当面试官抛出“如何压缩Prompt”这个问题时,这已不仅仅是在考察你的技术知识,更是在检验你的工程落地能力与成本控制意识。在大模型应用中,过长的Prompt会显著拖慢填充阶段,导致首次响应时间(TTFT)飙升,影响用户体验并增加调用成本。
作为技术架构师,必须认清一个核心事实:大型语言模型(LLM)不具备跨请求的持久记忆,它每次“思考”都仅基于当前请求所携带的上下文。在自动化编程等复杂场景中,原始信息动辄百万Token,远超任何模型的上下文窗口。因此,构建一套精密的“上下文工程”体系至关重要,其核心在于精准决策:哪些信息必须即时呈现,哪些可以暂存或摘要处理。
核心架构:五级渐进式压缩策略
一个成熟的解决方案,通常是一个五级压缩流水线。其设计哲学是渐进式压缩:优先使用成本最低的手段释放上下文空间,仅在必要时才动用计算代价更高的“重型武器”。
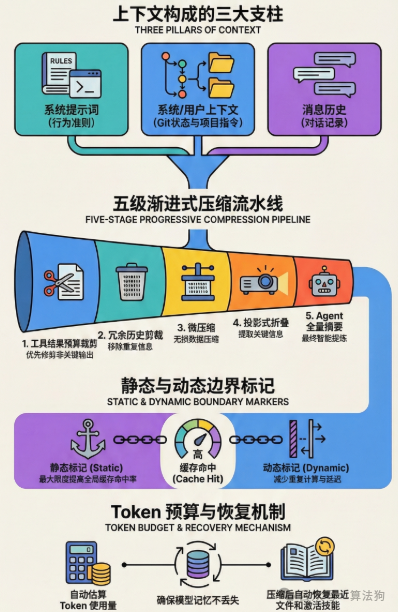
第一阶段:工具结果预算裁剪(Tool Result Budget)
这是成本最低的压缩方式。除了移除停用词和格式化符号外,最有效的工程实践是对工具(如代码搜索、文件读取)返回的结果进行预算控制。
- 深度策略:当工具返回数万行代码时,不应简单截断,而应将其持久化存储到磁盘或缓存中。在发送给模型的上下文中,仅保留一个约2KB的“内容预览”和唯一的文件路径标记。这种方法在节省大量Token的同时,确保了模型在需要时能通过路径“召回”完整数据。
第二阶段:冗余历史剪裁(History Snip)
这是针对多轮对话流的优化。通过精准识别并移除对话历史中已过期的、冗余的状态信息或中间指令,可以快速释放Token。关键在于系统能区分哪些消息是“任务完成后即可安全丢弃”的临时上下文。
第三阶段:微压缩(Microcompact)
这是一种更精巧的、依赖缓存状态的动态机制。
- 路径A(缓存已冷):当用户会话中断较久、服务端缓存已失效时,可以直接修改历史消息内容,将旧的、冗长的工具结果替换为简短的占位描述。
- 路径B(缓存仍热):当用户处于活跃对话中,服务端可能缓存了大量KV(Key-Value)以加速推理。此时严禁直接修改原始消息内容,否则会导致数十万Token的缓存全部失效,引发性能雪崩。正确的做法是通过API层发送特定的指令(如
cache_edits),在不破坏服务端缓存键的前提下,从逻辑层面“隐藏”或标记某些内容为可压缩。
第四阶段:投影式折叠(Context Collapse)
这比简单的文本摘要更高级。它不直接修改原始消息,而是为当前对话创建一个“折叠视图”,将早期不重要的消息整体替换为其语义摘要。
- “投影”的价值:类似于数据库的视图(View),底层数据保持不变,但API接口看到的是经过筛选和摘要后的版本。这使得压缩操作是可逆的,在后续需要时,系统可以轻松退回到包含原始细节的完整视图。
第五阶段:语义摘要与自动全量压缩(Autocompact)
这是最后的终极手段。当所有轻量级压缩策略都无法将上下文控制在预算内时,系统会启动一个子任务,fork一个专用的Agent来生成整个对话历史的语义摘要。
- 关键避坑技巧:为了生成高质量的摘要,可以采用“链式思考草稿”技术。让模型先在独立的分析块(如 `` 块)中,详细梳理用户意图、已尝试的方法及待办任务列表,然后仅将最终精炼出的结论性摘要放入主上下文。这种“丢弃分析过程、保留核心结论”的方式,能确保摘要的信息密度和可用性远超模型直接生成的普通概要。
资深避坑指南:应对压缩的副作用
仅提出方案不足以体现深度,识别并规避潜在风险同等重要。以下是针对Prompt压缩常见副作用的工程化对策。
1. 解决信息丢失:分级保护与恢复机制
除了设定“系统指令区禁止压缩”和白名单规则外,一个资深的工程实践是实施压缩后恢复机制(Post-compact Recovery)。
- 为何需要? 模型在压缩后可能会“忘记”对话中刚刚提及的关键实体,例如正在编辑的源代码文件。
- 对策:在执行完全量压缩(如第五阶段)后,系统应自动将最近读取的几个关键文件内容,以及当前激活的技能(Skills)描述,以“附件”或“记忆闪回”的形式重新注入上下文。这能有效维持对话任务的连贯性。
2. 规避负优化:高精度的Token估算策略
调用额外的大模型来执行压缩本身就有开销。为避免“为压缩而压缩”导致的性能反优化,应采用锚点估算法。
- 原理:无需为统计Token而频繁调用昂贵的API。可以利用模型正常响应时返回的
usage 字段数据作为高精度“锚点”,对后续新增的消息内容,仅通过本地快速的字符数估算(如字符数 × 1.2的保守系数)来预测Token增长。这让你能以极低的成本,精准把握触发压缩的时机。
3. 守护缓存性能:静态与动态边界标记
为了在压缩的同时极致降低延迟,必须与提示词缓存(Prompt Caching) 技术协同工作。
- 工程实现:在系统提示词中引入一个特殊的哨兵字符串,例如
SYSTEM_PROMPT_DYNAMIC_BOUNDARY。
- 边界之前:存放全用户共享的、几乎不变的静态内容,如核心行为准则、安全规则。这部分缓存命中率极高。
- 边界之后:存放用户私有的、随对话变化的动态内容。这种物理隔离确保了对动态部分进行压缩或修改时,不会导致前面高价值静态缓存的整体失效,从而保护了缓存效益。
总结:高并发场景的工程组合拳
面对生产环境中的高延迟挑战,最终的胜利方程式往往是一套组合策略:
- 静态优化:利用粘性锁存(Sticky-on Latch) 等技术,确保提示词缓存的头部不会因为功能开关(Feature Flag)的微小变动而失效,维持缓存稳定性。
- 动态管线:采用上述渐进式五级流水线,从本地的“工具结果裁剪”开始,逐步升级到云端的“投影式折叠”,直至万不得已时的“全量摘要”。
- 兜底容错:引入反应式压缩(Reactive Compression) 机制。当模型API直接返回“上下文过长”错误时,系统能立即捕获该异常,并触发最激进的压缩策略进行重试,保障请求的最终成功。
这套从 人工智能 工程实践中总结出的方案,其目标是在超长对话中,依然能让模型清晰地“记得”它一分钟前正在修改的那行代码。通过精密的压缩与缓存管理,可以实现延迟降低50%以上的优化效果,这正是面对“面试求职”中关于成本与性能平衡问题时,一份具备生产级视角的工程化答案。如果你对这类AI工程化实践有更多想法,欢迎来云栈社区与更多开发者交流探讨。 |  发表于 2026-4-5 04:28:54
|
查看: 181|
回复: 0
发表于 2026-4-5 04:28:54
|
查看: 181|
回复: 0
