信息量的位置。
MolmoAct2-Think 解决的是另一处麻烦:机器人需要空间推理,但不能为了推理变慢。它会预测 depth tokens,让模型在行动前显式知道距离、遮挡、桌面结构。更巧的是 adaptive depth:相邻控制步里,很多区域其实没变,所以它只重算变化区域,把静态区域缓存下来。这个思路我很喜欢,因为它没有假装 reasoning 免费,而是在承认延迟很贵之后,去抠那些可以不算的部分。
最有说服力的是它跑了很多真实卷子
MolmoAct2 的实验很多,我不想把表格逐项翻译。真正有说服力的是它没有只挑一个好看的 benchmark。它先验证 Molmo2-ER 这个 embodied reasoning backbone:13 个 embodied reasoning benchmark overall average 63.8%,超过 GPT-5 的 57.9,也超过 Gemini ER 1.5 Thinking 的 61.3。这个数字挺反直觉,一个开放体系里的 backbone,在这组空间和具身推理题上压过了更大的闭源模型。
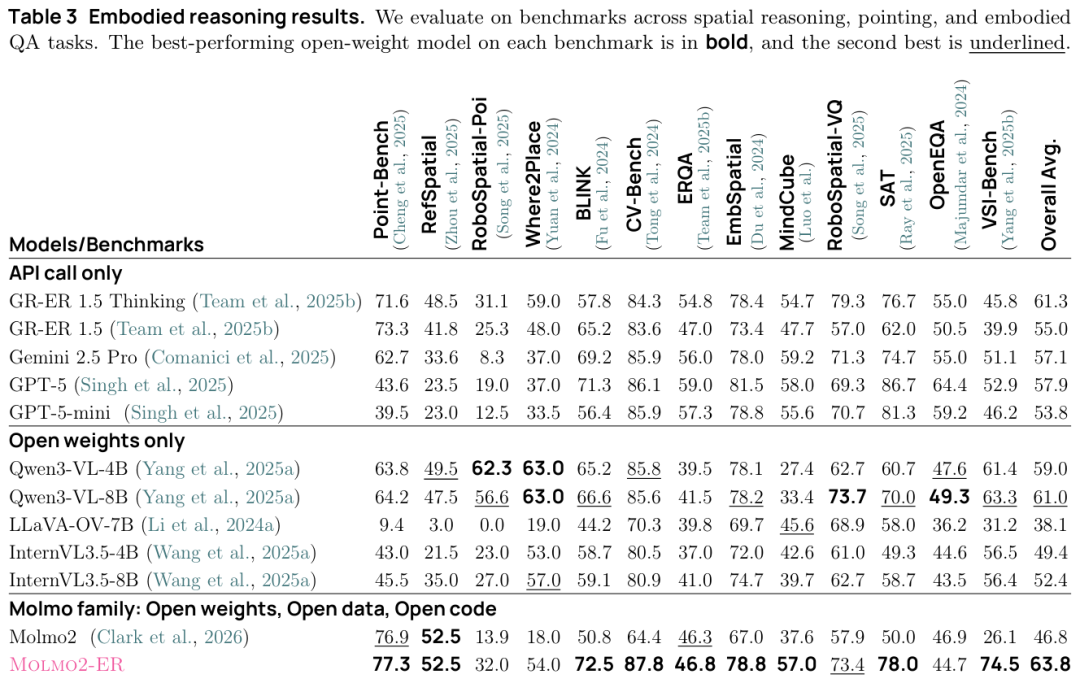
这张表说明一件事:机器人 VLA 里的 VLM backbone 不是装饰。它对空间、指向、视角、视频变化的理解,最后会传到动作学习里。Molmo2-ER 比 Molmo2 提升 17 个点,也让后面的 action model 有了更好的起点。
接着看 out-of-the-box。MolmoSpaces 上,MolmoAct2-DROID average 37.7,pi0.5-DROID 是 34.5;simulation held-out average 20.6,对比 pi0.5-DROID 的 10.0。这个差距我看得比单个最高分更重,因为 held-out 环境更接近“没专门给你调过”的情况。机器人如果只能在熟悉桌面上稳定,离部署还差一大截。

真实机器人数字更硬。DROID real tasks 里,MolmoAct2-DROID average 87.1,对比 MolmoBot 的 48.4 和 pi0.5-DROID 的 45.2;SO-100 平台 average 56.7,对比 pi0-SO100/101 的 45.3。fine-tuning 后,LIBERO 是 97.2%,RoboEval 是 44.3%,现实 8 个 YAM 任务平均 50.1%,比 runner-up 高 15 个百分点。
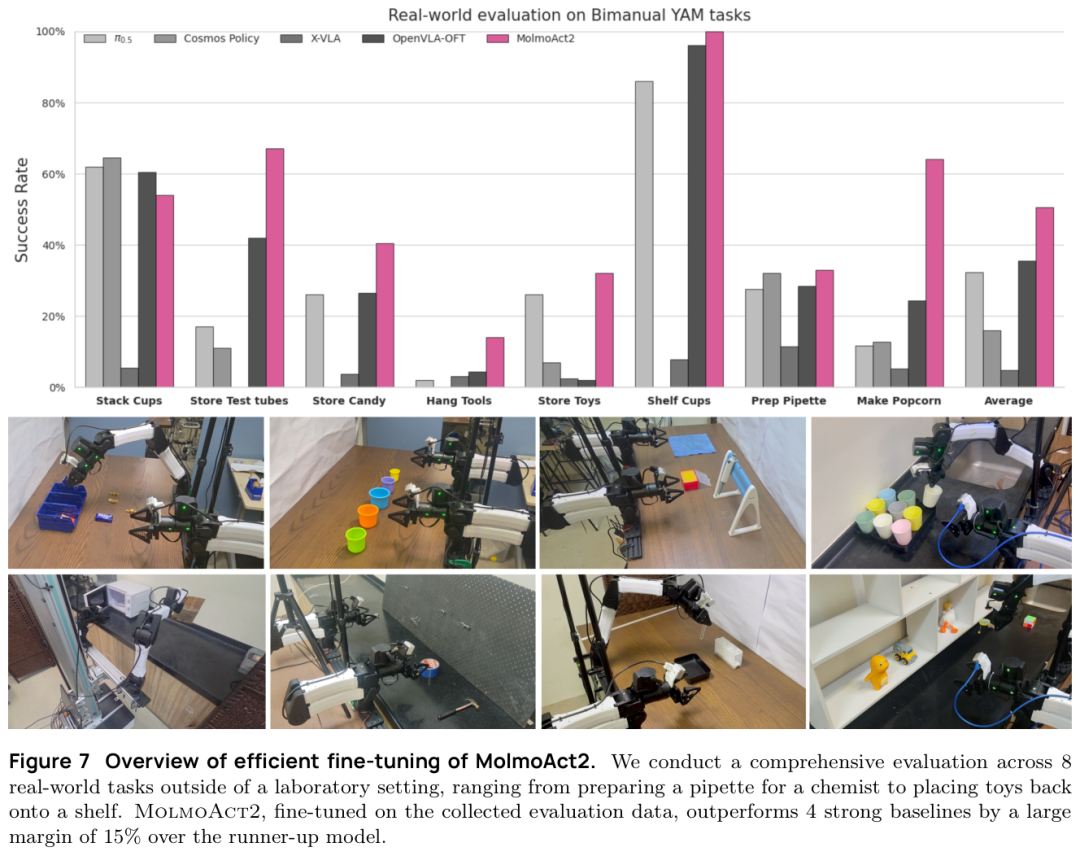
这里有个细节很现实:那 8 个任务不是抽象名字,而是 stack cups、store test tubes、prepare pipette、store toys、make popcorn 这类动作。把试管收回架子和把玩具放回架子,看起来都是收纳,真实难点却不同。一个要避开细长容器,一个要处理杂乱物体。我更愿意相信这种任务集,比只看单一仿真榜单更接近工程现场。
我还注意到 RoboEval 的位置。它看任务成功,也看轨迹质量。机器人把东西放到了目标位置,但中间绕了很远、抖了很多、碰了旁边物体,在真实部署里依然不好用。MolmoAct2 在 RoboEval 上 44.3%,不是一个漂亮到让人放心的数字,却提醒我们评测正在从“有没有完成”走向“怎么完成”。这对机器人很要命,因为人类会本能地躲开一个动作粗糙的机械臂。换到咖啡店场景,杯子最后到没到托盘只是一半问题,路径是否稳定、有没有擦到旁边的热水壶、动作能不能被店员预判,都会影响它能不能真的上岗。
速度也不能跳过。MolmoAct2 原始路径是 23.02Hz,做 caching 后到 27.39Hz,加 CUDA Graph 后到 55.79Hz。机器人控制频率不是锦上添花,它决定模型能不能跟得上机械臂和环境变化。Think 版本速度提升没这么夸张,也说明 autoregressive depth 仍然是成本点,这里我有一点存疑:adaptive depth 在更动态的真实场景里,到底能不能一直稳定省延迟,还需要更多长时序测试。
我愿意看好它,但还不会把试管交给它
MolmoAct2 很值得看,但我不会把它解读成机器人马上能进家门。现实 8 任务平均 50.1% 已经明显领先,可如果把场景换成实验室自动化,这个失败率仍然太高。试管放错、移液枪没准备好、爆米花包装抓歪,在论文里是一次 trial failed,在真实流程里就是要人重新介入。
我还担心迁移细节。AI2 开放了数据和代码,已经比只给权重好很多,但每个实验室的相机位置、夹爪磨损、桌面高度、动作空间都会不一样。MolmoAct2-Think 在 LIBERO 上从 97.2 到 98.1,方向是对的,可这个 0.9 个点在真实低延迟控制里会放大还是被噪声淹掉,我还没完全想明白。
更难的部分是失败后恢复。很多机器人评测默认一次尝试走完任务,可家庭和实验室里经常不是这样:杯子被碰偏了,试管半插进架子,玩具卡在隔板边缘,机械臂需要意识到自己已经失败,然后改动作。MolmoAct2 把开源部署链路铺出来了,但这种在线纠错和安全策略,还没有被同等程度地解决。这里我会保留一点谨慎。真实部署还会遇到人突然伸手、桌面被临时挪动、物体反光这种麻烦,单靠离线 demonstrations 很难覆盖干净。
所以这篇论文对我的价值,不是让我相信“机器人问题解决了”。它更像一个分界点:开源机器人 VLA 不能再只交一个模型文件,然后让别人自己猜数据、tokenizer 和部署 recipe。MolmoAct2 把门打开得更大了。厨房里的茶、实验室里的试管,离完全放心还远,但至少这次,更多人终于能拿着同一套零件进场试了。对一个还在快速试错的方向来说,这种可拆开的系统,比一个看不见训练过程的高分模型更有用,也更容易让后来者发现问题出在数据、连接方式,还是部署细节。在云栈社区,我们始终关注这类把前沿技术工程化、可复现化的硬核实践,因为它真正降低了整个领域协作与验证的门槛。
 发表于 2026-5-7 20:07:59
|
查看: 129|
回复: 0
发表于 2026-5-7 20:07:59
|
查看: 129|
回复: 0
