故事是这样的。2022 年夏天,斯坦福的一组研究者发了篇论文,标题叫《FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness》。
这名字听着挺无聊的,对吧?一堆缩写、一个技术名词,跟每天几百篇论文里随便哪篇长得都一样。但我读完却觉得,这件事挺有意思的。因为它解决了一个几乎所有做 Transformer 的人都踩过坑的问题:大模型推理慢,到底慢在哪里。
很多人第一反应是“算不动”,觉得算力不够,换更大的 GPU 就行。但这篇文章的作者 Tri Dao 一帮人说了句不一样的话:不是算不动,是数据搬不动。他们管这个叫 IO-Awareness ——在写注意力算法的时候,不要只盯着 FLOP 数看,要把 GPU 显存层级之间的读写次数也算进去。
听起来像废话对吧,但就是这个“废话”,让 Transformer 的训练速度提升了 3 倍,内存消耗降低了 20 倍,还让 Transformer 第一次在 64K 长度的序列上跑出了好结果。64K。之前所有方法,要么跑不了,要么跑出来跟随机猜差不多。
这篇文章,我想把这个论文的核心内容,用人话讲清楚。
问题:注意力机制的平方复杂度
先看最基本的注意力公式:
O = softmax(QK^T / sqrt(d)) V
三个矩阵相乘,再加一个 softmax。看起来很简单对吧。但问题在于,Q 和 K 的矩阵乘法会生成一个 N×N 的注意力矩阵,其中 N 是序列长度。这意味着时间和空间复杂度都是 O(N²)。序列长度翻倍,计算量翻四倍。这个平方复杂度是 Transformer 的天然缺陷,从 2017 年那篇“Attention Is All You Need”出来就没变过。
现有方案的局限
过去几年,一堆人想解决这个问题。方案主要分两类:
第一类,近似注意力。 用稀疏化、低秩分解、核函数近似等等手段,把注意力矩阵从 N×N 压缩到接近 N×1。这类方法理论上把计算复杂度降到了线性或近线性,但实际跑起来,墙钟时间(wall‑clock time)并没有明显加速。为什么?因为很多方案只关注减少 FLOP,忽略了内存访问的开销。
第二类,稀疏注意力。 让每个 token 只关注有限的其他 token,直接剪掉大量注意力连接。这种方法确实减少了计算量,但稀疏模式本身也有内存访问的 overhead,而且效果往往不如 dense attention。
作者的判断
这篇文章的作者认为,现有方案没效果的根本原因不是算法不行,而是没有考虑 GPU 内存层级的 IO 特性。现代 GPU 的内存层级是这样的:

- DRAM(系统内存):容量最大(几十 GB 到几百 GB),速度最慢(大约 12.8 GB/s)
- HBM(高带宽内存):GPU 显存,容量中等(40–80 GB),速度中等(大约 1.5–2.0 TB/s)
- SRAM(片上缓存):容量最小(A100 每个 SM 大约 192 KB),速度最快(大约 19 TB/s)
从 HBM 到 SRAM,带宽差了一个数量级。但现代 GPU 的计算速度已经超过内存速度了,操作越来越被内存访问(IO)而不是计算本身瓶颈住。所以,关键问题不是 FLOP 多不多,而是有多少数据在 HBM 和 SRAM 之间来回搬。这就是“IO‑Awareness”的核心思想。
2. 标准注意力实现的问题
标准算法:三步走
标准的注意力实现通常是三步:
第一步:计算 QK^T
把 Q 和 K 从 HBM 读到 SRAM,在芯片上算 QK^T,结果写回 HBM。这一步产生了一个 N×N 的注意力分数矩阵 S。
第二步:Softmax
把 S 从 HBM 读出来,逐行做 softmax,得到 P 矩阵。P 再写回 HBM。
第三步:PV
把 P 和 V 从 HBM 读出来,在芯片上算 PV,结果写回 HBM。
这三步看起来很自然,但每步都在做一件事:把中间结果从 HBM 写出去,再从 HBM 读进来。
HBM 访问次数的分析
前向传播:
- 第一步:读 Q、K,写 S → O(N²d + N²) 次 HBM 访问
- 第二步:读 S,写 P → O(N²) 次 HBM 访问
- 第三步:读 P、V,写 O → O(N²d + N²) 次 HBM 访问
总共 O(N²d + N²) 次,序列长度的平方级。
反向传播:
反向传播需要用到前向计算的 S 和 P 矩阵,同样要读 S、P 写回 dQ、dK、dV,也大约 O(N²d + N²) 次 HBM 访问。
核心矛盾
整个前向 + 反向传播的 HBM 访问总量大约是 O(N²d) 次。但输入 Q、K、V 本身的总大小只有 O(Nd),输出 O 也只有 O(Nd)。数据量是 O(Nd) 的东西,为什么要做 O(N²d) 的 HBM 访问? 多出来的 O(N²) 次访问,全是用在那个大得离谱的 N×N 注意力矩阵上。这个矩阵太大,放不下 SRAM,只能在 HBM 和 SRAM 之间反复搬。这就是标准实现的根本问题。
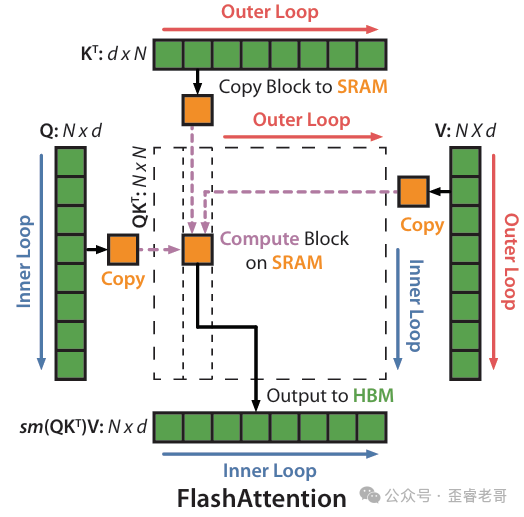
3. FlashAttention 算法:核心思路
两个关键技术
FlashAttention 的思路很简单:用两个经典技术,避免把 N×N 注意力矩阵写到 HBM 上。 这两个技术是:
- Tiling(分块计算)
- Recomputation(重计算)
Tiling:分块做 Softmax
标准 softmax 需要对整行做归一化,看起来必须把整行读进来才能算。但数学上有个技巧:softmax 可以分块计算。具体来说,如果我把一个向量 x 拆成两段 x¹ 和 x²,那么整个向量 x 的 softmax 结果,可以用 x¹ 和 x² 各自的 softmax 统计量(最大值 m 和归一化因子 ℓ)来逐步合并。
公式大概是:
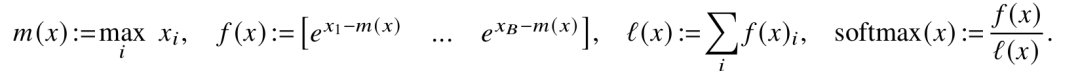
这样,每次处理一个块,只需要记录两个小值(m 和 ℓ),就能把结果正确合并起来。
所以 FlashAttention 的做法是:把 K、V 分成多个块;每次只把一个块加载到 SRAM;对 Q 的每个块,和 K 的这个块算 QK^T;在 SRAM 里算 softmax,更新 m 和 ℓ;逐步累积输出,最后写回 HBM。关键:整个过程中,N×N 注意力矩阵从来没有完整地出现在 HBM 上。
Recomputation:反向传播时不再读矩阵
反向传播怎么办?反向传播需要用到前向的 S 和 P 矩阵。标准做法是把前向的 S 和 P 存在 HBM 上,反向时直接读。但 FlashAttention 说:不存了,反向时重新算。 它只存前向的输出 O 和 softmax 的统计量 m、ℓ,这两个东西很小,O(Nd) 的大小。反向传播时,从 HBM 读 Q、K、V,重新在 SRAM 里算 S 和 P,然后再算梯度。虽然多算了一些 FLOP,但因为避免了从 HBM 读 N×N 矩阵的开销,实际运行时间反而更快。这在学术上叫选择性梯度检查点(selective gradient checkpointing)。
4. IO 复杂度分析
理论保证
文章给出了严格分析。标准注意力的 HBM 访问次数是 Θ(N²d + N²)。FlashAttention 的 HBM 访问次数是 Θ(N²d / M),其中 M 是 SRAM 的大小。
为什么是 N²d / M?因为 SRAM 能放下大小为 Θ(M) 的 K、V 块,每次能处理 Θ(M/d) 个 K 行。对于 N 行的 Q,需要 N / (M/d) = Nd/M 次扫描。每次扫描加载 O(Nd) 数据,所以总共 O(N²d / M) 次 HBM 访问。
实际差距
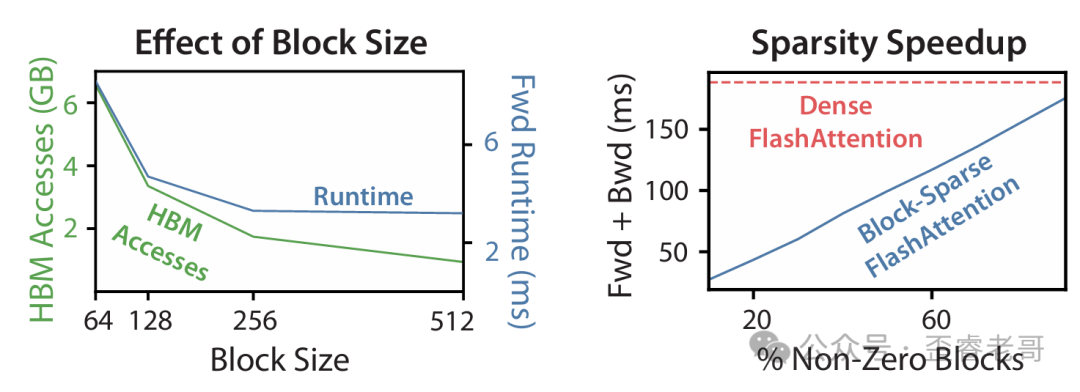
拿 A100 来算:d = 64(head 维度),M ≈ 100KB(每个 SM 的 SRAM)。标准注意力:O(N² × 64) 次 HBM 访问;FlashAttention:O(N² × 64 / 100000) ≈ O(N² × 0.00064) 次 HBM 访问。HBM 访问量减少了大约 100 倍。 虽然实际不可能完全达到理论极限,但文章实验显示前向传播减少了约 8 倍,反向传播减少了约 7 倍,合计约 9 倍的 HBM 访问量降低。
下界证明
文章还证明了一个有意思的结论:对于任何精确注意力算法,在所有可能的 SRAM 大小范围内,不可能渐近地优于 O(N²d / M) 的 HBM 访问下界。 换句话说,FlashAttention 在这个意义上是最优的。
5. Block‑Sparse FlashAttention
扩展:稀疏注意力
FlashAttention 不只是精确注意力,还可以扩展到稀疏注意力。思路很简单:如果注意力矩阵是块稀疏的(比如某些块全是零),那么在 Tiling 循环中直接跳过这些块就行。算法跟 FlashAttention 几乎一样,只是加了一个 if 判断:如果当前块 M_ij = 0,跳过计算。文章证明了 Block‑Sparse FlashAttention 的 HBM 访问次数是 Θ(N²d · s / M),其中 s 是非零块的比例。s 越小,加速越多。实验显示,在 LRA benchmark 上,Block‑Sparse FlashAttention 相对于标准 FlashAttention 有 2.8 倍的加速,同时精度相当。
6. 实验结果
训练速度
- BERT‑large:在 MLPerf 1.1 上,FlashAttention 比 NVIDIA 记录快了 15%(从 20.0 分钟降到 17.4 分钟)。
- GPT‑2 small:比 HuggingFace 实现快 3.5 倍(从 9.5 天降到 2.7 天),比 Megatron‑LM 快 2.0 倍(从 4.7 天降到 2.7 天)。
- GPT‑2 medium:比 HuggingFace 快 3.0 倍(从 21.0 天降到 6.9 天),比 Megatron‑LM 快 1.7 倍(从 11.5 天降到 6.9 天)。
- Long‑Range Arena:平均加速 2.4 倍。
模型质量提升
FlashAttention 不只是更快,还能训练出更好的模型。
- GPT‑2 长上下文:用 FlashAttention 训练 GPT‑2 small,上下文长度从 1K 提升到 4K,仍然比 Megatron 的 1K 版本快 30%,且 perplexity 低了 0.7。
- 长文档分类:在 MIMIC‑III(医疗文本分类)和 ECtHR(法律判决分类)上,增加序列长度带来显著提升:MIMIC‑III 16K 序列比 512 序列提升 4.3 分;ECtHR 8K 序列比 512 序列提升 8.5 分。
- PathFinder 挑战:Path‑X(16K 序列)FlashAttention 的 Transformer 达到 61.4% 准确率,是第一个在这个任务上超过随机猜测的 Transformer;Path‑256(64K 序列)Block‑Sparse FlashAttention 达到 63.1% 准确率。
基准测试
- 序列长度 128–512:FlashAttention 比 PyTorch 标准实现快 2–3 倍。
- 序列长度 1024–2048:FlashAttention 比所有近似注意力方法都快。
- 内存占用:FlashAttention 比 PyTorch 标准实现低 20 倍,比 Linformer 低 2 倍。
不同硬件上的表现
- A100:2–4 倍加速
- RTX 3090:2.5–4.5 倍加速(HBM 带宽更低,加速效果更明显)
- T4:加速较少(SRAM 更小,块大小需要更小)
7. 总结
这篇文章的核心贡献,可以用一句话概括:写注意力算法的时候,要把 GPU 内存层级的读写开销也算进去。 这个“IO‑Awareness”的思想听起来简单,但在深度学习这个领域里,很少有人真正认真对待过。大家习惯了看 FLOP 数,看理论复杂度,看 benchmark 上的 accuracy。但 FLOP 不等于 wall‑clock time,不等于内存使用量,不等于实际训练出来的模型质量。FlashAttention 用两个经典技术——Tiling 和 Recomputation——把注意力机制的 HBM 访问量从 O(N²) 降到了 O(N² / M),在保持精确计算的同时实现了 3 倍的加速和 20 倍的内存节省。而且它不只是更快,还让 Transformer 第一次真正具备了建模 64K 长度上下文的能力。这就是 IO‑Awareness 的力量。
如果你对 Transformer 模型的训练优化有更多兴趣,欢迎访问 云栈社区 与开发者交流实战经验。
 发表于 2026-5-2 18:05:39
|
查看: 226|
回复: 0
发表于 2026-5-2 18:05:39
|
查看: 226|
回复: 0
