大家好,我是小Y。上次OPPO面试复盘火了之后,我又去面了小红书AI应用开发。本以为有了经验能稳一点,结果面试官直接把难度拉满——不考套路,专考底层认知。
全程1小时,项目深挖+概念本质+代码实战,出来手都是抖的。今天把题目和我的反思完整写下来,希望能帮你们少走弯路。

一、项目开讲:Multi-Agent保险文档生成
面试官第一句:“讲一个你做的最好的项目。”
我选了基于Multi-Agent的保险公司文档生成系统。这里我用了4个Agent协作:
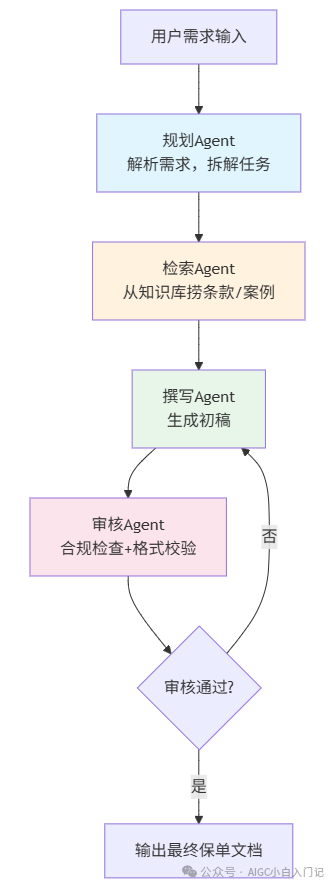
分工协作细节:
- 规划Agent:LLM做意图识别和任务拆解,输出结构化任务列表
- 检索Agent:向量检索+关键词检索,召回保险条款和相似案例
- 撰写Agent:接收检索结果,按照模板生成Markdown文档,占位符用
{{}}标记
- 审核Agent:用规则引擎+小模型校验,比如保额不能为负、日期逻辑自洽
面试官追问:“如果是小红书场景,你怎么搭建?”
我答:小红书的文档生成偏向种草文案,需要加入用户画像Agent(分析粉丝偏好)和热点Agent(抓取当前流行词),审核Agent要换成风控敏感词过滤。
难点后面问,先接着往下看。
二、项目有什么难点?
我讲了两个真实翻车点:
难点1:Agent之间信息丢失
撰写Agent有时会忽略检索Agent返回的关键条款。解决方案:结构化通信——不是传纯文本,而是传JSON,固定字段{“clause_id”: “”, “content”: “”, “importance”: “high”}。审核Agent再校验是否所有high重要性的条款都被引用。
难点2:长文档生成的不一致性
比如前面写“年缴保费5000元”,后面变成“6000元”。解决:引入全局状态变量,用字典存储已确定的实体,每个Agent读写同一个共享内存。
面试官点头,然后突然转向底层理论——
三、Embedding的本质是什么?维度里的每个参数有什么含义?
这题我愣了一下,平时都用现成的Embedding模型,没想这么深。
我的回答(面试官后来给了补充):
本质:Embedding是把离散的符号(文字、ID)映射到连续向量空间,使得语义相近的物体在空间里距离近。它不是一个查表,而是一个可学习的压缩表示。
维度里的每个参数有具体含义吗?
——没有独立可解释的含义。单个维度不代表“性别”或“颜色”。Embedding是一个分布式表示,语义是由多个维度的组合模式共同决定的。比如“国王”的向量减去“男人”加上“女人”会接近“女王”,这不是单一维度的功劳,而是方向上的线性关系。
面试官补充了一个很妙的比喻:
就像RGB三个通道分别看都是黑白噪点,合在一起才是彩色图像。Embedding的每个维度单独看没有意义,组合起来才有。
他还问了:“降维到2维可视化,为什么能用PCA?”
答:PCA找的是方差最大的方向,而语义的差异往往就体现在方差大的方向上。
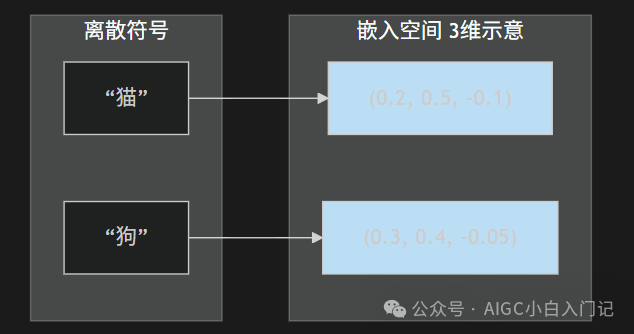
单个维度的值没意义,但向量间的余弦距离代表了语义相似度。如果你想深入了解Embedding在各类人工智能模型中的应用与优化,可以查阅更多资料。
四、不做训练,怎么让Agent知道调用工具?格式怎么定?
面试官:“假设没有微调,模型是base版本,你怎么教会它调用工具?”
核心思路:上下文学习 + 强制格式约束。
-
给示例(Few-shot):在system prompt里放2-3个工具调用的对话样例。比如:
用户:帮我查一下明天天气
助手:我需要调用工具 get_weather(city, date)
模型看到模式后,就会模仿。
-
用JSON Schema约束输出:要求模型输出必须符合特定JSON结构。
输出格式:{"tool": "tool_name", "params": {"key": "value"}}
-
配合解析器:拿到输出后,正则或JSON解析,如果格式不对就重试或回退。
-
不用微调的原因:微调成本高,且底座模型如果足够强,Few-shot就能学会。小红书场景下工具数量不多(10个以内),完全可行。
面试官追问:“如果模型总是不按格式输出怎么办?”
答:可以在解析层做容错,比如用模糊匹配找关键词;或者用更小的模型(比如CodeLlama-7B)专门做格式约束微调,再配合base模型做路由。
五、多Agent协作,怎么做上下文管理?怎么共享?
这是系统设计题。我画了分层架构:
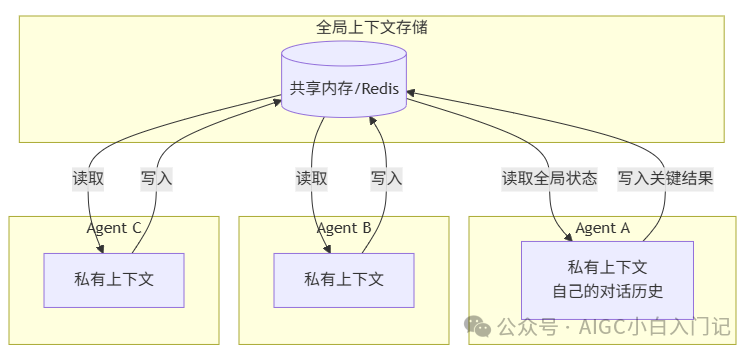
答案要点:
- 私有上下文:每个Agent自己的对话历史,用于维持自身推理的连贯性
- 全局上下文:共享的键值存储,存放“已确定的事实”“待办事项”“关键实体”
- 共享方式:建议用Redis或内存数据库,通过读写锁避免冲突。每次Agent完成一步操作,把重要输出push到全局空间,下一个Agent启动时拉取。
难点:如何避免全局上下文爆炸?
设置作用域和过期时间。比如“当前任务”作用域只在一次文档生成周期内有效;“用户偏好”可以持久化。每个写入字段带TTL。
面试官:“如果两个Agent同时写同一个key?”
答:使用最后写入获胜策略,或者设计成只能追加的日志结构,下游Agent自己合并。保险场景我用了追加方式,因为合规需要保留所有修改痕迹。这类系统设计的思想,在后端 & 架构领域有很多成熟的模式可以参考。
六、Skills了解吗?如何管理各个Skills?
小红书内部应该很重视Skills(类似OpenAI的Plugins或Function Calling的概念)。
Skills本质:将外部能力封装成标准接口,Agent可以通过名称和参数调用。Skill包含:名称、描述、输入JSON Schema、输出格式、调用URL或本地函数。
管理方式:

我实践过三种管理策略:
- 声明式注册:写一个YAML文件,列出所有Skill及其描述,启动时加载。
- 动态发现:基于向量检索,根据用户问题召回最相关的Skill(类似RAG召回tool)。
- 权限与限流:对敏感Skill(如发帖、删帖)做鉴权,对高频Skill做限流。
面试官追问:“如果Skill描述有歧义,Agent选错了怎么办?”
答:增加反馈回路——执行后如果报错或结果不符合预期,让Agent反思是否选错了Skill,然后重试。这其实是一个小型ReAct循环。
七、手撕代码:简易计费引擎
最后20分钟,面试官甩来一道题:
实现一个计费引擎,支持三个操作(按顺序到达,但timestamp不一定单调递增):
add(user_id, amount, timestamp):增加一笔费用cancel(user_id, amount, timestamp):取消一笔费用(只能在add之后的一定时间内取消)query(user_id, timestamp):查询用户当前总费用
要求时间复杂度最低。
难点分析:
- timestamp乱序:不能假设输入按时间递增
- cancel需要在add之后一定时间内(比如1小时),乱序时如何判断时间窗口?
- 需要支持高效查询
我的思路:
class BillingEngine:
def __init__(self, cancel_window_seconds=3600):
self.records = {} # user_id -> list of (amount, timestamp, status) status: 'active' or 'cancelled'
self.balances = {} # user_id -> current_total (缓存,用于O(1)查询)
self.cancel_window = cancel_window_seconds
def add(self, user_id, amount, timestamp):
if user_id not in self.records:
self.records[user_id] = []
self.balances[user_id] = 0
# 加入记录
self.records[user_id].append((amount, timestamp, 'active'))
# 更新缓存总金额
self.balances[user_id] += amount
def cancel(self, user_id, amount, timestamp):
if user_id not in self.records:
return False
# 寻找匹配的active记录:金额相同且时间差在窗口内
# 因为timestamp乱序,需要遍历该用户的记录
for i, (amt, ts, status) in enumerate(self.records[user_id]):
if status == 'active' and amt == amount and abs(ts - timestamp) <= self.cancel_window:
# 改为cancelled
self.records[user_id][i] = (amt, ts, 'cancelled')
self.balances[user_id] -= amount
return True
return False
def query(self, user_id, timestamp):
# 注意:timestamp参数可能用于检查时间有效性(如只统计某个时间点之后的费用)
# 本题简化:直接返回缓存余额
return self.balances.get(user_id, 0)
时间复杂度:add O(1),query O(1),cancel O(k) 其中k是该用户记录条数(最坏O(n))。如果用户操作非常多,需要优化cancel。
优化方案:为每个用户维护一个按时间排序的索引(如平衡树或跳表),并且对每个金额维护一个哈希表 amount -> list of (timestamp, index)。这样cancel可以O(log n)找到待取消的记录。但面试官说先实现简单版,再讨论优化。
注意timestamp乱序对cancel的影响:如果cancel先于add到达,需要缓存pending cancel,等add到来时再匹配。我在现场没有做到这个,只说了思路。面试官表示可以接受,因为题目明确“操作按顺序到达”但timestamp乱序,意思是输入的顺序是执行顺序,但每个操作自带的时间戳可能是乱的。所以cancel到达时,对应的add可能已经出现过(在历史记录里),也可能还没出现。我上面的实现假设add先到,不完善。正确的做法:
def cancel(self, user_id, amount, timestamp):
# 先检查现有记录中是否有匹配的
# 如果没有,将cancel请求缓存起来
最终评价:面试官说核心考察点是对乱序时间戳的处理意识,以及查询O(1)的缓存设计。他认可了我的整体方向。这类手撕代码的算法题,正是面试求职环节中考察基本功的常见方式。
总结:小红书面试给我的教训
- 底层原理要刨根问底:Embedding的维度含义这种问题,平时觉得“用就行”,但面试官想看你有没有真正理解分布式表示的本质。
- Agent设计要落地:不能只说“我用了Multi-Agent”,要能画出架构图、说清通信协议、共享状态、异常处理。
- 手撕代码注重边界:计费引擎看似简单,但timestamp乱序、cancel与add顺序依赖都是坑。代码写出来只是及格,能聊出优化方案才是加分项。
- Skills是未来的趋势:大模型应用一定会走向Skill生态,了解注册、检索、调用、管理的完整链路会让你脱颖而出。
你在Agent开发中遇到过什么奇葩的上下文bug?或手撕代码时被什么边界条件坑过?留言区一起吐槽~
 发表于 2026-4-30 19:39:48
|
查看: 125|
回复: 0
发表于 2026-4-30 19:39:48
|
查看: 125|
回复: 0
