所有Agent框架都会碰到同一个瓶颈:上下文窗口终究是有限的,装不下模型需要的全部信息。会话越来越长、文件越读越多、子任务调用越来越频繁、工具返回结果不断累积——框架必须在“保留哪些内容”“压缩哪些内容”“延后调用哪些内容”之间做出权衡。
不管是ChatGPT还是DeepSeek,会话拉长后模型都会逐渐模糊最初的任务目标;冗长的模板内容往往占掉近半的上下文;各种工具输出更是挤占了本该留给有效对话的空间。
现在真正关键的问题已经不是“往提示词里放什么”,而是“框架如何长期、动态地管理上下文”。优秀的系统不会把上下文窗口当成被动的文本缓冲区,而是主动调控:常驻核心高价值状态信息、按需调取数据、用索引快速检索所需内容(grep这类文本检索工具正是这个思路),同时以合理的截断方式保留线索,提示用户或模型可以去取更多完整内容。
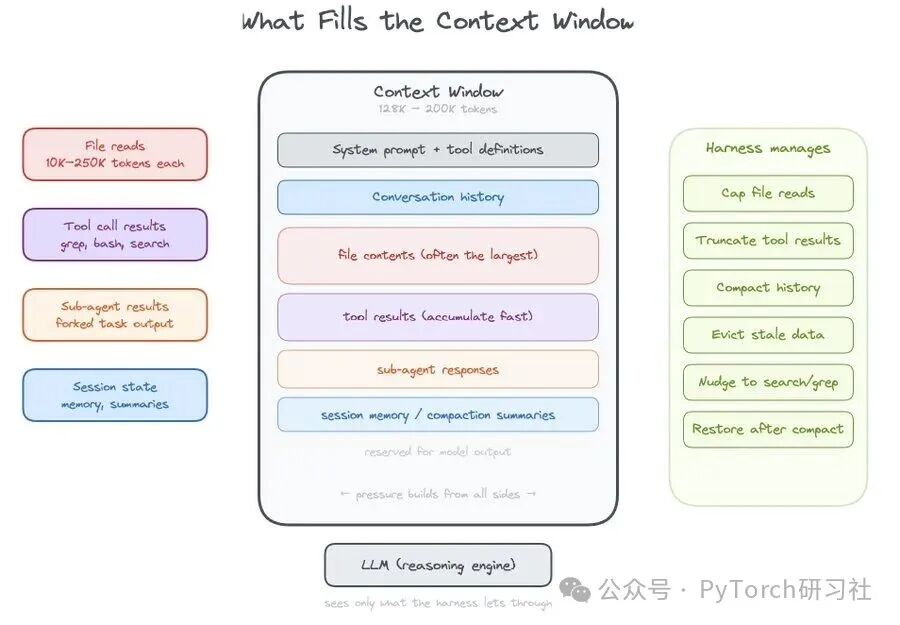
OpenClaw、Claude Code等Agent在这个问题上的做法各有不同,但路线正在逐渐收敛,背后是一套趋于共识的底层逻辑。上下文已经不再是“能塞进对话记录里的东西”,而是需要系统主动管理的资源。真正的设计核心在于:多少管理逻辑由Agent框架承担,又有多少得交给模型自己去处理。
核心思路:让模型自己管理上下文
每一项上下文管理策略,其实都暗含对模型行为的预设。关键分歧在于:框架到底要不要主动限制上下文占用,还是信任模型能自行把控资源配额?
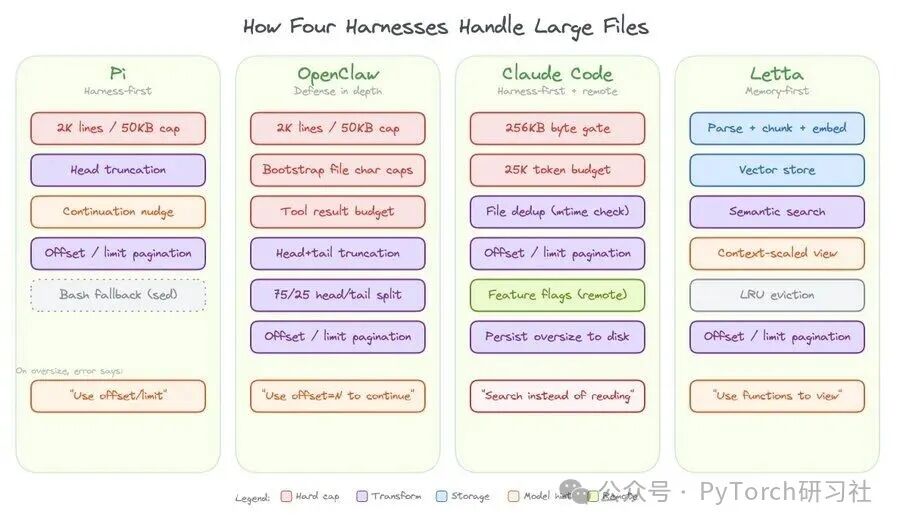
文件读取就是个很直观的例子。当模型要读的文件超过上下文容纳上限时,必须由某一方来决定保留哪些内容。OpenClaw和Claude Code都支持偏移量与限制条数参数来实现分页读取。
OpenClaw
OpenClaw 读取文件设有硬性上限:最多 2000 行或 50 千字节,以先到者为准,即便模型没有要求分段读取也会强制限制。内容从开头截断,工具输出末尾会附带明确的续读提示:“当前展示 1–2000 行,共 50000 行。可使用 offset=2001 继续读取”。工具说明中也明确标注:输出内容将截断至 2000 行或 50 千字节;大文件请使用偏移量与条数限制参数。
在此基础上,它对启动文件(会话初始加载的一次性上下文文件)增设额外限制:单文件上限 12000 字符,整体总计上限 60000 字符。若启动文件超出配额,会采用前 75%+ 后 25% 的拆分策略:保留文件首尾内容,删减中间段落。
工具返回结果也设有独立配额:16000 字符,或上下文窗口容量的 30%,取两者较小值。若识别到文件尾部存在关键内容(报错信息、JSON闭合符号、总结类关键词),会自动切换为首尾保留模式;否则仅保留文件开头内容。
OpenClaw 采用的是多层防护方案:以截断规则作为第一层防护,额外限制启动文件注入内容,再叠加工具输出配额管控。
Claude Code
Claude Code 为文件读取设置双层防护机制。第一层是读取前校验:打开文件前通过文件状态检测,设置 256 千字节的大小上限;文件超标则直接拒绝读取并返回错误提示,引导模型改用分页参数或检索指令。第二层是读取后校验:统计输出 token 数,上限 25000 token,用于拦截体积合规但文本密度过高的文件。两项限制均可通过 GrowthBook 功能标签远程调整,无需更新客户端版本。
即便文件未超出限制,工具默认仅返回开头 2000 行,且单行字符超过 2000 也会被截断。模型必须手动填写偏移量与条数参数才能读取更多内容。
工具说明为多段落完整提示词,详细讲解分页规则、大小限制,适配图片、PDF、笔记类文件,并支持多文件并行读取。偏移量、限制条数参数均配有独立说明,明确适用于超大文件分段读取。同时可根据功能标签,选择性在提示词中直接展示 256KB 限制规则。
其文件去重机制也极具实用价值:若模型重复读取同一文件的相同区间且文件无修改,系统将返回精简摘要,避免上下文出现重复 token 冗余。
Claude Code 是一套可远程调控的框架优先方案:包含读取前字节校验、读取后 token 校验、行数与单行长度限制、引导式报错、详尽工具说明、读取去重,以及服务端动态可调的功能配置。
真正的工程难点:会话精简
随着对话不断变长,所有 Agent 框架都必须抉择哪些内容保留、哪些舍弃。这恰恰是设计差异最关键的体现——内容压缩策略直接决定了长期运行的 Agent 是能保持逻辑连贯,还是逐步劣化。
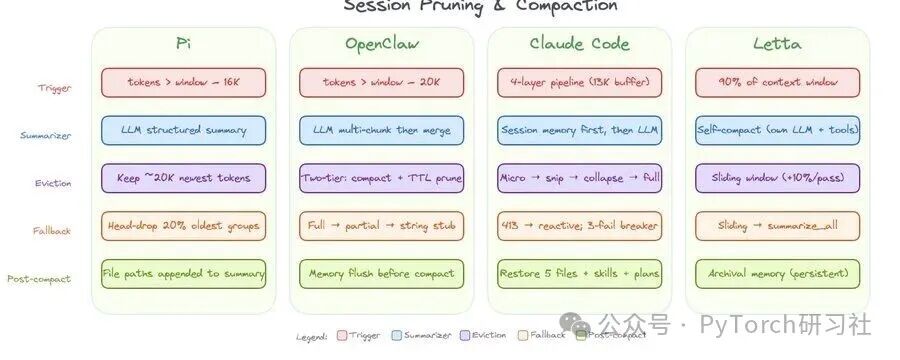
OpenClaw
OpenClaw 采用基于大模型摘要的压缩机制,由 token 阈值触发执行。
- 触发条件:对话历史占用超过上下文窗口的 50%(最大历史占比,默认值 0.5)
- 保留内容:将历史记录按 token 量均匀分块;丢弃最旧分块,保留剩余内容,并修复工具调用与返回结果的配对关系
- 内容摘要:被丢弃的内容会经过多阶段、多轮大模型摘要处理,并执行内容合并
- 摘要存放:将生成的摘要消息前置到保留的后续对话内容开头
- 工具调用安全:通过 repairToolUseResultPairing 修复分块删除后孤立的工具返回数据;借助 splitMessagesByTokenShare,避免在工具调用/结果配对中间截断内容
- 压缩前状态留存:执行一次静默 Agent 轮次,在历史内容清理前将运行状态持久化至记忆文件
- 第二层机制:对工具结果进行无损内存精简(先软截断,再强制清空),缓存有效期五分钟;在保障完整对话记录不被破坏的同时,为当前请求释放上下文空间
Claude Code
Claude Code 依靠查询前优化与大模型摘要压缩双重方式管理上下文。
Sub-agent 上下文管理
无论是 OpenClaw 还是 Claude Code,都不会把完整的父级对话历史复制给 sub-agent。Sub-agent 普遍与父会话相互隔离。
两者的核心差异在于:sub-agent 会继承哪些工作空间上下文。
OpenClaw 默认给 sub-agent 分配全新的隔离会话,不继承父对话记录。它提供分支复制模式,仅在同类型 Agent 派生场景下才会将父会话记录同步至 sub-agent;工作空间上下文会经过过滤,仅保留最小白名单文件(AGENTS.md、TOOLS.md、SOUL.md)。
Claude Code 包含两种运行模式。默认的 typed-agent 模式会创建空白对话:委派指令作为唯一用户消息,无任何父级历史。新增的分支派生模式则会把完整父会话消息同步给 sub-agent,实现提示缓存复用,同时附带一条合成助手消息与占位工具返回结果。工作 agent 会重新初始化独立权限的工具;异步 agent 拥有明确权限白名单(读取、检索、路径匹配、终端命令、编辑、写入、网页搜索等)。Agent 配置中引用的能力模块会提前预加载,完整技能文档以用户消息形式注入初始会话,而非按需加载。
写在最后:趋同之处
最关键的结论并不是彼此的区别,而是高度的共识。OpenClaw 和 Claude Code 都对文件读取设置硬性上限、支持偏移/分页读取、限制工具输出体积、隔离 sub-agent 会话、基于 token 阈值触发大模型摘要压缩、实时估算上下文占用并识别资源压力。这并非巧合,而是面对同一工程难题的趋同解法:在有限的固定上下文空间里,实现近乎无限的使用体验。
这种趋同不止停留在功能层面,核心设计思路高度契合:Claude Code 与 OpenClaw 都会将超大工具结果持久化至本地;两者在压缩精简时都严格保证工具调用与返回结果的边界完整;它们都支持将父会话记录分支同步给 sub-agent。OpenClaw 和 Claude 彼此独立研发,最终却形成了一致的最优方案。
五十年的计算机发展史早已证明:最优的内存管理,是让程序完全无感的管理。寄存器、缓存行、页表、交换分区,每一层都由系统自主调度,对上层完全透明。程序只需正常运行即可。
Agent 框架也正朝着这一方向演进。其目标并非把所有信息全盘交给模型,而是在恰当的时机为其提供恰到好处的工作集,并让模型能自主动态决策、管理自身上下文。
如果你对这类工程实践感兴趣,不妨在云栈社区上找到更多同行的深度讨论。
 发表于 2026-4-29 07:27:19
|
查看: 157|
回复: 0
发表于 2026-4-29 07:27:19
|
查看: 157|
回复: 0
