前两天在技术群里看到一个问题,讨论得很热烈:大模型推理到底卡在哪里?
问题描述非常具体——推理阶段,尤其是 token by token 生成的时候,延迟高得离谱。
评论区分裂成好几个流派。有人说“上更大内存”,有人说“换更硬的芯片”,还有人说“优化算法”。吵了半天,没一个说到根上。
后来我花了一周时间,把一篇 60 页的综述论文啃了一遍。论文标题是《Hardware Acceleration for Neural Networks: A Comprehensive Survey》,作者是一群搞硬件加速的研究人员,内容覆盖了 ANN、CNN、RNN 到 Transformer 的完整硬件加速方案。
看完之后,我发现争议的根源在于:大家根本没搞清楚一个最基本的东西。
大模型推理慢,不是缺算力。是内存带宽不够,是数据搬运太慢,是架构设计没跟上算法的演进。
这篇文章,我想把这个综述的核心内容,用人话讲清楚。
一、为什么需要专用加速器
先从一个直白的问题开始:如果 CPU 能跑深度学习,为什么还需要 GPU、TPU、NPU 这些专用芯片?
答案很简单:因为矩阵运算的本质,是高度并行的。
一个典型的深度学习模型,每次前向传播都要做大量矩阵乘法。一个 7B 参数的模型,每次推理涉及至少几十次矩阵乘法。单次矩阵乘法的维度可能是 4096×4096,甚至更大。
如果这些操作串行执行,算一次可能需要几分钟。但如果用专门设计的硬件并行执行,计算密度和吞吐量能提升几十倍甚至几百倍。这就是专用加速器的核心价值。
但问题来了:不同的神经网络架构,计算模式完全不同。
全连接层的矩阵乘法,是稠密的、规则的计算,适合通用矩阵乘法引擎。卷积层有空间局部性,同一个卷积核要滑动应用到输入特征的多个位置,适合流水线和空间并行。
循环神经网络有严格的时序依赖,每一步的计算结果会影响下一步,难以并行。Transformer 的注意力机制复杂度是二次方的,自回归生成的延迟又受限于 KV cache 的读写带宽。
所以一个残酷的事实是:没有一种加速器能通吃所有模型。 每种架构,都有最适合的硬件设计。下面我逐个讲。
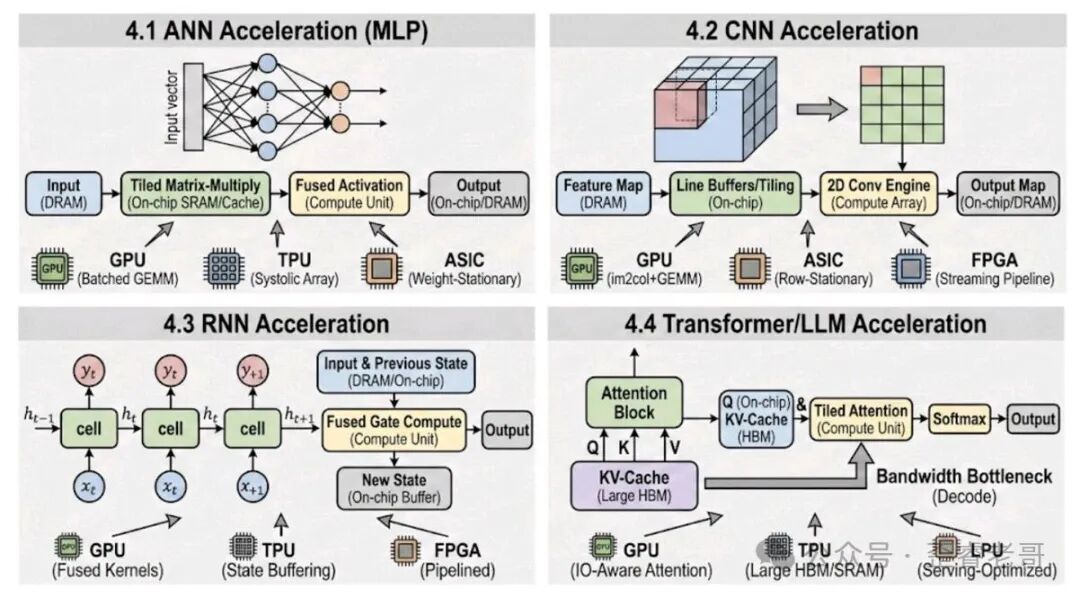
二、ANN 加速器:全连接层的基石
计算模式
ANN 的核心操作是矩阵乘法(GEMM),即 General Matrix-Matrix Multiplication。一个全连接层的计算可以表示为:
output = W @ input + bias
其中 W 是权重矩阵,input 是输入向量,bias 是偏置。
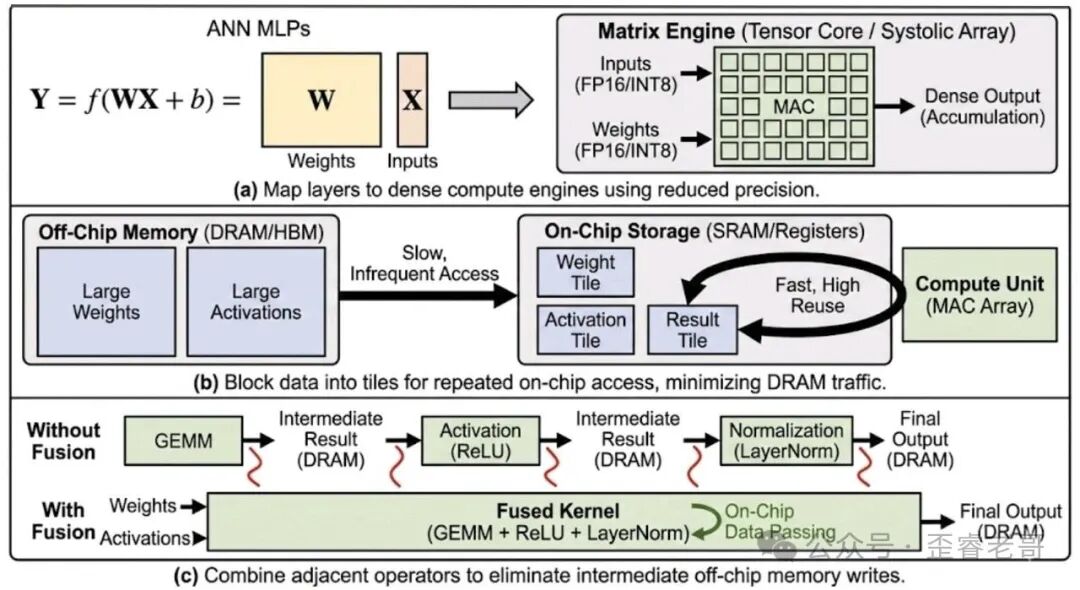
这个计算的特点是高度规则、计算密集。每个输入神经元都要和权重矩阵的每一行做点积,每个点积都是一系列乘加操作的累加。因此,ANN 加速器的核心设计目标非常明确:最大化矩阵乘法的吞吐量,同时最小化内存访问。
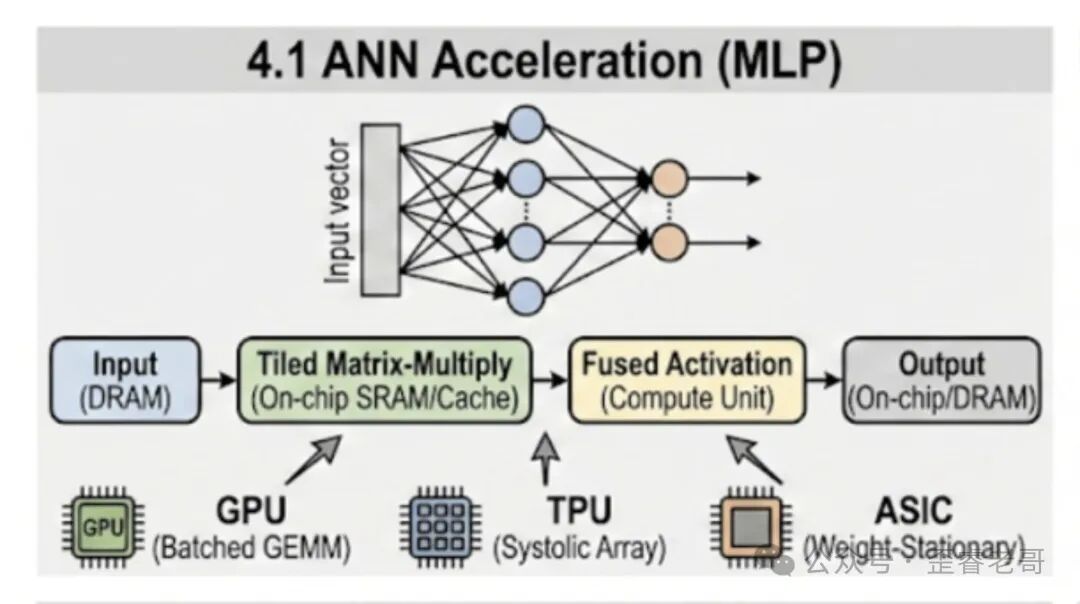
GPU 上的 ANN 加速
GPU 加速 ANN 的核心思路是让数据复用最大化。具体有几个关键技术:
Tiling(分块)
权重矩阵和激活值太大了,一次性加载到显存再算,带宽根本吃不消。所以要把数据分成小块(tiles),每次只加载需要的数据到寄存器或 shared memory,反复利用。
比如一个 4096×4096 的矩阵乘法,如果分块成 64×64 的 tiles,每次只加载 64×64 的权重和 64×64 的激活值,就能在芯片内反复利用这些数据,大幅减少 DRAM 访问。
Fusion(算子融合)
传统做法是矩阵乘法算完,结果写到全局显存,然后下一个激活函数再从全局显存读出来算。这样每个中间结果都要经过一次显存读写。融合的做法是把激活函数、归一化等操作直接嵌入到矩阵乘法的 epilogue 里,结果存在寄存器里,根本不写入显存。这一刀切下去,显存带宽压力直接减半。
混合精度
训练阶段用 FP16 或 BF16 做计算,累加用更高精度(FP32),这样吞吐量翻倍的同时,数值稳定性也不会崩。推理阶段更猛,INT8 量化能把权重和激活值压缩到原来的 1/4,吞吐量直接提升 4 倍——前提是精度损失在可接受范围内。
TPU/NPU 上的 ANN 加速
TPU 和 NPU 的设计理念和 GPU 不太一样。GPU 的核心是灵活——它有 CUDA 核心、tensor core、各种内存层级,能跑各种模型,什么都能算。NPU 的核心是效率——它的硬件是为特定计算模式量身定制的,比如脉动阵列(Systolic Array),专门为矩阵乘法设计。
脉动阵列的工作原理说起来有点绕,简单讲就是数据像流水线一样在阵列中流动,每个处理单元同时接收输入数据,执行乘加操作,然后把部分结果传递给下一个单元。这种设计能实现计算和数据流的完美匹配,几乎没有多余的内存访问。
NPU 的关键挑战在于编译器和调度。因为硬件是固定的,必须在编译期就把计算图切分成适合硬件执行的 tile,安排好数据在 SRAM 中的复用,才能让阵列保持 100% 忙碌。
ASIC 上的 ANN 加速
ASIC 是专用集成电路,硬件完全定制。对 ANN 来说,ASIC 的设计思路是去掉所有不必要的灵活性。
GPU 有指令集、有调度器、有复杂的控制逻辑,这些都是为灵活性服务的。但 ANN 的计算模式太固定了,绝大部分时间都在跑矩阵乘法,其他操作占比很小。所以 ASIC 可以硬连线一些固定的矩阵引擎,去掉调度开销,去掉指令 fetch,甚至去掉浮点单元,直接用定点数做计算。这种设计能实现比 GPU 高几十倍的能效比,但灵活性几乎为零。
FPGA 上的 ANN 加速
FPGA 的优势在于可重构。对 ANN 来说,FPGA 的设计思路是空间流水线。把矩阵乘法映射到硬件上,设计一个固定数据流,每个周期推进部分和的计算,避免中间结果写入 DRAM。
值得注意的是确定性延迟。只要输入维度固定,FPGA 的延迟就是固定的,这对实时推理场景很重要。
三、CNN 加速器:利用空间局部性
计算模式
CNN 的核心操作是卷积,和矩阵乘法的不同在于空间局部性。同一个卷积核要滑动应用到输入特征的多个位置,相邻输出的输入窗口有大量重叠。这意味着权重可以被反复利用,而且输入数据也有很好的空间局部性。硬件加速器的设计目标就是把这种局部性挖掘到极致。
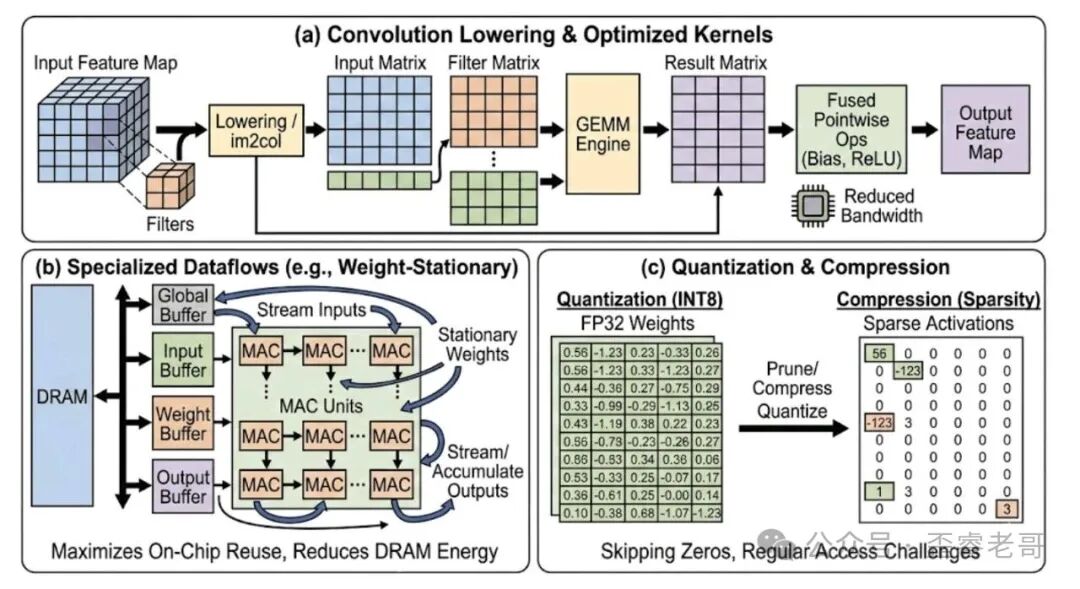
GPU 上的 CNN 加速
GPU 加速 CNN 的核心技术是 Winograd 变换和 Im2Col 优化。Im2Col 是把输入特征图展开成矩阵,把卷积操作转化为矩阵乘法,然后 GPU 可以用高度优化的 GEMM 内核来执行。
Winograd 变换是另一种思路,通过数学变换减少乘法操作的次数。一个 3×3 的卷积,传统做法需要 9 次乘法和 8 次加法,Winograd 只需要 4 次乘法。代价是增加了加法运算和数据转换的开销,实际效果要看数据量和硬件架构。
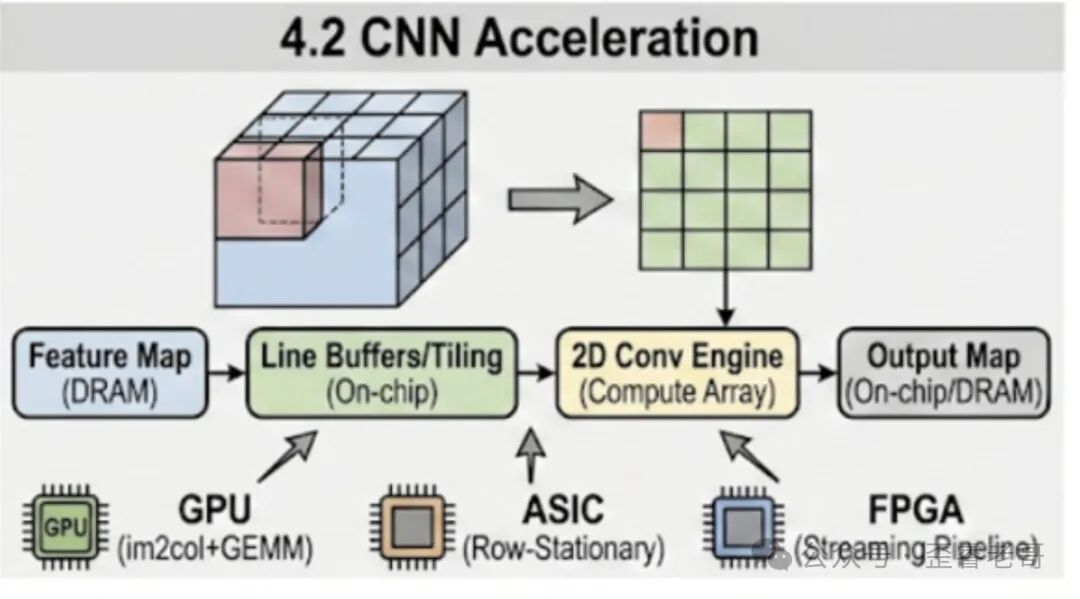
ASIC 上的 CNN 加速
CNN 的 ASIC 设计,经典案例是 Eyeriss。它的核心理念是行驻留映射(row-stationary mapping):让输入特征的一个“行”在计算过程中驻留在本地缓冲区,权重和输出部分和在阵列中流动。这样能最大化数据复用,最小化 DRAM 访问。
关键设计是层次化的缓冲和片上互连,确保数据在正确的时间出现在正确的位置,以维持数据流。
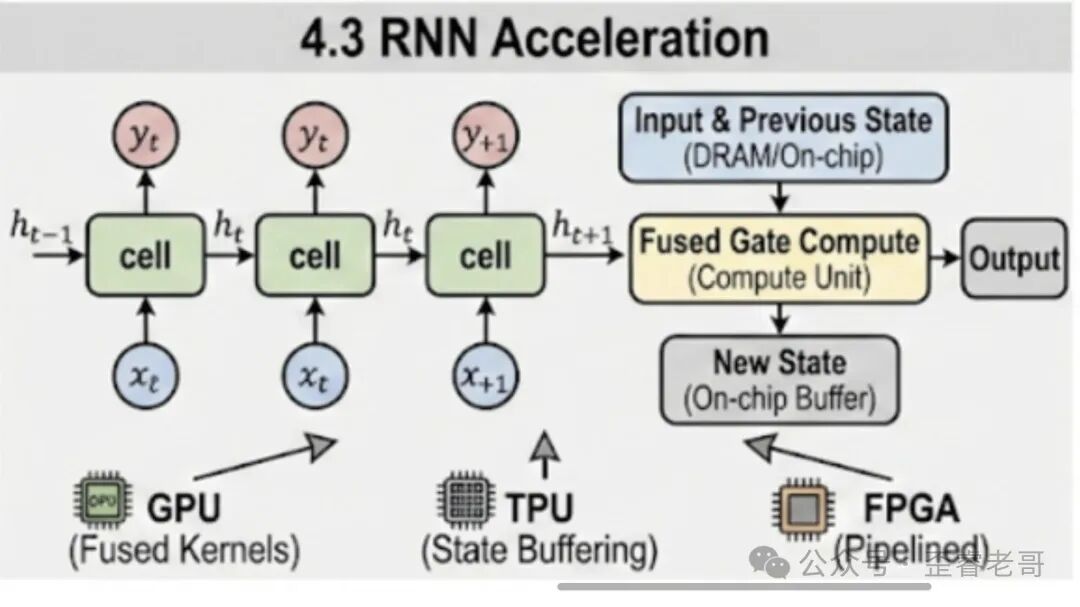
四、RNN 加速器:时序依赖的挑战
计算模式
RNN 和 ANN、CNN 最大的不同在于时序依赖。RNN 的隐藏状态在每一步都会更新,并且影响下一步的计算。这意味着RNN 难以并行化,每一步都必须等上一步的结果。因此,RNN 的加速方向不是追求吞吐量,而是降低单步延迟。
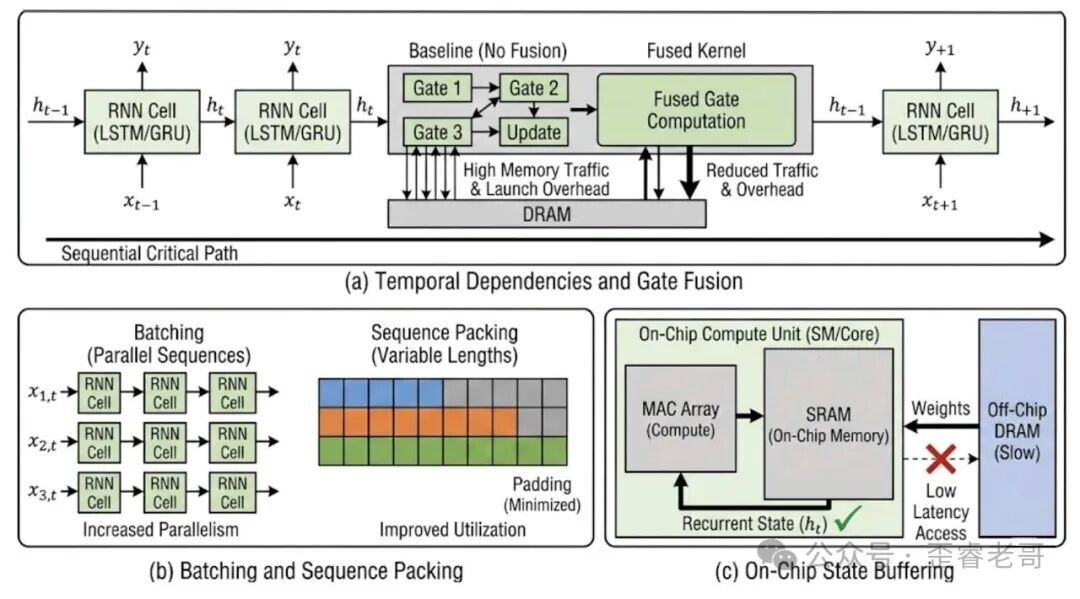
关键技术
Gate Fusion(门融合)
LSTM 和 GRU 有多个门——遗忘门、输入门、输出门等,每个门都是一次矩阵乘法加激活函数。传统做法是每个门独立执行,中间结果写入显存再读回来。融合的做法是把所有门操作合并成一个内核,中间结果存在寄存器或 shared memory 里,避免显存往返。
On-chip State Buffering(片上状态缓冲)
RNN 的隐藏状态每一步都要读写,如果每次都要访问 DRAM,带宽会成为瓶颈。好的设计是把隐藏状态和权重缓存在 SRAM 里,每一步只需要在内部传递,不需要访问外部内存。
实际瓶颈
RNN 的实际瓶颈往往不是 MAC 吞吐量,而是软件栈的调度效率。每次 kernel launch 的开销、不同 timestep 之间的同步开销,都比计算本身更耗时。所以 RNN 加速的核心是减少内核数量、减少内存访问、保持循环紧密。
Transformer 的计算模式是三者中最复杂的。它包含密集矩阵乘法(QKV 投影、MLP 块)和带宽密集型注意力机制,而且推理阶段有自回归生成的额外开销。具体来说,LLM 推理分为两个阶段:
Prefill(预填充):一次性处理整个 prompt,计算密集,适合批量处理。
Decode(解码):每次只生成一个 token,需要读取/写入 KV cache,计算量小但内存访问量大。
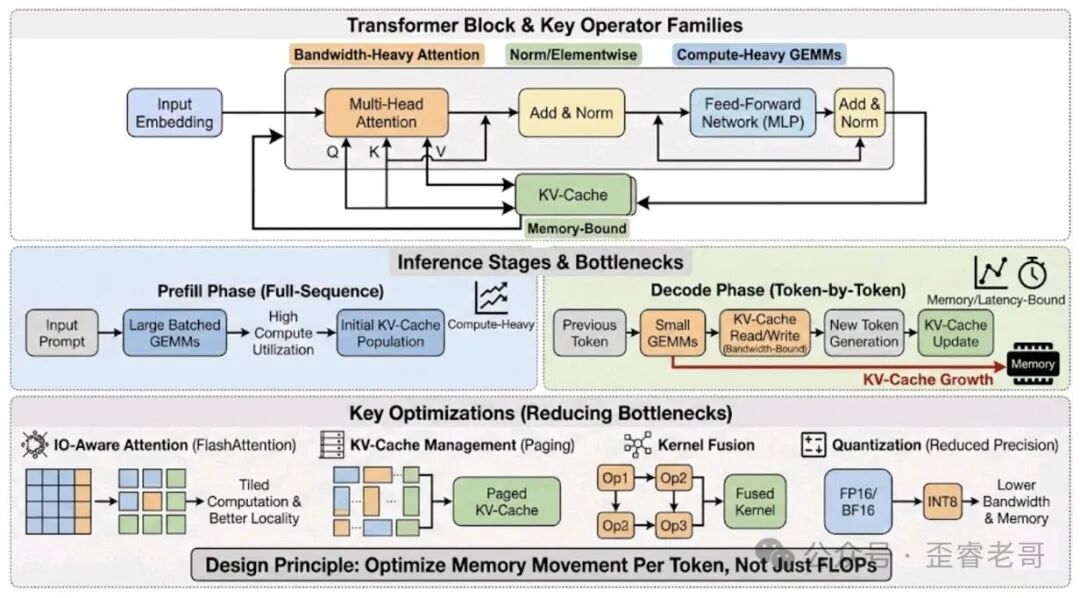
Decode 阶段就是瓶颈所在。 每个 token 的生成,需要读取整个 KV cache,执行一个小矩阵乘法。对于 7B 模型,KV cache 可能有几 GB 的数据,每次生成一个 token 都要读这么多数据。这就是为什么大模型推理的瓶颈不是算力,而是内存带宽。
GPU 上的 LLM 加速
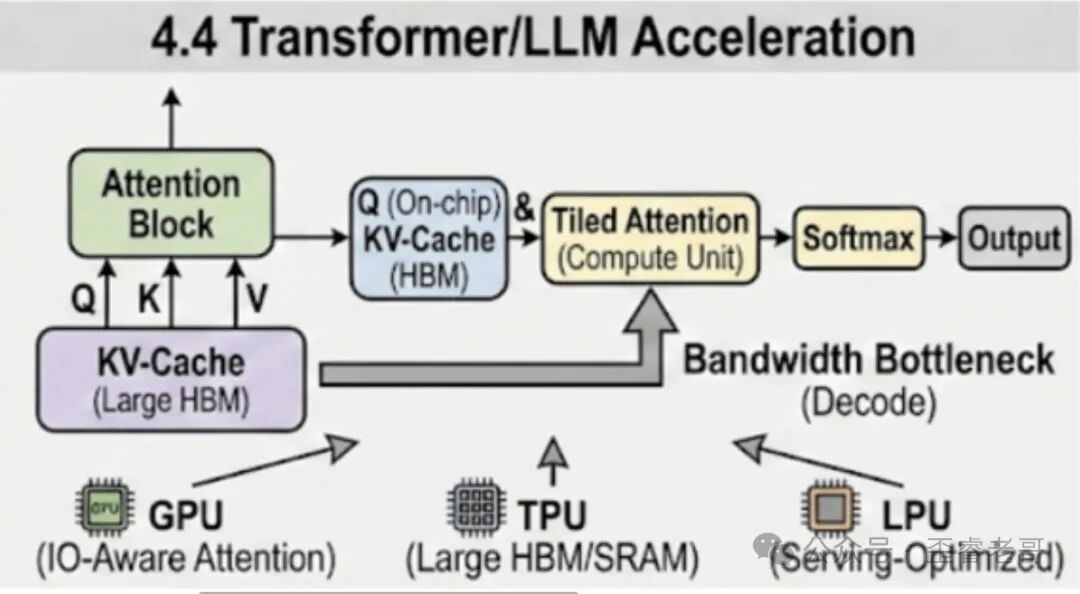
GPU 加速 LLM 的核心技术主要有三个:
IO-aware Attention(IO 感知注意力):传统注意力机制要把整个注意力矩阵计算出来然后做 softmax。IO-aware 的做法是分块计算,避免一次性把整个矩阵加载到内存。这也是 云栈社区 上很多开发者讨论的 FlashAttention 的核心思想。
KV Cache 管理和分页:KV cache 的增长会导致显存耗尽,影响并发。分页技术可以把 KV cache 分散存储,像操作系统的虚拟内存一样管理。
Speculative Decoding(推测解码):用小模型预测几个 token,然后大模型只验证这些预测。这样每次大模型推理可以生成多个 token,减少端到端延迟。
ASIC/FPGA 和专用推理加速器
专用 LLM 推理加速器的设计思路是优化 token 级延迟和能效。核心挑战是在 MAC 吞吐量和内存带宽之间做平衡。如果只优化 MAC,解码阶段就会因为 KV cache 读取而 stall;如果只优化内存,预填充阶段就利用不好硬件。
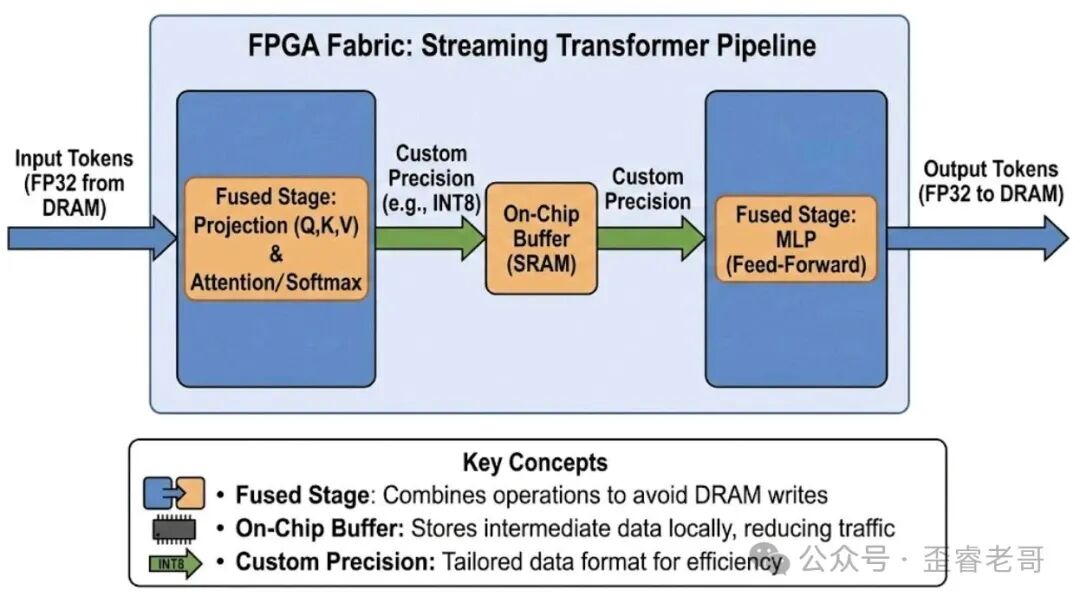
所以好的设计是全局系统效率优化:内存 provisioning、cache 管理、控制开销最小化,缺一不可。
六、总结:架构演进的核心逻辑
看完这个综述,我最大的感受是:硬件加速器的发展,本质上是算法演进的结果。
ANN 时代,计算模式简单,矩阵乘法是核心,加速器设计围绕 GEMM 展开。CNN 时代,引入了空间局部性,加速器设计开始利用数据复用和空间并行。RNN 时代,时序依赖成为瓶颈,加速器设计转向降低延迟和内存访问。
Transformer 时代,注意力机制和自回归生成带来了全新的挑战,加速器设计必须同时优化计算密度、内存带宽、cache 管理和调度策略。
算法变了,硬件必须跟着变。变慢了,就被淘汰。
所以未来加速器的方向,一定会更加定制化、更加系统化。不再是通用芯片的简单优化,而是算法、硬件、软件栈的全局协同设计。在 智能 & 数据 & 云 领域,这种软硬件协同的趋势已经越来越明显。如果你对 人工智能 的底层加速原理感兴趣,也欢迎进一步交流。
附:论文引用
本文内容基于以下论文:
Hardware Acceleration for Neural Networks: A Comprehensive Survey
主要技术点涵盖:
- ANN 加速:Tiling、Fusion、Mixed Precision
- CNN 加速:Winograd、Im2Col、Systolic Array
- RNN 加速:Gate Fusion、On-chip State Buffering
- Transformer 加速:IO-aware Attention、KV Cache Management、Speculative Decoding
- 硬件平台:GPU、TPU/NPU、ASIC、FPGA
 发表于 2026-5-2 18:08:55
|
查看: 258|
回复: 0
发表于 2026-5-2 18:08:55
|
查看: 258|
回复: 0
