时隔五个月,DeepSeek v4 终于发布了。
在以月为迭代单位的 AI 行业里,这段沉默期不算短。期间,Agentic 能力被 GPT-5.4 和 Opus 4.6 拉开了差距,核心成员离职的传闻也断续传出,外界开始对 DeepSeek 的战略方向打上了问号。
这次 v4 是架构级别的换代。读完官方技术报告,可以肯定地说:这是开源模型头一回在核心能力上真正与闭源第一梯队比肩,也是对外界质疑的有力回击。
V4 系列包含两个模型:DeepSeek-V4-Pro(1.6T 参数,49B 激活)和 DeepSeek-V4-Flash(284B 参数,13B 激活),均支持 100 万 token 上下文,采用 MIT 协议,完全开源。

v4 在技术架构上究竟换了什么,又有哪些真正的创新?下面是我从官方 58 页技术报告中提炼的核心要点,咱们逐层拆解。
1. 混合注意力:百万上下文的效率密码
V4 最大的工程突破在于注意力机制。
要理解 v4 的创新,得先铺垫一点背景。大模型的推理成本主要烧在两个地方:计算量(FLOPs)和显存(KV cache)。上下文越长,这两样东西就会线性甚至超线性增长。在传统架构下,100 万 token 的上下文光 KV cache 就能吃掉几十 GB 显存。这也是为什么很多模型号称支持长上下文,实际跑起来又慢又贵。
DeepSeek 给出的方案是 CSA(压缩稀疏注意力)与 HCA(高压缩注意力)的混合打法。
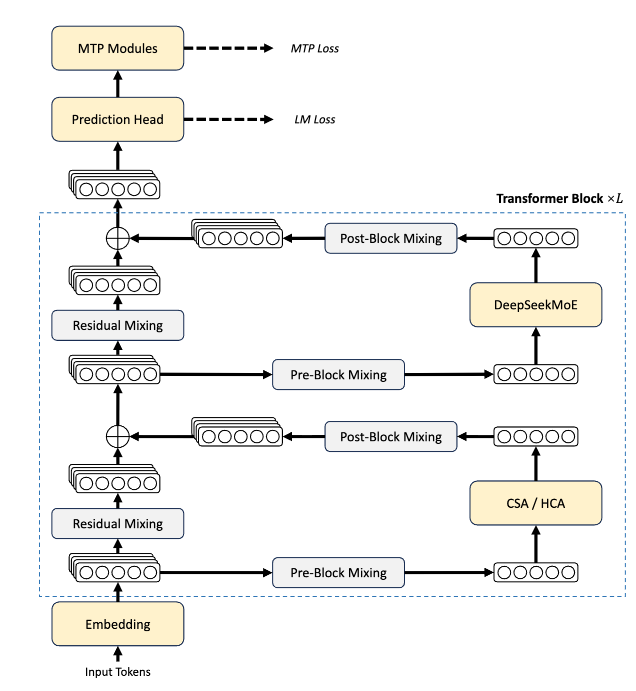
说白了,就是不让每个 token 都去和历史上所有 token 做完整的注意力计算。大部分情况下,用压缩后的版本就够了,只在那些需要精细理解的局部才调用完整注意力。
这么做的直接效果是:在处理 100 万 token 上下文时,V4-Pro 只需要 V3.2 约 27% 的推理计算量和 10% 的 KV 缓存。算力成本不到过去的三分之一,显存占用更是只剩十分之一。
我们可以横向对比一下:早期 Llama 4 Scout 也支持 1000 万 token 上下文,但它依赖的是分层检索加外挂检索器,本质上是一种“记忆 + 搜索”的混合路径。DeepSeek 的方案则是在注意力层内部直接做压缩,不需要任何外挂组件,架构上干净得多。Gemini 3.1 Pro 的百万上下文质量目前是最高的(MRCR 92.9),但它的推理成本并未公开,更像是靠工程资源堆出来的质量。Llama 4 靠外挂降成本,Gemini 靠堆资源保质量,而 DeepSeek 选择在架构层寻找平衡。
2. mHC 与 Muon:训练 1.6T 模型的地基
V4 另外两个架构升级同样关键。
一个是 mHC(流形约束超连接),它要解决的是深层 Transformer 的信号退化问题。传统 Transformer 靠残差连接把信号从底层传到顶层,可层数一多(V4 有上百层),信号要么衰减殆尽,要么直接爆炸。mHC 在残差路径上加了约束,让信号传播更稳定。没有这项技术,1.6T 参数的模型很可能根本训不出来,或者训出来也难以保证质量稳定。
另一个是 Muon 优化器的创新性应用。自 2017 年 Transformer 诞生以来,几乎所有大模型都被 Adam 家族(Adam、AdamW)的优化器所统治。Adam 的优点是稳定,但缺点是慢,调参空间也小。Muon 则另辟蹊径,用矩阵正交化的思路替代了 Adam 的自适应学习率,在大规模训练中收敛更快。DeepSeek 并非第一个使用 Muon 的,之前在小模型上已有验证,但把 Muon 真正用到 1.6T 这种工业级规模并成功跑通的,DeepSeek 是头一个。
3. 训练:32T 数据与“先专后统”
预训练数据量达到 32T,这是目前公开报道中开源模型里最大的规模之一。
更有意思的是它的后训练方法论。此前主流的后训练方式是“一锅炖”:把数学、代码、推理、知识的数据搅在一起,SFT 加 RL 一步到位。问题在于,不同领域的 loss 会互相干扰,模型可能在一个领域学好了,却在另一个领域退步。
OpenAI 的 o 系列和 Anthropic 的 Claude 采用的是“分阶段”策略,先打基础再学推理,但每个阶段内部依然是混合训练。DeepSeek V4 的做法则是 “先专后统”。
它先用 SFT 加上自研的 GRPO(一种比 PPO 更轻量、无需单独训练 value model 的强化学习方法),分别培养出数学专家、代码专家、推理专家。每个专家只专注自己的领域,互不干扰。然后再通过 on-policy distillation(策略蒸馏),将多个专家的能力整合进一个模型里。这里的整合不是简单的参数平均,而是让模型在实际生成中学会在不同领域间自如切换。这个方法论让人想起一种类比:先让不同专业的博士各自做到顶尖,再找一个通才把他们的本事融会贯通。这比让一个人同时读五个博士要高效得多。
4. 三个推理档位
V4-Pro 与 V4-Flash 均支持最大 1M 的上下文长度,并同时支持非思考模式与思考模式。具体提供了三种推理模式:Non-think(快速直觉)、Think High(逻辑分析)、Think Max(推到极限)。
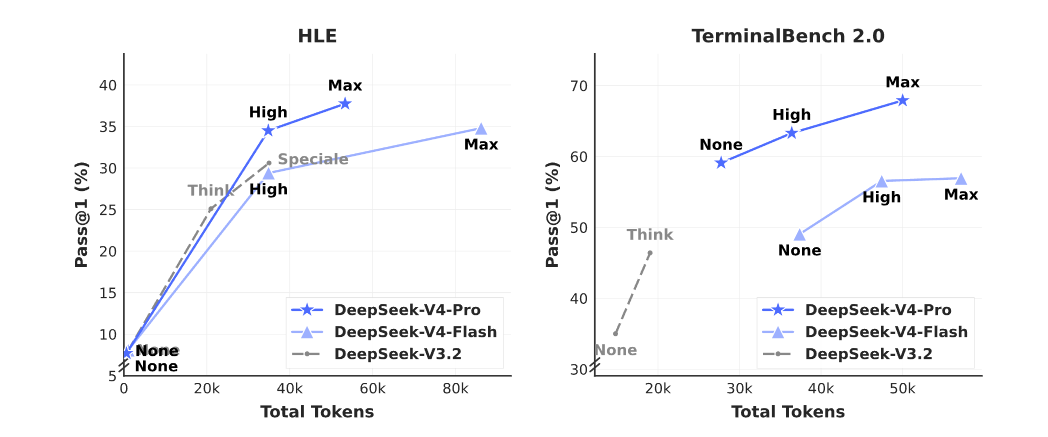
大部分日常任务用 Non-think 就够了,类似于 GPT-4o 的普通模式。遇到复杂问题可以拉到 Think High 开启思维链,而 Think Max 则是将推理推向极致。最恐怖的一点是,Flash 版本在 Think High 模式下,表现竟能逼近 Pro 的 Think Max。一个 284B 总参数、13B 激活的模型,经过 FP4 量化后单张消费级 GPU 就能跑,但在复杂问题上的表现和旗舰版差距很小。Think High 模式下 LiveCodeBench 能到 88.4,SWE Verified 达 78.6。这种性价比,目前在开源界没有对手。
5. 跑分
来说几个关键的 benchmark。
编程能力,V4-Pro Max 的表现,即使把闭源模型也算进来,都属于顶级水准。LiveCodeBench 93.5,超过 Gemini 3.1 Pro 的 91.7 和 Opus 4.6 的 88.8。Codeforces rating 冲到 3206,压过了 GPT-5.4 的 3168。Apex Shortlist 拿到 90.2,也高于 Gemini 的 89.1。三个最核心的编程基准测试全部拿下第一。
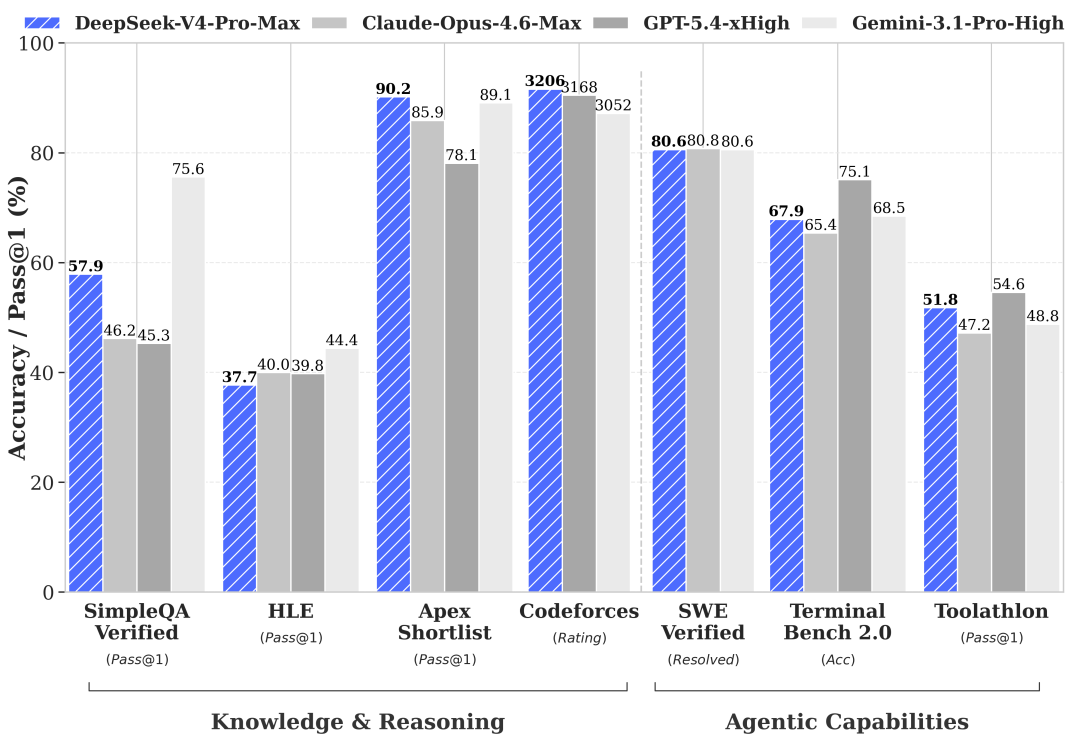
推理和数学,V4 排在 GPT-5.4 和 Gemini 3.1 Pro 之后。HMMT 2026 Feb 得分 95.2,对比 GPT-5.4 的 97.7;IMOAnswerBench 为 89.8 对比 91.4。GPQA Diamond 拿到 90.1,落后 Gemini 的 94.3 大约 4 个百分点。推理虽不是 V4 的绝对强项,但已经是开源模型的最高水平了。
知识和事实性,V4 进步最大,但短板也最扎眼。SimpleQA-Verified 从 V3.2 的 28.3 飙到 57.9,直接翻倍。中文知识更猛,84.4 几乎追平 Gemini 的 85.9。然而,英文事实准确性 57.9 与 Gemini 的 75.6 之间,还有将近 18 个百分点的差距。
Agent 能力,SWE Verified 拿到 80.6,和 Opus 4.6 几乎打平,MCPAtlas 73.6 也仅差 0.2 个百分点。但 Terminal Bench 2.0 只有 67.9,差了 GPT-5.4 将近 7 个点。看来,复杂的终端操作和工具编排任务上仍有提升空间。
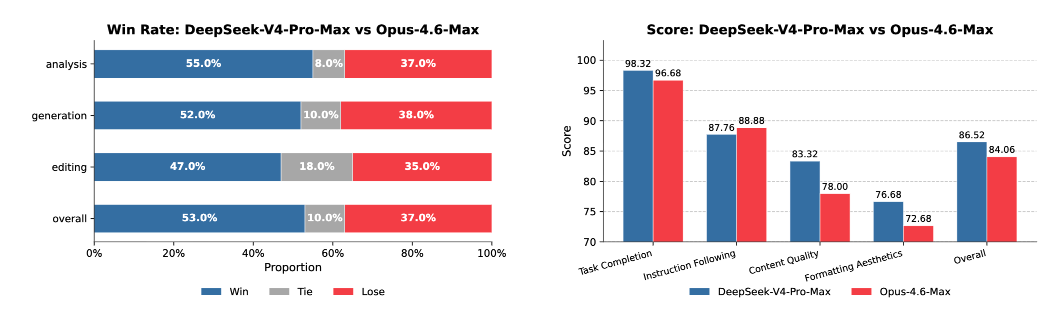
长上下文质量,Opus 4.6 依然是王者。MRCR 1M 上 Opus 拿到 92.9,V4 为 83.5;CorpusQA 1M 里 Opus 是 71.7,V4 为 62.0。V4 虽然在效率上赢了(仅需 27% FLOPs),但在质量上仍有差距。这本质上是一个效率对精度的 trade-off。值得一提的是,前端审美也有了极大提升。
6. 最后
API 调用文档: https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
价格方面:
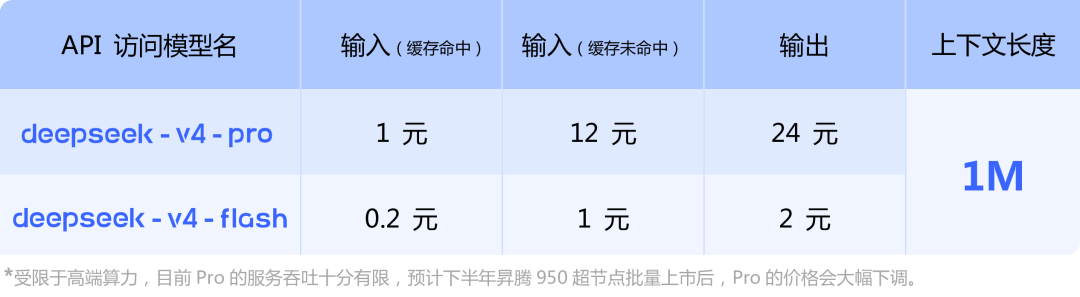
它依然是开源 MIT 协议,商用免费,修改自由,分发无限制。对于国内企业来说,一个代码能力全球第一、知识能力逼近第一梯队、支持百万上下文且采用 MIT 协议的模型,在做部署选择时几乎无需犹豫。
V4 的意义在于,开源模型再次在核心能力上站到了第一梯队。但它的短板我们也得清醒地看到:事实准确性与 Gemini 尚有近 18 个百分点的差距,长上下文质量距离 Opus 还有距离,复杂 Agent 任务同样存在提升空间。
最后,用 DeepSeek 发布文章里的一句话来结尾:“不诱于誉,不恐于诽,率道而行,端然正己。”在飞速演进的 AI 浪潮中,这种态度或许比一时的跑分更值得玩味。在云栈社区,我们也期待更多像这样务实的开源项目涌现,共同推动技术进步。
 发表于 2026-4-24 21:22:42
|
查看: 211|
回复: 0
发表于 2026-4-24 21:22:42
|
查看: 211|
回复: 0
