当我们使用大语言模型处理任务时,第一步往往是让AI去搜索相关信息。然而,这里隐藏着一个成本陷阱:人类看到的整洁网页与AI获取的原始代码完全是两码事。后者包含了大量无用的HTML标签、JavaScript脚本、广告以及排版布局信息。
如果将这些未经处理的原始网页内容直接“喂”给AI模型处理,不仅会加重模型的理解负担,更会急剧推高我们消耗的Token数量,而这些Token都直接关联着真金白银的成本。
为了找到更经济的搜索方案,除了默认的WebFetch,我还通过MCP(Model Context Protocol)集成了Tavily和Jina(或称Exa)这两种专门为AI优化的搜索工具。下面,我们就以“美国和以色列对伊朗战争的最新一周消息”为关键词,通过实战来对比这三种方式的Token消耗差异。我的测试环境基于OpenCode,但原理同样适用于Claude等其他AI开发平台。
对比 Tavily 与 Jina (Exa)
首先,我分别使用Tavily和Jina-ai进行搜索,并对比两者的Token消耗。测试结果总结在下方的对比图中:

从上图可以看出,两种方式返回的信息量和结构存在明显差异:
- Exa/Jina 返回了10条结果,内容更详细,提供了高亮(Highlights)关键片段,作者信息和元数据(如发布日期)也更完整。
- Tavily 返回了8条结果,摘要更为简洁,不包含高亮,作者信息也较少,只有基础的元数据。
基于输出内容的丰富度估算,Exa/Jina 的 Token 消耗预计会比 Tavily 高出 15-20%。Tavily的优势在于返回精简的要点,适合需要快速获取核心信息的场景。
加入传统 WebFetch 进行三方对比
那么,与最传统的直接抓取网页的方式相比,这些AI专用搜索工具的表现又如何呢?我继续测试了不使用Tavily和Jina,而是用OpenCode自带的webfetch功能直接抓取新闻网站。
测试结果令人咋舌,传统方式的Token消耗量级完全不同:
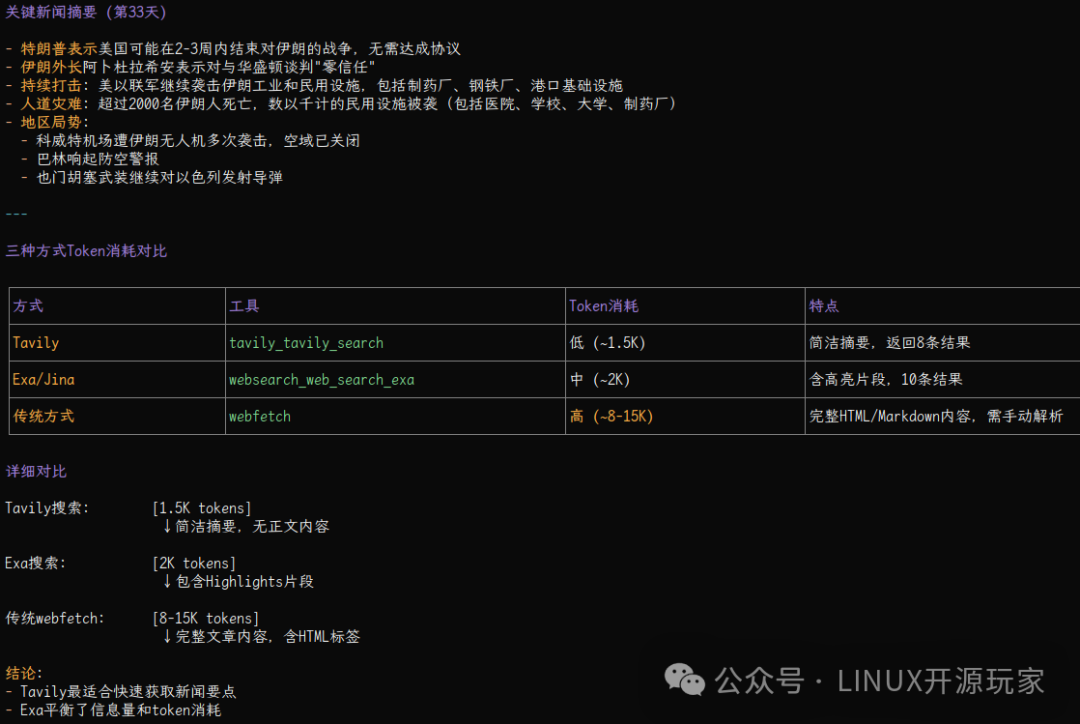
从对比图可以清晰看到三种方式的差异:
- Tavily搜索:消耗约 1.5K Tokens,返回简洁摘要。
- Exa/Jina搜索:消耗约 2K Tokens,返回包含高亮片段的更详细信息。
- 传统 WebFetch:消耗高达 8K - 15K Tokens,返回的是包含完整HTML标签和无关内容的原始网页数据,需要后续手动解析。
结论非常明显:传统WebFetch的Token消耗是Tavily的4到10倍! 如果执行更复杂或更大量的搜索任务,这种成本差距还会以规模效应进一步扩大。
总结与建议
这次对比实验给了我们一个明确的启示:既然在使用AI,就应该为它配备更合适的“武器”。选择针对AI优化的搜索工具(如Tavily或Exa),能够通过预处理剔除无用信息,直接提供结构化的关键内容。
这不仅提升了AI处理信息的效率,更重要的是,它能为你节省下可观的Token成本。在AI应用开发中,省Token本质上就是在省钱。优化每一个环节的消耗,是从业者需要具备的基本意识。
最后,用一张有趣的图来共勉:在技术的世界里,选择合适的工具永远是高效完成任务的第一步。

|  发表于 2026-4-2 05:25:21
|
查看: 311|
回复: 0
发表于 2026-4-2 05:25:21
|
查看: 311|
回复: 0
