刚刚,DeepSeek 宣布全新系列模型 DeepSeek-V4 预览版正式上线,并同步开源!该模型在 Agent 能力、世界知识和推理性能三个维度上均达到国内与开源领先水平,支持百万字超长上下文。
秉承一贯的开放精神,本次发布按模型大小分为两个版本:

- DeepSeek-V4 模型开源链接:
https://huggingface.co/collections/deepseek-ai/deepseek-v4
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
- DeepSeek-V4 技术报告:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
Pro 版本面向高性能,Flash 版本主打性价比。API 服务已同步更新,通过修改 model_name 为 deepseek-v4-pro 或 deepseek-v4-flash 即可调用。

从技术报告来看,DeepSeek V4 并非只在 NVIDIA 体系内优化,而是将细粒度专家并行(EP)方案同时在 NVIDIA GPU 和华为 Ascend NPU 上完成验证,说明其推理路径已具备跨算力平台适配能力。但当前开源层面仍主要基于 CUDA 的 MegaMoE 和 DeepGEMM,底层深度绑定 NVIDIA 工具链。此外,官方 API 页面提到,受限于高端算力,V4-Pro 服务吞吐有限,预计下半年昇腾 950 超节点批量上市后,Pro 价格将大幅下调——DeepSeek 一边在 CUDA 生态内极致优化,一边为华为 Ascend 等多算力环境预留空间,逐步解耦模型运行时与单一硬件依赖。
DeepSeek-V4-Pro:性能比肩顶级闭源模型
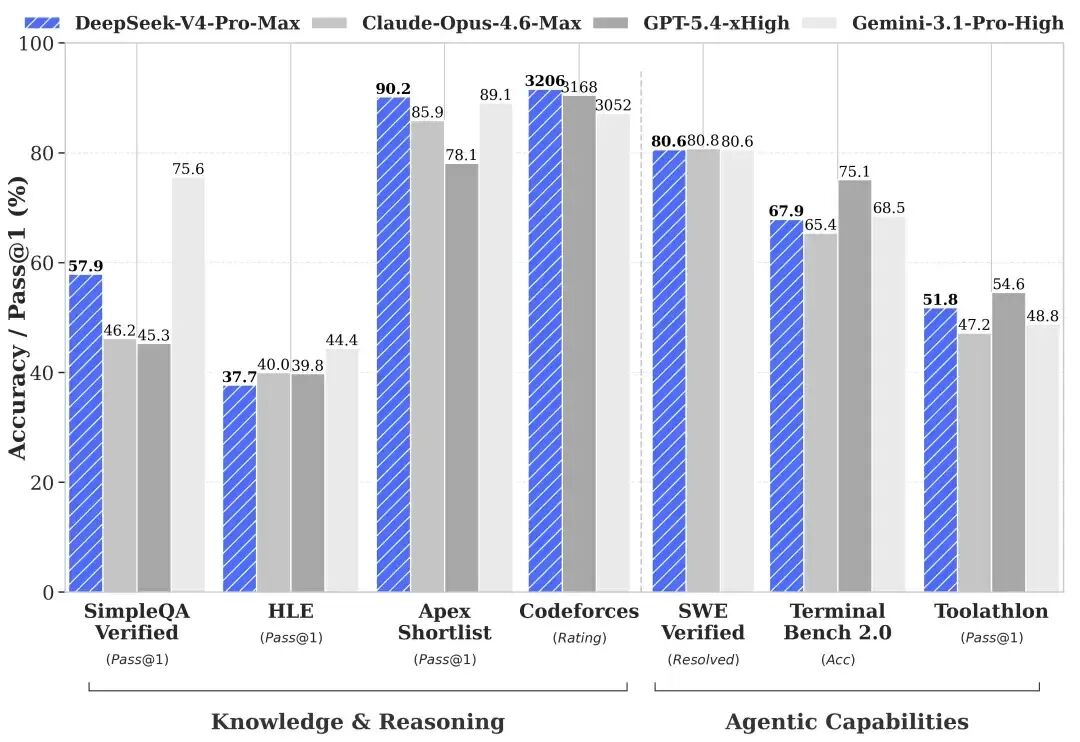
- Agent 能力大幅提高:相比前代显著增强。在 Agentic Coding 评测中,V4-Pro 达到当前开源模型最佳水平,其他 Agent 相关评测同样优异。目前该模型已成为公司内部员工使用的 Agentic Coding 模型,体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在差距。
- 丰富的世界知识:大幅领先其他开源模型,仅稍逊于顶尖闭源模型 Gemini-Pro-3.1。
- 世界顶级推理性能:在数学、STEM、竞赛型代码测评中,超越所有公开评测的开源模型,达到比肩顶级闭源模型的水平。
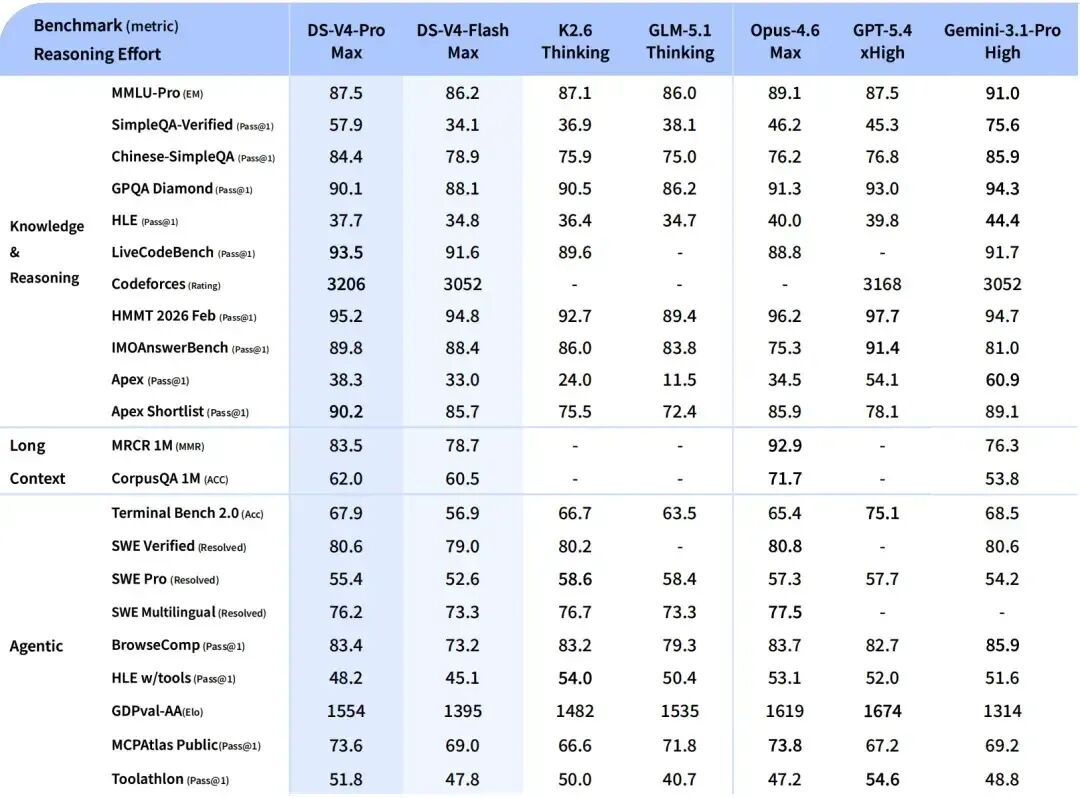
DeepSeek-V4-Flash:主攻性价比
- 世界知识储备稍逊于 Pro,但展现接近的推理能力。由于参数和激活更小,V4-Flash 能提供更快捷、经济的 API 服务。
- 在 Agent 测评中,简单任务与 Pro 旗鼓相当,高难度任务仍有差距。
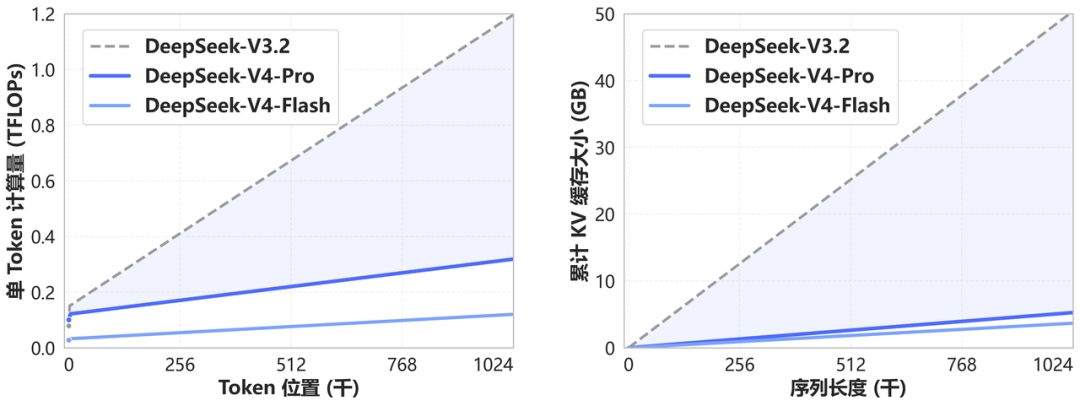
百万上下文已成标配
DeepSeek-V4 开创了全新的注意力机制,在 token 维度进行压缩,结合 DSA 稀疏注意力(DeepSeek Sparse Attention),实现全球领先的长上下文能力,相比传统方法大幅降低计算和显存需求。1M(一百万)上下文将是 DeepSeek 所有官方服务的标配。
上图展示了 DeepSeek-V4 和 DeepSeek-V3.2 的计算量与显存容量随上下文长度的变化。
值得注意的是,DeepSeek-V4 针对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流 Agent 产品进行了适配优化,在代码任务、文档生成等方面均有提升。下图为 V4-Pro 在某 Agent 框架下生成的 PPT 内页示例:
目前,DeepSeek API 已同步上线 V4-Pro 与 V4-Flash,支持 OpenAI ChatCompletions 接口与 Anthropic 接口。访问新模型时,base_url 不变,model 参数改为 deepseek-v4-pro 或 deepseek-v4-flash。
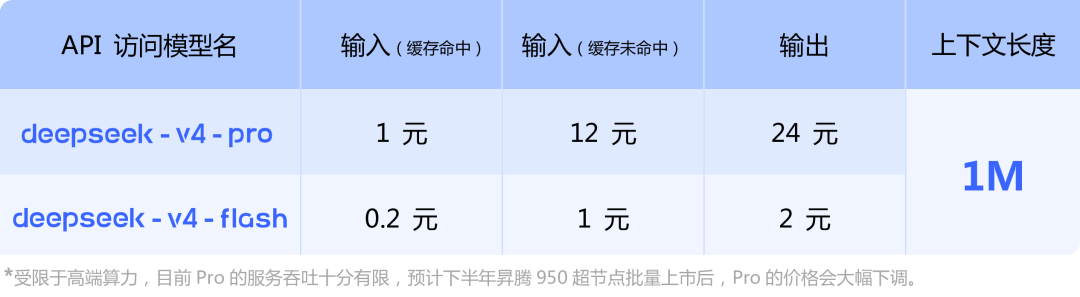
V4-Pro 和 V4-Flash 均提供 1M 上下文,同时支持非思考模式与思考模式。后者可通过 reasoning_effort 参数调节思考强度(high 或 max)。复杂 Agent 任务建议启用思考模式并设强度为 max。具体调用方式及参数设置请查阅 API 文档。
注意:旧接口中的 deepseek-chat 和 deepseek-reasoner 将于 2026 年 7 月 24 日停止使用。过渡期内,它们分别指向 deepseek-v4-flash 的非思考模式与思考模式。
拆解关键技术创新
混合注意力机制
CSA(压缩稀疏注意力)与 HCA(高度压缩注意力)是 V4 系列最关键的创新之一。传统注意力机制中每个 token 需与所有历史 token 计算注意力,导致计算量随序列长度平方增长。V4 设计两种互补的压缩注意力架构:
- CSA:将每 m 个 token 的 KV 缓存压缩为 1 个条目(m=4),每个查询 token 仅关注 k 个压缩后的 KV 条目(k=512~1024),引入 Lightning Indexer 高效选出重要压缩块,整体序列长度压缩至 1/m。
- HCA:采用更激进压缩率(m'=128),每 128 个 token 压缩为 1 个,保持稠密注意力,适用于信息密度较低场景。CSA 与 HCA 交错堆叠,兼顾效率与表达力。
工程亮点:支持 RoPE 部分位置编码(仅最后 64 维),维持相对位置信息;引入滑动窗口注意力分支捕获局部依赖;采用 Attention Sink 技术允许注意力得分总和不为 1。
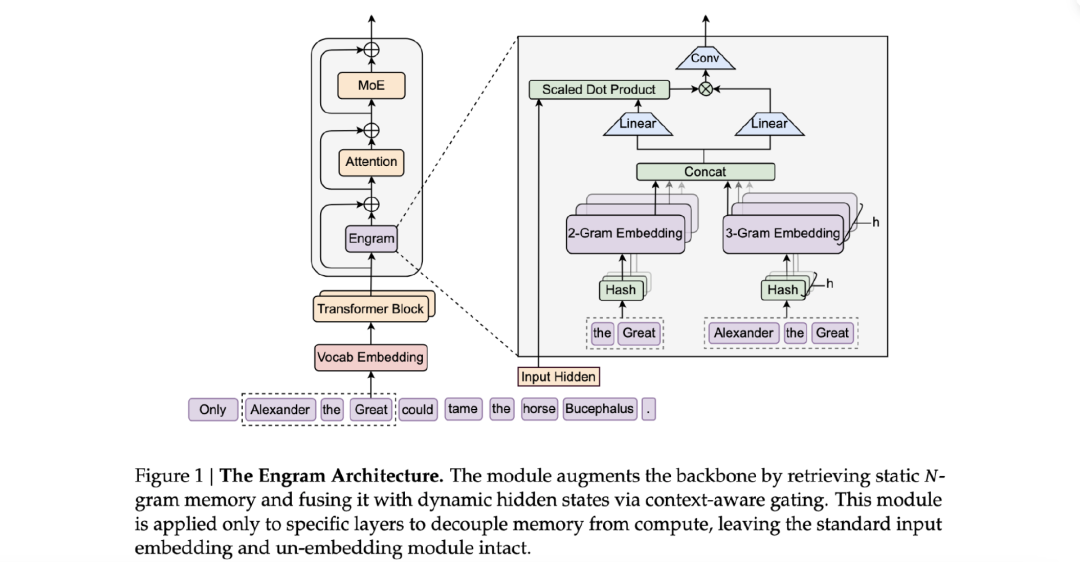
此外,Engram 和 mHC 两个版块的创新同样关键。
Engram 记忆模块
Engram(条件记忆模块)是 DeepSeek 创始人梁文锋署名论文的核心概念。它解决传统 Transformer 将记忆与推理混为一谈的根本问题——模型既要用注意力“检索”知识,又需要用注意力“推理”。Engram 将模型能力从连续的神经计算转移到确定性的哈希查找:将固定、需要记忆的模式(如实体名、固定搭配)存入类似“字典”的查找表,实现 O(1) 复杂度快速调用,无需消耗大量算力去“计算”记忆。这使得模型能将注意力资源释放出来,专注于复杂组合与推理任务。实验阶段,集成 270 亿参数 Engram 的模型,在同等参数和浮点运算次数下性能超过纯 MoE 模型。

mHC 流形约束超连接
mHC(流形约束超连接,Manifold-Constrained Hyper-Connections)解决极深网络训练不稳定性问题。传统 Transformer 堆叠到很深时易出现梯度爆炸或消失等信号 degradation 问题。通过将连接矩阵约束在双随机矩阵流形上,mHC 确保信号增益在每一层保持稳定(约 1.6 倍),让深层表示得以保留,使训练更深更强的模型成为可能,将计算利用率从行业平均约 60% 提升到 85% 以上,同时减少 30%+ 的原始计算依赖。
Muon 优化器:万亿参数新训练范式
V4 首次在万亿参数 MoE 模型上大规模采用 Muon 优化器。团队设计了一套混合 Newton-Schulz 迭代策略:前 8 步使用快速收敛系数,后 2 步切换为稳定系数,在正交化精度与收敛速度间取得最优。为解决 ZeRO 并行与 Muon 需要完整梯度矩阵的矛盾,设计了混合 ZeRO 分配策略——稠密参数限制并行度并用背包算法负载均衡,MoE 专家参数独立展平后均匀分布。MoE 梯度在同步前以随机舍入方式量化到 BF16,通信量减半;同时采用“all-to-all + 本地 FP32 求和”规避低精度加法器的累积误差。
FP4 量化:无损压缩与推理加速
V4 在 MoE 专家权重和 CSA 索引器的 QK 路径上应用 FP4 量化感知训练。关键发现:FP4 到 FP8 的解量化是无损的——因为 FP8 拥有更大动态范围,FP4 子块的细粒度尺度信息可被完全吸收。整个量化流程可无缝复用现有 FP8 训练框架。在推理和 RL rollout 阶段,使用真实 FP4 权重,实现实时显存节省和计算加速。索引器分数的 FP32→BF16 量化带来 2 倍加速,同时保持 99.7% 召回率。
专家并行:通信-计算深度融合
MoE 模型的专家并行受限于跨节点通信。传统方案中 Dispatch 和 Combine 阶段是纯通信瓶颈。V4 创新地将专家切分为“波”——每个波包含一小部分专家。波内专家通信完成后,计算立即开始,无需等待其他专家。稳态下,当前波的计算、下一波的 token 传输、已完成专家的结果发送三者同时进行。该细粒度流水线在 NVIDIA GPU 和华为昇腾 NPU 上实现 1.5~1.73 倍加速,在 RL rollout 等高敏感场景下可达 1.96 倍。团队还提出硬件设计建议:当前每 GBps 互联带宽足以覆盖 6.1 TFLOP/s 计算需求,盲目增加带宽会导致收益递减。
确定性内核:大规模训练可复现性保障
训练万亿参数模型时,非确定性行为可能导致难以调试的 loss 尖峰。V4 实现了全面的批量不变性和确定性:任何 token 的输出不因 batch 内位置而改变;每次运行的梯度累积顺序保持一致。技术难点包括:注意力反向传播放弃 split-KV 方案,改用双核策略;MoE 反向传播通过 rank 内 token 顺序预处理加 rank 间 buffer 隔离解决竞争;mHC 中小矩阵乘法(输出维度仅 24)使用 split-k 时,先输出各 split 部分再通过专用核确定性归约。这些工程打磨使大规模训练可复现性达到新高度。
TileLang DSL:高性能内核高效开发
为支撑数百个融合核的开发,V4 团队采用 TileLang 领域特定语言,并实现主机代码生成——将数据类型、形状约束等元数据嵌入生成的 launcher 中,运行时验证开销从数十微秒降至 1 微秒以下。同时集成 Z3 SMT 求解器进行形式整数分析,支持向量化优化、屏障插入等高级编译优化,严格对齐数值精度与 CUDA 工具链,保证 bit 级可重现性。
训练稳定性:预知路由与 SwiGLU 钳位
万亿 MoE 模型训练稳定性是一大挑战。V4 识别出 loss 尖峰与 MoE 层异常值的强相关性,且路由机制会加剧异常值。为此设计了预知路由:在 step t 使用历史参数 θ_{t-Δt} 计算路由索引,当前参数仅做特征计算,通过管线执行与通信重叠将额外开销控制在 20%,且仅在尖峰发生时动态激活。配合 SwiGLU 钳位(线性分量钳位到[-10,10],门控分量上界钳位到 10),有效消除了异常值且不影响性能。
框架层优化:长上下文 RL 落地
V4 的框架优化覆盖训练与推理全流程:
- 上下文并行适配:两阶段通信策略解决压缩边界跨 rank 问题,每个 rank 发送最后 m 个未压缩 KV,all-gather 后融合为完整序列。
- 张量级激活检查点:扩展自动微分框架,支持对单个张量标注重计算,框架自动计算最小重计算子图,释放显存并复用指针。
- 异构 KV 缓存管理:分离状态缓存(SWA+未就绪压缩 token)和经典 KV 缓存,支持磁盘存储实现共享前缀请求的零重复预填充。
后训练范式:同策略蒸馏
V4 后训练采用“独立专家训练→同策略蒸馏”两阶段范式。首先针对数学、代码、Agent、指令跟随等领域独立训练专家模型,每个专家经过 SFT 和 GRPO 强化学习,支持三种推理模式(Non-think / Think High / Think Max)。特别地,使用生成式奖励模型替代传统标量奖励模型,将 actor 与 judge 角色统一,将推理能力内化到评估中。然后通过同策略蒸馏将十多个专家融合到统一模型。采用逆向 KL 散度作为目标,使用全词表 logit 蒸馏(而非 token 级 KL 估计),梯度估计更稳定。工程上,教师权重 offload 到分布式存储,仅缓存最后一层 hidden states,训练样本按教师索引排序确保每个教师头只加载一次,使得万亿参数级别多教师蒸馏成为现实。
DeepSeek-V4-Pro-Max(最大推理强度模式)在多项基准上重新定义了开源模型天花板:
- 知识:SimpleQA-Verified 达到 57.9%,远超前代开源模型(约 30%)
- 编程:Codeforces Elo 3206 分,排名人类第 23,首次有开源模型在该任务上追平 GPT-5.4
- Agent:SWE-Verified 80.6%,接近 Claude Opus 4.6 的 80.8%;Terminal Bench 2.0 67.9%,与 GPT-5.4 的 68.5% 持平
- 中文任务:功能性写作以 62.7% 胜率优于 Gemini 3.1 Pro,创意写作在质量维度达到 77.5% 胜率
V4-Flash-Max 以极低成本实现了与 GPT-5.2 和 Gemini 3.0 Pro 相当的推理性能,证明了高效架构的可行性。
过去一年 DeepSeek 重要发布回顾
2025 年除夕夜,DeepSeek 低调发布 DeepSeek-R1,该模型在数学、代码编写和逻辑推理方面表现卓越,性能直追 OpenAI o1,并通过 MIT 协议开源权重和代码,直接重塑了全球开源与商业大模型竞争格局。
- 3 月 25 日:DeepSeek V3 小版本升级(V3-0324),聚焦体验优化和性能提升。
- 5 月 28 日:DeepSeek R1 小版本升级(DeepSeek-R1-0528),支持 128K 超长上下文,中文能力登顶 SuperCLUE。
- 8 月 21 日:DeepSeek-V3.1 发布,混合推理架构,同时支持思考与非思考模式。
- 9 月 22 日:DeepSeek-V3.1-Terminus 版本,优化语言一致性与 Agent 能力。
- 9 月 29 日:DeepSeek-V3.2-Exp 实验性版本,引入 DeepSeek Sparse Attention。
- 12 月 1 日:DeepSeek-V3.2 和 V3.2-Speciale 正式发布,Speciale 模型斩获 IMO 2025、CMO 2025、ICPC World Finals 2025、IOI 2025 金牌。
- 2026 年 1 月 13 日:开源论文与模块 Engram(Conditional Memory via Scalable Lookup),提出“查—算分离”机制。
参考链接:
DeepSeek-V4 预览版:迈入百万上下文普惠时代
声明:本文为 InfoQ 整理,不代表平台观点,未经许可禁止转载。
 发表于 2026-4-24 18:11:32
|
查看: 247|
回复: 0
发表于 2026-4-24 18:11:32
|
查看: 247|
回复: 0
