闻乐 发自 凹非寺
DeepSeek 的视觉功能真的来了!
DeepSeek 研究员陈小康率先发帖,用一条简短的消息点爆了开发者社区—— “Now, we see you. 👀 现在,我们看到你了。”
这条动态在云栈社区的技术圈子里也立刻炸开了锅,大家纷纷猜测:多模态这最后一张拼图是不是终于要拼上了?没过多久,另一位核心研究员陈德里也确认:V4 视觉模式已正式进入灰度测试阶段。
小鲸鱼能“看见”了,这事儿本身就像个信号:通用大模型的感知能力,正以肉眼可见的速度从实验室往外涌。
已经具备真实图像理解能力
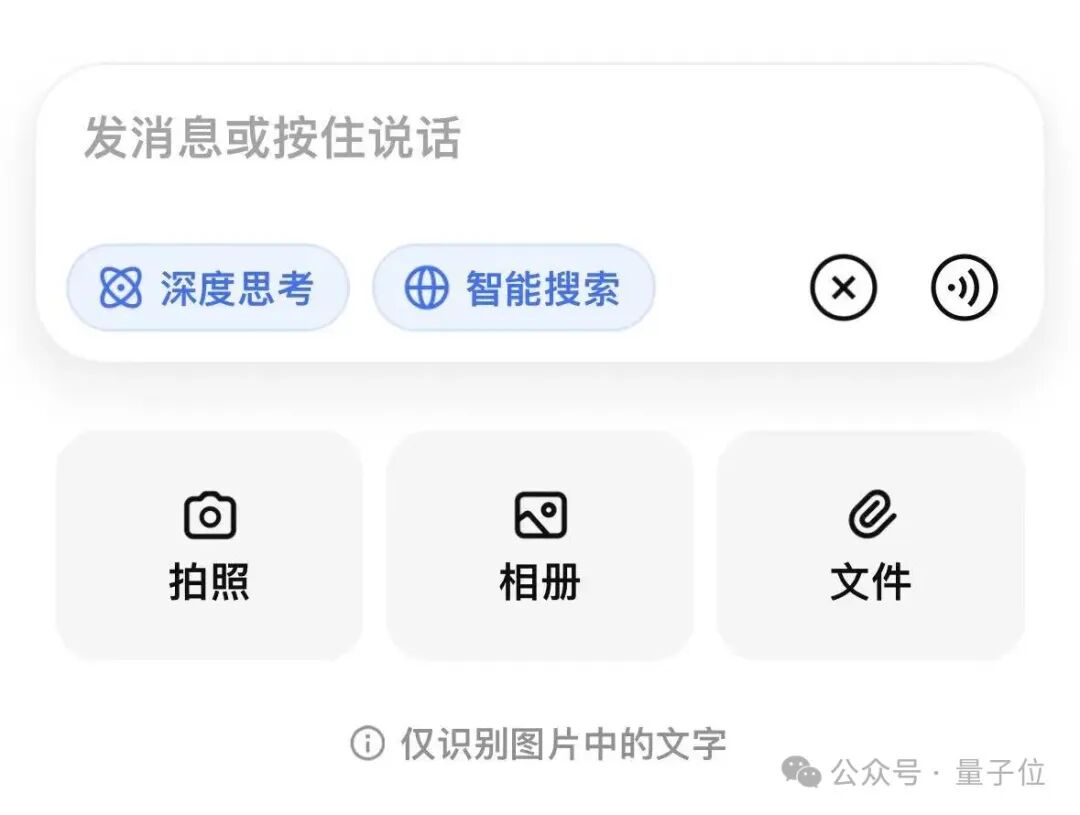
你要知道,在此前版本中上传图片时,模型只能走 OCR 路线,也就是单纯把图片里的文字扒出来。下图就是旧版界面的典型状态,底部还写着“仅识别图片中的文字”。
但今天的灰度更新算是跨了一大步。被灰度选中的“幸运鹅”发现,首页已经冒出了醒目的“识图模式”入口,下面紧跟着一行“图片理解功能内测中”的小字提示。
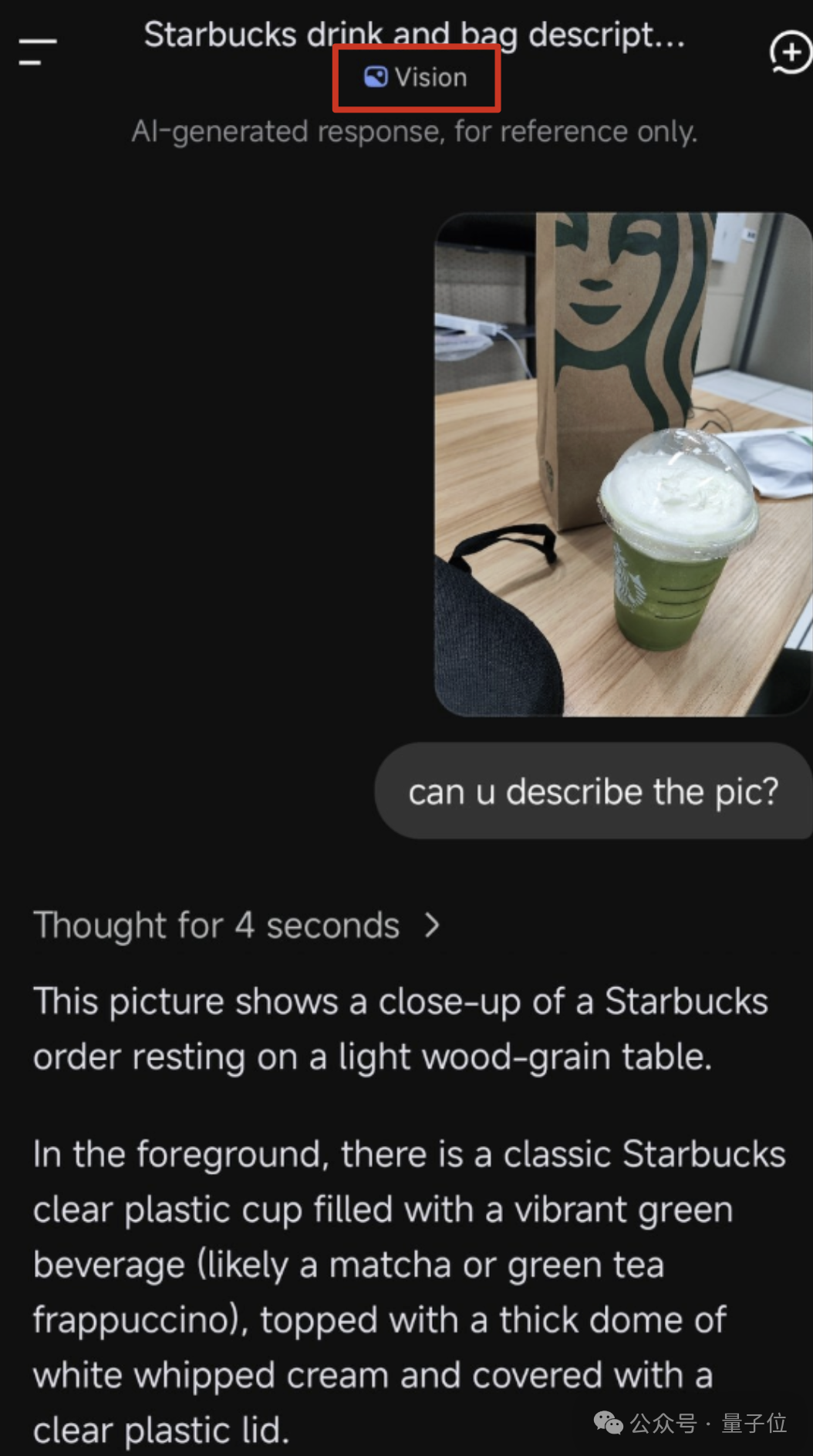
先来看看效果怎么样。一位获测用户分享的截图显示,他上传了一张无明显文字的星巴克饮品照片,DeepSeek 的测试版不仅正确识别出了抹茶星冰乐、透明杯型与奶油覆盖等细节,还经过 4 秒思考输出了完整且通顺的英文描述。这说明模型确实在“理解”画面内容,而不是只做字符扫描。
V4,满血归来
放出这两条爆炸性消息的研究员,可个个都不是“路人甲”。
陈小康,北京大学博士、DeepSeek 多模态研究组负责人。他主导的两项多模态工作,随便拎一个出来都是顶会常客:一个是 Janus 系列,专门搞统一的多模态理解与生成;另一个是 DeepSeek-VL2,基于 MoE 架构的视觉语言模型。

换句话说,DeepSeek 现在能“睁眼看世界”,就是他带团队硬刚出来的。
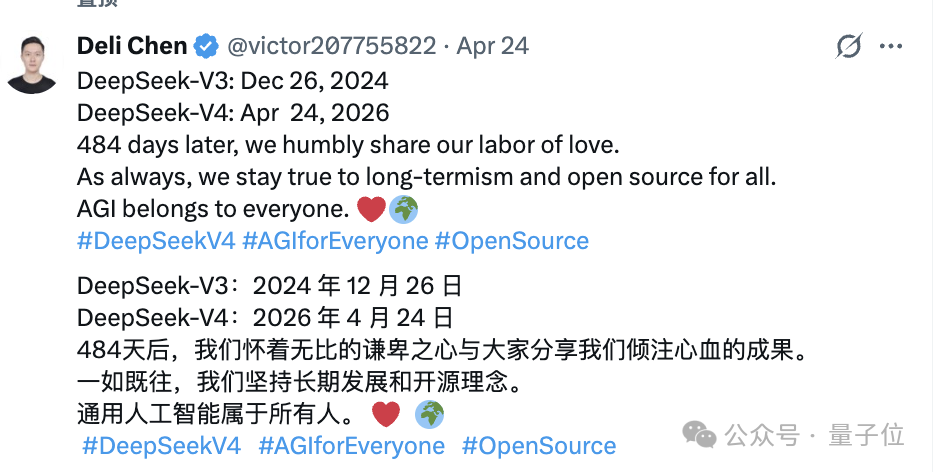
而另一位陈德里则长期扎根语言模型、对齐策略、训练策略以及模型泛化能力等核心方向。过去两年,从 V2、V3 到 R1,几乎所有重要发布里都能找到他的名字,这一次 V4 也绝不例外。他最近还专门发帖回顾了长期路线:DeepSeek-V3 发布于 2024 年 12 月 26 日,V4 发布于 2026 年 4 月 24 日,相隔 484 天。
API 价格已经“打骨折”之后,现在视觉能力又火速补上——还有多少惊喜是我们没猜到的?
不得不说,在多模态这条拼图上,DeepSeek V4 这一轮是真真切切地满血归来了。
参考链接:
[1] https://x.com/victor207755822
[2] https://x.com/PKUCXK/status/2049381471669080209 |  发表于 2026-4-30 21:01:05
|
查看: 194|
回复: 0
发表于 2026-4-30 21:01:05
|
查看: 194|
回复: 0
