本项目构建了一个网关路由 AI 安全审计系统,采用“通用 Agent + 业务 Skill”的分层设计,支持增量日检与存量月检。我们已经成功落地了 Open 网关路由的越权漏洞检测流程。通过“AI 批量筛查 + 人工深度验证”的人机协同模式,它为大规模 API 安全审计提供了一套可复用的智能化解决方案。核心思路是充分发挥通用 Agent 的能力,同时将易变的业务逻辑沉淀在 Skill 中实现快速迭代。
在深入探讨技术细节之前,不妨先思考一个问题:当你的平台需要管理数万条 API 路由、背后是数百个微服务时,如何确保每一处变更或新增都不会引入越权风险?这正是我们试图用 AI Agent 系统化解决的难题。如果您对这类 AI 与安全结合的实践感兴趣,也欢迎常来云栈社区看看,这里汇聚了许多关于安全攻防、逆向分析的技术讨论。
一、背景与技术方案
安全审计的核心挑战
随着平台 API 规模持续扩张,安全审计正面临前所未有的规模化挑战。

主要挑战如下:
- 覆盖面不足:传统抽样审计的覆盖率仅能达到约 20%。
- 时效性压力:新上线的接口迫切需要更快速的安全评估反馈。
- 规则一致性:标准化的检测规则在人工模式下难以有效沉淀和复用。
技术选型与建设契机
当前,以大型语言模型为基座的 AI Agent 在代码语义理解、逻辑推理与自动化执行等方面的能力,已超预期地成熟,其工程落地的准确率与稳定性得到了大规模验证。这一技术跃迁,使全量自动化安全审计从概念验证走向了可靠实践。传统人工抽样模式在数万条 API、数百个微服务的规模下已难以为继,而基于 AI Agent 的方案,则可以实现 100% 路由覆盖与分钟级的检测响应。本文将围绕这一契机,阐述如何构建贯穿全链路调用链的智能审计体系,旨在解决覆盖面、时效性与规则一致性这三大核心挑战。
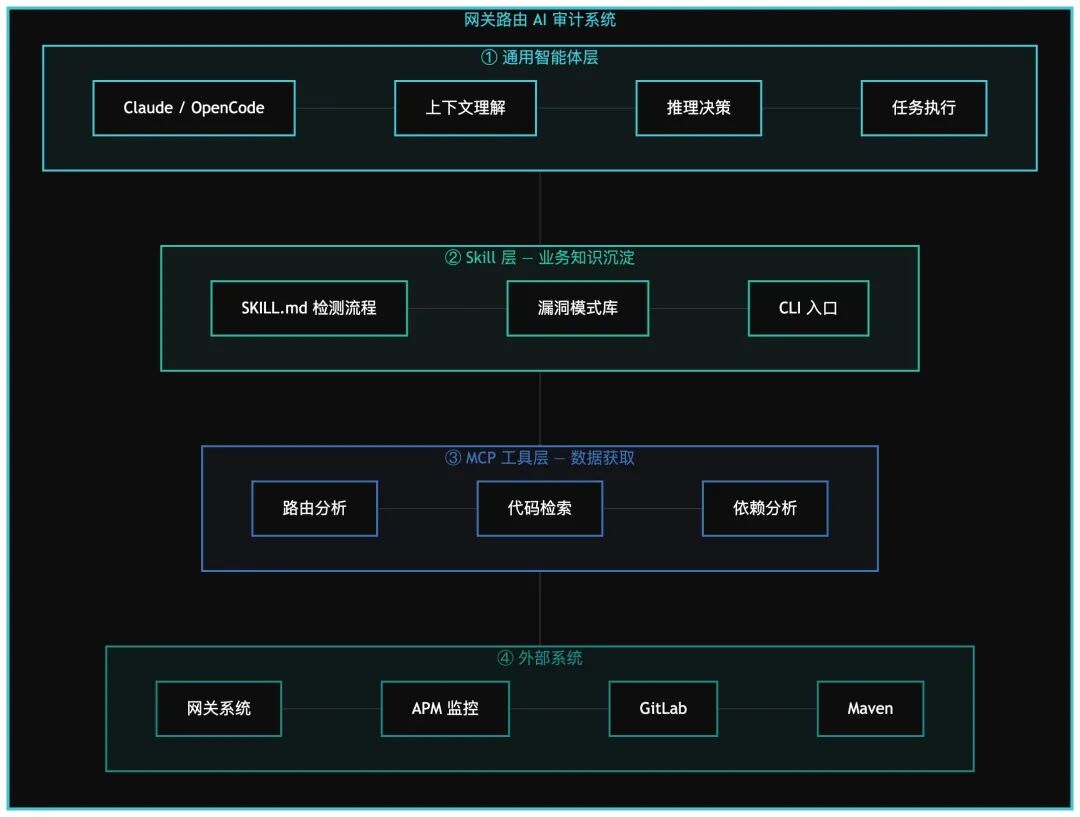
二、技术架构
整体架构设计
架构说明:常规代码负责任务调度与结果存储,而所有核心的 AI 分析工作,均由一个超级 Agent 完成。
在具体项目的分析告警环节,我们采用了“AI 批量筛查 + 人工深度验证”的人机协同模式:
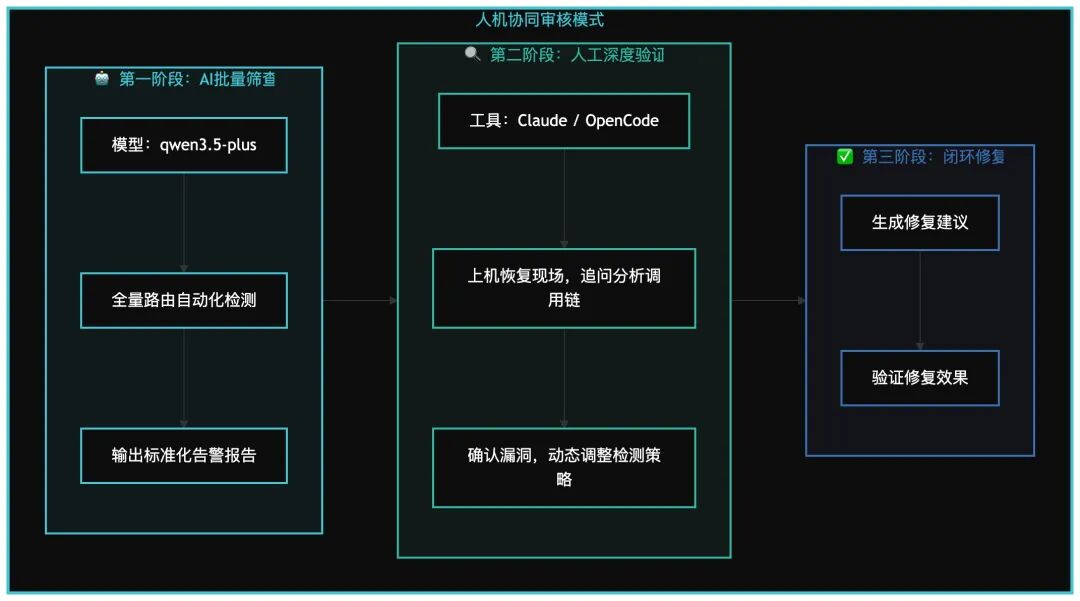
场景化应用说明:

架构设计原则:通用 Agent + 业务 Skill 分离
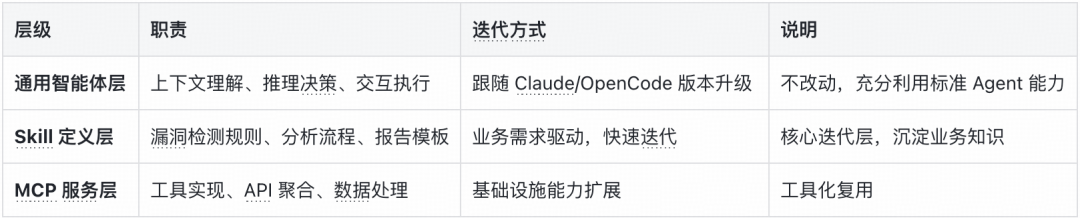
这种设计带来了几个关键优势:
- 通用 Agent 能力最大化:充分利用 Claude Code/OpenCode 的代码理解、推理分析、上下文管理、会话恢复等标准能力,绝不重复造轮子。
- 业务逻辑快速迭代:检测规则、分析流程、报告格式等所有业务逻辑,全部沉淀在 Skill 中,可以随时调整优化,灵活应对业务变化。
- 任务可追溯可复现:借助
--resume 能力恢复会话现场,任何分析过程都可以回溯、可被验证。
Skill 层核心组成
Skill 是整个体系的“业务大脑”,其目录结构清晰地展示了它的核心职责:
gateway-route-vuln-analyzer/
├── SKILL.md # 核心:漏洞分析主流程
│ ├── 检测决策树(Step 1-4)
│ ├── 危害评估规则
│ └── 报告输出模板
├── references/
│ ├── unauthorized_patterns.md # 越权漏洞模式库
│ ├── logic_flaws.md # 逻辑漏洞检测指南
│ ├── data_classification.md # 数据敏感性分级
│ └── report_template.md # 标准化报告模板
└── scripts/
└── mcpcli-gateway # CLI入口(Token优化)
MCP 工具集设计
工具层为 Agent 提供了耳目和手脚,是获取数据的关键。我们精心设计了一套 MCP 工具集来支撑分析链路。

三、漏洞检测方法论(以越权为例)
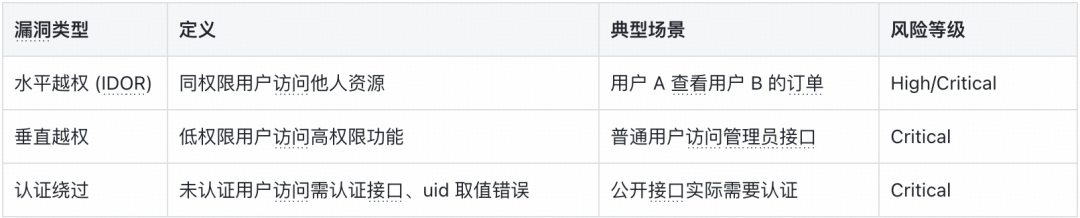
越权漏洞精细化分类
我们基于公开漏洞案例库进行了深入分析,对越权漏洞做了更精细的划分,而不是笼统地一刀切。
检测决策流程
整个检测过程分为清晰的四步,并且在前两步设计了短路退出机制,以最大程度地节约分析成本。流程概要如下:
- 路由配置检查:检查
auth_config.public 和 required_scopes,如果配置上不存在越权风险,则直接跳过后续的代码审计。
- 登录态识别:遍历调用链,查找认证节点。对于标准认证路由,我们选择直接信任,不再进行代码审计。
- 代码审计(三维检测):这是核心步骤,会从三个维度深入检查:权限注解(如
@PreAuthorize)、用户 ID 的来源(是安全地从登录态获取还是来自不可信的请求参数)、以及所有权校验的实现方式(是基于 DB 的过滤还是代码中的显式校验)。
- 精细化危害评估:这是最后一步,我们严格区分越权读取(看数据敏感性)和越权操作(看利益流向),最终输出精准的风险等级与修复建议。
精细化危害评估机制
越权读取 - 数据敏感性评估
依据《数据安全法》确立的数据分类分级保护制度及《网络安全法》的相关要求,我们让 AI Agent 对源代码进行文本分析(基于变量名、字段类型、接口定义等代码特征进行技术推断),对路由功能返回所涉及的数据资产进行分级评估。
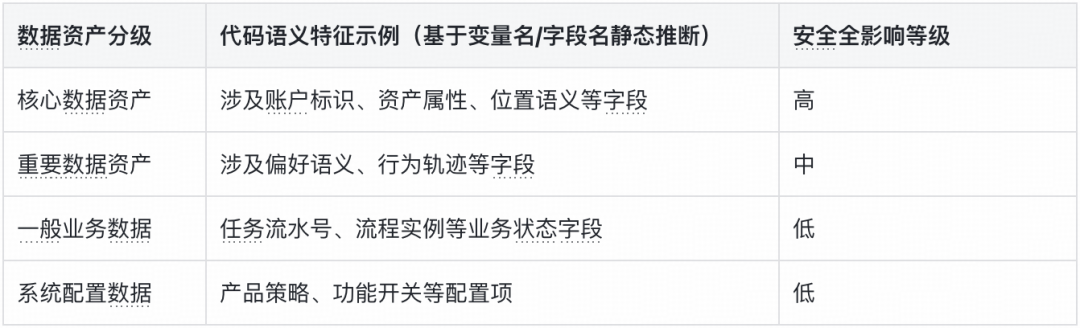
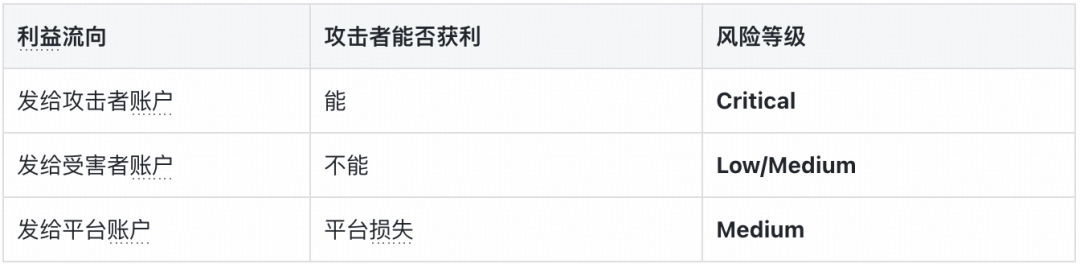
越权操作 - 利益流向评估
对于越权操作,我们引入了一个非常贴合业务的评估维度——利益流向,让风险评级不再是空洞的理论分级。
四、技术优化:Token 成本降低 95%+
问题诊断
通过对大量会话日志的深入剖析,我们锁定了 Token 消耗的几个关键瓶颈。

Token 消耗热点分析:
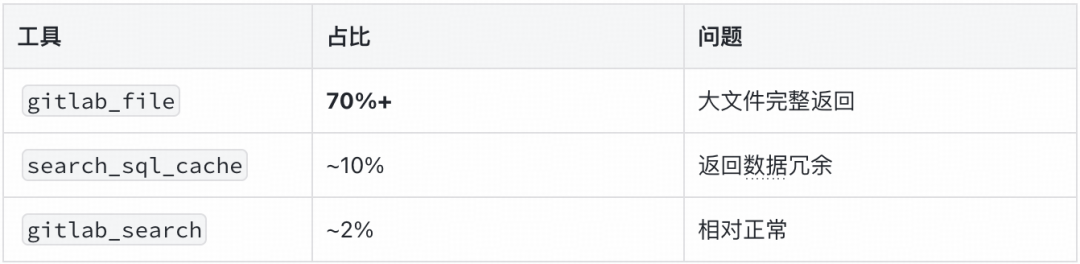
优化策略与效果
1. MCP → CLI 转换(mcp2cli):核心优化
2. 工具返回值优化:关键优化
- 问题:无参数调用会傻傻地返回完整文件,最大可达 1.47MB(约 500K tokens),极其浪费。
- 解决方案:为
gitlab_file 工具添加精准参数,实现按需提取,只取我们关心的那部分代码。
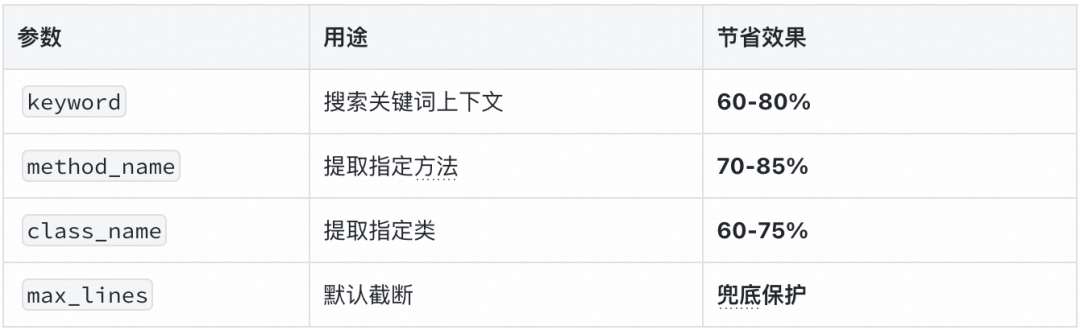
- 效果:相较 v1 版本,v2 版在此基础上再度节省了 88% 的 Token 开销。
3. Early-Exit 模式
- 原理:对于那些经过标准认证的路由,给予直接信任,跳过冗长且不必要的代码审计环节。
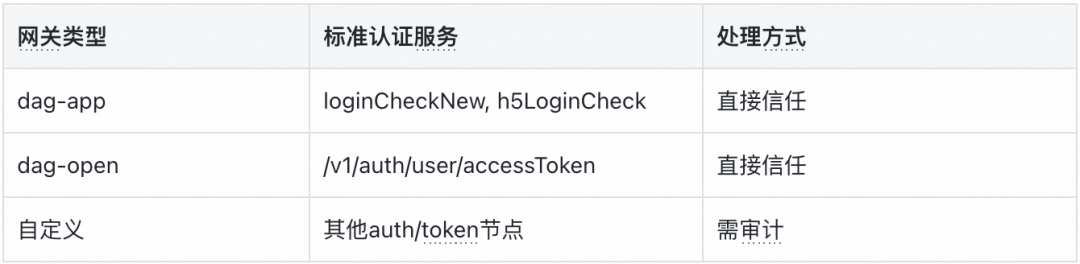
- 效果:在标准认证的场景下,能节省 50-70% 的 Token 消耗。
4. AI 友好返回格式 YAML
- 原理:YAML 格式在结构表达上天然比 JSON 更省 Token,层级关系也更直观,对 AI 模型的解析更友好,能降低其计算成本。
五、模型选型原则与决策框架
在路由安全审计这个场景下,模型选型绝非仅看跑分,而是围绕准确率(Precision)与召回率(Recall)两大核心指标,建立一套严谨的决策矩阵。

基于以上原则,我们最终选择了同时满足 P0 / P1 / P2 三重约束的最优模型。选型理由非常务实:在所有召回率达到 100% 的候选模型中,qwen3.5-plus 以更低的单位成本,实现了可接受的准确率,是批量扫描场景下的最优解。
局限性说明:
当然,任何方案都有其边界。我们的测试集基于独立手工标注的 100+ 样本,与生产告警数据隔离,结论仅能作为基线参考。此外,大模型领域迭代速度极快,市场中随时可能出现性能更优、成本更低的全新模型,本次评测尚未将其纳入考察范围。
归根结底,AI 不是要替代人工,而是要放大安全工程师的能力:让 AI 去处理那些繁重的重复性筛查,而把人的精力解放出来,去聚焦深度分析和复杂判断。
六、方法论沉淀
经过这个项目,我们沉淀下了一套可复用的方法论,主要体现在以下几点:
- 定制化漏洞分析能力沉淀:针对 API 越权漏洞场景,我们构建了专属的漏洞分析技能体系,并持续沉淀检测规则与标准化分析流程,确保了规则的落地实战有效性。
- 精细化危害评估体系:我们严格区分了越权读取与越权操作这两类风险行为,引入“利益流向”这一分析维度,规避了一刀切式的风险评级,使评估结果更贴合业务的实际风险。
- Token 成本系统化优化:通过“MCP→CLI 格式转换 + 代码精准按需提取 + Early-Exit 提前终止”这三层优化方案,整体实现了 Token 成本 95% 以上的降幅,为大规模应用扫清了成本障碍。
- 场景化分层模型选型:在批量例行场景采用高性价比模型,在核心关键场景启用高精度模型,在检测效果与使用成本之间实现了最优平衡。
七、误报分析与改进方向
误报根因分析
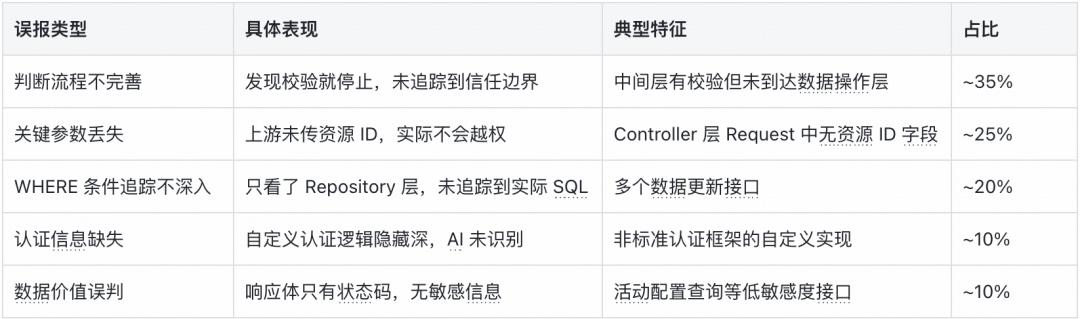
基于对已完成的复核告警的深度分析,我们识别出了导致误报的几个主要原因,并针对性地制定了改进方案。
针对性改进方案
1. 强化信任边界追踪(解决约 35% 的误报)
2. 上下游参数一致性校验(解决约 25% 的误报)
- 问题:下游方法参数存在理论上的越权可能,但上游调用时根本没传入资源 ID,导致误报。
- 方案:着重分析 Controller 层的 Request 对象,确认其是否真的包含了资源 ID 字段。如果上游 Request 中压根没有资源 ID 字段,我们就判定为“仅可操作当前用户数据”。实施上,在 Skill 中增加了规则:“优先检查 Controller 层入参,无资源 ID 则跳过越权分析”。
3. Dubbo 配置信息补充(解决约 10% 的误报)
4. 代码内的响应体价值预判优化(解决约 10% 的误报)
后续规划
后续,我们将从范围扩展、AI 复核闭环、平台化建设三个方向持续深化,旨在打造一个从发现到修复的全流程线上化体系。

八、小结
网关路由的 AI 驱动审计,是面向 API 安全场景的一种智能化交付范式。它将过去繁重的规模化安全审计,升级为了“AI 自动化检测 + 精细化危害评估 + Token 成本优化”的标准化机制。
它试图解答一个关键问题: 在网关路由规模飞速扩张的背景下,到底如何实现安全漏洞的全量自动化检测,并同时把成本控制在可接受的范围内?
它也证明了一系列事实: 我们通过实际发现了多个高危外网漏洞,这直接验证了 AI 在代码审计场景下的有效性。优化后单条路由的检测成本低至 ¥0.23,即便对某个大型业务集群进行一轮全量扫描,费用也不到 1 万元,成本完全可控。而“AI 批量筛查 + 人工深度验证”的人机协同模式被证明是行之有效的,完美兼顾了效率与准确性。
它最终沉淀下可复用的方法: 无论是 MCP→CLI 转换、精准代码提取,还是 Early-Exit 优化,这些技巧都能被复用到其他 AI 安全审计场景中去。
九、附录
标准化告警报告模板
本项目最终会输出一份标准化的漏洞分析报告,下面是它的模板结构,供你参考或复用。
# 漏洞分析报告
### 1. 路由信息
路由ID: [必填:从 analyze_route 返回的 route_id]
路径: [必填:分析的路由路径]
目标服务: [必填:目标服务名称]
描述: [必填:路由描述,如无则填"无"]
### 2. 接口功能分析
接口用途: [必填:简要说明接口用途]
业务场景: [必填:业务场景描述]
调用方: [必填:H5前端/APP客户端/小程序/其他服务]
数据敏感性评估:
- 涉及数据类型: [必填:PII/金融数据/订单信息/配置信息等]
- 敏感等级: [必填:critical/high/medium/low]
- 影响用户范围: [必填:全平台用户/特定用户群/内部用户等]
### 3. 调用链分析
[必填:调用链树形展示,使用缩进表示层级关系,标记漏洞点]
示例格式:
[网关入口] (总耗时)
└─ [认证服务]: [认证接口] (耗时) [认证节点]
└─ [业务服务A]: [业务接口] (耗时) [漏洞点]
└─ [业务服务B]: [数据库查询] (耗时)
关键中间件操作(只写与漏洞分析直接相关的部分):
SQL: [可选:列出执行的 SQL 操作类型,如 SELECT/INSERT/UPDATE/DELETE]
Redis: [可选:如有 Redis 操作则填写]
MQ: [可选:如有 MQ 操作则填写]
### 4. 漏洞详情
⚠️ 说明:
- 如果发现漏洞,必须填写此章节
- 如果未发现漏洞,填写"未发现漏洞"并跳过后续小节
#### 漏洞 1: [必填:漏洞标题]
- 严重等级: [必填:critical/high/medium/low]
- 类型: [必填:越权读取/越权操作/逻辑漏洞/竞争条件]
- 漏洞位置:
- 服务: [必填:漏洞所在服务名称]
- 方法: [必填:漏洞所在方法名]
- 文件: [必填:文件路径:行号]
- 仓库链接: [必填:GitLab 代码链接]
- Trace ID: [必填:对应的 trace_id]
问题描述: [必填:详细描述漏洞原因和利用机制]
调用链位置: [必填:标注漏洞在调用链中的位置]
问题代码:
[必填:漏洞代码片段,包含行号]
漏洞危害:
1. [必填:直接危害]
2. [必填:间接危害]
3. 潜在连锁攻击: [必填:可能的连锁攻击场景]
4. 合规风险: [必填:法律合规风险]
修复建议:
1. [必填:具体修复方案]
2. [必填:具体修复方案]
3. [可选:额外加固建议]
### 5. 分析置信度
- 置信度: [必填:高/中/低]
- 依据: [必填:说明置信度的判断依据]
### 6. 局限性
⚠️ 数据获取不全说明:
| 限制类型 | 说明 | 影响范围 | 建议操作 |
|----------|------|----------|----------|
| [限制类型] | [说明] | [影响范围] | [建议操作] |
### 7. 二方包依赖
- 涉及的二方包: [必填:group_id:artifact_id:version - 用途说明,如无则填"无"]
- 源码获取: [必填:已获取/未获取/不需要]
### 8. 涉及的微服务
⚠️ 重要:必须包含 commit_id 和 project_path
- [service_name1] (commit: [commit_id], project: [project_path])
- [service_name2] (commit: [commit_id], project: [project_path])
``
 发表于 2026-5-1 00:48:46
|
查看: 332|
回复: 0
发表于 2026-5-1 00:48:46
|
查看: 332|
回复: 0
