一、概述:AMDGPU 后端的 AA 策略
AMDGPU 后端并未实现一套完全独立的别名分析引擎,而是采用 “复用 + 增强” 的策略。可以将其概括为四个层次:
| 层次 |
具体内容 |
| 框架层 |
完全复用 LLVM 的 AAResultsWrapperPass / BasicAliasAnalysis / TypeBasedAliasAnalysis |
| 语义层 |
利用 AMDGPU 特有的地址空间(global / local / private / flat)强制分离,天然提供 NoAlias 信息 |
| 应用层 |
在 SIInsertWaitcnts、AMDGPUPromoteKernelArguments 等 Pass 中调用 AA 进行精确查询 |
| 传递层 |
通过 MachineMemOperand 的 AAMDNodes 将 IR 别名信息下沉到 Machine IR |
核心优势:避免在 Machine IR 层重建复杂的指针分析,大幅降低工程复杂度;充分利用 LLVM 成熟的 TBAA、Scope‑AA 等优化;通过地址空间划分获得“免费”的高精度别名信息。
二、框架接入:复用 LLVM 通用 AA
在 LLVM Pass 中获取 AA 结果的标准模式如下:
// 在 Pass 的 getAnalysisUsage 中声明依赖
void getAnalysisUsage(AnalysisUsage &AU) const override {
AU.addRequired<AAResultsWrapperPass>(); // 请求 AA 结果
}
// 在 runOnFunction 中获取 AA 指针
bool runOnFunction(Function &F) override {
auto &AA = getAnalysis<AAResultsWrapperPass>().getAAResults();
// 使用 AA...
}
AMDGPU 后端中直接使用 AA 的 Pass 列表:
| Pass 名称 |
主要用途 |
SIInsertWaitcnts |
判断 LDS DMA 存储与后续 LDS 读取是否别名,以决定等待粒度 |
AMDGPUPromoteKernelArguments |
结合 MemorySSA 判断内核参数指针是否被函数内操作覆盖 |
AMDGPUUnifyMetadata |
统一 TBAA 元数据,辅助后续 AA 查询 |
SILoadStoreOptimizer |
合并连续的加载/存储时检查别名(通过 mayAlias) |
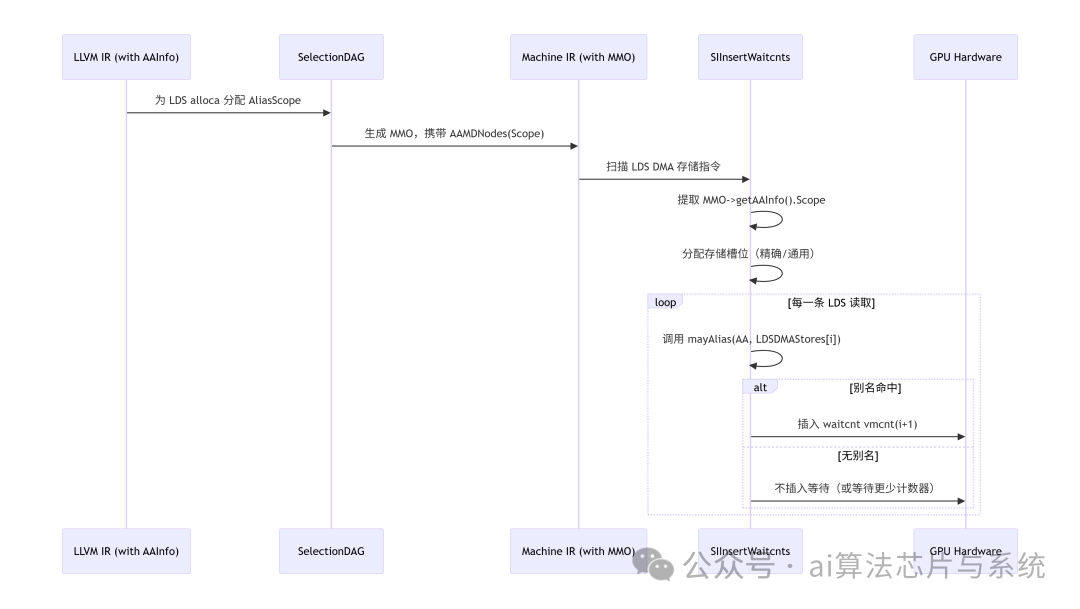
注意:获取 AA 后,通常不会直接调用 alias(),而是使用 MachineInstr::mayAlias(AA, OtherMI),该方法会遍历两条指令的所有 MachineMemOperand 并调用底层 AA。
三、SIInsertWaitcnts 中的 LDS DMA 别名分析
3.1 问题背景与挑战
LDS DMA 是指 VMEM 指令(如 buffer_load、flat_load)直接向 LDS 写入数据而绕过 VGPR。这类操作会:
- 增加
vmcnt 计数器(因为经过 VMEM 管道)。
- 写入的目标是 LDS 内存,而非 VGPR。
后续若有一条 ds_read 指令读取同一 LDS 地址,必须等待该 vmcnt 完成,否则会读到旧数据。
优化空间:如果编译器能证明两次访问的 LDS 地址不重叠,则可以省略这次等待,从而提升性能。
3.2 别名信息捕获流程
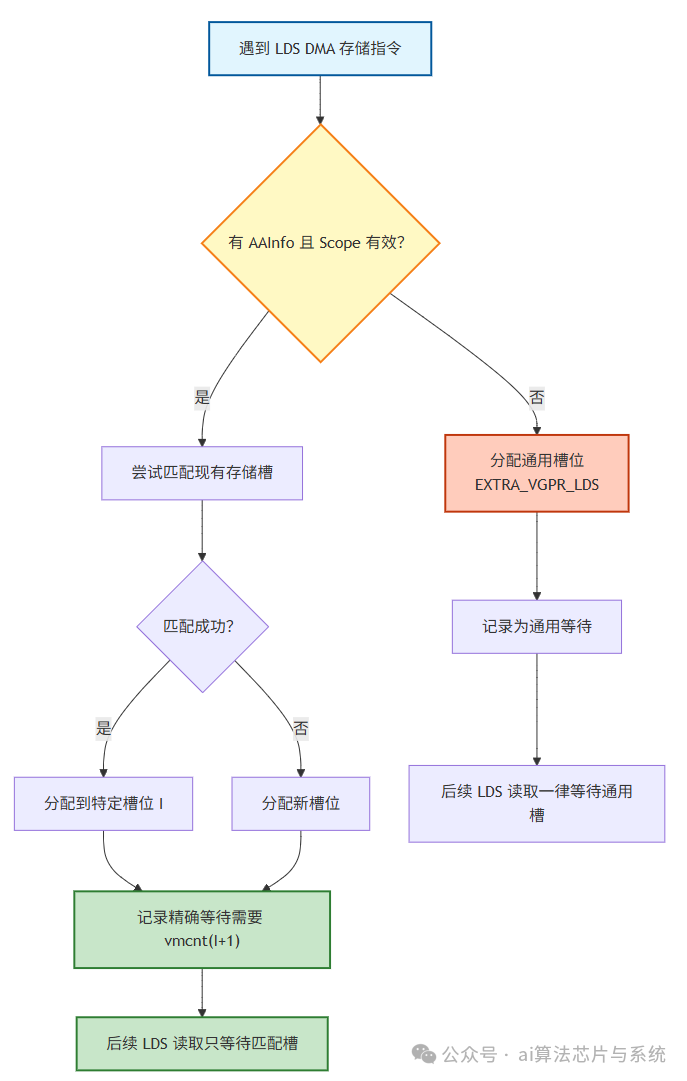
关键代码片段解读:
// 1. 遍历当前指令的 memoperands
for (const MachineMemOperand *Memop : MI.memoperands()) {
unsigned AS = Memop->getAddrSpace();
if (AS != AMDGPUAS::LOCAL_ADDRESS && AS != AMDGPUAS::FLAT_ADDRESS)
continue; // 只关心 LDS 或 FLAT 可能指向 LDS
// 2. 必须有 Scope 信息才能精确追踪
if (!Memop->getAAInfo() || !Memop->getAAInfo().Scope) {
// 无信息 → 回退到通用槽
break;
}
// 3. 遍历已记录的 LDS DMA 存储,匹配 Scope
for (auto *StoreMI : LDSDMAStores) {
if (MI.mayAlias(AA, *StoreMI, /*UseTBAA=*/true)) {
// 找到别名 → 生成针对该槽位的等待
ScoreBrackets.determineWait(LOAD_CNT, SlotIndex, Wait);
}
}
}
3.3 LDS DMA 存储槽管理策略
WaitcntBrackets 维护一个 LDSDMAStores 数组,最多容纳 NUM_EXTRA_VGPRS - 1 个具有不同 AAInfo.Scope 的存储代表。
存储槽分配规则:
| 情况 |
分配槽位 |
含义 |
| 无 AAInfo 或 Scope 为空 |
槽位 EXTRA_VGPR_LDS(固定) |
保守等待所有 LDS DMA |
| 有 Scope 且未匹配到 |
新槽位 1 … NUM_EXTRA_VGPRS-1 |
精确等待该 Scope 的存储 |
| 有 Scope 且匹配到已有槽位 |
复用已有槽位 |
多个存储共享同一等待 |
示例:
// 假设有两个不同作用域的 LDS DMA 存储
store1: buffer_load lds, ... // Scope = "MatrixA"
store2: buffer_load lds, ... // Scope = "MatrixB"
// 存储槽分配结果
LDSDMAStores[0] = store1 // 槽位索引 1
LDSDMAStores[1] = store2 // 槽位索引 2
// 后续 LDS 读取指令
ds_read v0, addr1 // 如果 addr1 属于 MatrixA 作用域,仅等待 vmcnt(1)
3.4 完整工作流程图
4.1 优化意图与条件
目的:将内核参数中类型为 addrspace(4)(generic 指针)提升为 addrspace(1)(全局指针),以便:
- 避免运行时地址空间解析(节省几条指令)。
- 使得该指针可以被更激进的全局内存优化(如合并)利用。
安全条件:该指针在函数内不会被任何内存操作覆盖(clobber)。即:
- 从该指针加载的值在函数生命周期内保持不变。
- 不存在对该指针指向内存的存储操作(或通过别名存储)。
4.2 结合 MemorySSA 与 AA 的判断
该 Pass 使用 MemorySSA 结合 AA 进行精确的 clobber 检测:
// 对于每个潜在的候选加载
if (LD->getPointerOperand()->stripInBoundsOffsets() == Ptr &&
!AMDGPU::isClobberedInFunction(LD, MSSA, AA)) {
Ptrs.push_back(LD); // 安全,可以提升
}
isClobberedInFunction 的内部逻辑可以概括为:
| 步骤 |
操作 |
依赖组件 |
| 1️⃣ |
获取 MemorySSA 中 LD 的内存定义(MemoryDef) |
MemorySSA |
| 2️⃣ |
遍历从该定义到函数出口的所有内存访问 |
MemorySSA 的 use-def 链 |
| 3️⃣ |
对每个潜在 clobber 访问(存储/原子/调用),调用 AA.alias(Ptr, OtherPtr) |
AA |
| 4️⃣ |
若 AA 返回 MayAlias 或 MustAlias,则视为 clobber |
AA |
| 5️⃣ |
若 AA 返回 NoAlias,则忽略该访问 |
AA |
示例:
// 内核函数
__kernel void foo(__global int *ptr) { // ptr 是 generic 指针
int a = *ptr; // 加载 1
*ptr = 1; // 存储 1 → 会 clobber ptr 吗? AA 判断 yes
int b = *ptr; // 加载 2 → 与存储 1 别名,无法提升 ptr
}
若中间没有对 ptr 的存储,则 isClobberedInFunction 返回 false,该加载可被提升。
4.3 提升后的标记与效果
一旦确认安全,Pass 会设置 amdgpu.noclobber 元数据:
LI->setMetadata("amdgpu.noclobber", MDNode::get(LI->getContext(), {}));
该元数据的作用:
- 告知后续优化通道(如
LICM、GVN)该加载结果在函数内不变。
- 指令选择时,可能生成更高效的直接地址模式(无需 runtime 解析)。
五、地址空间语义对 AA 的天然增强
5.1 AMDGPU 地址空间列表
| 数值 |
名称 |
说明 |
AA 性质 |
| 0 |
PRIVATE_ADDRESS |
线程私有(scratch) |
不同线程不别名,但 AA 无法跨线程,保守视为同地址空间 |
| 1 |
GLOBAL_ADDRESS |
全局内存(VRAM) |
不同指针可能别名,依赖 TBAA/范围 |
| 2 |
CONSTANT_ADDRESS |
常量只读内存 |
读操作与写操作天然 NoAlias |
| 3 |
LOCAL_ADDRESS |
LDS(工作组共享) |
不同工作组不别名,但 AA 只在一个函数内分析,视为同地址空间 |
| 4 |
FLAT_ADDRESS |
运行时解析(全局/局部/私有) |
最保守,默认 MayAlias |
| 5 |
REGION_ADDRESS |
GDS(全局数据共享,极少用) |
类似全局 |
5.2 地址空间带来的别名判定表
| 操作 A 地址空间 |
操作 B 地址空间 |
AA 结果 |
原因 |
| GLOBAL (1) |
CONSTANT (2) |
NoAlias |
硬件分离,常量只读,全局可写 |
| GLOBAL (1) |
LOCAL (3) |
NoAlias |
物理存储不同(VRAM vs LDS) |
| GLOBAL (1) |
PRIVATE (0) |
NoAlias |
私有内存是 scratch,不在全局视图中 |
| LOCAL (3) |
FLAT (4) |
MayAlias |
FLAT 可指向 LDS |
| CONSTANT (2) |
CONSTANT (2) |
取决于 TBAA/范围 |
同一地址空间,需要其他分析 |
5.3 典型示例分析
// 示例:全局指针和 LDS 指针
__global int *gptr;
__local int *lptr;
// 在任何情况下,gptr 和 lptr 都绝对不会别名
// AA 可以直接返回 NoAlias,无需分析具体地址值
int a = *gptr;
int b = *lptr; // 与上一行 NoAlias
这种基于地址空间的强制 NoAlias 是 AMDGPU 后端能获得高精度 AA 的基石,且几乎零成本。
六、Machine IR 层的别名信息传递
6.1 从 LLVM IR 到 Machine IR 的信息下沉
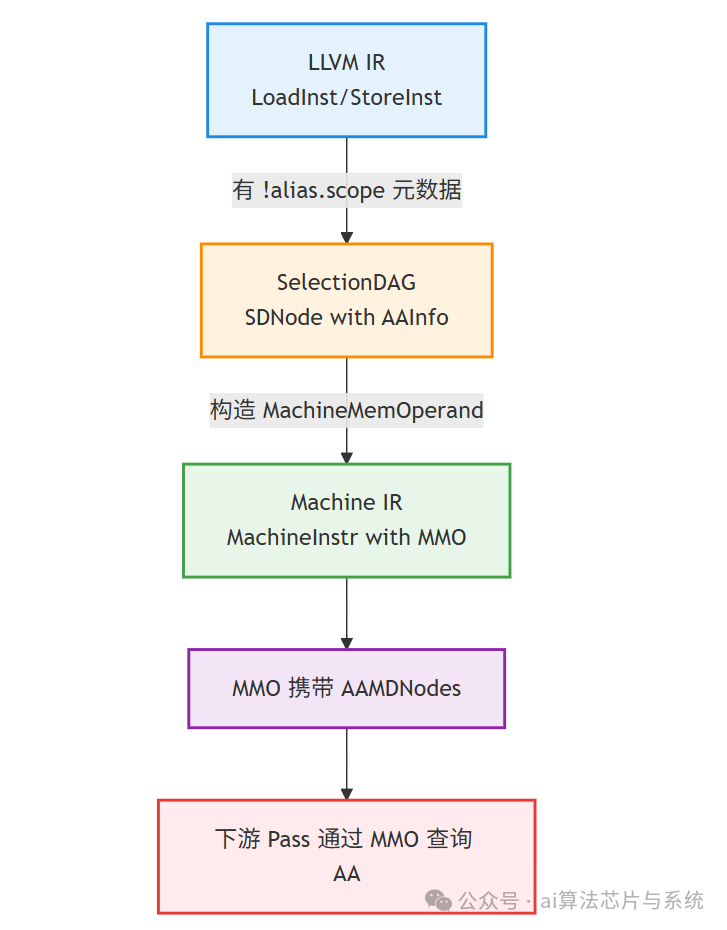
6.2 AAMDNodes 结构详解
AAMDNodes 定义在 llvm/IR/Metadata.h,包含:
| 字段 |
含义 |
来源 |
TBAA |
类型基础别名分析的标签 |
!tbaa 元数据 |
Scope |
别名作用域标识 |
!alias.scope 元数据 |
NoAlias |
不别名声明的集合 |
!noalias 元数据 |
在 MachineMemOperand 中,这些信息可通过 getAAInfo() 获取,并用于 MachineInstr::mayAlias。
6.3 图像内联优化器中的等价性推断
AMDGPUImageIntrinsicOptimizer 虽然不直接调用 AA,但它通过值等价性推断别名:
// 合并四个独立的 image_load_2dmsaa(不同样本)为单个 image_msaa_load
if (Load0->getAddress() == Load1->getAddress() &&
Load0->getDMask() == Load1->getDMask()) {
// 判定为相同图像坐标,可合并
}
这是一种轻量级的“强别名”推断:如果地址表达式完全相同,则它们指向同一内存对象。
七、局限性与保守性分析
7.1 主要局限性列表
| 局限性 |
描述 |
影响 |
| Machine IR 信息丢失 |
某些 SelectionDAG 模式未能正确传递 AAInfo |
后端被迫 MayAlias,增加等待 |
| LDS 别名依赖前端 Scope |
如果 IR 层所有 LDS 使用同一个 alloca,则 Scope 为空 |
LDS DMA 无法分槽,总是全等待 |
| 图像/纹理 AA 盲区 |
image_load 使用不透明描述符,AA 无法分析坐标别名 |
仅能基于坐标等价性优化 |
| 原子操作保守处理 |
原子操作标记为 mayLoad+mayStore,AA 总是返回 MayAlias |
即使地址不相交也无法优化 |
| 跨函数分析缺失 |
AA 是函数内分析,无法处理跨函数指针别名 |
PromoteKernelArguments 等 Pass 需额外保守 |
7.2 保守性场景示例
// 示例:IR 层 LDS 分配未带不同 Scope
%lds = alloca [256 x i32], addrspace(3) ; 只有一个 LDS alloca
// 所有 LDS 访问都基于这个 alloca 进行 GEP
// 则所有 LDS DMA 的 AAInfo.Scope 都相同(或为空)
// → 后端无法区分不同的 LDS 对象,所有 LDS DMA 共享一个等待槽
解决方案:前端应使用 llvm.amdgcn.lds.kernel.by.kernel 或为不同的 LDS 对象分配不同的 alias.scope。
八、总结
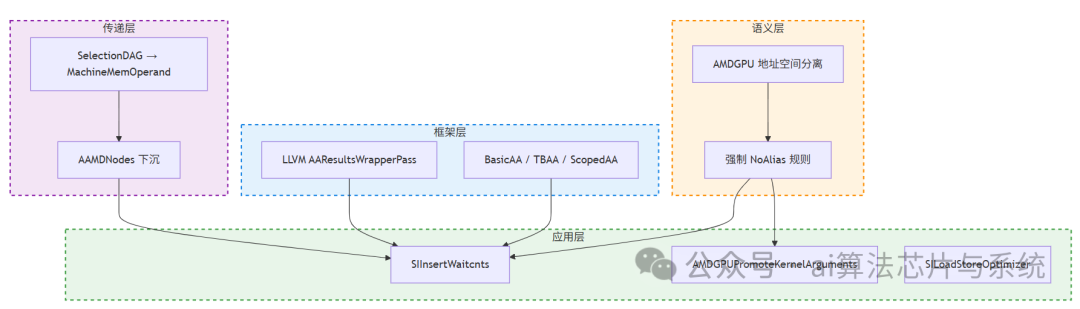
核心结论:
- ✅ 完全复用 LLVM 标准 AA,不重复造轮子。
- ✅ 利用地址空间语义获得“免费”的高精度别名信息。
- ✅ 在
SIInsertWaitcnts 中实现了精细的 LDS DMA 等待槽分槽,显著减少不必要的同步。
- ✅ 结合 MemorySSA 和 AA 实现安全的内核参数提升。
- ⚠️ 受限于 Machine IR 信息传递和部分内存操作的不可分析性,仍存在保守场景。
理解这套机制对于编写高性能 AMDGPU 内核以及调试等待计数相关问题至关重要。如果你对编译器如何与硬件底层交互感兴趣,在 智能 & 数据 & 云 板块能看到更多关于 GPU 架构和计算模型的内容。
总结一句话:AMDGPU 后端通过复用 LLVM 标准 AA,并借助地址空间强制分离和 MachineMemOperand 元数据,在关键优化点实现了精确的别名查询,同时通过保守策略保证正确性。
 发表于 2026-5-2 01:24:29
|
查看: 147|
回复: 0
发表于 2026-5-2 01:24:29
|
查看: 147|
回复: 0
