“价格屠夫”DeepSeek,又出手了。
新模型发布不到三天,“小蓝鲸”接连发起两波降价攻势。V4-Pro上线仅一天,直接甩出 75% 限时折扣(持续至5月5日23:59 UTC)。紧接着,今天又宣布 全系列API输入缓存命中价格永久降至原价的 1/10。
两项优惠叠加后,DeepSeek-V4-Pro 缓存命中输入仅 0.025 元/百万Tokens,V4-Flash 更是低至 0.02 元,创下全球大模型价格新低。
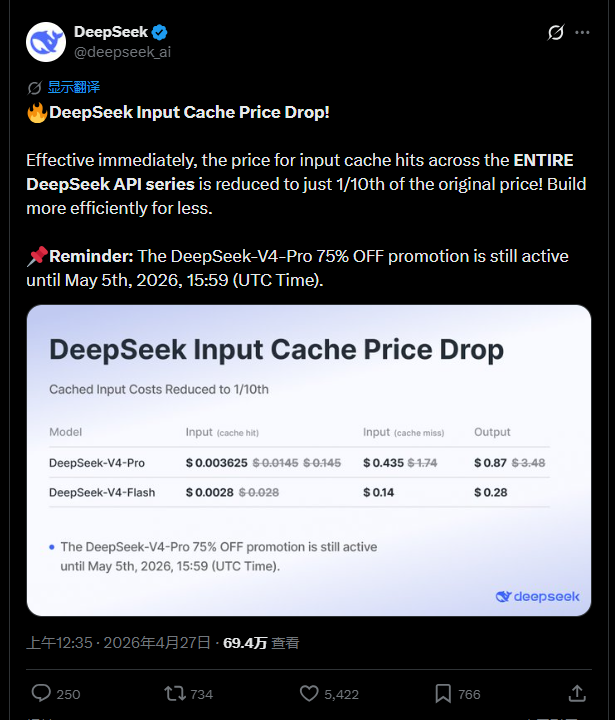
这个价格,让 OpenAI 和 Anthropic 黯然失色。据悉,GPT-5.5 pro 的输入价格高达 60 美元/百万Tokens,输出价格为 360 美元/百万Tokens。

换算下来,GPT-5.5 的输入价格是 DeepSeek-V4 的 16552 倍。即便对比同等性能的 GPT 5.4、Claude Opus 4.7(通常输入价 2~5 美元/百万Token,输出价 18~25 美元/百万Token),DeepSeek 的输入价格也至少低了 550 倍以上,输出价格则低了 30~90 倍。
问题不止在价格本身,更在于降价这个动作。2026 年以来,别家 AI 都在集体涨价,DeepSeek 怎么反而逆势“打骨折”了?
别人集体涨价,DeepSeek 反向降价
众所周知,2026 年,模型厂商的 AI [算力成本]整体都在涨。Claude Code、Codex、OpenClaw、Hermes 等 Agent 产品的普及,让全球 Token 调用量呈井喷之势,预计全年将达到 140 万亿Tokens。加上芯片、电力等资源日渐稀缺,多家云厂商和模型 API 已集体提价 10%-34%。
上游云厂商中,阿里云收紧 DataWorks 免费 API 额度,超额转向按量收费;百度智能云、腾讯云也因算力紧张和硬件成本上涨,上调了 AI 算力及相关服务价格,涨幅约 5% 至 30%。
下游模型厂商方面,国外 Anthropic 上月底对订阅用户实施了“限流”,高峰时段用户会很快达到会话上限。OpenAI 最新模型 GPT-5.5 的 API 价格也上涨不少。国内方面,智谱由于 Coding 与智能体调用成本持续走高,年内已三次提高 API 价格。
整体来看,从云基础设施到模型接口,业界普遍认为正在告别低价补贴期,进入成本传导与价值重估阶段。但 DeepSeek V4 的到来,加上这接连两刀,似乎又一次搅动了 AI 世界。
剑指 Agent 开发普及
DeepSeek 反其道而行,明明达到 SOTA 性能,却接连降价,主动把行业价格预期往下拉。不少业界机构与人士(如高盛、上海财经大学特聘教授胡延平等)认为,此举意在延揽更多用户,尤其是企业用户、开发者和各类 [Agent] 用户。这些场景 Token 消耗巨大,对价格最为敏感。降价后,高缓存场景成本可断崖式下跌 90% 以上,直接打破 AI 规模化落地的成本枷锁。
高盛等机构分析认为,DeepSeek V4 性能已接近一线闭源模型,却用极致性价比抢占市场,同时巩固了其在 [开源实战] 与性价比赛道上的领先位置。具体来看,V4-Pro 主打工程与 Agent 强项(长上下文、代码、多模态),这对于中小企业、开发者和 Agent 项目来说是重大利好,能帮助他们尽快跑出商业闭环。
其实,DeepSeek 一直有“价格屠夫”的传统,V3/R1 时期已多次引发行业跟进。这次更狠:部分用户反馈 V4-Pro 初始定价偏高后,24 小时内直接 2.5 折,快速纠偏并放大了这款模型的吸引力。
DeepSeek 凭什么这么狠?
如此狠的降价力度,背后是 DeepSeek 的技术突破。DeepSeek-V4 系列采用自研 MoE 架构与混合注意力机制优化。在 100 万 Token 的超长上下文场景下,与上一代 V3.2 相比,V4-Pro 的推理计算量(FLOPs)仅需 27%,KV 缓存暴降至 10%;V4-Flash 更极端,推理计算量降至 10%,KV 缓存降至 7%。
更关键的是,他们早早研发了成熟的磁盘上下文缓存(Context Caching on Disk)技术。在 RAG、Agent、多轮对话、智能客服、代码库分析等高重复场景里,缓存命中率极高,实际计算量能省 70-90%。这次直接把缓存命中价格砍到 1/10,就是把真实的技术红利 100% 让利给开发者。这次降价,本质上也是工程效率提升后的自然结果。
再次证明:国产算力也能训练出 SOTA
另一个降价的底气,来自 [国产算力]的全面适配。V4 系列已全链路适配华为昇腾 NPU,包括 950 超节点验证。昇腾 950 通过融合 Kernel 和多流并行技术降低 Attention 计算和访存开销,大幅提升推理性能,结合多种量化算法,实现了高吞吐、低时延的 DeepSeek V4 模型推理部署。此外,寒武纪、摩尔线程等国产算力也在第一时间宣布与 V4 系列适配。
这再次证明:在国际供应链波动、NVIDIA 算力受限的背景下,中国 AI 完全有能力实现从模型到国产芯片、再到云的自主闭环。在云栈社区的技术讨论中,越来越多开发者开始关注国产芯片在实际业务中的部署成本和性能表现。
这次逆势降价,可能只是一波预演。随着国产算力的普及,模型 API 降价将成为常态。
参考链接:
https://x.com/deepseek_ai/status/2048440764368347611
 发表于 2026-4-29 01:14:07
|
查看: 116|
回复: 0
发表于 2026-4-29 01:14:07
|
查看: 116|
回复: 0
