
1. 前言
2026年2月,OpenAI 在一篇博文里首次将“Harness Engineering”这个词带入主流视野。六天前,HashiCorp 创始人 Mitchell Hashimoto 在自己的博客中率先使用了这个词。随后短短三周,Martin Fowler 团队的分析、LangChain 的对照实验、Stripe 的内部系统、Anthropic 的工程研究纷纷加入讨论。到我写下这篇文章的2026年4月,整个 AI 工程界已基本形成了共识:模型是商品,Harness(驾驭层)才是真正决定系统好坏的那一层。
然而我在一线看到的真实情况是:这个词的传播速度远远超过了概念本身。很多人都听说过“驾驭工程”、“harness这玩意儿”,可一旦深入聊下去,就会发现大家理解的完全不是一回事。有人把它当作“给 AI 接一堆工具”,有人认为它不过是“一套复杂的提示词模板”,更有甚者直接将其与多 Agent 框架划等号。还有些解读把一个具体的工程概念包装得玄之又玄——什么“熵减”、“强化学习显式实现”、“AI时代的新软件工程”——听完了反而让人更糊涂了。
所以我决定把这件事理清楚。这篇文章不做任何拔高,也不搞玄学包装。我们直接从最朴素的问题入手:
- AI Agent 到底是怎么跑起来的?
- Harness 在这个过程中处于哪一层?
- 为什么同一个模型,换个壳子表现会天差地别?
- 既然“Agent = 大模型 + Harness”,那 Harness 里面到底装了什么?
- GitHub 上能直接看代码的 Harness 长什么样?
- 如果我想从今天开始上手,第一步该做什么?
回答完这些问题,你就会得到一张关于 Harness Engineering 的实用地图。这张地图不能替你走路,但至少能让你在走错时,知道自己错在了哪里。
2. 先用四个数字热热身
我不喜欢概念先行,更相信数字——它们不会骗人。下面这四个数据,每一条都有公开的原始出处(文末附链接),而且每一条都足以让一个工程师停下来思考。
2.1 模型不变,只改壳子,排名冲进前5
LangChain 在2026年2月针对 Terminal Bench 2.0 基准进行了一项实验:
- 模型:GPT-5.2-Codex,全程未变;
- 基准:89个编程任务(涵盖机器学习、调试、生物学、安全、游戏);
- 改动:仅优化外层的 system prompt、工具集和中间件;
- 结果:52.8% → 66.5%,整体排名 从前30名开外 → 前5名。
核心改动只有三点:第一,Agent 在声称“我做完了”之前,必须强制跑一次验证(PreCompletionChecklistMiddleware);第二,采用“推理三明治”策略——规划和验证阶段给予最高推理预算,实现阶段给予中等预算;第三,加入了循环检测,防止 Agent 反复修改同一文件导致死循环。
换个壳子,模型就从“中游选手”变成了“顶尖选手”。这在工程上非常合理——同一个人,在不同工作环境下的产出就是不一样——但在我们仍然习惯于用“哪个模型更强”来评价 AI 的当下,这个结果足够反直觉。
2.2 只改一个编辑格式,模型得分提升10倍
Can Boluk(2026年2月12日博文《The Harness Problem》)做的实验:
- 模型:Grok Code Fast 1;
- 改动:将模型编辑文件用的
str_replace 补丁格式,换成他自己设计的“Hashline”格式——读取文件时给每行算一个2-3字符的内容哈希,模型引用行时用哈希值,而不是复述整行原文;
- 结果:6.7% → 68.3%,约10倍提升。
他的总结是:补丁格式失败得太过惨烈,以至于模型真正的编码能力几乎完全被机械性的编辑失败所掩盖。换句话说——模型不是不行,是它跟文件对话的“接口”不行。
这是我最喜欢的一条数据。因为它将一个抽象的主张(Harness 比模型更重要)具象化为一项极其具体的工程决策(换个文件编辑格式)。当我们谈论 Harness 时,谈的就是这种一毫米之差便能决定生死的接口设计。
2.3 3个人,5个月,100万行代码,0行手写
OpenAI 博文《Harness engineering: leveraging Codex in an agent-first world》披露的内部实验:
- 周期:2025年8月底至2026年1月底,约5个月;
- 团队:从3人起步、扩展至7人;
- 产出:约 100万行代码(应用、基础设施、工具、文档、内部开发者工具);
- 手写代码:严格为零;
- 合并 PR:约1,500个,人均3.5个PR/天;
- 日均 token 消耗:约10亿,日均成本2,000-3,000美元。
团队负责人 Ryan Lopopolo 后来在 Latent Space 播客中有一句被反复引用的话:
“我从流程里退出来了。我不能再对代码细节有深入意见。就好像我是在技术上领导一个500人的工程组织。”
这不是一个“AI 代替人”的故事。这是一个“工程师的产出单位,从‘代码’换成了‘让 Agent 可靠产出代码的环境’”的故事。7个人,每人操控10-50个并行 Agent,传统代码审查的带宽根本跟不上——于是,“管 Agent 的那套规矩”变得比代码本身更重要。
2.4 工具砍掉80%,成功率反而翻倍
Vercel 工程师 Andrew Qu 在2025年12月22日的一篇博文里,讲了一个反直觉的故事。他们内部一个叫 d0 的 Agent,面向 Slack,做自然语言转 SQL 查询。一开始,他们给它配了大约16个专用工具——查表结构、查主键、查数据类型、生成查询、校验查询、解释结果……每个工具都对应一个“具体的用处”。
后来 Opus 4.5 发布了。他们顺手把16个工具中的14个删掉,只留下2个非常通用的——ExecuteCommand(执行shell命令)和 ExecuteSQL(执行SQL)。结果如下:
| 指标 |
改前 |
改后 |
| 成功率 |
80% |
100% |
| 平均响应时间 |
274.8秒 |
77.4秒(3.5倍提速) |
| Token 用量 |
~102k |
~61k(少37%) |
| 步骤数 |
~12步 |
~7步(少42%) |
Andrew 那句话让我印象很深:
“我们之前在解决一些模型自己就能搞定的问题。当我们停止替模型做选择时,模型做出了更好的选择。”
这条案例单独看,可能只是一个反常识的个案。但如果你带着它去看文章后半部分,会发现它其实预言了 Harness Engineering 的长期方向:做厚是起点,做薄才是终点。
3. 三阶段演进:从“怎么问”到“怎么让它干活”
理解 Harness Engineering 最干净的方式,就是把它放进一条时间线里看。过去三年,AI 应用开发经历了三个阶段,每一个阶段的出现,都源于前一阶段暴露出的根本瓶颈。
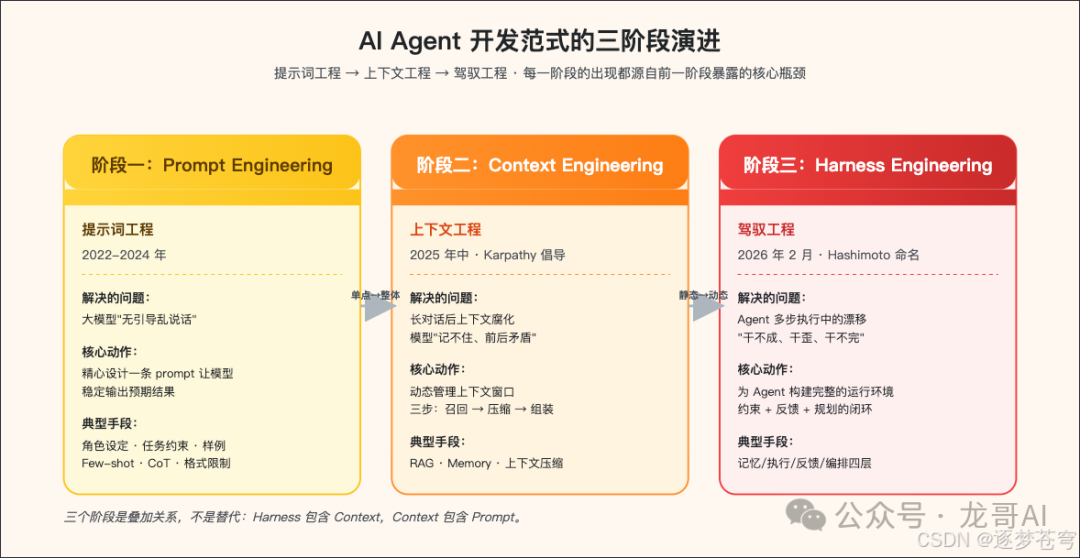
3.1 阶段一:Prompt Engineering——解决“无引导乱说话”
把任何一个 AI 产品(ChatGPT、Claude、Cursor)的外壳剥开,里面其实都是同一个东西:一个磁盘上的超大参数文件,加载到显卡内存里,配上 HTTP 接口。这就是大模型 API 服务。给它套个聊天界面就成了对话 AI,给它套个代码编辑器就成了 AI IDE。
大模型做的事情也很朴素:根据当前输入,预测下一个字词最有可能是什么。它本质上只是在猜你想要什么。所以当你给它的输入太宽泛时,它猜的答案就会非常发散。
比如你丢给它一段代码说“加个排序”,它可能只回你排序那段的写法。你得补一句“给我完整函数代码,不要乱改我其他代码”,它给的结果才会更符合预期。你可以继续补:角色设定、背景信息、历史对话、参考文档、输出格式限制……这些约束堆在一起,就是所谓的“提示词(prompt)”。
有意识地设计提示词,让模型稳定地朝你预期的方向输出——这就是提示词工程。它解决的是一个非常明确的问题:大模型“无引导乱说话”。
这个阶段的代表性技术有 Few-shot learning、Chain-of-Thought、角色扮演、结构化输出等。Andrej Karpathy 在2023-2024年间最有名的论断就是:“The hottest new programming language is English.”
但提示词工程很快遇到了天花板:它只能处理“一次性的单轮输出”。你没法靠一条 prompt 让 AI 完成一个涉及十几个文件、需要反复验证、需要调用外部接口的复杂任务。
3.2 阶段二:Context Engineering——解决“记不住”
提示词写得越长越仔细,模型知道的就越多,回答就越准。反过来,模型回答不准,大概率是它知道得不够多。
所以很自然地,大家开始不断往模型里塞更多资料:项目文档、历史对话、代码上下文、搜索结果、RAG 检索到的片段……这些打包发给模型的所有东西,合在一起叫上下文(context)。提示词只是上下文的一小部分。
但模型再强,一次能看的上下文也有最大限制——上下文窗口(context window)。在一个复杂 Agent 任务里,几轮工具调用下来就能把窗口打满。于是就必须做压缩、做丢弃、做选择。而在这个过程中,不可避免会丢掉一些关键信息,让模型开始“记不住”、“前后不一致”、“忘了自己一开始是要干什么”。这类问题业界有一个统一的名字:上下文腐化(context rot)。
解决这个问题的技术,就是上下文工程(Context Engineering)。Karpathy 在2025年6月明确倡导过这个词:
“在每一个工业级的LLM应用里,上下文工程才是那门精妙的艺术与科学——把上下文窗口填上恰当信息,为下一步做准备。”
上下文工程的核心动作可以拆成三步:
- 召回(Retrieve):找相关信息。可以来自外部文档、聊天历史、当前代码环境、工具执行报错。这里面涉及 RAG、Memory、Long-term Memory 等一堆子技术。
- 压缩(Compress):信息太多塞不进窗口就先压。比如把一段长对话送给大模型先做摘要,再把摘要放回上下文;把一堆工具调用日志折叠成几行关键信息。
- 组装(Assemble):信息放哪里、用什么顺序、什么格式——这些都直接影响模型的理解。一般越靠后的内容越容易被模型关注,所以把关键信息放在接近末尾的位置是一个常见技巧。
一旦你理解了上下文工程在做什么,就会明白一个重要的事实:提示词工程其实是上下文工程的一个子集——提示词只是上下文的一部分,优化提示词是在优化上下文的一小块。
但上下文工程还不够。因为 Agent 不只是“跟你聊天”,它要“干活”——要读写文件、要执行命令、要调 API、要跑测试。此时,问题已经不只是“我给它什么信息”,而是“它到底按什么流程动起来”。
3.3 阶段三:Harness Engineering——解决“干不成”
我们给大模型接上 Bash 沙箱、文件系统、MCP 工具、API 调用,它就有了“手”。但光有手不够——它要能根据任务,自己决定先动哪只手,动完观察结果,再决定下一步。
这个“一边思考、一边行动”的循环,在学术上叫 ReAct(Reasoning + Acting)——2022年普林斯顿提出的框架,已经成了几乎所有 Agent 的底层范式:
观察(Observation) → 思考(Thought) → 行动(Action) → 观察 → 思考 → 行动 → ...
把这个循环在外部用代码串起来,外层套一层控制流,一个能通过聊天帮你执行任务的程序就跑起来了。这就是 AI Agent 的本质——不是什么玄学,就是一个 for 循环加上工具调用加上上下文管理。
但只要这个 for 循环开始跑,新问题立刻出现:
- 上下文会持续膨胀,前面定好的目标和约束慢慢被冲淡;
- Agent 会在长链路上出现“理解漂移”——它以为自己在做A,但跑着跑着变成了做B;
- 它会“过早宣布胜利”——没有实际验证就说“我做完了”;
- 它会陷入死循环——反复改同一个文件,反复踩同一个报错;
- 它会积累技术债——复制仓库里已有的不合理模式,越跑越偏。
这些问题单个看都能解决。但它们叠加在一起,就构成了 Agent 系统特有的一类工程挑战——如何让一个 LLM 驱动的循环,在长时间、多步骤、可能出错的场景下,稳定地交付正确结果。
解决这个挑战的那整套工程实践,就是 Harness Engineering(驾驭工程)。它不是某一项具体的技术,而是围绕 Agent 的完整运行环境——规则、工具、反馈、规划——的集合体。
Mitchell Hashimoto 给出的操作性定义最简洁:
“每当你发现 Agent 犯了一个错误,你就花时间设计一个解决方案,确保 Agent 再也不会犯同样的错误。”
3.4 三者是包含关系,不是替代
我想特别强调一点——有些人把这三个阶段讲成“Prompt 过时了,Context 也过时了,现在要搞 Harness”。这是错的。
Prompt Engineering、Context Engineering、Harness Engineering 是层层包含的关系:
- Harness 里有上下文管理——所以它包含 Context Engineering;
- 上下文里有提示词——所以它包含 Prompt Engineering;
- 所以 Harness 自然包含另外两个。
你在做 Harness 时,并不会绕开“怎么组织提示词”、“怎么塞检索结果”。只是你的视角,从“一次对话”升到了“整个 Agent 生命周期”。
4. Harness 的四层工程外壳
到这里,我们可以打开 Harness 内部看看了。这也是整篇文章最核心的一张图。
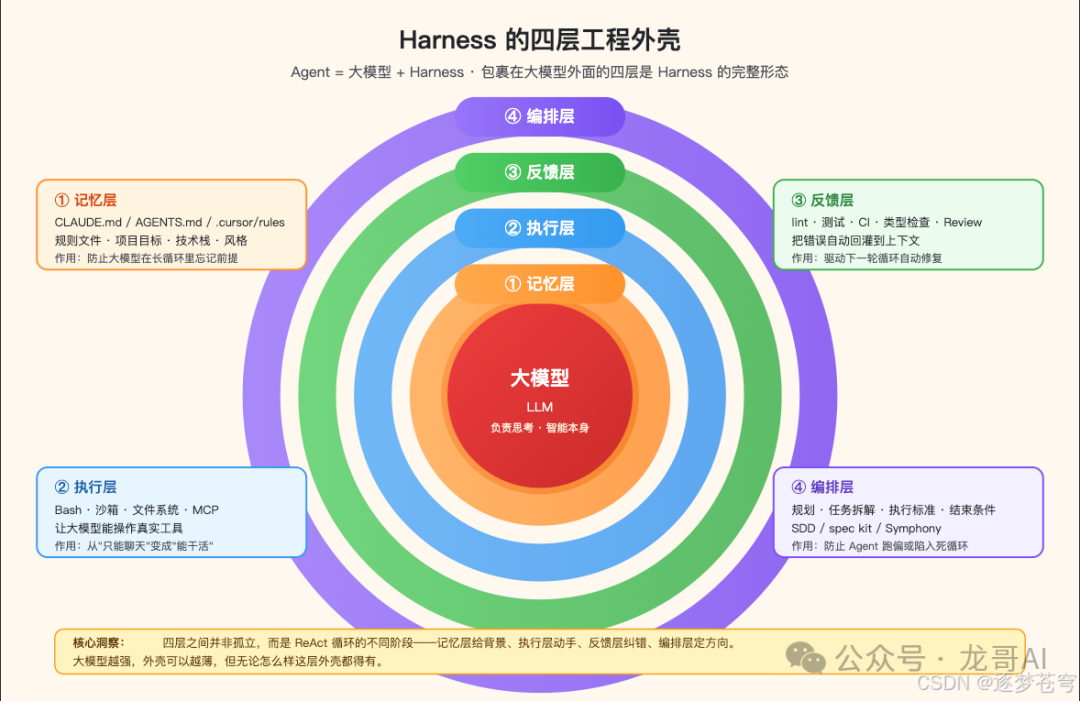
Harness 不是一个单一的东西,而是包裹在大模型外面的一层结构化系统。我把它拆成四层来讲:记忆层、执行层、反馈层、编排层。这四层不是彼此孤立的,而是在 ReAct 循环的不同阶段各自起作用。
4.1 记忆层:让大模型在长任务里不忘记前提
只要 Agent 的 for 循环一长,上下文就一定会膨胀。即使你上下文工程做得再好,膨胀本身也会稀释前期那些重要的约束——项目目标、技术栈、代码风格、禁止事项。跑到第10轮,Agent 可能还记得任务本身,但已经忘了“这个项目禁止直接改数据库”这条规则。
解决的办法其实很朴素:保证每次给大模型的上下文里,都包含一组可复用的核心信息。
这些核心信息可以独立写成文件,固定在代码仓库里。各家叫法不同——Claude Code 叫 CLAUDE.md,OpenAI Codex 的生态里叫 AGENTS.md,Cursor 叫 .cursor/rules,Aider 叫 .aider.conf.yml。我统一叫它规则文件。
规则文件会在每次调用大模型时,作为系统提示词自动注入上下文。它的典型内容:
# 项目背景
本项目是一个基于 Vue3 + TypeScript 的内部管理后台。
# 技术栈约束
- 状态管理用 Pinia,不要用 Vuex
- 请求库用 fetch 封装,不要引入 axios
- 组件库必须用 Element Plus,不要混用 Ant Design
# 禁止事项
- 不要直接修改数据库 schema
- 不要 eslint-disable 掉 any 类型检查
- 不要在组件里直接调 API,必须走 service 层
# 验证命令
- 改完代码必须跑:pnpm lint && pnpm test:unit
- 提交前必须跑:pnpm typecheck
规则文件写多了就会变长,长了就又会污染上下文。解决方案也很简单:拆。把一份大的规则文件拆成几份短的,加一个简单的路由——背景读 bg.md,技术栈看 stack.md,API 规范看 api.md。平时只加载文件路径,真正需要细节时,再让 Agent 按需读取全文。
OpenAI 在自己的实验里把 AGENTS.md 瘦身到大约100行——变成一份“目录”,指向结构化的 docs/ 子目录。他们特别强调了一句话:上下文是稀缺资源,当一切都“重要”时,什么都不重要。
记忆层做得好,Agent 即使跑到第50轮,也清楚自己处在哪个项目里、能做什么、不能做什么。
4.2 执行层:让大模型从“只能聊天”变成“能干活”
光记得事情没用,Agent 还得有手。执行层就是 Agent 的那些“手”:
- Bash / Shell:能跑命令行;
- 文件系统:能读写项目里的任何文件;
- 沙箱:隔离的执行环境,防止 Agent 把本地环境搞坏;
- MCP 工具:通过标准协议接入外部数据和能力;
- API 调用:直接打第三方 HTTP 接口。
执行层的工程关键是两个:接口设计和权限边界。
接口设计指的是工具对大模型的“表达友好度”。回到第2.2节 Can Boluk 的实验——同一个“改文件”能力,用 str_replace 格式和用 Hashline 格式,效果差了10倍。这就是工具接口设计的威力。好的工具对模型有以下几个特征:
- 描述清晰:不用模型靠猜;
- 输入简洁:不让模型复述冗长原文;
- 错误信息对模型友好:不只说“参数错了”,还告诉它“应该怎么改”;
- 返回结果结构化:不是一大段散文,而是结构化的 JSON 或者标记化文本。
权限边界指的是——不是所有能干的事都该给 Agent 干。一个生产级 Harness 必须对不可逆操作(删库、推主分支、发邮件、调支付接口)做明确的审批或隔离。Anthropic 2026年2月的研究显示,在真实的 Agent 交互里,不可逆操作只占工具调用的 0.8%——但恰恰是这 0.8% 决定了你敢不敢让 Agent 在无人值守下跑。
4.3 反馈层:把错误自动回灌到下一轮
有了记忆层和执行层的配合,Agent 就能不停写代码、跑 linter、跑测试。这个过程中一定会出错——编译不过、测试不通、类型不对。反馈层的作用,就是把这些错误自动捕获下来,回灌到 Agent 的下一轮上下文里,驱动它自动修复。
一个典型的反馈循环:
Agent 写代码 → 执行 linter / test / typecheck
├── 通过 → 继续下一步
└── 失败 → 把报错信息作为新的 Observation 送回 Agent
→ Agent 在下一轮用报错做修复 → 再执行验证
Fowler 团队把这一类组件叫做 Sensors(传感器)——与之相对的是 Guides(引导)。Guides 是“事前防错”(比如规则文件、架构约束),Sensors 是“事后纠错”(测试、lint、review)。两者缺一不可。
反馈层里最关键的一个工程决策是:什么时候升级给人类? Stripe 的 Minions 系统(内部每周自动合并1,300+ PR)采用了一条非常朴素的规则——“两次CI失败即升级”:如果 Agent 在两次尝试里没把 CI 跑绿,任务立刻转给人。这条规则的目的,是防止算力在 Agent 不太可能解决的问题上无限燃烧。
反馈层做得好,Agent 不仅能干活,还能在干错时自动收敛。
4.4 编排层:全局规划,防止 Agent 跑偏
有记忆、有执行、有反馈,Agent 已经能跑起来了。但跑起来 ≠ 跑对。如果缺少全局规划和清晰的结束条件,Agent 很容易在一个局部最优里打转——反复改同一块代码、无限补丁叠加、或者干到一半自以为完成了。
编排层要解决的就是这个问题:把一个大任务拆成若干子任务,每个子任务有明确的执行标准和完成条件,按规划驱动 Agent 分步推进。
编排层可以简单到一个 TodoList(Claude Code内置),也可以复杂到像 OpenAI 内部的 Symphony 那样——用 Elixir 的 BEAM 运行为每个任务起一个独立的 gen_server 进程,完整的任务状态机。
2025年下半年开始在业界火起来的一种落地范式叫 Spec-Driven Development(SDD,规约驱动开发)。它所做的事,其实就是把编排层显式化:
- 先生成约束文件:明确这个任务的需求、边界、验收标准;
- 再制定具体开发计划:把大任务拆成可执行的小步骤;
- 最后才是实际代码修改 + 测试;
- 每个阶段完成后,都可能更新规则文件(比如
CLAUDE.md),让后续 Agent 拿到最新的上下文。
GitHub 上的 spec kit 就是一个面向 Claude Code 的 SDD 扩展。它不是把 Harness 做复杂,而是把“编排”这一层从工程师的脑子里,搬到了版本控制里——让 Agent 自己也能看到每一步的计划。
4.5 四层合起来:Agent = 大模型 + Harness
把四层叠在一起,我们就得到了一个完整的公式:Agent = 大模型 + (记忆层 + 执行层 + 反馈层 + 编排层)。Harness 就是这四层之和。
这个公式有一个很实用的推论:只要不是“大模型”本身的那部分,都属于 Harness Engineering 的范畴。
- 你在写
CLAUDE.md?那是记忆层。
- 你在给 Agent 接一个新的 MCP?那是执行层。
- 你在做 CI 自动验证?那是反馈层。
- 你在用 spec kit 做规划?那是编排层。
过去几年大家零散做的事情,在这个公式下,第一次有了一个统一的名字。
5. Harness 内部的另一种拆法:OpenAI 的三类机制
第4节的四层划分是按“功能模块”拆的,好处是直观。但还有一种拆法是按“Agent 随时间会出什么问题”来拆的——这就是 OpenAI 在2026年2月博文里提出的 Context Engineering / Architectural Constraints / Garbage Collection 三类机制。两种视角可以互为补充。
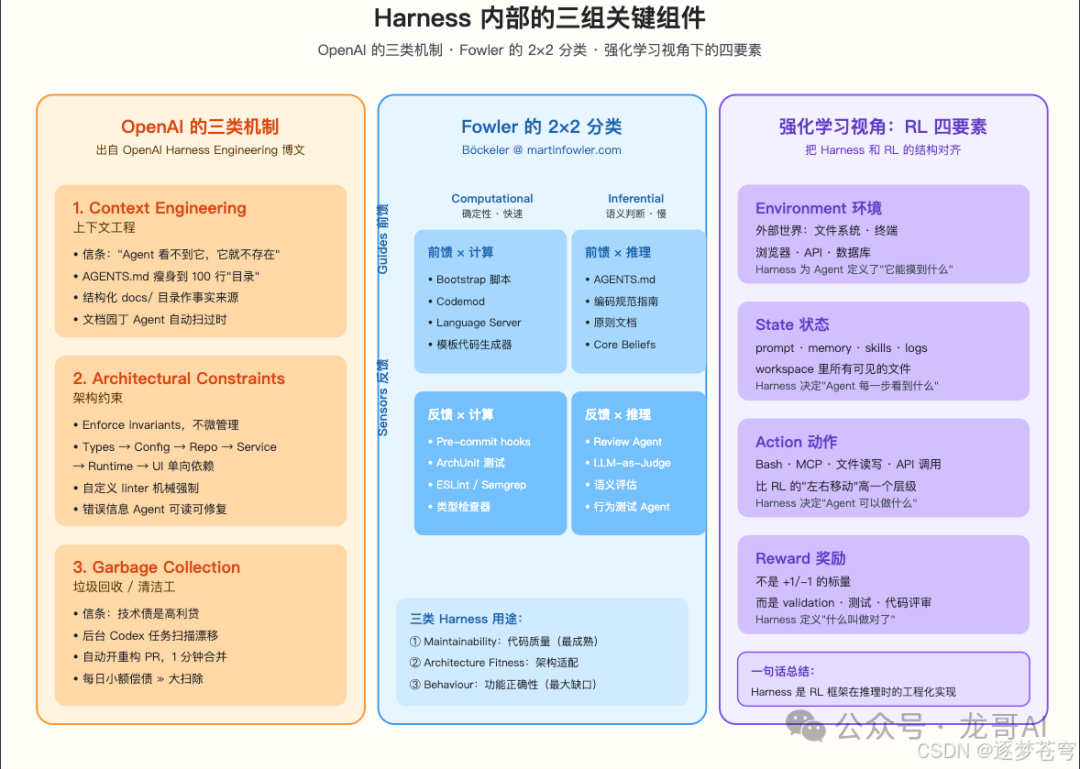
5.1 Context Engineering:把环境变成 Agent 可读的
OpenAI 对这一类的核心信条是:
“如果 Agent 看不到它,它就不存在。”
这意味着——在 Slack 讨论里达成的架构决策、在白板上画的数据流、在某个工程师脑子里的“我们这个项目的品味”,只要没有变成 Agent 能读到的结构化文档,对 Agent 来说就等于不存在。
这和我们在第4.1节讲的记忆层是同一件事,但 OpenAI 把它上升到了一个更绝对的层面:如果你希望 Agent 稳定地按某种方式工作,你就必须把“某种方式”写下来,放在它每次都能读到的地方。
他们的具体实践是:
- 把
AGENTS.md 瘦身到约100行目录;
- 把实际的知识放在
docs/design-docs/、docs/exec-plans/、docs/product-specs/ 这样的结构化子目录下;
- 维护一份
core-beliefs.md,里面写团队对产品的根本定义、12个月愿景、终端用户是谁;
- 定期跑一个“文档园丁” Agent 自动扫描过时条目、开 PR 更新。
5.2 Architectural Constraints:用规则替代代码审查
这一类的核心信条是:
“Enforce invariants, don't micromanage implementations.”
(强制不变量,不要微管理实现细节。)
OpenAI 代码库里最有代表性的约束,是一条严格的单向依赖链:
Types → Config → Repo → Service → Runtime → UI
每一层只能从相邻层导入。横切关注点(鉴权、遥测、功能开关)通过显式的 "Providers" 接口进入,其余一切都被禁止。这条规则不是写在 AGENTS.md 里让 Agent “请遵守”,而是编码为自定义 linter,机械性地强制执行——违反了直接报错,而且错误信息被特意设计为“Agent 可读”,告诉它规则为什么存在、正确做法是什么。
Ryan Lopopolo 在博文里有一句话我觉得特别值得咀嚼:
“这种架构通常是你有几百名工程师时才会考虑的。但在 coding agent 的世界里,它是一个早期前提条件——正是这些约束让速度成为可能,而不带来架构漂移。”
换句话说:当你有7个工程师但每人操控10-50个 Agent 时,你实际管理的是500人组织级别的并发产出。人肉 review 已经不可能覆盖所有代码,唯一的出路就是把规则机械化。
这类机制在四层框架里跨越了记忆层(Guides)和反馈层(Sensors)——因为它既在 Agent 动手前起引导作用(通过规则文件),也在 Agent 动完手后起检验作用(通过 linter)。
5.3 Garbage Collection:自动清“AI slop”
Agent 驱动的代码有一种独特的技术债积累方式——Codex 会复制仓库里已有的模式,包括那些不完整、不优雅、次优的模式。随时间推移,这种漂移不可避免。业界给这种“AI 产出的低质量、大量、看起来像但不对劲”的代码起了个俚语:AI slop。
OpenAI 团队一开始的做法是每周五花20%的工作时间手动清理 slop。但很快发现这不可持续——生产速度太快,清理速度跟不上。于是他们做了一件很有意思的事:把“清 slop”这件事本身也交给 Agent。
定期运行一批后台 Codex 任务,扫描偏离“黄金原则”的代码,自动开有针对性的重构 PR。这些清理 PR 通常在一分钟内就能被审查并合并。Ryan 的类比非常传神:
“技术债是高利贷。与其让它积累,不如每天小额偿还。”
这类机制对应了四层架构里没显式讲过的另一个维度——Harness 不仅要让 Agent 干活,还要让 Agent 清理自己干出来的混乱。
6. 换个视角:Harness 和强化学习
讲到这里,一个对 RL(强化学习)有基础的朋友可能已经看出来了——这一整套东西和 RL 的框架长得非常像。
我个人很喜欢这个视角。它不是一个新发现,而是一种“对齐”——它让我们能用一套已经很成熟的理论词汇,去讨论一个看起来全新的工程问题。
6.1 为什么 RL 和 Harness 天然同构
标准 RL 的五个核心要素:Environment(环境)、State(状态)、Action(动作)、Reward(奖励)、Policy(策略)。把它们和 LLM Agent 的工程组件一一对照:
| RL 要素 |
LLM Agent 对应 |
Harness 在这里做什么 |
| Environment |
外部世界:文件系统、终端、浏览器、API、数据库 |
执行层——定义 Agent 能摸到什么 |
| State |
prompt、memory、skills、logs、workspace 里的文件 |
记忆层 + 上下文工程——决定每一步 Agent 看到什么 |
| Action |
Bash 命令、MCP 工具调用、文件读写、API 请求 |
执行层的接口设计——决定 Agent 可以做什么 |
| Reward |
不是标量的 +1/-1,而是 validation / 测试 / 代码评审的结果 |
反馈层——定义“什么叫做对了” |
| Policy |
模型在当前上下文下的决策倾向 |
编排层 + 上下文组装——塑造 $π(a |
s)$ |
这个对齐不是一种类比——它在数学结构上是严格一致的。2026年3月的一篇 LLM Agent 综述(Lee Han Chung, A Taxonomy of RL Environments for LLM Agents)就已将其形式化:一个完整的 Agent 环境可表达为五元组(任务、Harness、Verifier、State、Configuration),Harness 是环境五元组的一个核心组件,而不是比喻。
这个视角给了我们一个关键洞察——Harness 不是在改变模型(权重没变),而是在改变模型的“有效策略”。同样的参数 $θ$,在不同的 Harness 下会表现出完全不同的 $π_θ(a|s)$。这就解释了,为什么第2.1节的 LangChain 实验中,同一个 GPT-5.2-Codex 可以从 Top 30 外跃升到 Top 5。
6.2 熵减:Harness 解决的核心矛盾
RL 的另一个基础概念是策略的熵:$H(π(·|s))$。一个熵很高的策略,意味着在当前状态下,它决定做什么“很不确定”——每个动作都差不多可能,实际上等于在乱走。
一个 Agent 系统在没有任何约束时,动作分布的熵会非常高——模型可以选择很多条路,但大部分都通向失败。Harness 的核心作用,就是降低这个条件分布的熵:
- 记忆层通过规则文件,让“这类事情禁止做”变得清晰;
- 执行层通过工具接口设计,把“乱调命令”的概率压下来;
- 反馈层通过即时纠错,让偏离方向的路径不断被中断;
- 编排层通过任务拆解,把一个模糊的大目标变成一系列明确的小目标。
每一层都在做同一件事——在决策点上降低不确定性。
所以我会用一句话概括 Harness 的本质:
Harness 是一种系统性的熵减——把 Agent 从“可能做很多种事”收敛到“大概率做对这件事”。
从热力学和信息论的直觉看,这也解释了为什么 Agent 在长循环里会“越跑越偏”——系统的熵会自发增加(上下文会腐化、AI slop 会积累、约束会被稀释)。你必须持续地往系统里注入“负熵”——这就是 OpenAI 的 Garbage Collection、Anthropic 的 init.sh 重启机制、Stripe 的“两次 CI 失败即升级”规则背后真正的物理图景。
6.3 越强的模型,外壳可以越薄
苦涩教训(Bitter Lesson, Rich Sutton 2019)告诉我们——利用算力的通用方法,最终会击败手工编码的领域知识。这条教训在 Harness 的语境下正反复上演:
- Vercel 删掉14个工具后,成功率从80%冲到100%;
- Manus 团队从2024年以来,完全重写了四次 Agent 框架,每次都偏向更薄、更通用;
- Noam Brown(OpenAI 研究员)直白地说:“推理模型出现后,你根本不需要那些复杂的 scaffolding——有时候加上反而更糟。”
这意味着 Harness 的内容会随时间分化为两类:
- 补偿层(短期):用来补偿模型当前能力不足的部分——比如防 Agent 死循环的 LoopDetection、防 Agent 复述原文的 Hashline、细粒度的工具分类——这些会随模型变强而自然消亡;
- 基础设施层(永久):工具集成、状态管理、环境接口、安全边界、可观测性——这些永远需要,因为它们不是补偿模型的弱点,而是 Agent 系统的本质组成。
对我在自己做项目时的启发是——设计 Harness 时,时时问自己一句:这一块是补模型的弱点,还是提供基础设施?如果是前者,就要准备它随时被拆掉。
一句话概括:大模型越强,外壳可以做得越薄,但无论怎么样,这层外壳都得有。
7. 生态位:Harness 在 AI 栈里住在哪儿
讲完 Harness 的内部结构,还得讲讲它在整个 AI 生态里的位置。业界有一个流传较广的简化说法是 “Harness 三层架构——应用/编排/协议”。这话基本成立,但我想在它的基础上做一个修正。

7.1 更准确的分层:Mollick 框架 + 生态三子层
Ethan Mollick(沃顿商学院教授)在2026年2月18日的一篇指南里,给了一个我觉得特别有帮助的划分。他把 AI 产品分成三层:
- Models——底层大脑,决定智能上限:GPT-5.2、Claude Opus 4.6、Gemini 3 Pro;
- Apps——用户直接打开的聊天界面产品:chatgpt.com、claude.ai、gemini.google.com;
- Harnesses——让模型的力量真正干活的系统:Claude Code、Cursor、OpenAI Codex、NotebookLM。
然后在 Harness 这层内部,又可以继续拆成三个子层——这就是“应用/编排/协议三层”想说的东西,但更准确的叫法是:
- Harness 产品子层:Claude Code、Cursor、OpenAI Codex、Cowork——用户直接使用的端到端 Harness 产品;
- 编排框架子层:LangGraph、Microsoft Agent Framework、Google ADK、CrewAI、Symphony——构建 Harness 产品所用的中间件;
- 协议子层:MCP(Agent-to-Tool)和 A2A(Agent-to-Agent)——跨框架、跨厂商的标准协议。
这里有个很易踩的坑:不要把 Claude Code 叫“应用层”。在 Mollick 的框架里,Apps 指的是 chatgpt.com、claude.ai 这类“聊天界面产品”,而 Claude Code、Cursor 恰恰不是 Apps——它们是 Harnesses。这两个概念是分离的:chatgpt.com 是 Apps,Claude Code 是 Harness 产品。
7.2 协议子层是 AI 时代的新基础设施
单独多说一句协议子层,因为这一层很可能是未来十年最坚硬的基础设施。
MCP(Model Context Protocol) 由 Anthropic 于2024年11月开源,2025年12月捐赠给 Linux 基金会。它把“Agent 连接工具”的 M×N 连接问题简化成了 M+N——只要你的工具实现 MCP 协议,所有支持 MCP 的 Agent 都能用它。截至2026年3月,MCP 的月 SDK 下载量已超9700万次。业界常说它是“AI 世界的 USB-C”。
A2A(Agent-to-Agent) 由 Google 在2025年4月发起,同样托管在 Linux 基金会。Agent 之间通过“Agent Card”互相发现,通过 JSON-RPC 2.0 over HTTP 通信。它解决的是“不同框架构建的 Agent 怎么协作”的问题。如果 MCP 是 USB-C,A2A 就是 AI 时代的 HTTP。
需要注意的是,Ryan Lopopolo 对 MCP 持明确看跌态度——理由是它强制把所有工具 token 注入上下文,干扰了模型自己管理注意力的能力。他的团队在100万行代码项目里只用了6个 skills,而不是接入一堆 MCP 服务器。这不是说 MCP 不好,而是说“协议好用”和“具体工具链好用”是两件不同的事——实践中需要权衡。
8. GitHub 上看得见的 Harness
光讲概念太虚。这一节我挑几个 GitHub 上 stars 相对比较高、能直接打开看代码的 Harness 项目。
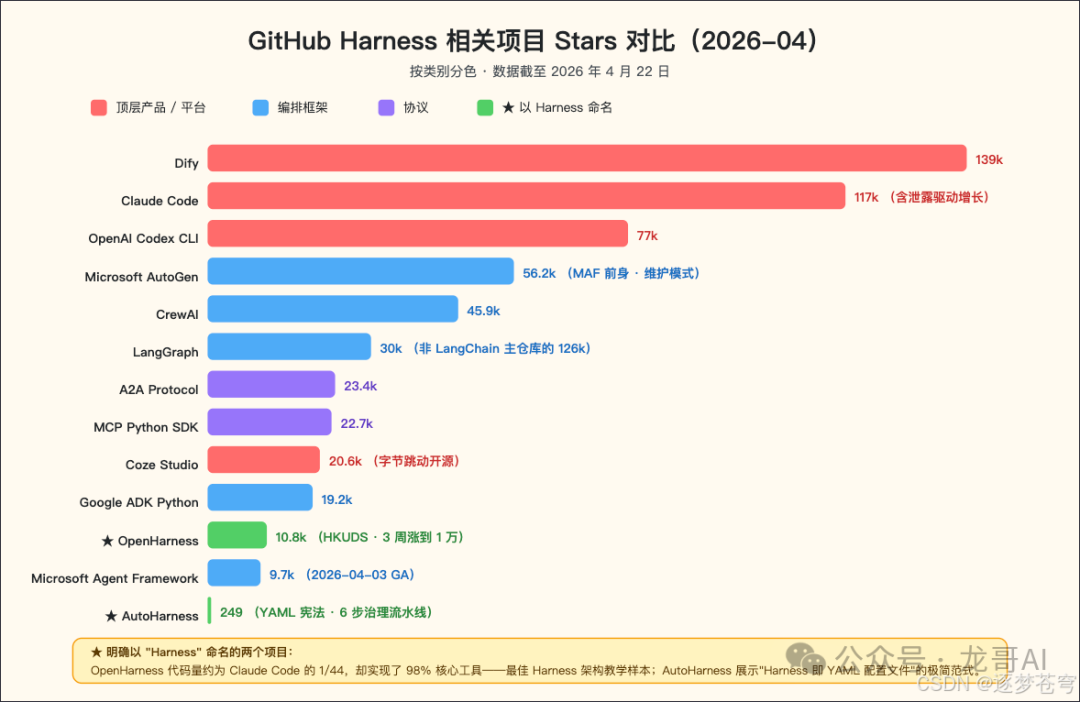
8.1 唯二以 Harness 命名的项目
8.1.1 OpenHarness(HKUDS 香港大学数据智能实验室)
- 仓库:github.com/HKUDS/OpenHarness
- Stars:约 10.8k(3周从0涨到1万)
- 语言:Python 93.5%
- 代码量:11,733行
这是目前 GitHub 上唯一把 Harness 作为核心命名概念、并完整实现该架构的开源框架。它的 slogan 是 "Open Agent Harness with a Built-in Personal Agent — Ohmo!"
对于想理解 Harness 架构的人来说,OpenHarness 有独特的价值——它用约 Claude Code 1/44 的代码量,实现了 Claude Code 98% 的核心工具能力(43个工具、54个命令)。换句话说,如果你想看一份能够完整读完的生产级 Harness 代码,OpenHarness 是你的最佳选择。架构分层清晰:
- LLM 智能层:负责“做什么”的决策;
- 执行层(Harness 层):负责工具、记忆、安全——“怎么做”。
支持多 Provider(Claude / OpenAI / Copilot / Codex / Kimi / GLM / MiniMax / Ollama),有完整的权限控制和 Skills 系统。建议打开仓库的 src/ 目录,对照第4节的四层框架读一遍,你会比读十篇博客都清楚。
8.1.2 AutoHarness(AIMING Lab)
- 仓库:github.com/aiming-lab/AutoHarness
- Stars:249
- 发布:2026年4月2日
Stars 不多,但价值在于它把 “YAML 宪法(Constitution)” 做成了核心。Agent 的行为规则完全由可读、可版本控制的 YAML 文件定义,每次调用都有 Token 预算管控,每一步都有 JSONL 审计日志。它的口号我觉得一针见血:
“Every agent deserves an aha moment — the model reasons, we harness the rest.”
(模型负责推理,我们 harness 其余的一切。)
2行代码就能把它集成进现有的 LLM 客户端,是理解“Harness 即配置文件”这个极简范式的最好样本。
8.2 顶层产品
- Claude Code (anthropics/claude-code):117k stars。2026年3月31日一次 npm 打包意外泄露了约50万行 TypeScript 源码,包含 KAIROS(持续监听自动行动)、ULTRAPLAN(委托远程 Opus 做30分钟深度规划)等内部系统。泄露的代码是目前公开的最完整生产级 Harness 案例。
- OpenAI Codex CLI (openai/codex):77k stars,Rust 实现(2025年6月从 TypeScript 迁移),周活用户已达300万。
- Cursor 3.0(闭源但配置层开放):2026年4月2日发布,从“AI辅助IDE”彻底转型为“Agent优先IDE”。
.cursor/rules(MDC格式)是 Harness 配置的典型样本,可以拷下来当模板用。
- GitHub Copilot Agent Mode:2026年3月向 JetBrains IDE 全面 GA,Coding Agent 模式可以把 GitHub Issue 直接分配给 Copilot。
8.3 编排框架
| 项目 |
Stars |
语言 |
核心卖点 |
| LangGraph |
30k |
Python |
图结构 Agent 编排,原生支持 checkpoint 和 human-in-the-loop |
| CrewAI |
45.9k |
Python |
角色扮演多 Agent 协作,日均12M Agent 执行 |
| Microsoft Agent Framework (MAF) |
9.7k |
Python+C# |
AutoGen + Semantic Kernel 合并的 1.0 GA 版(2026-04-03) |
| Google ADK Python |
19.2k |
Python |
多语言(Python/Go/Java/TS),A2A 原生支持 |
关于 LangGraph 经常被误传为126k stars——那是 LangChain 主仓库的数字,不是 LangGraph 自己的。LangGraph 自身大约30k stars,这才是准确数字。
8.4 协议和平台
- MCP Python SDK (modelcontextprotocol/python-sdk):22.7k stars
- A2A Protocol (a2aproject/A2A):23.4k stars
- Dify (langgenius/dify):139k stars。可视化 Agentic 工作流平台,运行在140万+台机器上。
- Coze Studio (coze-dev/coze-studio):20.6k stars。字节跳动开源,Apache 2.0,技术栈是 TS+Go+DDD。
9. 从今天开始怎么做
概念讲完了,生态讲完了,该聊聊怎么动手了。我自己的建议是分四步。
9.1 第一步:写一份 CLAUDE.md / AGENTS.md
不管你用的是 Claude Code、OpenAI Codex 还是 Cursor,都先在仓库根目录写一份规则文件。它的内容回到第4.1节我举的那个例子——项目背景、技术栈约束、禁止事项、验证命令。
写这份文件的原则只有一条:每出现一次你不满意的 Agent 行为,就往里面加一条规则。这就是 Hashimoto 那句操作性定义的字面意思。
我见过的团队里,最早一批把 Harness 做好的,不是 AI 经验最多的团队,而是最认真记录每一次“Agent 出错”的团队。AGENTS.md 长得快,Harness 就进化得快。
9.2 第二步:用 SDD 把编排层显式化
当你的 Agent 开始处理比“修个 bug”更大的任务时,就需要把编排层搬到版本控制里。方法是使用 Spec-Driven Development(SDD)范式,把一个大任务拆成三个阶段:
- 生成约束文件:明确需求、边界、验收标准——先让 Agent 帮你把需求写清楚;
- 制定开发计划:把大任务拆成可执行的小步骤——让 Agent 生成一份 todo list;
- 逐步实现 + 测试:Agent 按计划推进,每完成一步就跑验证。
GitHub 上的 spec kit 是一个面向 Claude Code 的 SDD 扩展,你可以直接拿来用。每一阶段它都会更新一次 CLAUDE.md,保证注入上下文的始终是核心信息。
当然 SDD 目前还不够完善,我相信很快会有更好的替代品出现。但它代表的方向是对的——把“规划”从工程师的脑子里搬出来,放到版本控制里。
9.3 第三步:加反馈层,让 Agent 自己纠错
记忆层和执行层做好之后,Agent 就能跑起来了。接下来最重要的事情是让它能“自己发现自己错了”。
具体做法——配置这些在 Agent 每次提交前必须跑的检查:
- lint:代码风格和简单错误;
- typecheck:类型检查(TypeScript / Python mypy / Rust 自带);
- unit test:关键路径的单元测试;
- integration test:端到端验证;
- CI:把以上所有内容串起来。
关键不是这些工具本身——大多数团队都已经在用——而是把它们的输出自动回灌到 Agent 的下一轮上下文里。Claude Code、Cursor、Codex 都支持这个能力,你只需要把验证命令写进 CLAUDE.md:
## 验证命令
改完代码必须按顺序执行:
1. pnpm lint
2. pnpm typecheck
3. pnpm test:unit
如果任何一步失败,请根据报错修复,然后重跑所有步骤。
这一条设置下去,Agent 的行为会从“觉得自己做对了”直接升级到“被外部事实验证做对了”。
9.4 第四步:学会删
这是我在第2.4节预告的那条反直觉原则——你的 Harness 不一定是堆得越厚越好,很多时候它需要的是“减”。
当模型能力在持续提升时,你早期加的很多补偿性约束会变成负担:
- 为旧模型做的复杂路由器,在新模型上反而让它绕弯;
- 为旧模型细粒度拆的16个工具,换成新模型后两个通用工具就够了(Vercel 的故事);
- 为旧模型精心设计的 Context Reset 机制,新模型自己能处理了(Anthropic 已经在拆早期 Harness 里的这类组件)。
所以每隔一段时间,回头审视你的 Harness,问一句:哪些约束现在其实是冗余的?哪些工具现在其实可以合并?
一个好的 Harness 工程师的核心能力之一,是知道“什么时候该加”,同样重要的另一个是“什么时候该删”。
10. 写在最后
我用一句话概括整篇文章——
AI Agent = 大模型(负责思考)+ Harness(负责让它能可靠干活)。而 Harness 由四层构成:记忆层让它不忘记前提、执行层让它能动手、反馈层让它能纠错、编排层让它不跑偏。
这是一件在我看来工程味道很浓的事情——没有什么神秘的。它不需要你懂深度学习、不需要你会调模型、甚至不需要你写什么很复杂的 AI 代码。它需要的是你把一个原本模糊的执行过程,变成一个可观测、可约束、可纠错、可规划的系统。
这件事有意思的地方在于——它本来就是一个工程师每天在做的事,只不过“被管理的对象”从人变成了 Agent。你在 CI 里写的流水线、你给新同事写的 onboarding 文档、你定的 code review 规范、你做的 monorepo 分层——这些经验全部可以迁移过来。换个名字而已。
不同的地方在于——当你的“同事”每天能干10-50份工作量、能在你睡觉时继续推进、但同时也会在某个接口细节上莫名其妙跌倒时,你会真正理解为什么环境设计比个人能力更重要。你不再相信“更好的提示词能解决一切”——因为你会看到,同样的模型在两个不同环境下表现差了10倍。
最后引一句 Ryan Lopopolo 的原话作结尾——他说这话时,刚完成那个3个人5个月100万行代码的实验:
“我从流程里退出来了。我不能再对代码细节有深入意见。就好像我是在技术上领导一个500人的工程组织。”
我不知道这句话会不会在几年后成为一代工程师的真实写照。但至少现在,它已经是一种可能。而 Harness Engineering,就是让这种可能从“OpenAI 实验室里的7个人”扩散到更广阔天地的那座桥。
11. 参考资料
以下所有资料我在写作时都一手核对过,按重要性排序,便于后续自己或读者查阅:
- Mitchell Hashimoto《My AI Adoption Journey》(2026-02-05)
mitchellh.com/writing/my-ai-adoption-journey
- OpenAI《Harness engineering: leveraging Codex in an agent-first world》(2026-02-11)
openai.com/index/harness-engineering/
- Ryan Lopopolo @ Latent Space Podcast《Extreme Harness Engineering for Token Billionaires》(2026-04-07)
latent.space/p/harness-eng
- Birgitta Böckeler《Harness engineering for coding agent users》@ Martin Fowler(2026-04-02)
martinfowler.com/articles/harness-engineering.html
- Ethan Mollick《A Guide to Which AI to Use in the Agentic Era》(2026-02-18)
oneusefulthing.org/p/a-guide-to-which-ai-to-use-in-the
- Can Boluk《The Harness Problem》(2026-02-12)
blog.can.ac/2026/02/12/the-harness-problem/
- LangChain《Improving Deep Agents with Harness Engineering》(2026-02)
langchain.com/blog/improving-deep-agents-with-harness-engineering
- Andrew Qu(Vercel)《We removed 80% of our agent's tools》(2025-12-22)
vercel.com/blog/we-removed-80-percent-of-our-agents-tools
- Stripe《Minions: Stripe's one-shot, end-to-end coding agents》(2026-02)
stripe.dev/blog/minions-stripes-one-shot-end-to-end-coding-agents
- Anthropic《Effective harnesses for long-running agents》(2025-11)
anthropic.com/engineering/effective-harnesses-for-long-running-agents
- Anthropic《Building a C compiler with a team of parallel Claudes》(Nicholas Carlini, 2026-02)
- Andrej Karpathy 的 Context Engineering 推文(2025-06-25)
x.com/karpathy/status/1937902205765607626
- Lee Han Chung《A Taxonomy of RL Environments for LLM Agents》(2026-03-21)
- Shunyu Yao et al.《ReAct: Synergizing Reasoning and Acting in Language Models》(ICLR 2023)
GitHub 项目:
- HKUDS/OpenHarness · aiming-lab/AutoHarness
- anthropics/claude-code · openai/codex
- langchain-ai/langgraph · crewAIInc/crewAI
- microsoft/agent-framework · google/adk-python
- modelcontextprotocol/python-sdk · a2aproject/A2A
- langgenius/dify · coze-dev/coze-studio
- github/spec-kit
 发表于 2026-4-25 09:06:48
|
查看: 286|
回复: 0
发表于 2026-4-25 09:06:48
|
查看: 286|
回复: 0
