如果你最近在使用 Claude Code 时,突然发现:
- Token 消耗异常飙升
- 对话上下文频繁“失忆”
- 同样任务成本直接翻了几倍
那你很可能已经踩中了 2.1.81 版本的一个隐蔽问题。
这不是使用方式的问题,而是一次典型的版本级“缓存机制失效”事故。
问题的本质是“缓存没有真正生效”
在正常情况下,Claude Code 会通过缓存机制复用上下文,从而有效减少 Token 消耗。一个稳定、高效的缓存系统是其控制成本的核心能力之一。
但在 2.1.81 版本中,却存在一个关键异常:
缓存创建失败 → 上下文无法命中 → 每次请求都全量计算 → Token 成倍增加
我们用下面这张流程图来清晰地还原这个问题的发生链路:
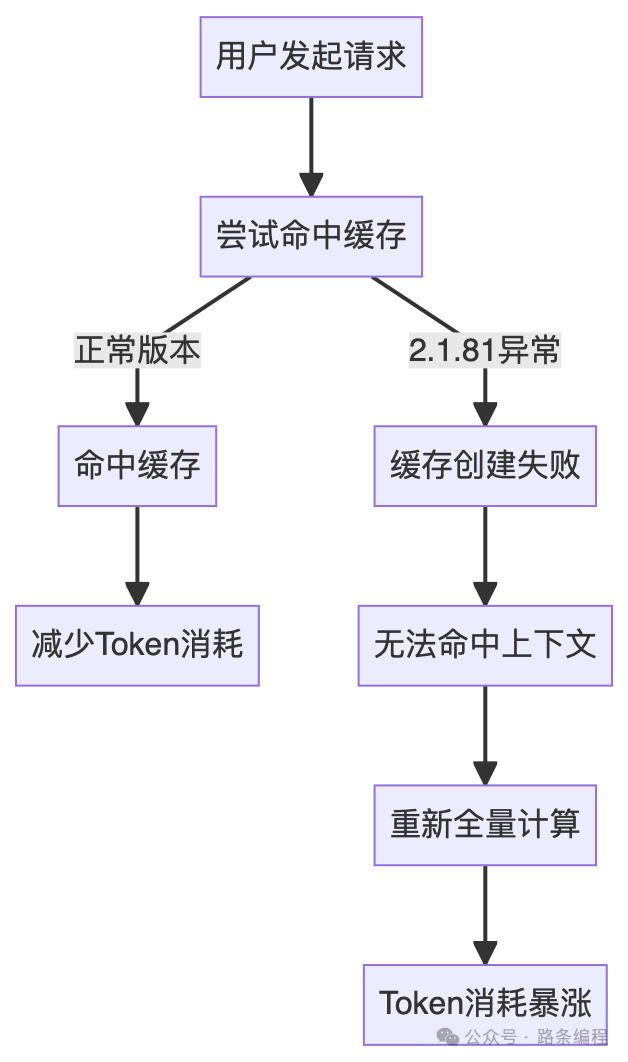
这个问题的危险点在于,它非常隐蔽:
- 并不会报错:程序运行看似一切正常。
- 不影响基础功能:代码生成、问答等核心功能依然可用。
- 但会持续“隐性烧钱”:在你毫无察觉的情况下,Token 消耗持续数倍于正常水平。
受影响的范围:“非官方链路”
这里有一个关键结论需要明确:如果你使用的是 Anthropic 官方 API,是不会受到这个缓存问题影响的。
受影响的主要集中在非官方或自建的接入场景:
- 本地推理服务(如自建代理服务器)
- 第三方 API 网关或中转服务
- 其他非官方的接入和封装方式
原因在于,2.1.81 版本引入了一些额外的 HTTP Header 和缓存策略。当请求通过这些非官方链路时,新增的 Header 可能未被正确处理或转发,从而导致服务端的缓存机制无法正确识别和创建缓存条目,最终使得每次请求都变成了“初次计算”。
诊断与解决方案
如果你已经遇到了 Token 消耗暴涨的问题,最直接有效的解决方案就是降级到一个已知稳定的版本。
方案一:降级到稳定版本
通过包管理器直接降级到 2.1.77 版本,该版本在缓存机制上被验证为稳定。
npm i -g @anthropic-ai/claude-code@2.1.77
执行此命令后,服务会立即回滚,缓存机制应恢复正常。
方案二:关闭非必要流量以禁止自动更新
为了避免系统或脚本自动升级到有问题的版本,建议在运行环境中设置一个特定的环境变量。
在 Linux 或 macOS 的终端中,可以临时设置:
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=true
如果你是在服务器上通过配置文件(例如 /usr/local/claude/config/.env)管理环境变量,可以在其中永久写入:
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=true
对于一些自定义部署,可以通过配置文件显式禁用可能干扰缓存链路的标识头。在配置文件(例如 /usr/local/claude/config/config.json)中加入:
{
“CLAUDE_CODE_ATTRIBUTION_HEADER”: “0”
}
这个配置的作用是:
- 禁用额外的标识头信息。
- 避免缓存创建和命中链路被无关信息干扰。
- 有助于提高上下文的缓存命中率。
关于降级的常见顾虑
许多开发者在考虑降级时会有以下担忧:
- 配置文件丢失或重置?
- 历史对话的上下文记忆被清空?
- 项目依赖环境出现异常?
可以明确的是:这些情况都不会发生。Claude Code 的用户配置、历史会话数据等是独立存储在特定目录下的,与主程序版本无关。降级操作仅仅是替换了可执行文件,并不会触及你的个人数据和项目环境。
建立“版本风险意识”
本次 2.1.81 版本的问题,本质上不是一个简单的功能 Bug,而是一个值得深思的工程风险案例:
- 缓存机制属于“隐性基础设施”:它默默工作,一旦异常,不易从表面现象立刻定位。
- 影响巨大:直接关系到使用成本和用户体验,在长时间、高频率的交互中,成本差异会非常显著。
尤其在当下,AI 编程工具 越来越重度依赖长上下文来实现复杂任务,缓存的效率直接决定了工具的经济性和实用性。技术选型与升级从来不是“越新越好”,而是“稳定压倒一切”。当工具直接参与你的成本计算时,每一次版本升级都应该经过谨慎的测试和验证,而非盲目追新。
希望这篇分析能帮助你快速定位并解决 Claude Code 的 Token 消耗异常问题。在探索 人工智能 技术与优化资源成本的路上,保持对新版本的好奇,同时也对生产环境的稳定性怀有敬畏,是每个开发者的必修课。如果你在部署或使用其他 AI 工具时遇到类似的基础设施问题,不妨到 云栈社区 与更多开发者交流经验。
 发表于 2026-4-5 04:31:17
|
查看: 366|
回复: 0
发表于 2026-4-5 04:31:17
|
查看: 366|
回复: 0
