2026 年 4 月 24 日上午,DeepSeek 又一次把“开源炸弹”丢进了大模型圈。没有预热,官微只有一句话:“今天,我们全新系列模型 DeepSeek-V4 的预览版本正式上线并同步开源”。从评分上看,这次的模型已经非常接近“闭源三巨头”的水平了,同时也是当之无愧的“地表最强开源模型”。但细读这份技术报告「DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence」,会发现 DeepSeek 的工作远比评分更硬核,无论是架构创新还是工程优化,都体现了其一贯的精雕细琢。如果你对前沿模型架构感兴趣,可以在 云栈社区 看到更多深入的技术探讨。
DeepSeek V4到底强在哪?
先看纸面参数:
- DeepSeek-V4-Pro:1.6T参数,稀疏激活49B,1M上下文
- DeepSeek-V4-Flash:284B参数,稀疏激活13B,1M上下文
有两个常见的小误解需要先澄清一下:
- “Flash 是 Pro 的蒸馏小模型?” —— 并不是。两者都是独立预训练出的 MoE 模型,区别仅在于规模和稀疏程度不同。
- “1M 上下文是可选开关?” —— 也不是。两个版本都默认支持 1M 上下文,服务端不再需要区分“长/短”文本模型。
再看评分:在编程、数学、Agent、长文本四个维度上,V4 同时跻身第一梯队,基本接近 GPT 5.4、Claude 4.6 及 Gemini 3.1 的水平,也是当之无愧的“开源最强”。
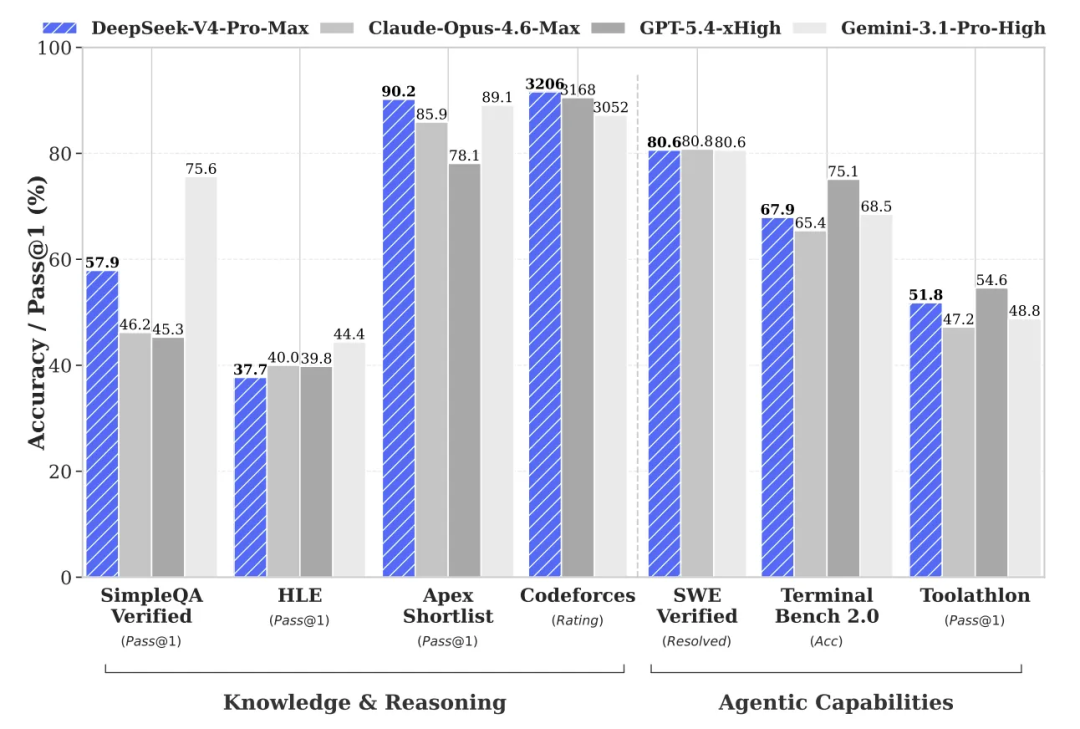
但 V4 真正硬核的地方绝不仅仅是 1.6T 参数和 1M 上下文,而是从 attention 到 kernel 的系统级重构与优化。DeepSeek 团队这次到底做了哪些工作?我们来一起深入浅出地解读一下。
开始之前的几个问题
为什么需要超长上下文?
或许在 OpenClaw 和 Hermes 这两个开源智能体框架走进公众视野之前,你可能会问:“我平时用 Chatbot 也就几千 token 足够了,1M 上下文到底谁在用?是不是厂商又在搞军备竞赛?”但当我们自己部署 OpenClaw 或 Hermes 作为助手时,会发现还没问几个问题就已经消耗了几十万甚至上百万 token 了。同时,随着智能体持久化记忆越来越多,传统的 128k 上下文窗口确实撑不住几轮对话。我用三个典型场景来说明原因:
场景一:Agent多轮任务轻松“吃”掉百万token。
一个跑 30 轮的 Coding Agent,每一轮都要向上下文里塞入:用户指令(几百 token)+ 读了三四个源文件(几千到几万 token)+ 执行了若干 shell 命令和它们的 stdout(又是几千 token)+ 自己的 reasoning trace(几千 token)。30 轮下来,数十万 token 只是起步价。V3.2 为什么要在新用户消息到来时丢弃 thinking history?不是它不想留,是留不下。
场景二:整仓库级代码理解 / 重构。
一个中型 Python 项目,300 个文件、15 万行代码,分词之后大约 80–120 万 token。以前的做法是 RAG:向量检索挑几个相关文件塞进去。但重构、跨文件一致性检查、类型推导这些任务,RAG 漏掉一个调用点就是一个 bug。超长上下文的意义在于:整仓扔进去,让模型自己看见所有调用关系。V4 在 SWE Verified 上拿到 80.6 的成绩,和它能“一口气读完整个项目”直接相关。
场景三:长文档推理。
一份 200 页的法律合同、一份 500 页的学术综述、一套季度财报的四个附件——单个文档 50–80 万 token 是很常见的。以前的做法是切块、摘要、再合并,前后逻辑缺失严重;现在可以直接让模型在原始材料上进行跨段落推理。MRCR 1M 这个指标考的就是这个能力——V4-Pro 在这上面拿到了 83.5,开源最高。
因此,1M 上下文绝不仅仅是“能写更长的 prompt”,它让 Agent、整库代码、长文档等任务的执行真正变得高效且可落地。
我们知道,在标准 Transformer 架构模型的推理过程中:
- Prefill 阶段,整段上下文一次性输入,注意力机制的计算复杂度是 $O(L^2)$——L 提升 8 倍,prefill 的计算量就会膨胀 64 倍。
- Decode 阶段,每生成一个 token 都要把前面所有 L 组 KV 缓存从 HBM 搬运一遍,显存占用和带宽压力都与 L 成正比($Mem_{KV} \propto L$)。
与此同时,任务越复杂、上下文越长,模型也必然要做得更深、更宽,才能驾驭跨段落的复杂推理和长程依赖——但深度和宽度一增加,层间标准残差的稳定性就成了新瓶颈。
因此,传统 Transformer 架构要突破到 1M 上下文时代,必须同时解决三个问题:
- 如果标准残差机制中层间是一条统一固定的通道,那么需要升级为多条稳定可靠的通道,且每一层都可以通过“统一调度系统”来控制前序层的贡献值——让更有价值的层获得更高的表达能力。
- GPU 能在有效时间内算得过来,显存也能存得下。
- 万亿参数、深度更大的模型网络训练需要更加稳定与规范化。
以上这三个问题,正是 DeepSeek V4 在架构层面的三项核心创新所分别回应的。
架构层面的创新机制
mHC:多流约束的残差连接
开始之前,请先看一下三种残差机制的直观对比图,以便理解:
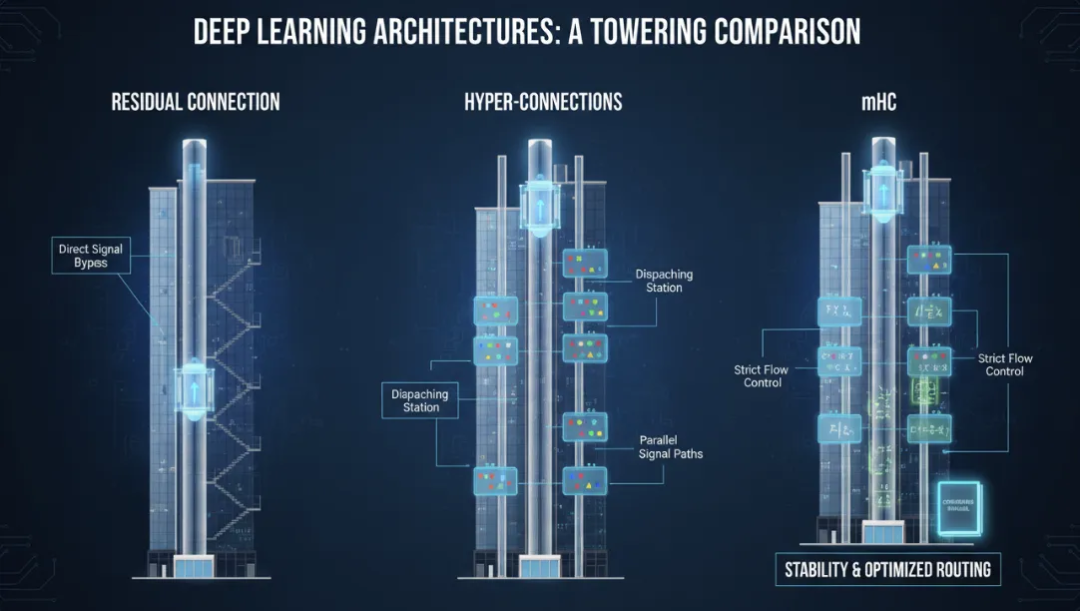
1. 标准残差:优雅但僵化
形象地理解标准残差:深层网络就像一栋 100 层的大楼,每一层都有自己的工作要做。标准残差就好比在每一层旁边修了一条直通天台的电梯井——让底层的信号不用挤楼梯就能直接通往上面任意一层。
标准残差的严谨定义:
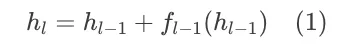
也就是每一层的输入隐状态 = 前一层的输入隐状态 + 前一层变换(attn 或 ffn 层)的结果。我们将这个公式逐层展开,同时令 $h_1=v_0$,$v_0$ 就是原始 embedding 后的结果用于模型输入;$v_i$ 代表每一层的变换结果 $f(h_i)$,得到如下公式:
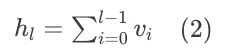
也就是说,每一层的输入,等于此前每一层变换结果的累加和,这也是标准残差的一条优雅性质。同时它也揭示了,历史每一层对深层的贡献是均等的。但数学上的优雅,却带来了实践中的僵化,具体体现在以下三方面:
- 容量瓶颈:所有层共用一条残差通路,浅层信息和深层信息都在同一条通路中“相互踩踏”,相互影响。
- 路由僵硬:标准残差是“无论如何都要均等地接受每一层的贡献”,没有“阀门”可以调节“这一层我需要哪些前序层分别贡献多少”,导致重要层的贡献被非重要层的贡献所稀释。
- 深度上限:万亿参数 + 百层以上时,由于多层累加的隐状态值无衰减累加的特性,导致标准残差会出现由梯度消失 / 激活爆炸带来的训练不稳定问题。
为了解决以上问题,改进的残差机制 Hyper-Connections 应运而生。
2. 标准 Hyper-Connections
形象地理解标准 Hyper-Connections:我们还是看那栋 100 层的大楼。标准残差好比在每一层旁修了一条通天的电梯井,但这栋楼里有人上楼、有人下楼、有人运货,大家都挤在一起,相互干扰。 Hyper-Connections 的思路就可以比喻为以下两点:
- 既然一条通道相互干扰,那就多修几条电梯。
- 有人上楼、有人下楼、有人运货还是互相干扰,那我们就让乘客每一层都下电梯,由大楼统一的调度系统根据乘客的目的地重新调度一次,再重新上电梯。(当然,用电梯的例子比喻,这在现实中反而会降低效率,但从算法的角度看,出通道、重新调度、再进通道是很快的)。
标准 Hyper-Connections 的严谨定义:

层间残差连接维护了 n 个流,每次层间变换(ATTN or FFN)前,先降流为 1,变换后的结果再升流为 n,进行带权重的残差加和。把上述公式展开成公式(2)的形式,得到如下公式:
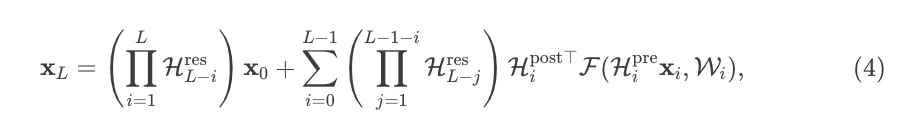
可以清晰地看到,这就是 HC 相对标准残差的本质区别:每一层的贡献是带权重、多流并行的。
标准 Hyper-Connections 看似从理论上解决了标准残差的问题,但实际上每一层的系数是残差映射矩阵 $H^{res}$ 的连乘计算。如果残差映射矩阵 $H^{res}$、降流矩阵 $H^{pre}$、升流矩阵 $H^{post}$ 都没有任何约束和限制,就会导致隐状态值衰减或爆炸,直接引发梯度消失 / 梯度爆炸。为了给这三个矩阵加上“运营规范”,DeepSeek 团队提出了 mHC 机制。
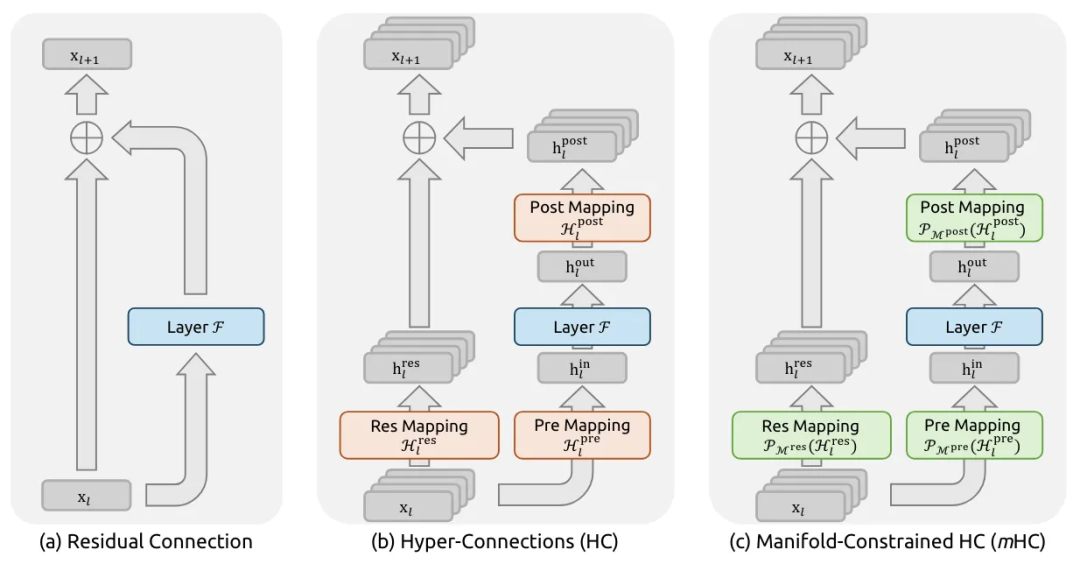
一张图看懂三种模式的演进:(a) 标准残差——单流直传;(b) HC——多流 + 三个映射(pre/res/post),但映射完全自由;(c) mHC——同样的多流 + 三个映射,但映射有约束以保证稳定。 上文只讲到了 (b),(c) 留给下一节。
3. Manifold-Constrained Hyper-Connections:多流约束的残差连接
形象地理解 mHC:如果说 HC 是给大楼修了多条电梯并配了统一的调度系统,那 mHC 就是给调度系统装上了一部严谨的“运营规范”,确保每次调度都不会让电梯超载、也不会让电梯空载。
mHC 的严谨定义:残差公式与标准 HC 的定义(公式3)完全一致,但是把残差映射矩阵 $H^{res}$ 限制在一个特殊的集合 M 上(公式 5),而降流矩阵 $H^{pre}$、升流矩阵 $H^{post}$ 仅需通过 sigmoid 限制在 (0,1) 范围内即可。
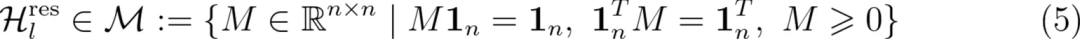
上述公式也称为「双随机矩阵」——每一行的和等于 1、每一列的和也等于 1、且所有元素非负,再配合 sigmoid,这就是我们上面比喻的运营规范。
那么,为什么需要把残差映射矩阵 $H^{res}$ 限制为「双随机矩阵」,而降流、升流矩阵仅需限制在 (0,1) 呢?我们再回顾一下公式(4),可以清晰地发现:历史每一层的系数都是残差映射矩阵 $H^{res}$ 连乘的结果,而每一层变换前后使用的降流、升流矩阵只和该层相关。 这就是 mHC “非对称约束” 设计的精髓——对高风险矩阵施加强约束,对低风险矩阵保持灵活。 而基于「双随机矩阵的乘法封闭特性」,可以使连乘之后的结果矩阵依然是双随机矩阵,从而确保公式(4)中每一历史层的系数均保持在 (0,1) 之间,也就从根本上解决了梯度消失/梯度爆炸的问题。
另外,标准残差连接和它的变种(比如 HighWay)实质上都是一种固定的函数表示路径,而 mHC 理论上可以达到通道数 m 种函数表示路径,这个结论也可以通过矩阵的半可分秩分析得到,这也从数学上证明了“多个通道”提升了网络的表达能力。
4. 其它残差优化机制
讲完了 DeepSeek 的 mHC,我们不妨把视野拉得更开一些——看看业界在残差机制上还有哪些有趣的尝试。这里简要介绍 Kimi 的注意力残差机制(Attn-Res)和分块注意力残差(Block Attn-Res)。其灵感同样是观察到标准残差机制无加权求和、层贡献被逐层稀释的问题,于是直接将无加权求和改为有权求和,其中权重参数通过注意力机制计算得到。但在实践过程中发现,每层都对所有历史层做注意力回看开销极大,因此设计了折中方案——分块注意力残差机制,即将 transformer 层进行分块,每个块聚合为单一表征,供后续阶段注意力查询使用,在保证效果和控制开销之间取得了权衡。实践证明,块数设为 8 时,可以达到全注意力残差几乎同样的效果,同时将开销控制在可接受的范围。
两种方案解决的是残差机制的不同侧面,没有绝对的优劣。这也是当前大模型架构设计中最有意思的地方:同样的问题,不同团队给出了风格完全不同的解法。
CSA / HCA:混合稀疏注意力机制
标准的 Transformer 里,每一层 attention 都要计算序列里每一对 token 之间的关联。在 4K 上下文的 ChatGPT 时代,这件事是理论上完美的,并且工程上跑得动的。 但当上下文窗口扩大到 1M 时,计算量立即膨胀 6.5 万倍,KV Cache 膨胀 256 倍,既算不过来,显存也存不下。 这就意味着,必须从“每一对都算”的范式里跳出来。 包含 CSA 和 HCA 两项核心创新的 Hybrid Attention,就是 DeepSeek V4 给出的解法。
开始之前,还是先看一个形象的比喻图,以方便理解:
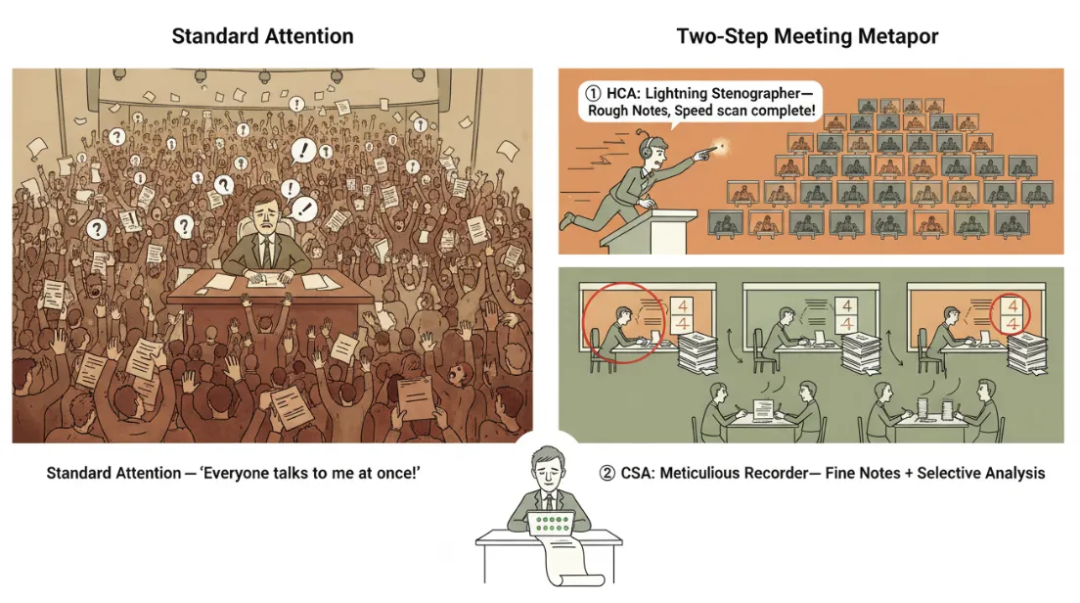
1. Compressed Sparse Attention:压缩稀疏注意力
形象地理解 CSA:与标准注意力里 token 两两直接计算关联度的做法不同,CSA 引入了一排“会议记录员”——他们不是会议的参与者,而是站在会议外围、专门做纪要的第三方。每位记录员负责把相邻两组所有人的发言综合成一份纪要。当要使用这些纪要时,通过索引找到高关联度的纪要,再逐一仔细查阅,最后得到自己所需的信息。我们可以把 CSA 形象地比喻为三个步骤:
- 步骤一:每位记录员记录相邻两组的发言,也就是说,除了序列末尾的那一组,每一组都会被两个记录员来记录。同一组的内容,自然也会被记录进两份不同的纪要。同时,记录员并不机械地抄录每个人的话——他会给每个人的每个“发言维度”独立打分:A 说的“时间维度”说得好,就多记录 A 的时间观点;B 说的“情感维度”说得深,就多记录 B 的情感观点。最终的纪要是两个组所有人在各自强项维度上的“最佳剪辑”——既压缩了信息,又保留了每个人的独到见解。
- 步骤二:当要使用这些整理好的纪要时,我们通过索引的方式,找到与我们预期关联度高的那部分纪要。
- 步骤三:然后再逐一精细查阅这些高关联度的纪要,整理相关信息,最后得出结论。
我们就按着这三个步骤来逐一分析 CSA 的具体设计。
压缩机制(对应步骤一):思路是把全部的 token 分组,每组 m 个 token。在压缩时,首先要确保组内每个 token 的贡献是加权的,其次通过把连续的两个组的压缩内容拼接在一起,来保证切割后语义的连贯性。
CSA 压缩机制的数学表达式为公式(6):
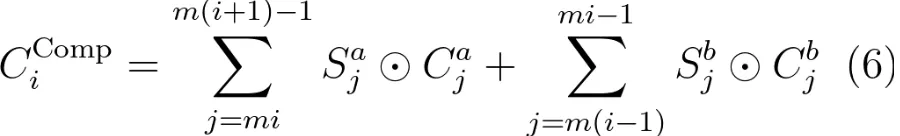
其中,公式左侧代表当前组 token 的带权重加和压缩,公式右侧代表前一组 token 的带权重加和压缩(注意这里的计算是哈达玛积,不是矩阵乘法)。矩阵 S 为权重矩阵,定义为公式(7):
![Softmax公式:[S^a_{...}; S^b_{...}] = Softmax_row([Z^a_{...} + B^a; Z^b_{...} + B^b])](https://static1.yunpan.plus/attachment/2cfe11bde396ae69.webp)
而计算上述内容需要的值投影矩阵 C 和矩阵 Z 由隐状态值投影得到:
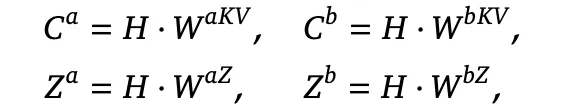
4 个 W 矩阵和 2 个偏置矩阵 B 都是可学习的,在训练过程中得到。
闪电索引机制(对应步骤二):思路与 DeepSeek V3.2 中的 DSA 机制一致,通过快速计算出每个 token 与压缩得到的全部“纪要”的关联度分数,同时每个注意力头加权后得到最终得分,随后选择关联度最高的 k 份纪要,供后续执行注意力计算时使用。
关联度分数计算方法为公式(8):
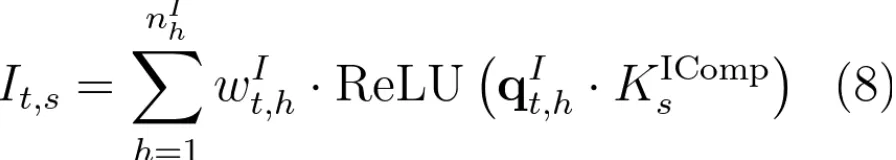
其中 K 矩阵采用和公式(6)完全一致的计算思路,它代表的其实是压缩结果的“key 投影”。每个 token 的查询矩阵 q 和注意力每个头的权重矩阵 w 也均由隐状态值投影得到:
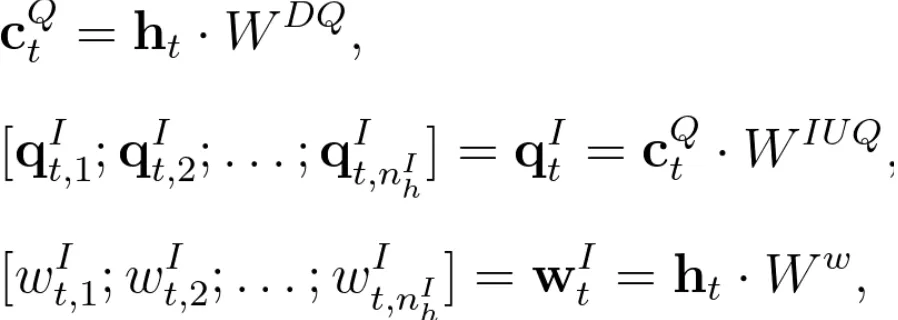
同样,投影计算用到的矩阵也都是通过训练得到的。
注意力计算(对应步骤三):这里其实就是标准注意力计算了,只是共享了 KV,注意力计算方法为公式(9):
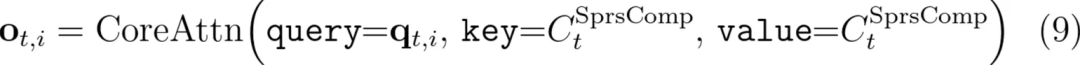
其中,KV 共享的 C 矩阵就是通过闪电索引 top-k 采样得到的 K 组压缩过的信息,q 是每个 token 的查询矩阵,计算方法不再赘述。
由此,就完成了 token 压缩 + 进一步稀疏采样的 CSA 机制。CSA 完整的架构也可以参考下图:
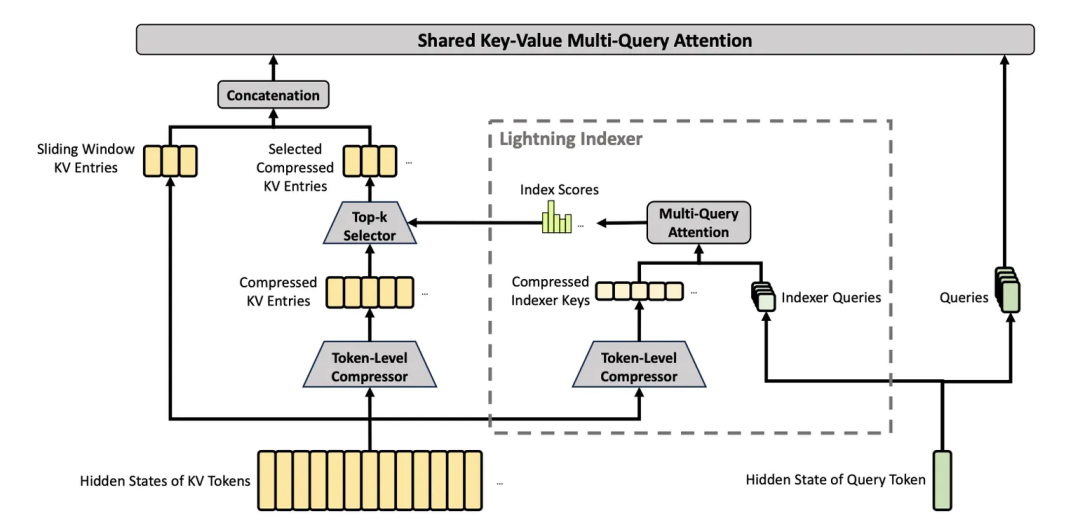
2. Heavily Compressed Attention:高度压缩注意力
形象地理解 HCA:它像一个速览版的 CSA,只是把“会议记录员”换成了“会议速记员”。在这个场景中,每场会议参与的人数更多,“会议速记员”要记录内容更多的会议纪要,但他仅需要聚焦于这一场会议,而不需要同时关注“前后两场小会”。当需要使用这些会议纪要时,由于每份纪要都是多人大会的纪要,总份数并没有那么多,直接逐一查阅即可。我们同样把 HCA 形象地比喻为两个步骤:
- 步骤一:每位速记员记录一场大会的全部发言,针对每个人发言内容的处理逻辑与 CSA 中记录员一致。
- 步骤二:当使用这些纪要时,直接逐一查阅每份纪要,整理相关信息,最后得出结论。
我们同样按着这两个步骤来逐一分析 HCA 的具体设计。
压缩机制(对应步骤一):与 CSA 的压缩思路类似,区别是每个组有 m' 个 token(m' ≫ m),并且不需要将连续两组的压缩内容拼接在一起。
HCA 压缩机制的数学表达式为公式(10):
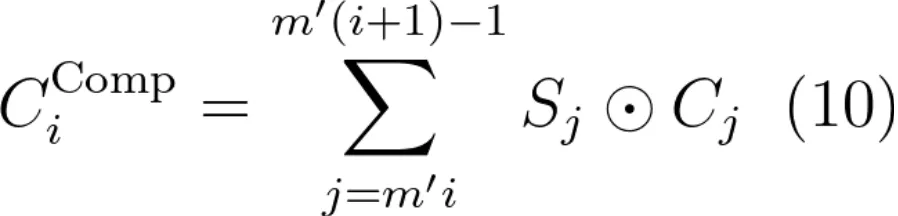
可以清晰地看到,HCA 的压缩机制无需拼接连续两组的内容,且加权计算、权重矩阵 S 和值投影矩阵 C 的计算方法与 CSA 中完全一致。
权重矩阵 S 定义为公式(11):
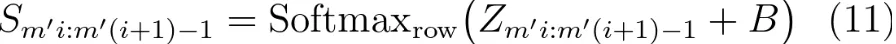
值投影矩阵 C 和矩阵 Z 也同样由隐状态值投影得到,2 个 W 矩阵和偏置矩阵 B 也都是可学习的,在训练过程中获得:
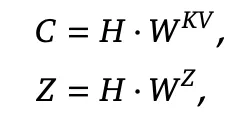
注意力计算(对应步骤二):计算方法与 CSA 的注意力计算相同,公式同样参考公式(9),区别在于这里使用每个 token 的查询矩阵 q 与 HCA 压缩计算得到的 C 矩阵进行注意力计算,计算时也同样共享 KV。
由此,就完成了高度压缩的 HCA 机制。HCA 完整的架构也可以参考下图:
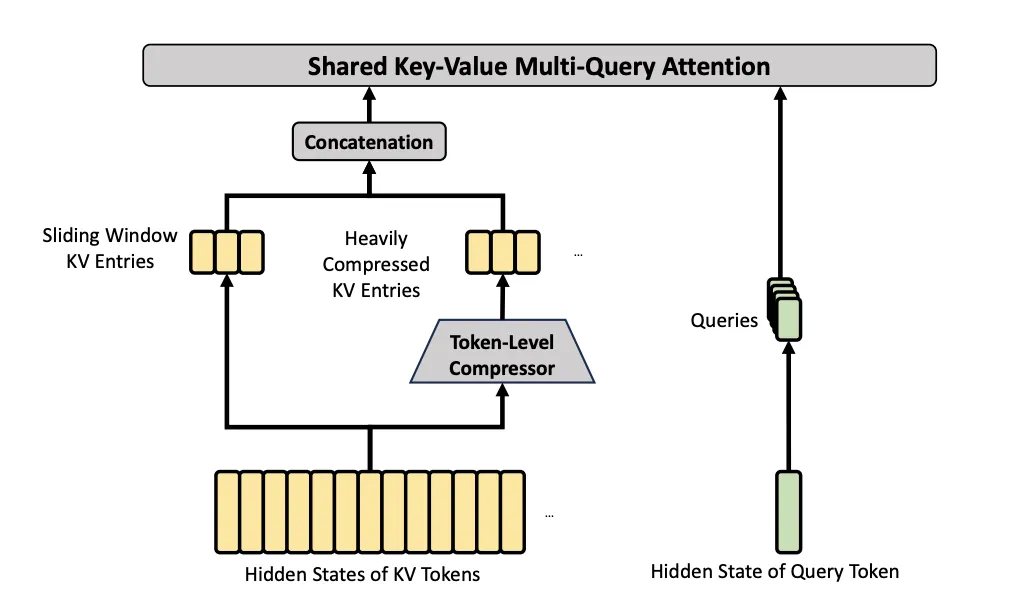
在实践中,先通过 HCA 来定位到上下文中关联度高的“大块信息”,随后在这些信息中进行 CSA 的稀疏注意力计算,实现“内容海选-内容精选-稀疏采样&精确计算”的三层处理,从而大幅优化超长上下文中的注意力计算量和 KV-Cache 消耗量。
3. 其它注意力优化机制
同样,我们也看看业界在长上下文的注意力机制上还有哪些有意思的尝试。这里简要介绍 Kimi、Qwen 采用的混合线性注意力机制。注意力计算中 Prefill 的计算量和 Decode 的 KV-Cache 消耗量巨大,主要是由于 Q、K、V 和 Softmax 计算机制相互耦合所导致。线性注意力的关键技巧在于引入了一个核函数来打破 Softmax 的约束,使其可以基于矩阵运算的乘法结合律先算 $K \times V$,再作 Q 计算。如此,则可以将计算复杂度由 $O(L^2)$ 降至 $O(L)$,同时也不再需要维护随序列长度增加的 KV-Cache,仅需维护一个固定大小的隐状态矩阵,从而使计算量和显存消耗量均大幅降低。
Muon优化器:让训练更加稳定,快速收敛
- 举措一:在训练过程中将梯度正交化,使梯度在正交变换后各方向独立更新,减少震荡发散,提升稳定性的同时,训练收敛速度也更快。——这就好比你在用两只手配合拧一个魔方——左手拧一下,右手又拧回来,最后魔方越拧越乱。梯度正交化就像把两只手的动作“解耦”:左手只管左半边,右手只管右半边,互不牵扯,每拧一下都是真实的进步。
- 举措二:Logits 爆炸会导致 Softmax 分布极端化和训练震荡等问题。DeepSeek V4 将 Q、K 在计算注意力之前就先进行 RMSNorm 计算,即在 softmax 计算之前就规避掉 $QK^T$ 矩阵中少数值过大的问题,也就从根本上解决了 Logits 爆炸的问题,从而提升训练的稳定性。——这就好比你在主持一个 10 人会议,规则是“每人发言加权平均后形成决策”。正常情况下大家音量相近,决策就能综合各方意见。但现在有一个人嗓子特别大,声音是其他 9 个人的 100 倍。最后加权平均的结果几乎完全由他一个人决定——其他 9 个人的意见完全被淹没。RMSNorm 就像给每人发了一个定制的麦克风增益器:无论你原本音量大还是小,话筒都会自动调到合适的音量,确保每个人都能被公平地听见。
Infra层面的优化机制
前面聊到的三项核心优化机制瞄准的是“让模型变好”的问题,然而优雅的架构更需要精细化的 Infra 方案来“让硬件吃饱”。接下来,我们就来看 DeepSeek V4 针对 Infra 层优化的答案。
专家网络模块中更细粒度的计算通信重叠
MoE 架构最初提出时,是按照“算完再通信,通信完继续算”的流程进行的。这样带来的问题是,通信时算力模块闲置,计算时通信模块闲置,硬件整体的资源利用率低。于是就有了计算通信重叠的优化思路,即在矩阵运算的同时,并行执行分发/回收的通信操作,这样可以适当提升硬件整体的利用率。但按阶段进行调度,很难让矩阵运算的阶段和通信阶段消耗的时间严格对齐,也就是说依然存在“气泡”现象。DeepSeek V4 提出了更加细粒度的调度方案,尽可能减少,甚至完全消除气泡,从而大幅提升硬件的利用率。三种方案的执行时序对比详见下图:
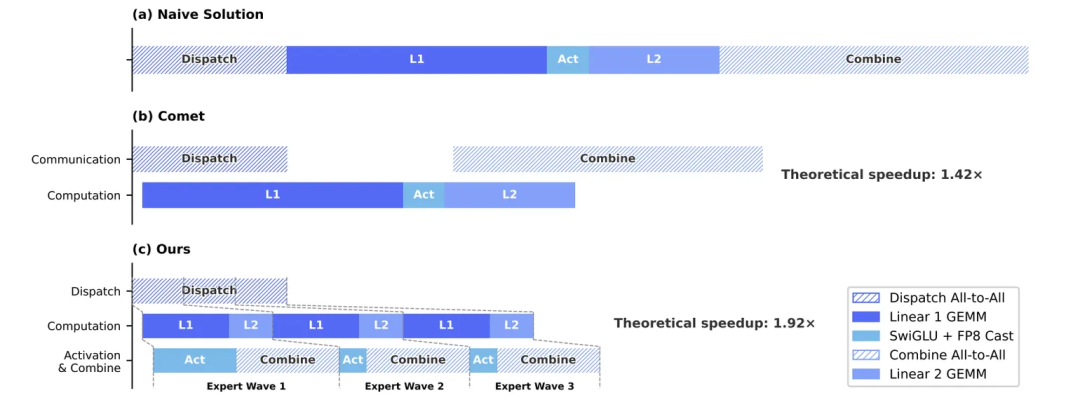
这就好比我们同时使用洗衣机和烘干机时,由于洗衣和烘干的耗时往往不一致,如果中间不能打断,总会出现一台机器先完成、空转等另一台的情况。但如果两台机器都可以随时中断、交接——洗衣机刚洗完就把湿衣服送进烘干机、自己立刻开始洗下一批——整条流水线就能以最高效率运转。
另外,DeepSeek 也洞察到,一款硬件计算能力 C 和通信带宽 B 的比值(C/B)是一个定值;而 MoE 模块计算时,一旦模型架构与量化方案确定,所需的计算量 $V_{comp}$ 和通信数据量 $V_{comm}$ 的比值($V_{comp}/V_{comm}$)也将是一个定值。由于 MoE 模块是算力密集型的,所以当 $V_{comp}/V_{comm} > C/B$ 时,理论上通信可以完全“隐藏”进计算,即实现气泡的完全消除。此外,部署 MoE 模块的硬件选型,也可以不必一味追求高带宽,够用即可。
使用TileLang来实现算子的高效开发
TileLang 是一种面向 tile 的高级抽象语言,其核心思想是将数据流逻辑与调度策略解耦:前者用高层抽象语言简洁表达,后者通过少量标注交由编译器优化,以达到用更简洁的代码表达复杂计算,并获得最优性能的效果。DeepSeek V4 中包括了 mHC、CSA、HCA 等多种优化机制,如果纯靠 CUDA 编写算子将会非常复杂。通过 TileLang 编写,编译出的 kernel 性能可以对齐甚至超过手工编写的 CUTLASS/cuBLAS 水平。另外,TileLang 的可移植性很好,同一套 TileLang 代码可以针对不同后端进行编译,包括 NVIDIA,也包括国产硬件。简单来说,TileLang 就是让 DeepSeek V4 快速跑得起、跑得快、跑得远的关键支点。
批无关性 & 计算确定性
批无关性(Batch-Invariant):
批无关是指在训练或推理过程中,无论 batch 如何切分,某个 token 落在哪个 batch,它的输出结果都在 bit 级别上完全一致。形象地比喻为:我和朋友一起去买奶茶,我喜欢精准 50% 糖的奶茶。无论店员做奶茶的顺序如何、或者我们一起下单的朋友有几个人,我的那杯都不能是 51% 糖或 49% 糖,必须是 50% 糖。——店员必须用同一套严格的固定工序做每一杯,不能因为订单多就开“批量快捷模式”走捷径,也不能因为做到后面累了就敷衍了事。
具体的措施是,在注意力计算过程中,将“单条序列全程在单个 SM 内完成注意力计算,保证满载计算波的高吞吐”和“采用多 SM 协同处理单序列”两种 kernel 的计算顺序完全对齐,使得同一条 query 无论走哪个 kernel 都能得到 bit 级别完全一致的结果,从而消除 batch 大小变化对输出的影响。另外,矩阵乘法这一侧的挑战更隐蔽,浮点数加法不满足结合律,而 GEMM 内部本质上是大量浮点数的累加,累加顺序一变,结果就会漂移。通用的 GEMM 库 cuBLAS 是动态调整乘法计算顺序和切分模式来追求性能最优的,同一个 GEMM 在不同 batch 下可能走不同路径,天然就是批相关的,所以需要使用 DeepSeek 开源的 DeepGEMM 矩阵乘法库来实现矩阵乘法的批无关。
计算确定性(Determinism):
浮点加法不满足结合律,因此在大规模浮点累加过程中(注意力、矩阵乘法、梯度汇聚等),同一个数学上等价的计算可能因为执行顺序不同而产出不同的结果。我们还用买奶茶的例子,还是这杯“50% 糖”的奶茶——按“糖浆 → 牛奶 → 冰块”的顺序加料,和按“冰块 → 糖浆 → 牛奶”的顺序加料,每样用料分量虽然完全一样,但尝起来的糖度、奶感、冰感总会微妙地不同。浮点加法就是这样一位挑剔的味觉——数学上明明等价的算式,换个加法顺序,最后一口总能尝出不同的味道。
为了保证浮点累加固定顺序,简单来说,注意力反向传播、MoE 反向传播、mHC 的 split-k 归约——反向传播里这三个典型的“多对一”累加场景——V4 都强制要求累加顺序固定。“执行顺序”依然允许乱——只要最后把加法的括号结构钉死,整条训练就是 bit 级确定的。
FP4量化感知训练
核心思想是:与其让模型训练完再被粗暴量化、掉一波精度,不如在训练过程中就让模型“预演”低精度计算,提前适应量化带来的数值扰动。V4 在后训练(post-training)阶段引入量化感知训练,目的是在部署时吃到推理加速 + 显存节省两重红利——但前提是:模型得先在训练中“习惯”低精度的世界。
但是量化也不是一刀切,而是分模块进行:
- MoE 专家权重量化为 FP4——MoE 的参数量远大于 ATTN 模块,显存占用的大头在这里,压缩收益也最大。
- CSA 闪电索引中的 q、K 也采用 FP4 量化,原因是这些是长上下文中的热点路径。
- 但闪电索引的打分仅量化到 BF16——这个分数是用于 top-k 排序的,排序对数值精度非常敏感。
这就好比你在搬家打包的时候,被子又大又重,直接抽真空压缩到极致,但衣服只能叠起来放,否则会压坏,不能正常穿了。
训练框架的优化
- 新优化器与旧分布式训练打架:V4 换上了新的优化器(Muon),它需要一次性拿到完整的参数梯度才能更新参数,但传统分布式训练会把参数切成小块分到各机器上,两者天然冲突——V4 重新设计了一套参数分组和分配方式,让 Muon 和分布式训练能共存,并把机器间传输梯度的通信量砍了一半。
- 新残差结构拖慢流水线:V4 用的新残差结构(mHC)虽然效果更好,但会占用更多显存,机器之间也需要传输更多数据——V4 通过定制计算内核 + 选择性地“算过的不存、回头再算一遍” + 调整流水线节奏三招组合,把新残差带来的额外耗时压到只有 6.7%。
- 长文本训练时压缩段跨机器:训练超长文本时,一条文本会被切开分给不同机器处理,而 V4 的“KV 压缩”机制需要连续的一小段 token 一起压缩,这段有时正好跨在两台机器的边界上——V4 设计了一套两步走的机器间通信,让相邻机器先交换一下边界数据,再把压缩结果收拢重排,完美解决了跨机器压缩的问题。
- 显存和算力的精细权衡:训练大模型时,经常要在“多存一点中间结果省算力”和“少存一点省显存、用到了再算一次”之间做取舍——传统做法粒度太粗(要么整层都存、要么整层都重算),V4 做了一套精细到单个 tensor 的自动化机制,开发者只需要写一次前向逻辑并标注几个关键 tensor,框架就能自动帮你算出“重算哪些最省”。
推理框架的优化
KV Cache架构:由于 V4 引入了包含 CSA、HCA 的混合注意力机制——它们的 KV 结构、大小、更新规则各不相同,导致每层的 KV Cache 长得都不一样。而传统的 PagedAttention 假设所有层 KV 形状一致,在 V4 面前直接失效,所以需要重新专门设计 KV Cache 架构。这个架构包括滑动窗口注意力的缓存和 CSA/HCA 混合注意力的 KV Cache:
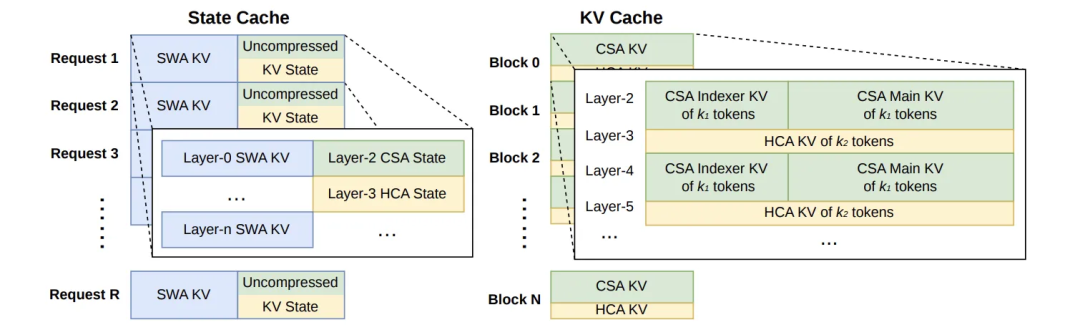
KV Cache持久化:想象一个公司的知识库,所有用户的 system prompt、知识库内的文档,其实内容都是不经常变化的,但在每次请求时都要计算一次就会非常浪费资源。通用的做法是把算过的 KV 持久化到磁盘,下次命中直接读取,跳过重算。而 V4 的具体创新点在于:面对自己的异构 KV(CSA/HCA 压缩 + SWA 未压缩 + 尾部 state),拆开分类存储,特别是为 SWA 提出了三档取舍方案,让这套机制在 V4 的混合架构下依然能用。
写在最后
写到这里,该停笔了。V4 没有发明新的轮子。mHC、CSA/HCA、Muon、TileLang、QAT——每一块拆开看原理,都似曾相识,但 V4 把它们逐一重新雕琢了一次,让它们都重新升华了。更重要的是,V4 把它们组织在一起,完成了一次从架构到工程的系统级闭环。V4 的动人之处,不只在于每一块的精进,更在于系统级的优雅。
当然,这份技术报告我还有很多细节没有理解透彻,但可以肯定的是,它让开源又向前迈出了决定性的一步。
参考
 发表于 2026-5-1 18:50:03
|
查看: 117|
回复: 0
发表于 2026-5-1 18:50:03
|
查看: 117|
回复: 0
