当 AI 开始加速 AI,模型公司的迭代周期正在被进一步压缩,模型公司开始进入“月更时代”。
过去的两周是全球模型的高密度发布期:Anthropic 发布 Opus 4.7,OpenAI 发布 Image 2.0 和 GPT-5.5,腾讯发布 Hy3 preview,沉寂了相当长一段时间的 DeepSeek 也终于带着 V4 回归。在 DeepSeek V4 发布后,我们组织了一场 Best Ideas 讨论会,和一线 AI researcher、开发者、创业者和投资人一起,复盘最近几款模型的真实使用体验,讨论 Opus 4.7、GPT-5.5、DeepSeek V4 背后的架构变化、能力边界和产业影响。这篇文章是对这场讨论的纪要整理。就像 云栈社区 上大家常聊的那样,技术迭代越快,来自一线的体感才越有价值。
What's Next:接下来,我们会继续围绕真实的 AI 产品构建来组织讨论、持续观察这一轮智能竞赛。
Insight 01
新模型一线实测
Opus 4.7
1、 Opus 4.7 最明显的两个优点:
• Long horizon task 的表现明显提升:给它一个比较难的任务可以推进得更长,而且不是靠无节制地烧 token,而是在高效的 token 配比下把任务推到极致。
• 多模态理解能力有明显进步,已经追平了目前主流的多模态模型,有可能是为了解锁设计类垂直场景。
2、 但 Opus 4.7 的缺点也很明显:文字表达能力退步了,不像 Opus 4.6 那样擅长抓重点、说话不绕弯。
3、 这个变化很可能是一次阶段性的 trade-off:Anthropic 做模型时习惯从 pre-training 层面做优化,每次配比变化都会对体验产生影响,加上 强化学习 的持续迭代和 tokenizer 的更换,可能带来了一些副作用。
4、 这种 trade-off 后可能也存在战略考量:如果不在 Opus 和 Sonnet 之间做明确的差异化,用户所有任务都用 Opus 跑,Anthropic 的算力会更加吃不消。现在的结果是用户自然形成了分工:做 coding 用 Opus 4.7,做文字表达切换到 Sonnet,这对 Anthropic 的资源分配反而是好事。
Dario 曾经解释过 Haiku / Sonnet / Opus 这三档分类背后的逻辑,它不是简单的“低/中/高”三档智能,而是同一条“能力-速度-成本”曲线上的三种产品定位,本质上是能力、速度、成本的不同取舍。因此,具体某个模型的升级并不是所有能力同步 +1。
GPT-5.5
5、 GPT-5.5 提升比较明显,它不是像之前 5.3、5.4 那样纯靠 post-training 压榨 Codex 方向的能力,而是从 pre-training 层面做了实质性的改进。验证了 OpenAI 是可以做好 agentic 任务的。
6、 GPT-5.5 最明显的体感是速度变快。对 coding agent 来说,速度本身就是能力的一部分,因为很多代码任务不是一次性写对,而是在环境里不断试错、运行、修改。当模型足够快,整个试错链路也会变快,实际效率会被放大,不过到了美国上班时间后会明显变慢。
7、 总体来说,GPT-5.5 更像是 OpenAI 用来狙击 Opus 4.7 / Opus 4.6 的模型,而不是最终大招,也不是传言中的 Spud 模型。
8、 今天的 SOTA 还是 Opus 4.7,核心领先优势在于 brainstorm 和 planning 能力。很多开发者在做 plan mode 和 brainstorm 的时候仍然选择用 Opus,因为它对用户意图的理解、在方向探索上的深度和广度,仍然更胜一筹。
DeepSeek V4
9、 DeepSeek V4 在 agentic & coding 能力上是开源模型里明确的 SOTA,但和闭源模型的 SOTA 之间仍然有一定差距,这个差距大约在六个月以内。不过考虑到 DeepSeek 此前一直没有非常重视 agentic & coding,能临时追到这个程度已经很厉害了。
10、 DeepSeek V4 最大的卖点是极致的性价比。它在模型计算 FLOPs 优化、KV cache 压缩等方面做了非常极致的性能优化,如果后面再叠加国产算力,价格还有可能继续被打下来。这也是 DeepSeek 一直以来最有价值的地方:每当市场在某个阶段出现供需不平衡,它总能给出一个极致优化的局部最优解。
11、 DeepSeek 在过去很长一段时间里把 bet 下在了 long context 上,认为这是下一代范式的基础能力。但 long context 在智能提升的体感上不像 coding & agentic 那么明显和直观,如果 V4 能更早发布(比如去年底),借助 OpenClaw 带起来的这波 agentic 热潮,效果可能会更好。
12、 DeepSeek 使用华为芯片这件事,大多数人关注的是“国产替代”本身,但更值得关注的视角是:DeepSeek 又比别人早了半步。虽然适配华为芯片确实耽误了相当长的时间,但如果它最早把华为 950 跑通了,接下来就可能最早吃到华为产能的红利。
13、 DeepSeek 的历史意义不仅在于单个模型的性能,更在于它已经演化成中国为数不多能够独立探索新模型架构的厂商。每次 DeepSeek 的新架构出来,即使没有在能力上达到 SOTA,也会带动智谱、Kimi 等国内厂商跟进架构升级,连带降低整个行业的 inference 和训练成本。这次 DeepSeek 跑通了华为 950 集群的集成,只要其他厂商用类似架构,上 950 的门槛也会显著降低。
14、 Google 异常的安静可能不是因为落后了,而是因为觉得自己有把握。Google 的算力资源实在太充裕了,它的 de-risk 集群都比 OpenAI 和 Anthropic 最大的训练集群要大。从和 Google 内部团队的交流来看,他们似乎对自家模型比较有信心,并不急于在现在回应竞争对手的每一次发布。
Insight 02
模型吃掉一切脚手架
15、 模型把“脚手架”训进去的速度非常惊人。一个典型的开发体验是,在 GPT-5.4 发布后,在同样的需求下,它和前一天的 GPT-5.3 已经呈现出完全不同的行为模式:有朋友提出了一个 iOS App 的开发需求,Codex 没有停留在写代码或给步骤,而是主动识别到手机和电脑处在同一网络环境里,进一步判断可以直接把 App 部署到手机上,并挂上调试进程。随后,它会让用户直接打开 App 体验,自己在后台观察日志、记录用户操作行为、定位 bug,再修改代码、重新部署。
16、 过去这套闭环通常需要很多外部脚手架来帮模型组织,但现在模型已经自己成为了一个能跑完整开发流程的软件工程师。
17、 从实际使用体验来看,模型升级对使用不同 harness 框架的用户带来的影响也非常不同:
• Opus 4.7 更新后,没有搭建自己脚手架的用户会感受到 AI 能力有飞跃,因为模型本身已经把很多 long running task 的能力训进去了,可以自发地跑很长时间。
• 但基于 Opus 4.6 精心定制过脚手架的用户,反而会觉得效果变差。具体表现为,token 消耗量明显增大、频繁触发 context 压缩、会更积极地要求开新 session 而不是在当前 session 里复用,甚至在设置了 YOLO 模式后仍然会无视指令。
这背后的原因大概是:Opus 4.7 在 RL 训练中是以 team coordination 的模式来做 long horizon task 的,所以在使用过程中,最适配的方式也是把主 agent 设计成 team coordinator,用 agent-to-agent 的方式去跑,而不是直接让主 agent 去自主完成长程任务。
18、 也有 AI 开发者提到,从 GPT-5.2 开始,OpenAI 和 Anthropic 在模型的开发能力上已经没有太大差别,差距更多来自 Codex 和 Claude Code 之间 harness 的差距,而这个 harness 的差距在 Q1 也已经逐渐追平。他在春节后选择全面切到 Codex,因为整体体验更稳定,在速度、开发能力、供应量、稳定性,以及账号风险等方面都更好。
19、 上面这些 case 都暴露出一个趋势:模型和 harness 的耦合关系在变得越来越紧。新模型不是一个抽象的、更强的“通用大脑”,而是带着某种非常具体的使用范式一起发布。它的训练方式、system prompt、RL 数据分布,都会暗含“应该怎么使用它”。如果外部开发者没有按这个具体方法使用,效果可能会大打折扣。
20、 这个趋势对于 harness 领域的创业公司来说是一个危险的信号:因为如果你的 harness 是根据上一代模型的能力和缺陷设计出来的,一旦下一代模型把这些能力训进去了,你的 harness 会瞬间变成 technical debt。除非 harness 本身更像一个可以随模型自动生成、自动编译、自动适配的系统,否则每次模型升级都会带来一次重构。
21、 模型吞噬 harness 的趋势同样对 Skills 领域带来影响。当下的讨论中提到的 Skills AppStore、Marketplace 本质上还是把 Skills 默认为插件、模板的存在,但 Skills 的商业化更像一个短期窗口,而不是一个长期平台型机会。
22、 今天的 Skills 可以分为 2 类:
• 类型 1:Capability uplift(能力提升),也就是让模型学会原本不会的事情,它的保鲜期大约只有三个月,因为有价值的部分一定会成为模型的养料,会在下一个版本被训进模型;
• 类型 2:Encoded preference(偏好编码),也就是把个人偏好喂给模型,补充的是具体用户的个性化偏好,那它也会因为高度个性化而分发价值有限。
23、 Coding/Agentic 场景下是否已经建立起数据飞轮?
• 掌握用户数据一定是重要的,但用户数据并不能直接拿来训练模型,因为这些原始数据的清洗成本极高;
• 数据飞轮更多体现在产品层面:当一个产品拥有全世界最多的程序员在你的平台上编程,你就能从统计意义上理解这几百万核心开发者的 preference 到底是什么,比如他们的编程习惯是怎样的、什么环节会介入。这种理解会持续反哺产品迭代,让产品越来越贴合真实用户的工作流。
• 但这是不是一个足够深的壁垒,目前还不好说。它取决于程序员的行为模式到底有多碎片、多复杂,需要多大的样本量才能充分捕捉,以及这些数据和具体产品的 harness 环境绑定有多深等等。
Insight 03
模型越快迭代,算力瓶颈越大
24、 过去两三年大家反复讨论 Scaling Law 能不能继续,最终总是落到数据够不够的问题上,但现在往后看一到两代模型,数据不是卡点,算力才是。尤其当头部模型公司已经进入了 AI 加速 AI 研发的自循环,这意味着模型迭代速度会越来越快,算力也会越来越紧俏。
25、 最新的 Mythos 超大参数模型发布后,最大的限制就是需要极大的集群才能 serve 起来,可能需要 NVIDIA GB200/GB300 NVL72 或者 Google TPU7x / Ironwood 这种级别的硬件。
26、 国产模型要缩小和海外顶尖模型的差距,核心可能是三点:
(1) 能组织起 10 万卡以上的高性能、稳定训练集群。这不仅要考验 GPU 数量,更考验 GPU 之间的连接能力,两者都有待补齐。
(2) 自主建立起类 CUDA 的软件栈,不能永远被英伟达生态卡住。
(3) 有更好的数据生成能力,比如 synthetic data,以及像 Claude Code 一样通过更好的产品掌握用户在真实任务里执行、试错、纠错的轨迹数据,了解真实的数据分布情况。
27、 短期来看,算力是远比数据更大的挑战。中国开源模型在过去一年给了市场一种“追得很快”的感觉,但接下来有可能会阶段性地卡一下。因为国内模型现在在模型大小上和海外御三家还有不小的差距,要跳到下一个 level,可能至少需要四、五万张卡以上的集群支撑。
28、 不过在更长的时间尺度上,中国在芯片方面的追赶速度可能被低估了,只是短期内(比如 2028 年之前)压力仍然很大:
• 随着美国几家 AI 大厂开始自研芯片,客观上会增加市场上懂芯片设计的人才供给,其中一部分 know-how 可能会流回中国。
• Coding Agent 能力的提升也让手搓优化 kernel、从一个架构迁移到另一个架构的难度在下降。以前这个过程预计需要 5 到 10 年追赶,但今天在 AI 的辅助下可能会被加速。
Insight 04
Token 涨价是确定趋势
29、 Token 涨价会是一个确定性事件,中美两个市场同步进入涨价周期,尤其国内从“价格战”模式逐渐切换到“性能定价”模式:
• OpenAI 的 GPT-5.5 相较于 GPT-5.4 token 价格翻倍;
• 智谱的 GLM 5.1 相比于 GLM 4.7,也在三个月左右 token 定价翻倍;
• Kimi 的 K2.6 相较于 K2.5 token 定价大概涨了 50%。
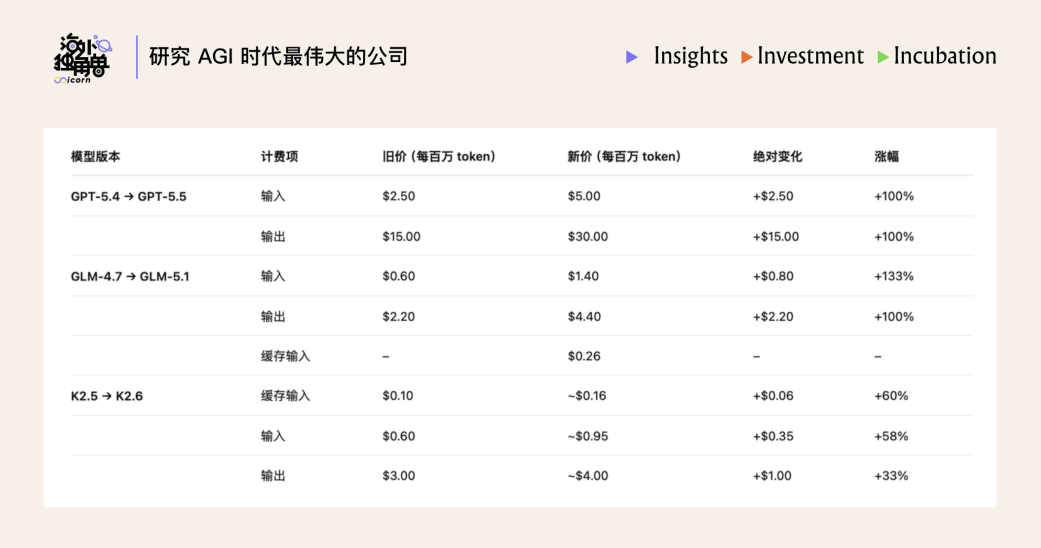
30、 涨价首先是由供需关系驱动:当前对 token(AI 智能)的需求是非线性增长,但供给只能线性扩张。未来两年 token 需求可能涨 1000 倍,数据中心也就扩几倍,供需缺口越来越大。
• 成本端:今年算力成本至少上涨了 20%:
(1) GPU 极度稀缺,包括 Anthropic 的几乎每家 AI 厂商都要面临缺卡难题;
(2) 集群的运维成本也在涨;
(3) 模型变大、上下文变长,尤其是百万上下文对推理成本的影响非常显著,生成单个 token 所需的计算量和显存需求都大幅增加;
• 需求端:Opus 4.5 之后,模型智能在复杂场景和任务上的表现提升,Agentic 和 coding 场景开始创造真实 ROI,以前不可想象的用例正在批量出现,且每个场景都极度消耗 token。只要企业发现模型能带来正向经济价值,就会愿意为更强模型支付更高 token 价格。
随着模型能力提升,更多新的高 token 消耗用例还在不断被解锁。例如 SemiAnalysis 最新播客访谈中提到,他们利用 AI 可以通过一张照片让模型反向拆解芯片里用了什么金属、对应什么设计,再进一步推理出一个投资判断。
31、 DeepSeek 最早把国产开源模型的 API 定价打到了极低水平,这对国内模型厂商、推理厂商来说不太健康。因为中国模型并不天然拥有低一个数量级的成本优势,后面可能会有一次“价格修复”。
32、 考虑到 DeepSeek 过去并没有大规模对外提供商业化 API,所以过去的定价并不具备参考性。但接下来它自己也必须考虑商业可持续性。
33、 Anthropic 和 OpenAI 可能明年一家的 ARR 就可以到达 2000-3000 亿美金,假设模型训练成本 300 亿美金,推理端毛利率 60% (Anthropic 目前的 API 毛利率据说已经有 70%+),那么头部模型一年的净利润可以达到近千亿美金,这已经超过 Meta 的利润水平。如果未来训练算力的投入占比持续下降,头部模型的利润率会非常可观。
但这么高的利润率能不能守得住,才是真正的问题。回顾历史,任何行业出现这种 margin 都会吸引激烈的竞争。两年前 Google DeepMind 说过一句话:"We don't have a defending moat, neither does OpenAI",这句话到今天似乎仍然成立。
34、 关于需求侧的渗透率,目前 agent 类产品的渗透率可能只有 5% 左右,仍然很低。一个粗略估计是,Codex 周活用户约 400w,Claude Code 可能约 1000w;加上其他 agent 产品,总用户可能在 2000-3000w。相对全球 4 亿左右的高级知识工作者,这个渗透率大概也就是 5%,远远没有到天花板。
35、 AI 时代的商业逻辑和互联网时代有一个根本不同:互联网时代单客的客单价是相对固定的,但 AI 时代一个人的客单价几乎没有上限,一个深度用户可以每天消耗上亿 token。Claude Code 现在头部 10% 用户大约贡献了 80%-90% 的营收,power law 非常明显,这意味着渗透率和使用深度是两个独立的增长维度,后者相比前者,可能反而有更大的释放空间。
Insight 05
用好 AI 的 bottleneck 在于人本身
36、 今年 Q1,模型能力已经跨越了拐点,接下来的核心竞争战场不再是模型智能本身,而是上下文和外部能力的对接。对企业来说是整个经营体系在数字世界里的完整映射,对个人用户来说就是自己的上下文管理。
37、 有一位二级朋友分享了自己实际用 AI 辅助投研的完整流程,她从大约一万多家标的出发,搭建了一个多维度、多轮筛选的 agent 工作流。
• 第一层是用结构化数据筛选公司的财务健康度:先从 Wind、Bloomberg 等数据源里拉取数据,整体大概有 300 多个维度,把 1 万多家公司按财务质量、估值、成长性、波动、盈利能力、资本结构先筛一遍,剔除基本面不健康的标的。
• 第二层是利用非结构化数据做趋势判断:比如可以通过 YouTube API 实时抓取行业关键人物的公开发言,黄仁勋、Dario 等说了什么,同时整合 Stratechery、SemiAnalysis 等深度分析源的内容,形成一些对行业、公司的认知判断。
• 第三层是用聪明钱做验证和估值分类:参考特定机构、特定投资人的持仓或方向,结合估值模型做最终筛选。
整个过程花了 2-3 天,人全程参与,从 1 万多家公司,筛到 1000 家、100 家,最后锁定个位数标的,目前选股胜率是 100%。
38、 在投研场景里,不需要 SOTA 模型,真正决定效果的,往往是数据域:
• 数据 solid 程度如何 (这里可以设计多种维度互相校验);
• 数据实时性如何 (比如是否能通过 Yahoo、Youtube 等各类数据源的 API 实时捕捉最新的趋势变化),
这两点最大程度上决定了这个 agent 的上限。换句话说,模型只是发动机,数据域和 workflow 才是投研 agent 的护城河。
39、 人的判断没有消失,但人的杠杆被放大了很多。AI 在投研里最强的价值是“宽搜索”。AI 可以在两三天内扫完 1 万家公司的所有数据维度,但人类最强的价值依然是“深度思考”。人类的直觉、对异常信号的感知、对单点问题的判断,仍然非常关键。
40、 中国企业的数字化基础普遍很差,包括大互联网公司也是如此,即便数字化做得不错的企业,组织权限的割裂也会严重限制 AI 的效果。一个很现实的例子是,做系统对接时,最高效的方式是把两个系统的源码都拉到一起,让 AI 通读两边逻辑。但现在,不同系统的代码权限分属不同的员工,根本不允许拉通。所以,用好 AI 的 bottleneck 越来越不是模型本身,而是人和组织。谁能把上下文和权限打通得更彻底,谁的组织转速就会更快。
 发表于 2026-4-30 19:43:41
|
查看: 124|
回复: 0
发表于 2026-4-30 19:43:41
|
查看: 124|
回复: 0
