等了很久的 DeepSeek-V4,终于来了。
4 月 24 日,DeepSeek 正式发布了 V4 预览版并同步开源。自从去年 1 月 R1 发布以来,这家公司已经沉寂了 15 个月,期间经历了多次推迟——从原定的 2 月推到 3 月,再到 4 月下旬。这段时间里,OpenAI 发了 GPT-5.4 和 GPT-5.5,Anthropic 迭代到了 Claude Opus 4.7,Google 推出了 Gemini 3.1 Pro,腾讯混元也刚刚发布了 Hy3 preview。竞争对手们都没闲着,市场对 DeepSeek 的耐心也在一点点消磨。
但 DeepSeek 这次拿出来的东西,确实有料。
百万上下文,从此是标配
V4 最引人注目的变化,是百万字超长上下文成为所有官方服务的标配。
这句话值得拆开来看。过去,百万级别的上下文窗口要么只有少数顶级闭源模型才有(比如 Gemini 的 1M 上下文),要么虽然技术上支持但实际使用成本很高。DeepSeek 这次做的事情,是通过架构层面的创新把这个能力的门槛打了下来。
具体来说,V4 开创了一种全新的注意力机制,在 token 维度进行压缩,结合他们自研的 DSA 稀疏注意力技术(DeepSeek Sparse Attention),大幅降低了长上下文场景下的计算量和显存需求。从官方给出的对比图来看,V4 在处理超长上下文时的资源消耗相比前代 V3.2 有了非常显著的下降。
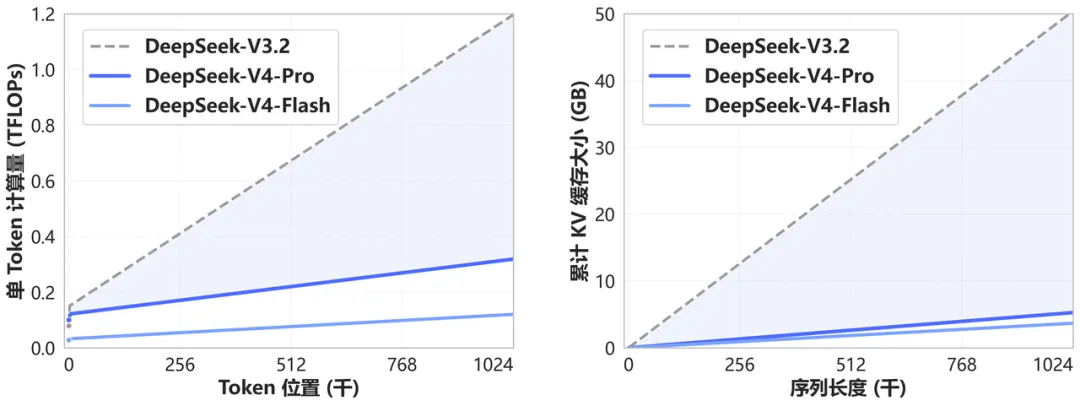
这意味着什么呢?意味着以后你可以一次性把一整本书、一整个代码仓库、几个月的会议记录丢给模型,让它在完整的上下文中理解和工作。这对于需要处理大量文档的知识工作者、需要理解完整代码库的开发者来说,是一个实质性的能力跃升。
更重要的是,DeepSeek 说的是「标配」。这个词的分量在于,它不是一个高端版本才有的特权功能,而是所有用户都能享受到的基础能力。当百万上下文变成基础设施级别的东西,很多原来不可能的工作流就变得可能了。
两个版本,各有定位
V4 分为两个版本:Pro 和 Flash。

V4-Pro 是旗舰版。在 Agent 能力方面,它在 Agentic Coding 评测中达到了当前开源模型的最佳水平。DeepSeek 自己的员工已经在日常工作中用它做编程智能体了,内部反馈是使用体验优于 Anthropic 的 Sonnet 4.5,交付质量接近 Claude Opus 4.6 的非思考模式,但和 Opus 4.6 的思考模式还有差距。
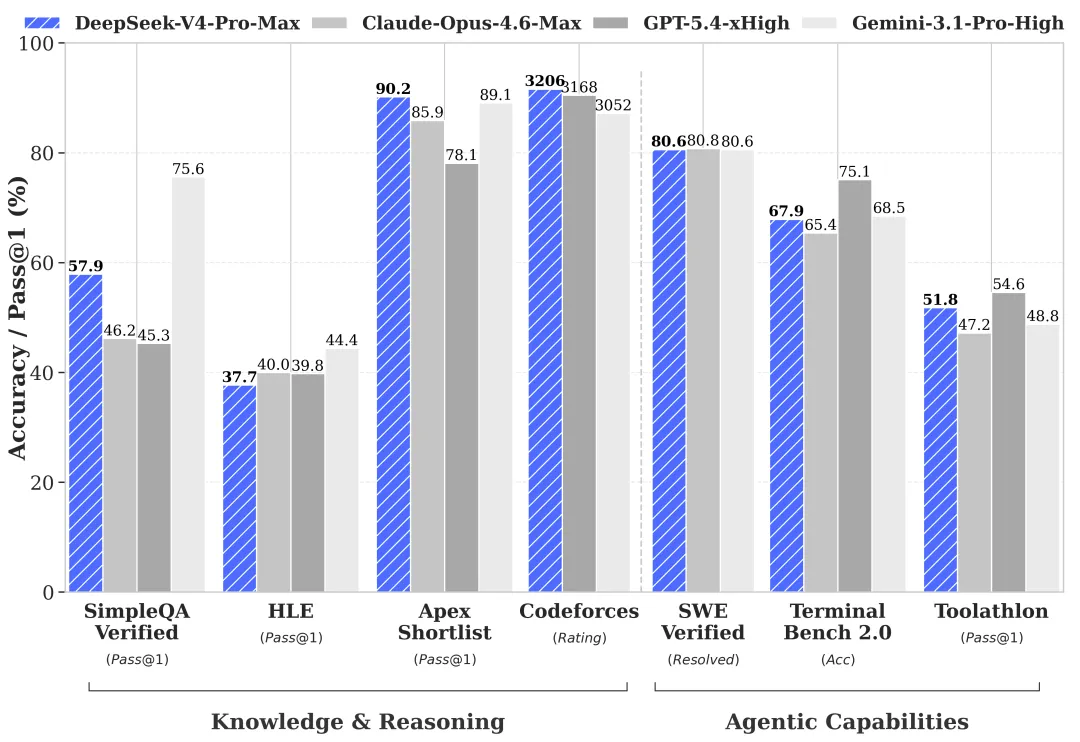
这个表述很有意思。DeepSeek 没有说自己是最强的,它很坦诚地承认和 Opus 4.6 思考模式之间还有距离。但考虑到这是一个开源模型,能做到接近顶级闭源模型的非思考模式,已经是一个相当了不起的成绩了。据 The Information 的报道,V4 在 DeepSeek 的内部测试中甚至在某些维度上超过了 Claude 和 GPT 系列模型,而 DeepSeek 一贯的风格是低调而非夸大。
世界知识方面,V4-Pro 大幅领先其他开源模型,仅稍逊于 Google 的 Gemini-Pro-3.1。推理性能方面,在数学、STEM、竞赛型代码的测评中,V4-Pro 超越了所有已公开评测的开源模型,达到了比肩世界顶级闭源模型的水平。
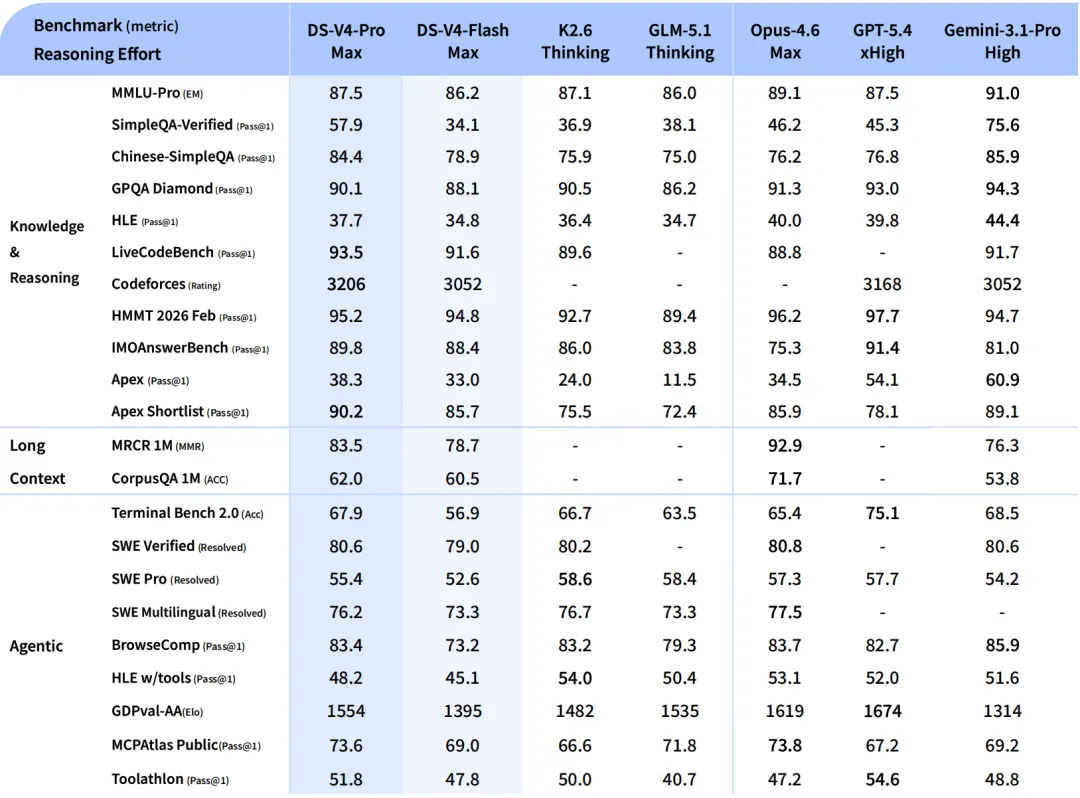
V4-Flash 是轻量版,参数更小,激活更少,速度更快,价格更便宜。它的推理能力接近 Pro,但世界知识储备稍弱一些。在简单的 Agent 任务上和 Pro 旗鼓相当,复杂任务上有差距。对于大多数日常使用场景来说,Flash 可能是性价比更高的选择。
这种大小搭配的产品策略其实很聪明。不同的任务对模型能力的要求差异很大,写一封邮件和解一道竞赛数学题需要的算力完全不在一个量级。让用户根据具体需求选择合适的版本,既能满足高端需求,又能控制日常使用的成本。
Agent 能力:竞争的新焦点
V4 这次特别强调了 Agent 能力的提升,而且做了一件很有意思的事情:专门针对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流 Agent 产品进行了适配和优化。
这个动作透露了一个重要的行业信号。现在的 AI 模型竞争,焦点正在从「跑分谁最高」转向「在真实的 Agent 场景里好不好用」。一个模型在 benchmark 上的分数再漂亮,如果接入实际的编程智能体框架后体验不好,开发者也不会买账。DeepSeek 显然看到了这一点,所以在模型层面就做了针对性的适配。
这也说明了一个趋势:AI 模型正在从「通用工具」向「专业基础设施」演进。过去大家比的是模型本身的通用能力,现在开始比的是模型在具体工作流中的表现。你的模型能不能和 Claude Code 配合得好?能不能在 OpenClaw 的框架下稳定输出?这些实际场景中的兼容性和可靠性,正在变得和 benchmark 分数一样重要。
对于开发者来说,这意味着选择模型的标准也在变化。以前可能主要看评测分数和价格,现在还要看它和你正在使用的工具链配合得怎么样。
开源的力量:价格屠夫再次出手
DeepSeek 的一贯风格是开源加低价,这次也不例外。
V4 的权重已经同步在 Hugging Face 和 ModelScope 上开源,技术报告也一并公开。这意味着任何人都可以下载模型权重,在自己的硬件上部署和运行,不需要依赖 DeepSeek 的 API 服务。
API 方面,两个版本都已上线,支持 OpenAI ChatCompletions 接口和 Anthropic 接口两种格式,切换起来非常方便。两个版本都同时支持思考模式和非思考模式,思考模式还可以通过 reasoning_effort 参数调节强度(high 和 max 两档)。对于复杂的 Agent 场景,官方建议使用思考模式并设置强度为 max。
值得注意的是,旧的 API 接口名 deepseek-chat 和 deepseek-reasoner 将在三个月后(2026 年 7 月 24 日)停用。目前这两个名字分别指向 V4-Flash 的非思考模式和思考模式。如果你在用 DeepSeek 的 API,记得提前做好迁移。
根据此前的信息,DeepSeek V4 的 API 定价预计会比 GPT 和 Claude 系列便宜 10 到 50 倍。这个价格差距如果成立,对整个行业的定价体系又是一次冲击。当一个性能接近顶级闭源模型的开源模型,以十分之一甚至更低的价格提供服务,那些依赖高定价维持利润的闭源模型厂商就不得不重新思考自己的商业模式了。
不过也有一个现实的约束。DeepSeek 自己也承认,受限于高端算力,目前 Pro 版本的服务吞吐十分有限。他们预计下半年昇腾 950 超节点批量上市后,Pro 的价格会大幅下调。这说明即便是 DeepSeek,在算力供给上也面临着瓶颈。
架构创新:V3 和 R1 的统一
从技术架构的角度来看,V4 做了一件很有意义的事情:把之前 V3 系列(通用对话)和 R1 系列(推理)合并成了一个统一的模型。
过去 DeepSeek 有两条产品线,V3.X 负责日常对话和通用任务,R1 负责需要深度推理的场景。用户需要根据任务类型选择不同的模型,这在使用体验上多少有些割裂。V4 把两种能力整合到了一起,通过思考模式和非思考模式的切换来适应不同场景。简单任务用非思考模式,快速响应;复杂任务切到思考模式,深度推理。
这个统一的趋势其实在整个行业都在发生。OpenAI 的 GPT-5 系列也在做类似的事情,把推理能力和通用能力融合到同一个模型里。对用户来说,这是好事。你不再需要记住哪个模型擅长什么,一个模型就能覆盖大部分场景,只需要调节一下参数就行。
据泄露的信息,V4 的总参数量达到了万亿规模(约 1 万亿),但通过 MoE(混合专家)架构,每个 token 实际激活的参数大约只有 370 亿,这让推理成本保持在了一个中等规模模型的水平。用大白话说就是:模型很大很聪明,但跑起来并不贵。
放在行业里看:开源正在改变游戏规则
把 DeepSeek-V4 放到整个行业的背景下来看,有几个趋势值得关注。
第一,开源模型和闭源模型的差距正在快速缩小。一年前,开源模型和 GPT-4、Claude 3 之间还有明显的代差。现在 V4-Pro 已经能在多个维度上接近甚至比肩顶级闭源模型了。这个追赶速度比很多人预期的要快。
第二,百万级上下文正在成为行业标配。Google 的 Gemini 最早把上下文窗口推到了 1M,现在 DeepSeek 也跟上了,而且通过架构创新把成本打了下来。可以预见,其他模型厂商也会很快跟进。当所有模型都支持百万上下文的时候,那些依赖长上下文能力的应用场景就会真正爆发。
第三,Agent 能力正在成为模型竞争的核心战场。V4 专门为主流 Agent 框架做适配,GPT-5.5 强调在 Codex 里的工程能力,Claude 系列一直在 Cursor 等编程工具中占据主导地位。模型厂商们都意识到了,未来的竞争不只是模型本身的能力,还包括模型在实际工具链中的表现。
第四,中国 AI 公司正在用开源加低价的策略重塑全球竞争格局。DeepSeek 的定价策略对 OpenAI 和 Anthropic 构成了持续的压力。当一个开源模型能提供 90% 的能力但只收 10% 的价格,很多对成本敏感的企业和开发者就会重新评估自己的选择。
这场竞争还远没有结束。DeepSeek 说这次发布的是「预览版」,意味着正式版可能还会有进一步的提升。而 OpenAI 刚刚发布了 GPT-5.5,Anthropic 也在持续迭代 Claude 系列。AI 模型的军备竞赛正在进入一个新的阶段:每家都在同时比拼性能、效率、成本和生态。
对于我们普通用户来说,这场竞争带来的最直接好处就是:更强的模型、更低的价格、更多的选择。百万上下文、Agent 能力、开源可部署,这些曾经只属于少数人的能力,正在变成所有人都能触及的基础设施。
DeepSeek 在官方公告的最后引用了一句话:「不诱于誉,不恐于诽,率道而行,端然正己。」这句话出自荀子,大意是不被赞誉所诱惑,不被诽谤所恐惧,按照正道行事,端正自己。对于一家在 15 个月的沉寂中承受了大量市场压力的公司来说,这句话多少透露了一些心境。
而从结果来看,这 15 个月的等待,确实等来了一个值得认真对待的产品。
开源权重和本地部署
DeepSeek-V4 模型开源链接:
https://huggingface.co/collections/deepseek-ai/deepseek-v4
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
DeepSeek-V4 技术报告:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
作为 云栈社区 的成员,我们对这种推动技术民主化的开源发布总是格外关注。当模型权重、技术报告全部公开,开发者社区的创造力才会被真正释放出来。如果你也在尝试本地部署 V4 或者用它构建 Agent 工作流,欢迎来社区分享你的实践经验。
 发表于 2026-4-24 21:06:49
|
查看: 185|
回复: 0
发表于 2026-4-24 21:06:49
|
查看: 185|
回复: 0
