项目卡片
- 项目:browser-harness
- 状态:v0.1.0 / 4200+ Star / 5 天内爆发增长,来自 browser-use 团队
- 一句话判断:目前最"裸"的 AI 浏览器控制方案——不包装、不抽象,让 agent 直接通过 CDP 操控你的 Chrome,还能边跑边改自己的代码
800 行代码做了什么
我一般拿到这类项目先看依赖列表——pyproject.toml 里只有 browser-harness、cdp-use、websockets 三个。整个核心四个 Python 文件,加起来约 806 行:
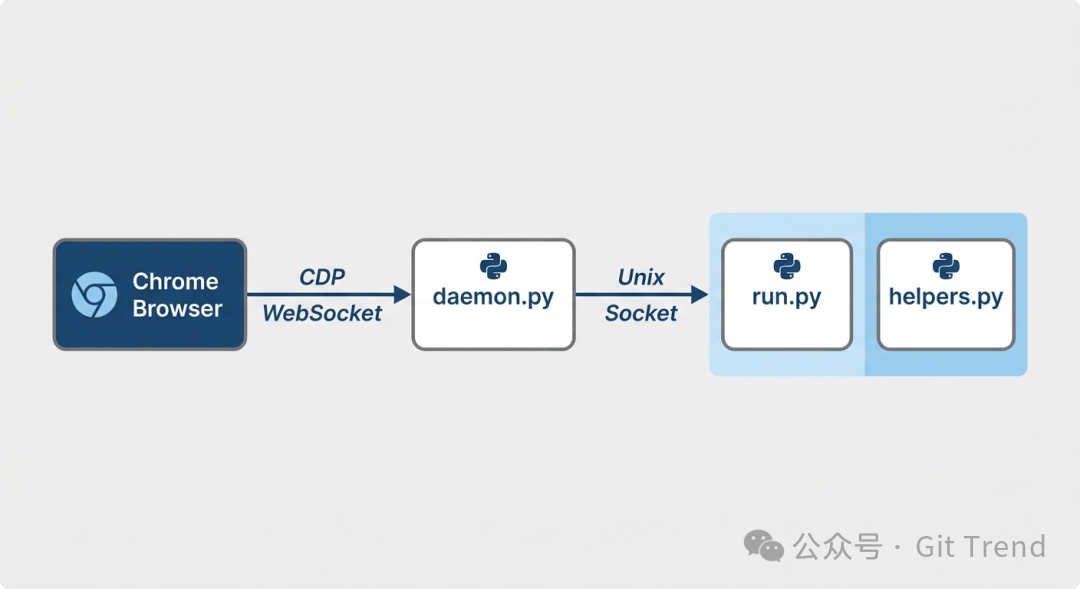
run.py(44 行)——入口,从 stdin 读 Python 代码,exec 执行helpers.py(216 行)——浏览器操作原语:导航、点击、截图、标签页管理daemon.py(248 行)——CDP WebSocket 持久连接,通过 Unix socket 对外服务admin.py(298 行)——daemon 生命周期管理、远程浏览器调配、profile 同步
架构是一条直线:Chrome 通过 CDP WebSocket 连接到 daemon,daemon 监听 Unix socket,run.py 通过 socket 发送 JSON 请求,拿到结果。没有消息队列,没有任务调度,没有中间层。
这个架构选择直接决定了它的使用方式。你不会 import 一个 SDK 来调用 API,而是直接写 Python 脚本,通过管道喂给 browser-harness:
browser-harness <<'PY'
new_tab("https://github.com/trending")
wait_for_load()
screenshot("/tmp/trending.png")
PY
所有的 helper 函数已经被 pre-import,所以这本质上就是一个"浏览器版 REPL"。
最重要的设计:连接你的 Chrome,不启动新的
browser-harness 的设计约束里有一条很明确:连接到用户正在运行的 Chrome,不要自己启动浏览器。
这意味着 agent 看到的是你真实登录态的浏览器——你的 cookies、你的 session、你的已打开标签页。不需要额外配置登录,不需要导出 cookies,不需要 Selenium 那套 driver 管理。
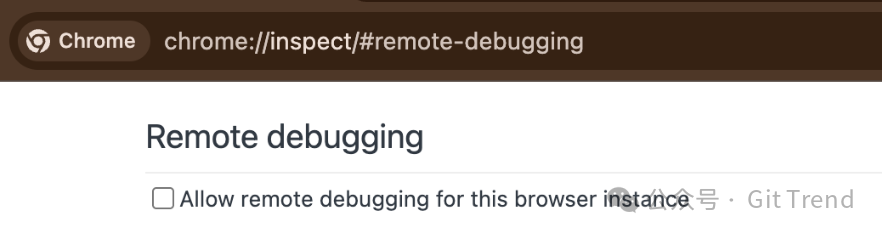
它通过读取 Chrome 的 DevToolsActivePort 文件来发现 CDP 端口。你只需要在 Chrome 里打开 chrome://inspect/#remote-debugging,勾选复选框,就可以了。而且这个设置是按 profile 粘滞的——勾一次,以后每次启动 Chrome 都自动启用。
对于不想折腾本地 Chrome 的场景,它还提供了远程浏览器支持。Browser Use Cloud 免费层提供 3 个并发浏览器,不绑信用卡。启动远程浏览器只需要:
start_remote_daemon("work")
daemon 会自动连接到云端 CDP,把浏览器实例的生命周期管理好——停止时自动持久化 profile 状态。
"自愈"到底是什么意思
这是 browser-harness 最有意思的概念,也是它和其他浏览器自动化工具本质不同的地方。
传统做法是框架预设好所有 API,agent 只能调框架提供的函数。框架里没有"上传文件",agent 就卡住了。
browser-harness 换了个思路: agent 可以直接编辑 helpers.py。
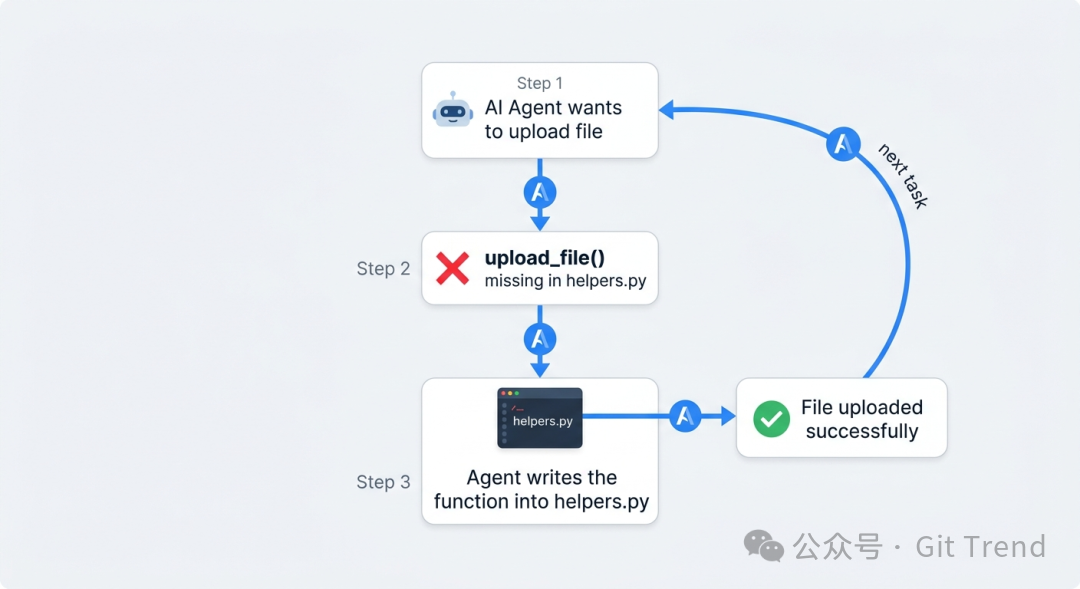
README 里给了个例子:
agent 想上传一个文件
→ helpers.py 里没有 upload_file()
→ agent 自己写了这个函数到 helpers.py
→ 文件上传成功
这不是比喻。因为 run.py 的本质就是 exec,agent 拥有完整的 Python 执行能力。它可以在运行时修改 helpers.py,下一次调用就能用上新写的函数。
我看到这个设计的第一反应是"这能跑起来吗"。但仔细想了一下,agent 本来就有文件读写能力,browser-harness 只是顺水推舟把"改自己"这件事合法化了。
这个设计的哲学是:不需要预先枚举所有浏览器操作,agent 遇到什么就写什么。这也是为什么 helpers.py 到现在只有 216 行——不是功能不够,是没遇到的需求不需要提前写。
67 个 Domain Skills:agent 自己写的知识库
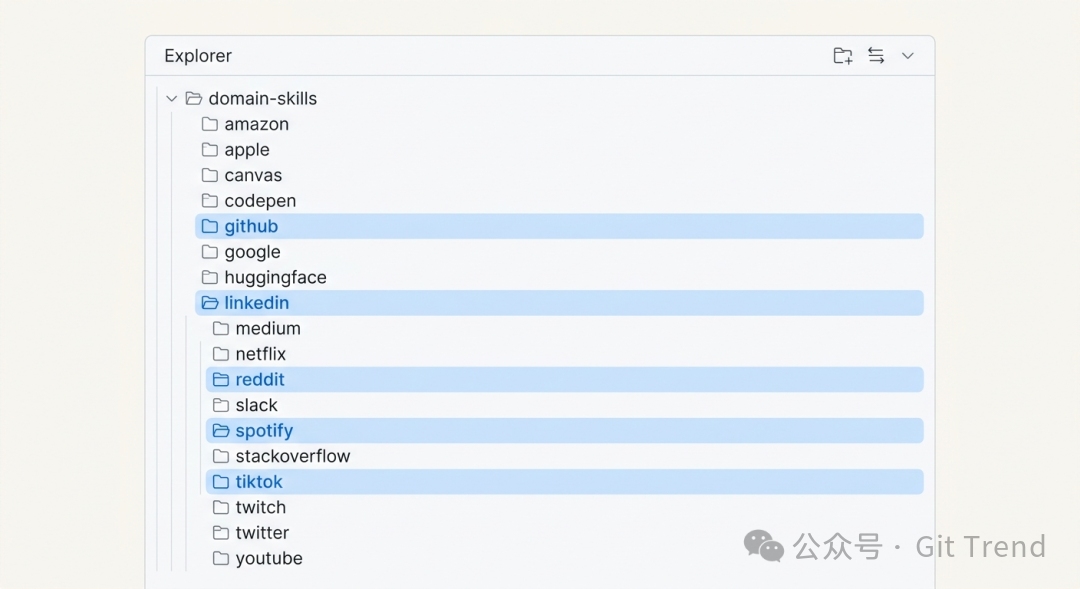
domain-skills/ 目录下有 67 个子目录,覆盖了 GitHub、LinkedIn、Amazon、Reddit、TikTok、Spotify 等主流网站。每个目录里是 markdown 文件,记录了这个网站的 selector、API 端点、交互坑点。
关键点在于:这些 skill 文件不是人写的,是 agent 在实际操作中自己生成并 PR 上来的。
SKILL.md 里明确说:
Skills are written by the harness, not by you. Just run your task with the agent — when it figures something non-obvious out, it files the skill itself.
比如 GitHub 的 scraping skill 记录了:trending 页面必须 wait(2) 因为 React hydration 在 readyState == 'complete' 之后才完成;star 数是带逗号的字符串如 "4,548" 需要解析。这些都是在实际操作中踩到的坑,agent 自动记录下来,下次就不会再踩。
这形成了一个正循环:agent 操作网站 → 踩坑 → 写 domain skill → 下次操作更快 → 踩更多坑 → 更多 skill。5 天里积累了 67 个 domain skill,增速不慢。
和传统工具有什么区别
browser-harness 不是要替代 Playwright 或 Selenium,它解决的是一个不同的问题:
| 维度 |
Playwright/Puppeteer |
browser-harness |
| 调用者 |
人类写的测试脚本 |
AI agent |
| 浏览器 |
启动独立实例 |
连接用户的 Chrome |
| API 设计 |
预设完整 API |
最小原语,agent 自己扩展 |
| 知识积累 |
人类写文档 |
agent 自己写 domain skills |
| 定位精度 |
DOM selector |
截图 + 坐标点击(compositor 级别) |
browser-harness 默认用坐标点击而不是 DOM selector。Input.dispatchMouseEvent 在 compositor 层面工作,可以穿透 iframe、shadow DOM、跨域边界。不需要处理 iframe 切换、shadow root 查找这些复杂情况,看截图点坐标就行了。
实际代价也写在 SKILL.md 里:agent 每次操作后必须重新截图验证结果,因为坐标点击没有 DOM 级别的反馈。操作密集的场景(比如连续填 20 个表单字段),token 消耗会明显高于 selector 方案。对于需要精确 DOM 操作的场景,它提供了 js() 执行任意 JavaScript 和 cdp() 调用原始 CDP 协议。
另一个实际限制:每个 browser-harness 调用是独立的 exec,脚本之间不共享状态。跨调用的状态要么通过文件系统,要么通过浏览器本身的 cookies/localStorage。
值不值得试
适合的场景:让 Claude Code / Codex 这类 coding agent 直接操控浏览器完成任务——填表、爬数据、发帖、自动化工作流。特别是那些需要登录态的场景,连接你的 Chrome 比任何 cookie 管理方案都省事。
不太适合:传统的自动化测试(用 Playwright)、需要高并发的爬虫(直接用 HTTP)、不想让 AI 碰自己浏览器的场景。
上手成本很低:
git clone https://github.com/browser-use/browser-harness
cd browser-harness
uv tool install -e .
browser-harness <<'PY'
new_tab("https://example.com")
print(page_info())
PY
唯一的前提是你需要打开 Chrome 的远程调试端口,就一个勾选框的事。
browser-use 团队同时维护着 88k star 的 browser-use[^2](Python 的 AI 浏览器自动化框架),browser-harness 可以理解为他们在探索的另一个方向:把框架去掉,让 agent 直接裸奔在 CDP 上。说实话,我不确定这个方向能跑多远——当 domain skill 积累到一定程度,很难说不会重新长出一个隐式框架。但至少现在,它的简洁和诚实值得一看。
[^1]: browser-harness: https://github.com/browser-use/browser-harness
[^2]: browser-use: https://github.com/browser-use/browser-use
 发表于 2026-4-24 18:08:21
|
查看: 268|
回复: 0
发表于 2026-4-24 18:08:21
|
查看: 268|
回复: 0
