
大模型推理只能靠外挂?陈丹琦团队连发两文打造训推双引擎,榨干内部试错轨迹,向内重塑复杂推理。
要让大模型在复杂任务中少犯错,目前最常见的操作依然高度依赖外力。
比如在训练阶段,利用 GPT-4 这样的前沿模型生成详尽的纠错步骤,以完成知识蒸馏。或者在推理阶段,启动海量并发采样,试图用多数投票机制把正确答案“砸”出来。
但这条路线正变得越来越昂贵,且难以持续。一旦失去了更强模型的监督指导,或者面对需要频繁调用工具的长周期智能体任务,这些传统手段往往会迅速失效。
普林斯顿大学陈丹琦团队近期连发的两项研究( SD-ZERO 与 AggAgent ),给出了一套向内挖掘的新解法。他们将重心从向外借力转向了对模型内部状态的深度回收。
这两项工作分别聚焦 post-training 与 test-time compute,二者共同印证了同一套底层逻辑,即模型自身在试错中产生的错误轨迹与中间步骤,并非应被抛弃的废料,而是重塑复杂推理最优质的养料。

训练引擎:SD-ZERO 实现自我密集监督

论文标题:
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
论文链接:
http://arxiv.org/abs/2604.12002
在数学证明、代码生成等可验证场景中,强化学习(如 RLVR)通常只能基于最终结果的正误给出二元奖励。
这种反馈信号过于稀疏,导致模型很难精确定位究竟是哪一步推理出现了偏差。而知识蒸馏虽然能提供精细到 token 级的反馈,却往往需要高度依赖外部的高质量标注或闭源模型。
针对这一瓶颈, SD-ZERO 尝试让单一模型同时扮演生成器(Generator)与修正器(Reviser),在内部完成监督信号的转化。
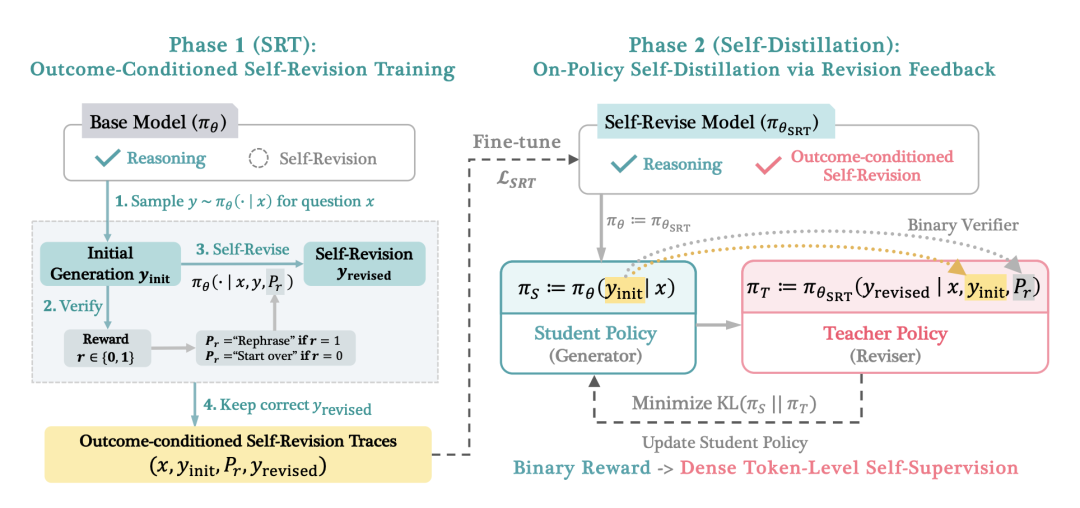
〓 SD-ZERO 两阶段训练概览:阶段一进行自我修正训练,阶段二通过修正反馈进行同策略自我蒸馏。
整个训练 pipeline 分为两个阶段:
自我修正训练 (SRT) 阶段的核心,是让模型学会评估并纠正自身的输出。模型首先针对问题采样多条初始回复,并通过外部验证器判定对错。
随后,模型会接收到不同的引导提示:若初始答案正确,则学习如何重新表述(Rephrase);若答案错误,则学习如何指出症结并重新开始(Start over)。
这些经过筛选的优质修正轨迹,成为了后续微调的原始语料。

〓 SD-ZERO 训练 pipeline 伪代码
SRT 阶段的优化目标函数兼顾了修正与生成:
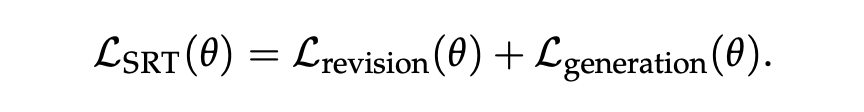
修正损失训练模型在给定初始输出与引导提示时,给出修正后的答案。
生成损失则确保模型在仅有输入的情况下,依然能输出包含完整思考过程的解答。
在随后的同策略自我蒸馏 (On-policy Self-distillation) 阶段, SD-ZERO 旨在将这种事后纠错的能力,内化为开口即对的直觉。
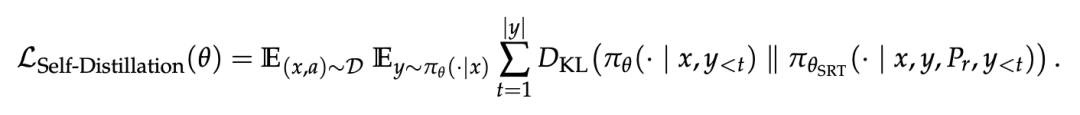
此时,学生模型(生成器)生成同策略响应,而冻结参数的 SRT 模型作为教师(修正器),基于学生的表现计算概率分布。
学生模型通过最小化与教师分布之间的 KL 散度,将原本“事后纠错”的本领转化为初次生成的准确度。

〓 Token 级 KL 奖励分布图:左侧显示错误轨迹的惩罚信号高度集中,右侧展示了修正器精准定位错误推理 token 的热力可视化。
这种自蒸馏模式带来了一个直观的变化,模型学会了在生成初期规避潜在陷阱,输出长度相比 SRT 阶段减少了约一半,大幅减少了因反复纠错而产生的冗余文本。
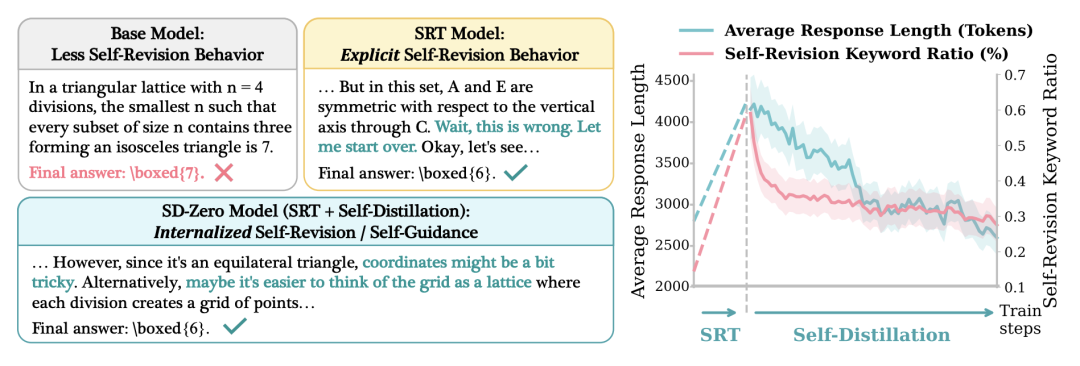
〓 随着自蒸馏进行,模型输出长度与显式修正关键词频率显著下降
在 Qwen3-4B-Instruct 和 Olmo-3-7B-Instruct 上的评估显示,在同等的 15K 样本预算下, SD-ZERO 在 AIME、MATH 等基准上全面优于 SFT、拒绝采样(RFT)、GRPO 以及自蒸馏微调(SDFT)。
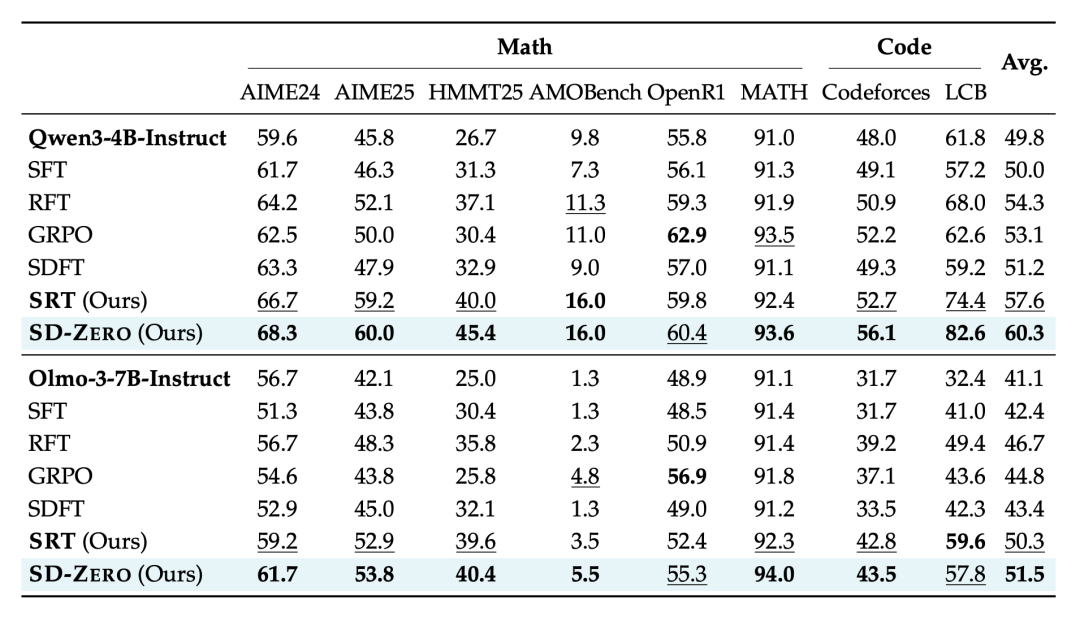
〓 SD-ZERO 与现有基线方法在各项数学与代码基准测试中的准确率对比
SD-ZERO 还支持迭代式自我演进。经过一轮自蒸馏后,更新后的模型在修正能力上同样获得了提升。
将其重新设定为教师模型进行下一轮蒸馏,能够获得超过 3% 的准确率增益。
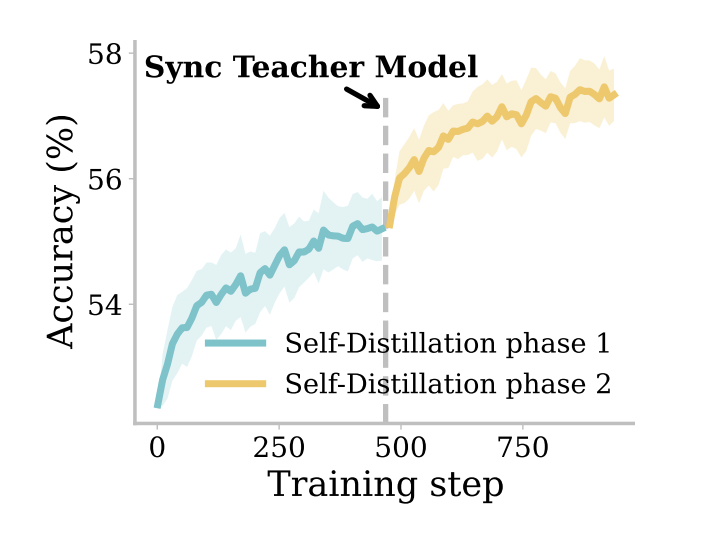
〓 迭代式自我演进曲线,展示了准确率随训练轮次持续增长的潜力

推理引擎:AggAgent 重构长轨迹聚合

论文标题:
Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks
论文链接:
http://arxiv.org/abs/2604.11753
在深度的智能体任务中,增加并行采样次数是换取准确率的常规做法。但在诸如网页搜索或深度调研等长周期任务中,轨迹往往包含数百个交互步骤和环境反馈。
传统的多数投票(Majority Voting)只核对最终答案,丢弃了宝贵的中间探索信息。摘要聚合(SummAgg)则容易抹除关键细节并带来庞大的计算负担。
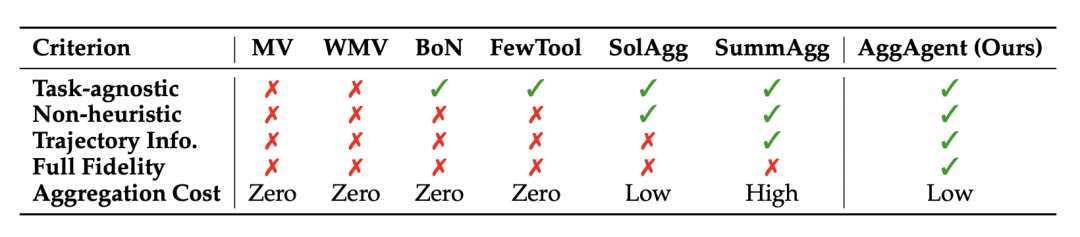
〓 AggAgent 与传统基线方法在信息利用率及聚合成本上的特性对比
AggAgent 的创新点在于,它不再将并行生成的候选轨迹看作静态长文本,而是将其视为一个可以被交互、被搜索的虚拟环境。它部署了一个专门的聚合智能体,通过主动调取局部信息来完成综合。

〓 三种聚合范式对比:解决方案聚合、摘要聚合以及主动运用内部工具的 AggAgent 聚合
为了避免上下文窗口溢出, AggAgent 采用按需检索策略,配备了四个内存级工具:
get_solution:获取所有轨迹的阶段性结论。search_trajectory:在特定轨迹内部执行关键词检索。get_segment:精确提取轨迹中关键步骤的原始状态。finish:提交最终合成的方案及聚合理由。
这种设计让 AggAgent 具备了识别少数派正确答案的能力。
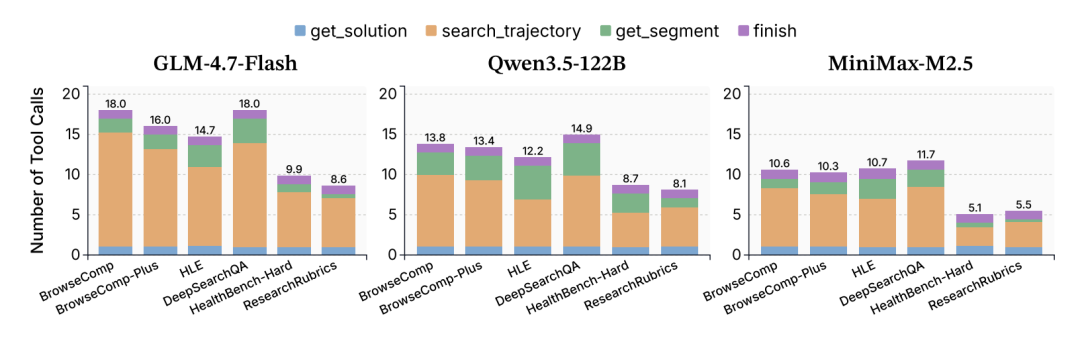
〓 不同底层模型下 AggAgent 处理单次查询的平均工具调用频次
即使并行生成的 8 条轨迹中只有一条包含了正确的证据链,聚合智能体依然能通过跨轨迹的逻辑核对将其提取出来,甚至能从多条彻底失败的轨迹中拼凑出隐藏的线索。

〓 AggAgent 典型决策行为:少数派事实确认、跨轨迹矛盾消解、碎片信息综合等
由于 AggAgent 的所有操作均在本地数据结构上执行,其引入的聚合成本仅为基础运行开销的 5.7%,远低于摘要聚合带来的 41% 额外负担,真正实现了推理算力向性能的高效转化。
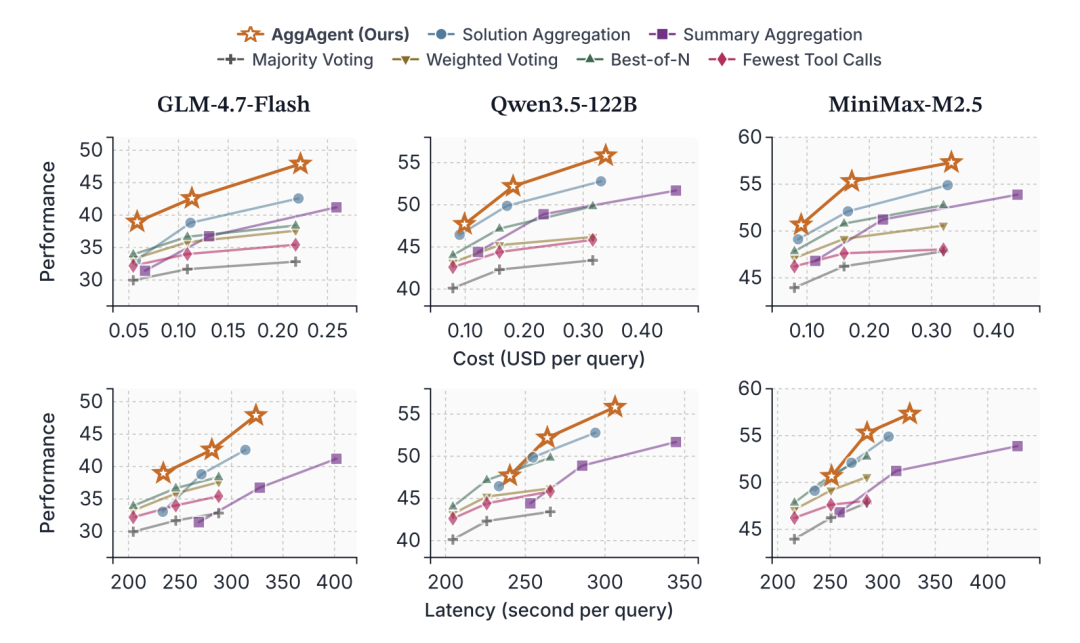
〓 AggAgent 在成本与延迟维度的帕累托效率曲线
测试结果显示,以 GLM-4.7-Flash、Qwen3.5-122B 等为底座, AggAgent 相比现有聚合方法,平均绝对性能最高提升了 5.3%。
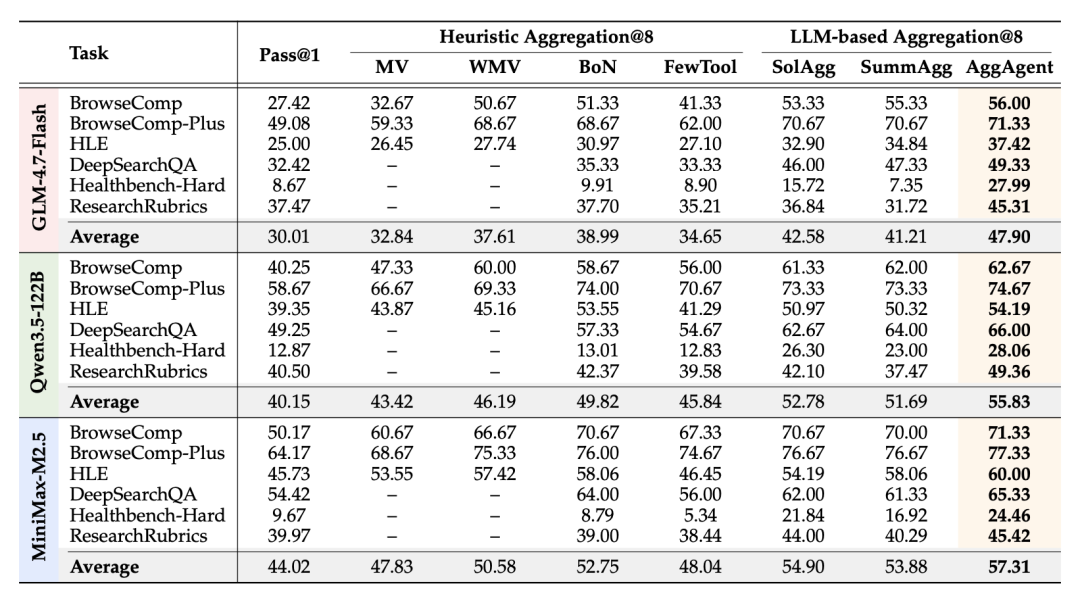
〓 在不同底座模型配置下,AggAgent 的得分全面优于现有聚合策略
在开放式深度研究任务中,采用“综合重写(Synthesis)”策略的表现显著优于单纯的“最优项选择(Selection)”。
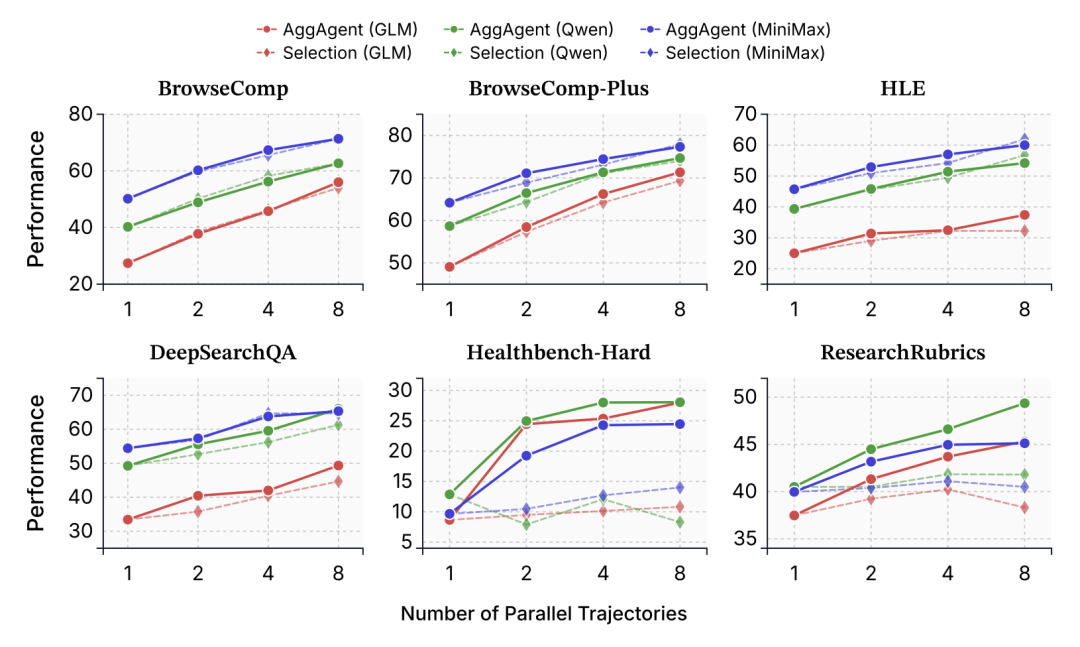
〓 输出设计消融实验:综合重写策略在深度研究任务中具有明显优势

结语
应对日益庞大的任务复杂度,陈丹琦团队的两项研究展示出了一种殊途同归的技术路径。
SD-ZERO 证明了模型可以通过对自身错误轨迹的反复重写,在不依赖外部模型的情况下,建立起精准的反馈机制。
AggAgent 则验证了在并发任务中,引入系统层面的主动校验与证据打捞,能够极大提升信息的利用率。
这两篇工作实质上都在探讨同一个核心问题:如何减少粗放式的算力消耗,转而向内挖掘模型中间轨迹的价值。
相比于单纯指望更庞大的参数或无止境的采样,教会模型如何审视自身的思考过程,或许是通往复杂推理更加直接和高效的桥梁。在 云栈社区,我们持续关注此类兼具架构设计巧思与深度学习前沿突破的技术思路,期待这些方法能尽快在更广泛的应用场景中落地。
 发表于 2026-4-30 21:05:02
|
查看: 175|
回复: 0
发表于 2026-4-30 21:05:02
|
查看: 175|
回复: 0
