D 神又开播了?真的假的?
DeepSeek 憋了这么久的大招,最近终于开始尽情释放。上周他们刚悄咪咪地把 V4 端上来,紧接着就是两波大降价——梁神,你又来普度众生了?
今天,它忽然给我推了一条灰测通知:DeepSeek 有多模态能力了,准确来说是识图。

验过了,牌是真的。
想尝鲜的差友现在就可以打开你的 DeepSeek 瞅一眼。
如果界面里多出一个「识图模式」,恭喜你,你就是被内测到的幸运儿,可以直接白嫖真正的多模态版 V4。
DeepSeek 自家的研究员陈小康也按捺不住发了条推文:我们鲸鱼终于长眼睛了,再也不是国服盲僧。


大伙儿反应这么激动,实在是因为 DeepSeek 缺多模态这事儿已经被诟病太久了。国外三巨头 ChatGPT、Gemini、Claude 早就有了多模态能力,国内豆包、千问等模型也做得非常出色。
而你,作为被寄予厚望的国产之光,这么多年连张图都「看」不懂,只能靠 OCR 识别图片里的文字,体验这块确实拉了一大截。
现在,这块短板终于被补上了。
话不多说,直接上测试。

首先,它确实摆脱了传统 OCR,能真正「看」见图片全貌。
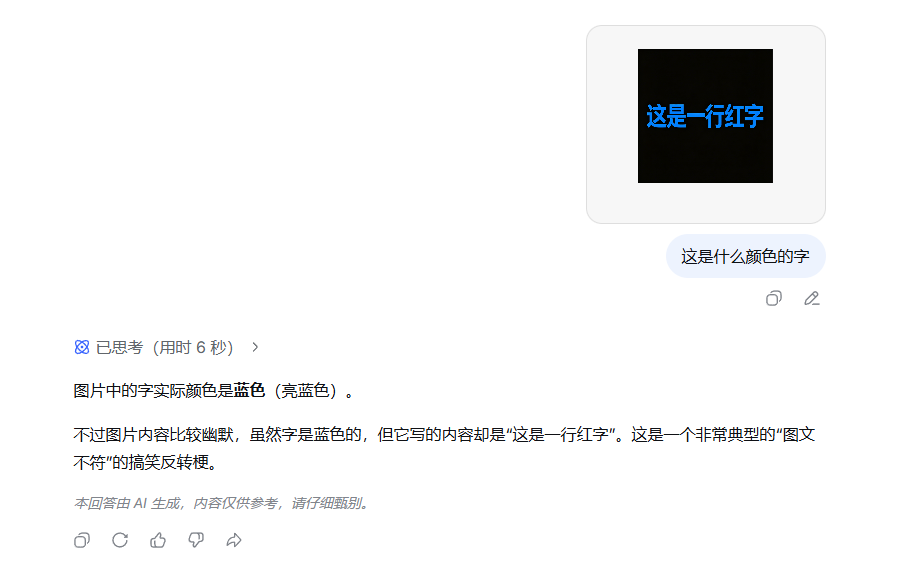
比如我们给它一张用蓝色写的「这是一行红字」。如果只用传统 OCR,它顶多识别出文字是「这是一行红字」,绝对识不出颜色。
而开启视觉模式后,它可以精准识别出这是一行蓝色的「红字」,甚至 get 到了我的幽默。
不光如此,它还有了视觉推理能力。

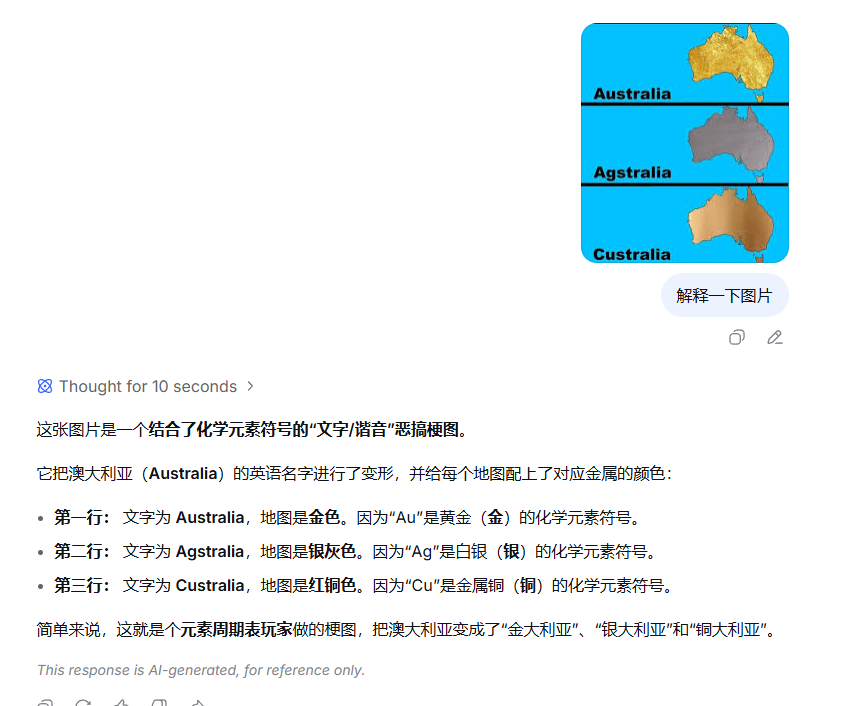
这张梗图大家都见过吧?相信以差友的智商,绝对看得懂它在玩什么。
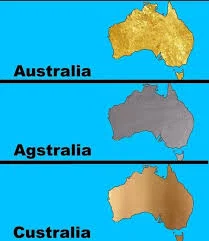
于是我发给 DeepSeek,让它帮我进行笑点解析。
它一番思考过后,不光看出来了,还顺便做了个本土化翻译——「金大利亚」「银大利亚」「铜大利亚」,有点忍俊不禁。

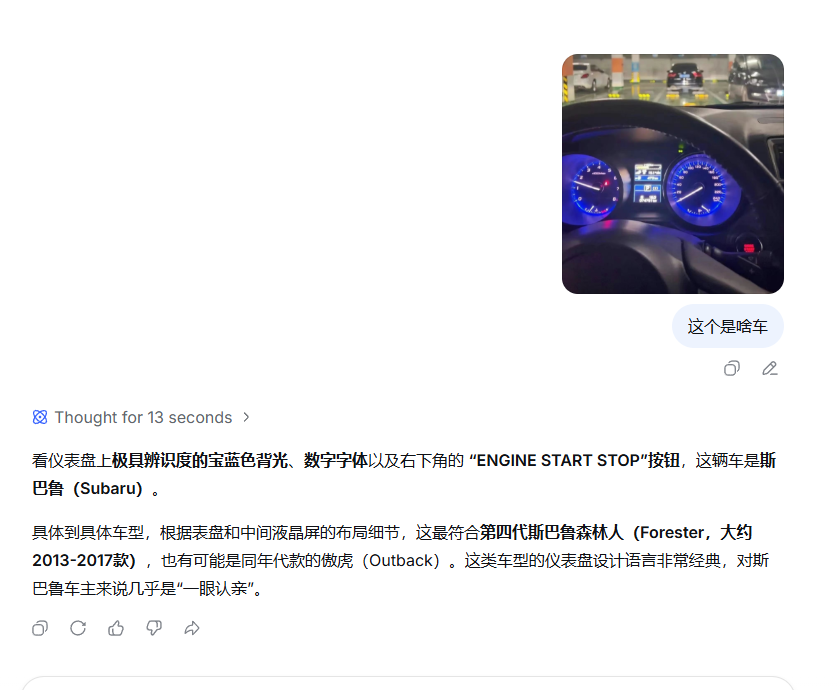
接着我又发了一张同事开车时随手拍的照片,其实挺糊的,只有些外观、光效上的信息可以分析。

结果它还是猜出来了——这辆车确实是斯巴鲁,而且思考 13 秒就给出了结论。

考虑到 D 老师是数学高手,我们又给它传了一张数学相关的梗图。说实话世超差点都没看懂,是哥们丈育了。
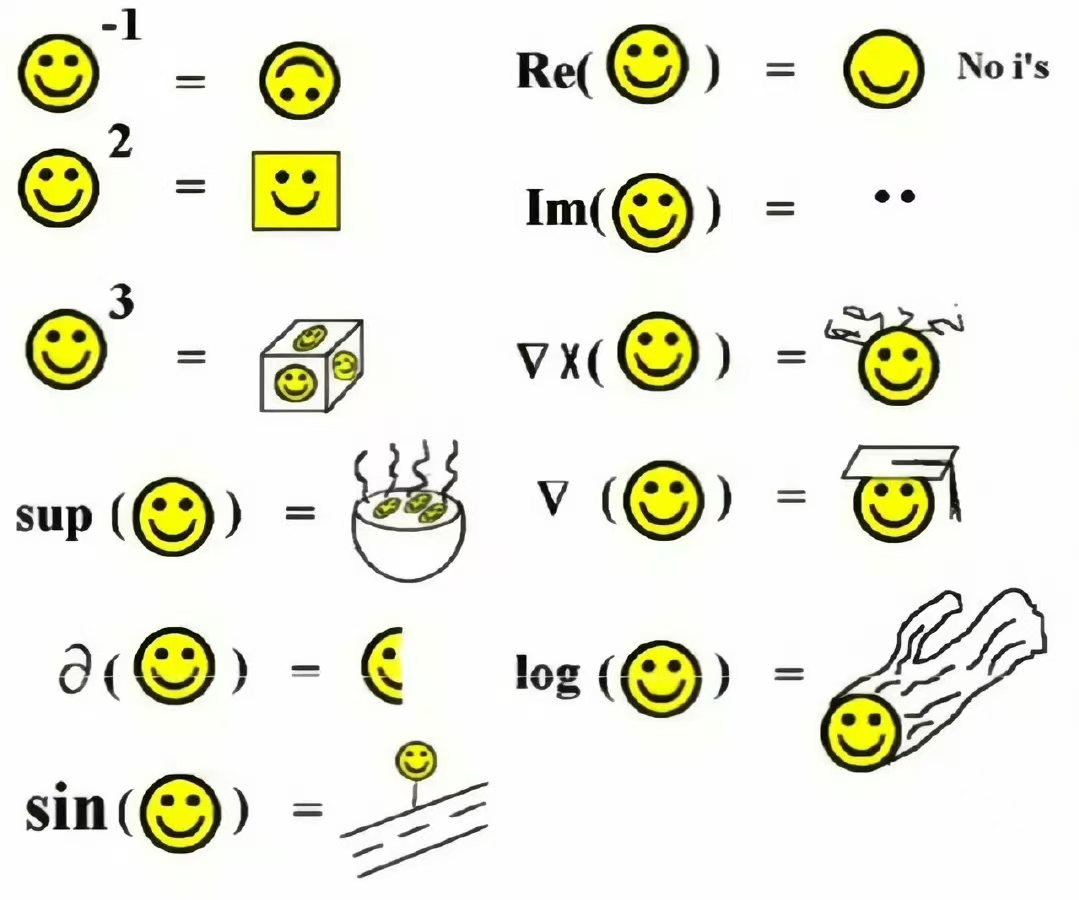
D 老师的解释依旧非常完美。
不光整明白了简单运算,它甚至看出了里面的几个谐音梗:取实部就是去掉虚数「i」,也就是去掉「眼睛」(Eye);倒三角 ∇ 是梯度(Grad),刚好跟 Graduate(毕业)沾边,所以给小脸带上了学士帽。
已经忘记数学知识的差友们可以逐字复盘一下。

顺便呢,我也测了几个生活中的问题,比如这个 3.5mm 插头该插哪里。

这个方头 USB 口又该插哪里。

虽然很简单,但它能理解我没对上焦的随手拍,也算能胜任日常任务了。

但其实,根据世超的实测,D 老师目前这个版本,也没有到天下无敌的地步。
比如咱给它丢了一张非常美丽的地球夜景。

DeepSeek 也看得蛮清楚的,说这张照片来自国际空间站。
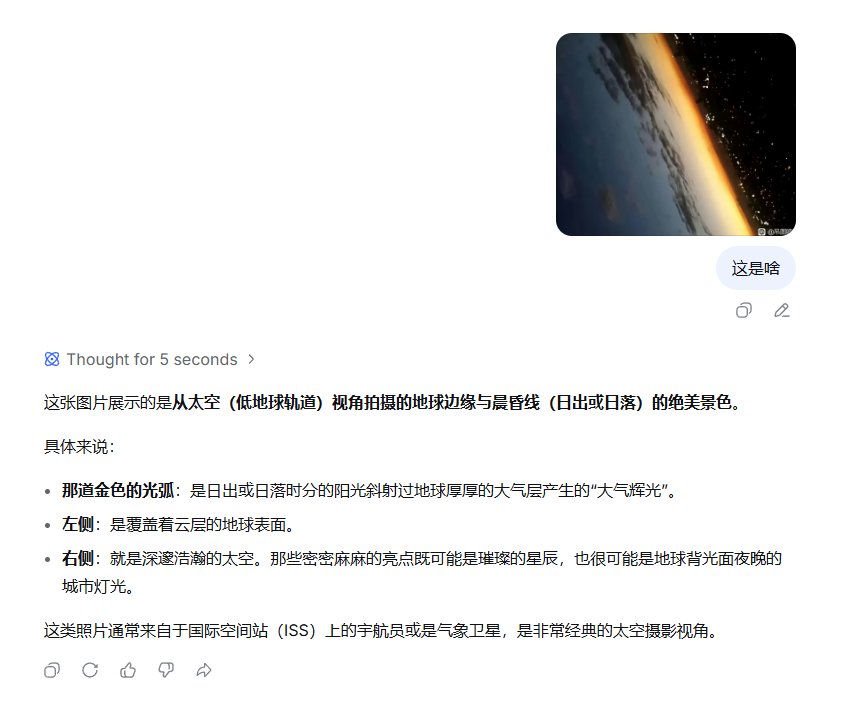
但其实,你们把照片翻过来看看,就会发现它只是一张晚霞下的城市——这是倒悬过来的视角……

然后我丢给了公认的多模态高手 Gemini……它还真看出来了。不是,降智了都这么强吗?
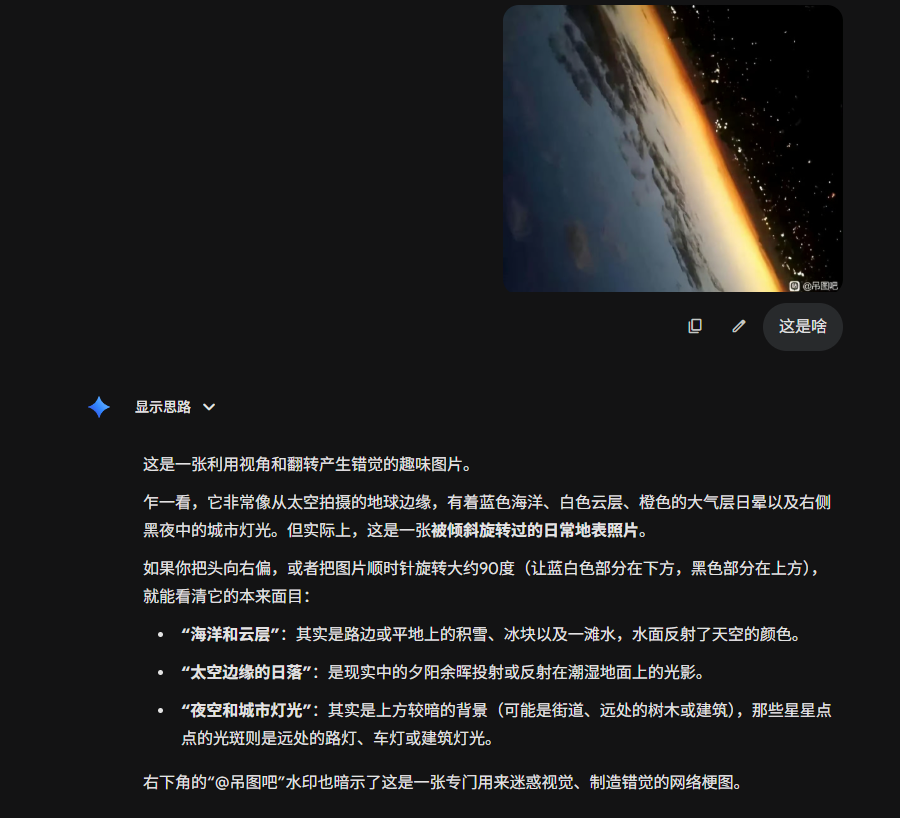
还是没能让多模态之王用尽全力吗,哈吉鲸。
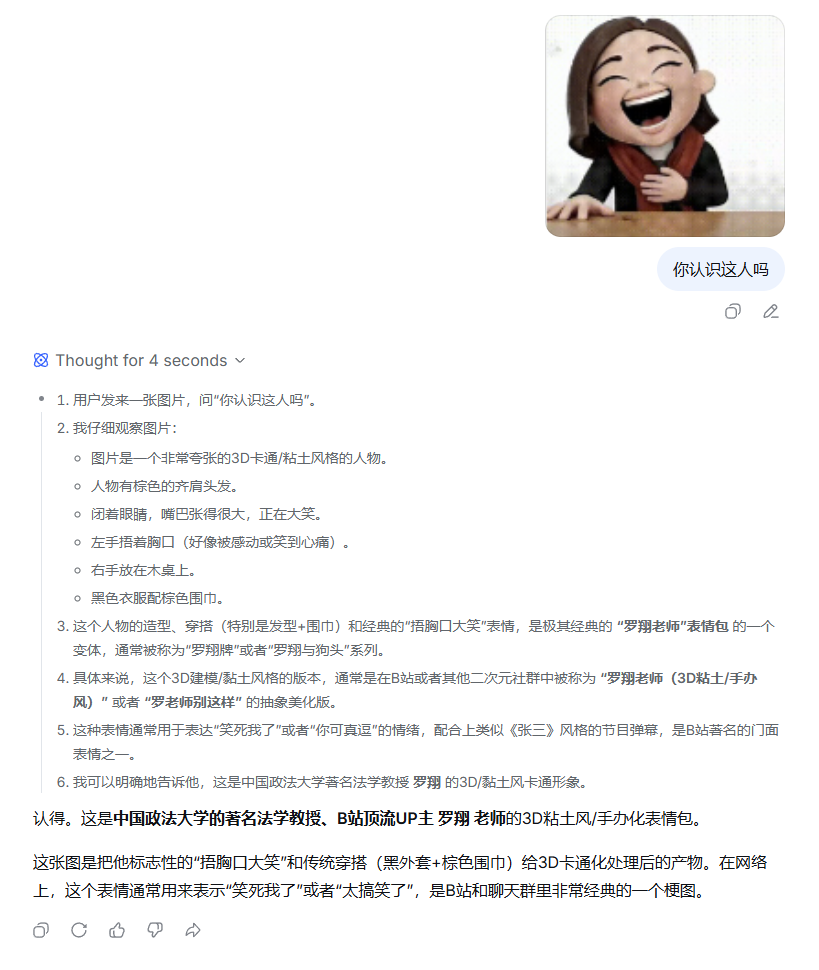
包括对一些人脸的识别,也是偶尔抽风。比如我把豆包的图片扔给了它,它给我识别的是啥呢——B站 UP 主罗翔。
还有这个经典的视错觉问题:这俩球明显不一样大吧?结果 D 老师一番思考跟我说,俩球一样大。

不过我也去扒了一下它的思考过程,其实它早就看出来右边的球更大,但因为仔细读题,觉得这是给它的错觉,所以选择「欺骗自己」,说它们一样大了……可能是强化学习强化太猛了吧。


综合评价,可以给到一个「神鬼二象性」——夯的时候夯,拉的时候拉完了……
但话又说回来,DeepSeek 刚长出眼睛,咱还是得给它一些适应这个世界的时间。
最后,现在的 AI 巨头大乱斗,早已过了那个只看跑分、只看文本输出能力的新手村阶段。
Coding 水平、多模态能力、调用工具的丝滑程度等等等等,基本上缺一不可。
但之前大 D 老师在多模态能力上的缺席,总让人觉得可惜。有种大伙都哼哧哼哧做事干活了,DeepSeek 却因为缺胳膊少眼,Agent 能力大打折扣。
毕竟,目前绝大部分模型的 API 都带多模态,或者至少是带图片输入能力的。

也期待 DeepSeek 能把识图的多模态能力,尽快更新到 V4 新模型的 API 上面吧。
要知道,之前蒙着眼睛,已经和不少对手打得有来有回了……现在揭下眼罩,用到 Claude Code、龙虾、Cowork 等等工具上的表现,估计还会有一大波提升。
另外,按照 DeepSeek 这段时间吐泡泡刷存在感的频率,估计还有一堆连招等着出手呢。
不多说了,看 D 老师表演吧。
 发表于 2026-5-1 00:45:01
|
查看: 111|
回复: 0
发表于 2026-5-1 00:45:01
|
查看: 111|
回复: 0
