知识就是那个摇柄。知识不是给到你,你就会了,然后你去应用——知识是给到你,这次没用,那就接着给、接着摇,不断地转,一直到有机会你突然一下被它点燃,砰,火苗起来。——罗振宇
2026年春天,技术世界正在同时发生三件事:Google发布Code Wiki,Cognition(Devin的母公司)把DeepWiki开放给所有公开仓库,Andrej Karpathy在X上分享他用LLM构建个人知识库的完整工作流。这三件事指向同一个方向——知识的生产者和消费者都在从人类迁移到机器,而Markdown正在成为这个时代的通用知识介质。
这不仅仅是一个技术话题。罗振宇用十年跨年演讲反复阐述的道理——知识的伟大不在于有用,而在于凝聚共识——在AI时代获得了全新的注脚:当AI agent成为文档的最大读者群体时,“共识”的含义从人与人之间扩展到了人与机器之间。
一、文档已死,Wiki永生
旧世界的痛:文档写完即过期
每个程序员都经历过这样的场景:花三天写了一份架构文档,两周后代码重构,文档就变成了历史遗迹。Stack Overflow的调查数据显示,过时或不准确的文档是开发者对内部工具最大的不满。开发者30%的工作时间花在阅读和理解别人的代码上,其中大量时间浪费在与代码脱节的文档上。
传统文档工具——GitBook、Docusaurus、Read the Docs——的根本问题不是功能不够,而是它们把文档当作一个独立的产出物。文档和代码是两条并行的河,靠人力维护同步,而人力永远是最不可靠的。
新范式:代码即唯一可信文档
2025-2026年涌现的一批产品,共同验证了一个假设:唯一100%可信的文档就是代码本身。如果文档能从代码自动生成、自动更新,“文档过期”这个问题就从根上消失了。
这个赛道上,四个重要玩家的路径各不相同,但目标完全一致:
| 产品 |
背后团队 |
发布时间 |
核心特点 |
定位 |
| DeepWiki |
Cognition (Devin) |
2025.5 |
5万+公开仓库索引,自动生成架构图,内置Devin问答 |
Agent的“读书笔记” |
| Code Wiki |
Google |
2025.11 |
Gemini驱动,每次commit自动重新生成文档,动态图表 |
开发者工具,免费公共仓库 |
| Repo Wiki |
Qoder |
2025 |
存储在 .qoder/repowiki,git提交共享,支持中英双语 |
IDE内嵌的agent知识层 |
| Mintlify Wiki |
Mintlify |
2026 |
替换GitHub URL即可生成文档站,零配置 |
面向外部的文档托管 |
二、DeepWiki:Agent给自己写的“读书笔记”
DeepWiki的故事要从Devin说起。Cognition在2024年发布Devin——号称“第一个AI软件工程师”——引发了巨大争议。但争议之下有一个被忽略的产品细节:当Devin接入一个新仓库时,它做的第一件事不是写代码,而是给自己生成一份wiki。
这个逻辑非常自然。一个人类开发者入职新团队,前几天干的也是同一件事——读代码、画架构图、记笔记。Devin只是把这个过程自动化了,并且把产出物开放给了人类。
2025年5月,Cognition将这个内部工具以DeepWiki的名义公开发布。把任何GitHub仓库的URL从 github.com 替换为 deepwiki.com,就能看到这个仓库的自动生成文档。上线不到一年,DeepWiki已经索引了超过5万个公开仓库。
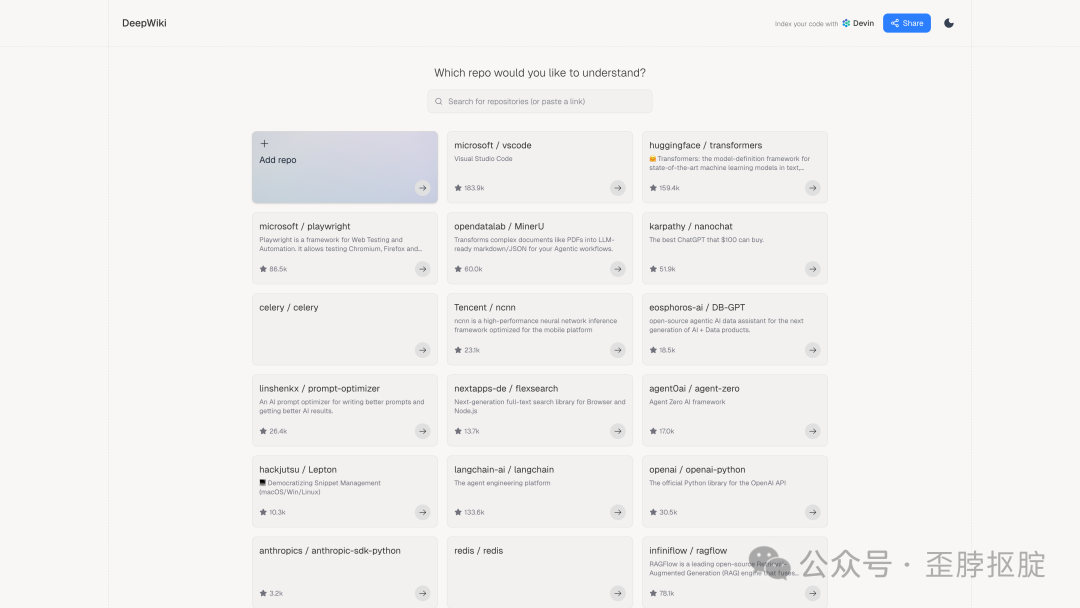
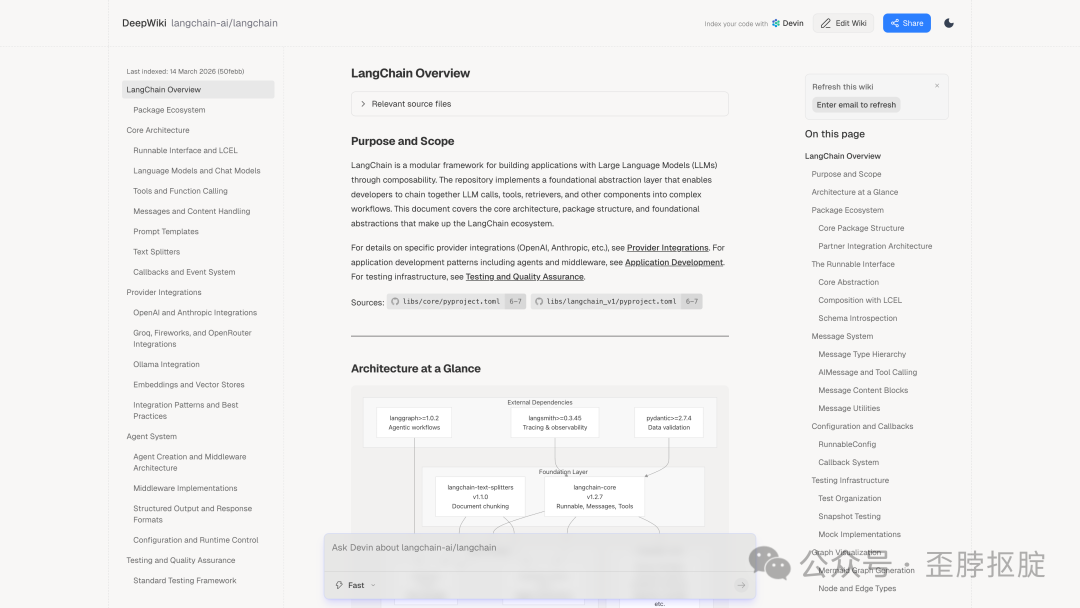
上面这张LangChain的wiki页面展示了DeepWiki的核心能力:自动生成的架构图(展示了LangGraph、LangSmith、LangChain-core之间的依赖关系和版本号),每个概念都链接到源码文件,左侧导航覆盖了从Core Architecture到Testing Framework的完整知识树。底部的“Ask Devin”输入框让你可以用自然语言提问——不是和一个通用模型对话,而是和一个已经读过整个代码库的agent对话。
DeepWiki还提供了MCP Server,暴露 ask_question、read_wiki_structure、read_wiki_contents 三个工具。这意味着其他AI agent可以直接调用DeepWiki的知识——agent产生的知识被其他agent消费,形成一个代码理解的供给网络。
对于私有仓库,用户可以通过Devin账户获取wiki,或者在仓库根目录放一个 .devin/wiki.json 配置文件来控制文档生成的重点和结构。
三、Google Code Wiki:大厂的时代宣言
Google在2025年11月发布Code Wiki时,官方博客的副标题是:“A new perspective on development for the agentic era.” 这不是一个文档工具的slogan,这是一个时代宣言。
Google做这件事的背景和DeepWiki不同。Google内部有全球最大的单体代码库(monorepo),几十年来一直在解决“如何让工程师理解不是自己写的代码”这个问题。Code Wiki是这套内部经验的外化产品。
Code Wiki和DeepWiki的关键差异在于更新策略。DeepWiki是索引时生成一次(可以手动刷新),Code Wiki则在每次commit后自动重新生成文档。这意味着你看到的架构图、类图、时序图永远反映代码的当前状态,而不是上次索引时的快照。
Code Wiki的另一个特点是Gemini chat的集成方式:整个最新的wiki作为上下文注入chat,所以Gemini的回答能精确地链接到具体的代码文件和函数定义。Google的愿景很明确——新人入职第一天就能提交代码,资深工程师几分钟内理解一个新库,而不是几天。
目前Code Wiki的公开版免费支持公共仓库(codewiki.google),私有仓库的Gemini CLI扩展正在waitlist。
四、Qoder Repo Wiki:存在Git里的Agent知识层
如果说DeepWiki和Code Wiki是云端的文档生成服务,Qoder的Repo Wiki走了一条更“接地气”的路——生成的wiki直接存储在你的代码仓库里。
Qoder是一个agentic coding平台,Repo Wiki是它的核心功能之一。当你在Qoder IDE中打开一个项目,可以一键生成整个仓库的结构化文档。生成的wiki存储在 .qoder/repowiki 目录下——它就是你仓库的一部分,可以 git commit 和 git push,团队成员 git pull 就能拿到。
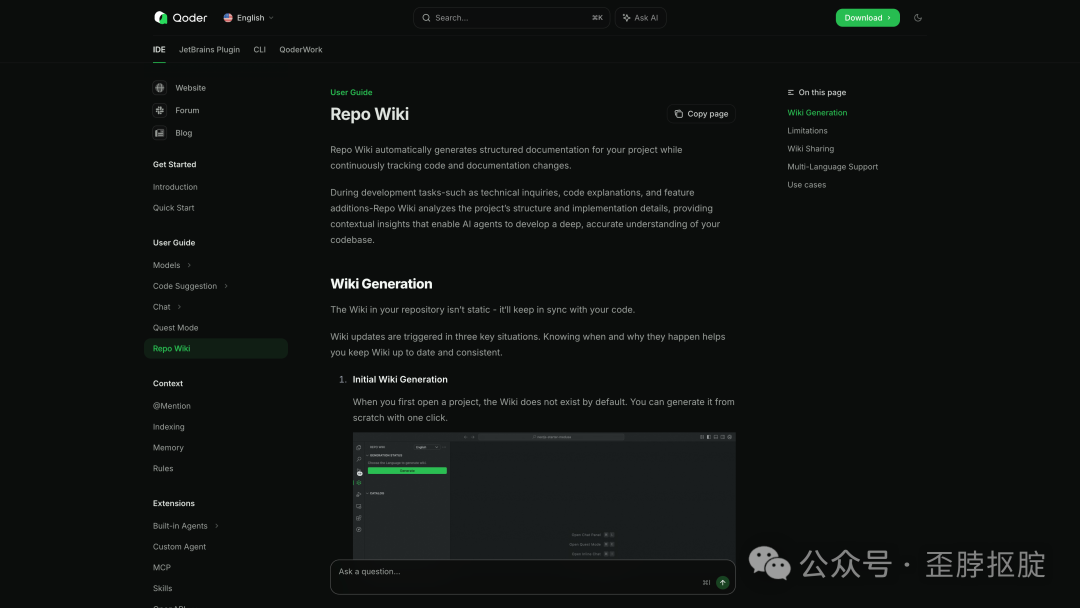
这个设计选择看似简单,实际上解决了一个DeepWiki和Code Wiki都没解决的问题:wiki的所有权和版本控制。当wiki和代码在同一个Git仓库里时,你可以看到wiki的变更历史,可以在code review时同时审查文档变更,可以在分支之间切换时看到不同版本的文档。这不是“文档作为外部服务”,这是文档作为代码的一等公民。
Repo Wiki的更新机制分三种触发方式:
- 初始生成——对一个4000文件的仓库,大约需要120分钟。这个时间不短,但只跑一次。
- 代码变更检测——当你修改了被文档引用的文件(函数签名、类定义、API端点等),系统检测到不匹配,只重新生成受影响的部分。
- Git目录同步(v0.2.0+)——如果你直接编辑了Git目录下的Markdown文件,系统检测到差异后可以同步更新。
截至目前,Qoder已经生成了超过 40万份 代码库wiki。这个数字透露了一个信号:开发者(和agent)对“自动理解代码”的需求远比想象中要大。Repo Wiki还支持中英文双语生成——在 repowiki/zh/ 和 repowiki/en/ 下分别维护不同语言的文档,这对跨国团队是刚需。
Repo Wiki的核心使用场景是 agent驱动的开发任务。当Qoder的agent需要加新功能、修bug或重构时,它首先读取Repo Wiki来理解项目架构和实现细节,然后才动手写代码。这和DeepWiki的理念完全一致——agent要高效工作,第一步是给自己建一份“读书笔记”。不同之处是Qoder把笔记留在了仓库里,而不是云端。
五、Mintlify:从文档美化到知识基础设施
在这个赛道里,Mintlify的起点和上面三家不同——它不是从AI agent的需求出发的,而是从“让开发者文档变好看”出发的。2022年从YC W22毕业时,Mintlify做的事很简单:极简配置就能生成带搜索、暗黑模式、代码高亮的文档站。Anthropic、Perplexity、Vercel等AI公司都在用它。
但Mintlify有一组数据让整个行业侧目。2026年3月,它分析了旗下文档站30天内约7.9亿次请求的Cloudflare User-Agent数据:AI Agent的请求量(45.3%)几乎追平了浏览器(45.8%)。Claude Code单月1.994亿次请求,超过了Chrome on Windows。
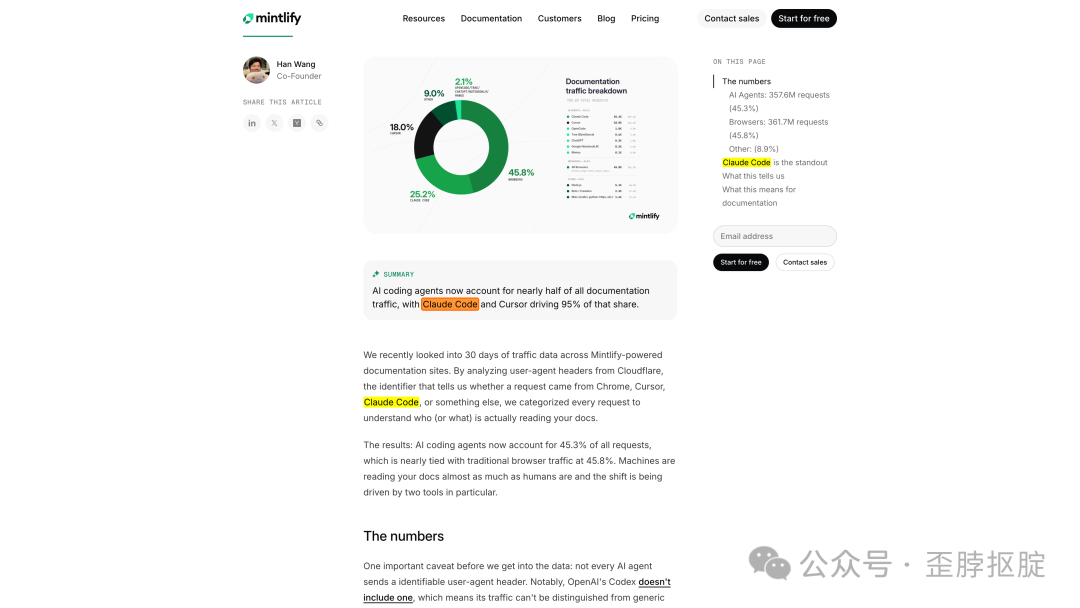
这组数据有一个重要的caveat:它的样本全部来自Mintlify托管的2万多个文档站,这些站主要服务开发者工具和API文档——本身就是AI coding agent最频繁访问的内容类型。统计单位是请求数而非独立用户(一个Claude Code session调API时可能几分钟发几十次请求),所以不能简单推论为“45%的人在用agent看文档”。但即便打折扣,趋势本身是清晰的:机器正在成为文档的主要消费者。
这个发现促使Mintlify转型。它在2026年4月以5亿美元估值完成了a16z和Salesforce Ventures领投的4500万美元B轮融资(累计融资6700万美元),定位从“文档平台”变成了“AI知识基础设施”。新产品线包括Workflows(自动化文档更新)、MCP支持(让agent直接查询文档)、以及零配置的Mintlify Wiki(把GitHub URL的 github.com 替换为 mintlify.com 即可生成文档站)。
六、Karpathy的LLM知识库:当AI不再只是写代码
上面四个产品解决的都是“代码文档”问题。Andrej Karpathy在2025年底分享的LLM Knowledge Bases工作流,把这个话题推向了更广阔的维度:AI不只是代码的消费者,它可以成为任何领域知识的编译器。
Karpathy的方法很直接。原始材料(论文、文章、仓库、数据集、图片)被丢进一个 raw/ 目录,然后让LLM“编译”出一个wiki——一组带目录结构的Markdown文件。wiki包含所有原始数据的摘要、反向链接,按概念分类,为每个概念写文章,并互相链接。
project/
├── raw/ # 原始材料,只读
│ ├── papers/
│ ├── articles/
│ └── images/
├── wiki/ # LLM编译产物
│ ├── index.md
│ ├── concepts/
│ ├── entities/
│ └── sources/
└── outputs/ # 查询/分析的输出
├── reports/
└── slides/
这套系统的精妙之处在于知识复利。当你向wiki提问,LLM会遍历相关文章,综合出答案。如果这个答案涉及三个以上已有页面、产生了新的综合洞察,它就被写回wiki。每一次使用都让知识库变得更完整。Karpathy自己的一个研究wiki已经积累了约100篇文章、40万字。在这个规模下,LLM通过自动维护索引文件和文档摘要,不需要复杂的RAG系统就能很好地回答问题。
Karpathy用Obsidian作为前端,用它的图谱视图来发现概念之间的涌现性连接。他还会定期跑“健康检查”——让LLM找出不一致的数据、填补缺失信息、发现有趣的连接点来产生新文章候选。这不是AI辅助写作——这是AI作为知识管理员,人类反而变成了偶尔提问和审阅的角色。
他在帖子末尾写了一句意味深长的话:
I think there is room here for an incredible new product instead of a hacky collection of scripts.
这句话在发布后不到半年就被验证了。
七、LLM-Wiki项目:Agent的外脑
Karpathy的帖子引爆了一个社区运动。nvk的 llm-wiki 项目把Karpathy的思路变成了一个可复用的系统,作为Claude Code插件发布,安装只需一行:
claude plugin install wiki@llm-wiki
也可以用一个 AGENTS.md 文件做到全平台兼容——Codex、OpenCode、Gemini、任何能读写文件和搜索网络的agent都能用。SamurAIGPT的fork版本(llm-wiki-agent)已经获得了超过2100个GitHub star。
这个系统的核心设计是四个操作形成闭环:
/ingest(原始来源 → wiki页面)
↓
/query(问题 → 合成答案 + 写回)
↓
/lint(健康检查 + 自动修复)
↓
/research(引入外部源)
↓
(循环回 /ingest)
知识被分为严格隔离的三层:原始材料(sources/)永远不修改,提炼知识(wiki/)由agent维护,操作日志(wiki-log.md)记录每一次变更。这种分层的核心理念用一句话概括:vault是agent的外脑。llm-wiki把“知识库”从人类工具变成了agent-native工具——由agent写,给agent和人类读。
用户提到的OpenCLI实践更进一步:wiki agent作为agent team的一部分参与项目管理,实时摄入项目的设计决策和交付成果。两层架构(AGENTS.md + Skill)是这个设计理念的产物——AGENTS.md定义agent的行为规范和工作流,Skill文件提供领域知识。wiki的产出物是知识库图谱,兼容Obsidian进行可视化浏览。初始阶段不做GUI,因为内容维护是Agent本身的工作——GUI只做展示用。
这种设计暗合了一个更深层的趋势:在multi-agent架构中,共享知识库不是可选项,而是agent协作的基础协议。没有wiki,agent之间就只能通过上下文窗口传递信息,这既昂贵又有损。
八、罗振宇的隐喻:知识的摇柄与信用的长期主义
把一个知识付费领域的创业者和AI代码文档放在一起讨论,看起来跨界得有些离谱。但罗振宇在最近的访谈中说的几段话,恰恰切中了这一轮“wiki热”的哲学内核。
第一层:知识是摇柄,不是说明书。
罗振宇用东北冬天启动大卡车的曲柄来比喻知识:知识不是给到你就能用的,你得不断摇、不断转,直到某个时刻被点燃,生命按这种方式燃烧起来。
这个比喻精确地描述了Karpathy的LLM知识库在做的事。原始材料被ingest进来的时候,它们只是“生的”——论文摘要、代码注释、API文档。LLM把它们编译成wiki的过程,就是“摇”的过程:建立链接、发现矛盾、产生综合。你向wiki提问,答案被写回去,知识库变得更完整。这不是一次性的知识传递,是持续转动的飞轮。
第二层:知识的伟大不在有用,在凝聚共识。
罗振宇在被追问“知识是不是太实用化了”的时候回答:知识最主要的价值不是教你怎么做药、怎么造机器,而是凝聚共识。他做跨年演讲,生产的不是知识本身,而是“共识的议题”——提出一个议题,大家讨论这个议题,好的议题推进文明的进步。
这和代码wiki解决的问题本质上是同构的。一个代码库的wiki不只是告诉你“这个函数做什么”,它提供的是整个团队(包括AI agent)对系统的共享理解。当Google Code Wiki说“你不是在和一个通用模型对话,而是在和一个完整了解你代码库的模型对话”时,它在说的其实就是:我们为人和agent之间建立了关于这份代码的共识。
第三层:信用胜于流量。
罗振宇在访谈中反复强调:互联网时代永远的逻辑是“点赞、关注、转发”,但正常社会的状态是“谁有信用我看谁”。信用是长期积累的、难以伪造的资产。他选择做得到、做文明之旅、坚持3652天日更60秒语音,本质上都是在积累信用。
文档——可靠的、准确的、永远最新的文档——是软件产品的信用。一家公司改了定价,帮助中心没更新,所有基于这个内容构建的AI support agent就开始给客户报错误的价格。流量(agent请求量)可以很高,但如果内容不可信,流量越大伤害越大。
罗振宇说“以万变引入自己体内来保持自己不变”——接受新技术、新工具、新的内容形态,但核心不动。这个“不变”的核心是什么?对DeepWiki是代码的准确理解,对Qoder是存在Git里的可信文档,对Karpathy的wiki是经过编译和验证的知识——都是信息的准确性。形式从静态文档变成AI-powered wiki,读者从人类变成agent,但“信息准确”这件事永远不变。
九、一个正在发生的融合
把上面所有的线索拉在一起,我们看到的是一幅正在拼合的图景:
┌──────────────────┐
│ 代码 / 原始知识 │ ← 唯一可信源
└────────┬─────────┘
│ 自动编译
┌────────▼─────────┐
│ Wiki / 知识库 │ ← Markdown,结构化
└──┬────────────┬──┘
│ │
┌────────▼──┐ ┌───▼────────┐
│ 人类阅读 │ │ Agent消费 │
│ (Obsidian, │ │ (Claude Code,│
│ 浏览器) │ │ Cursor, │
└────────────┘ │ Codex) │
└──────────────┘
代码文档领域(DeepWiki、Google Code Wiki、Qoder Repo Wiki、Mintlify Wiki)解决的是“从代码到可读文档”的自动化,核心价值是消灭文档过期。
个人/团队知识库领域(Karpathy的LLM Knowledge Bases、nvk的llm-wiki、OpenCLI的实践)解决的是“从任意来源到结构化知识”的编译,核心价值是知识复利。
两者正在融合。Qoder的Repo Wiki存在Git里,本质上已经是代码仓库的知识层。llm-wiki的 /research 命令可以引入外部源,做的事和代码wiki一样。Google Code Wiki的Gemini chat和Karpathy的wiki Q&A在技术路径上几乎完全一致——区别只在于知识源是代码还是论文。DeepWiki的MCP Server让wiki成为agent可调用的工具,而不只是人类阅读的页面。
这个融合的底层逻辑是:AI agent需要一个比上下文窗口更持久、比RAG更结构化的知识层。上下文窗口是工作记忆——昂贵、有限、易失。RAG是按需检索——适合问答,但缺乏整体图景。Wiki是编译后的知识——结构化、持久、可增量更新、人机共读。
当agent成为文档的主要消费者,文档的形态必然会进一步向“机器友好”演进——不是牺牲人类可读性,而是两者恰好在Markdown + 良好结构这个交叉点上高度兼容。
十、这意味着什么
对于不同角色的人,这场变化的实际含义不同。
如果你是开发者——你的文档正在被AI agent阅读的频率可能已经超过了人类。API参考的一致性、代码示例的完整性、参数描述的精确性,这些“过去觉得可以凑合”的东西,现在直接决定了AI agent能不能正确地帮用户使用你的产品。考虑用DeepWiki、Code Wiki、Qoder Repo Wiki这类工具,让文档自动保持最新。
如果你是个人研究者或知识工作者——Karpathy的方法论值得认真实践。不需要等待一个完美的产品,现在就可以用Claude Code + llm-wiki或者类似的方案开始构建自己的知识库。关键心智转换是:你不再是知识库的维护者,而是提问者和审阅者。LLM负责写、链接、发现矛盾、填补缺失,你负责输入高质量的源材料和提出好问题。
如果你在做团队管理——团队的共享知识库从“nice to have”变成了“agent协作的基础设施”。当你的团队开始使用AI agent开发时,agent理解代码库的能力直接取决于有没有一份好的wiki。Qoder的Repo Wiki给出了一个直接的方案——wiki存在仓库里,随代码一起版本控制。OpenCLI的实践给出了另一个范式——wiki agent作为team的一部分,实时维护,Obsidian可视化,AGENTS.md定义规范。
罗振宇说人这一辈子就是“奋力向前爬行”。知识也是。从泥板到纸张到网页到wiki,知识的载体在变,但“凝聚共识、点燃他人”的内核不变。只不过现在,被点燃的不只是人,还有机器。
 发表于 2026-4-23 02:16:11
|
查看: 240|
回复: 0
发表于 2026-4-23 02:16:11
|
查看: 240|
回复: 0
