引言
对于自回归结构的 Transformer 模型,AI 推理过程面临的问题已从传统的受限于计算密度变为受限于显存带宽(Memory Bandwidth Bound)。算力单元的空转不再是因为 ALU 能力不足,而是因为数据搬运速度远滞后于运算需求。为了优化首字响应时间(TTFT)并降低推理成本,全球半导体产业正经历一场从底层物理结构到软件调度逻辑的根本性变革。
本文将深度剖析四种驱动 AI 推理 Token 成本下降的代表性技术路径:Groq(SRAM 极致时延)、 迈特芯/MetaChip(3D-DRAM 立方脉动)、 微珩科技(冷热异构存储分层)、微纳核芯(3D-CIM 存算一体)。这些技术解决方案代表了从“存储靠近计算”到“存储即计算”的范式跃迁。
一、Groq LPU:SRAM 架构与软件定义执行的确定性巅峰
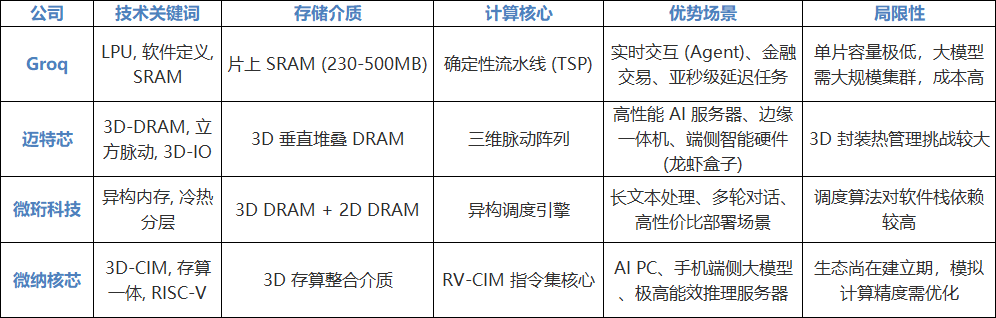
Groq以其语言处理单元(LPU)重新定义了实时交互的物理极限。其核心逻辑在于通过牺牲存储密度来换取极致的确定性时延。
· 存储物理学:6T SRAM vs. 1T1C DRAM
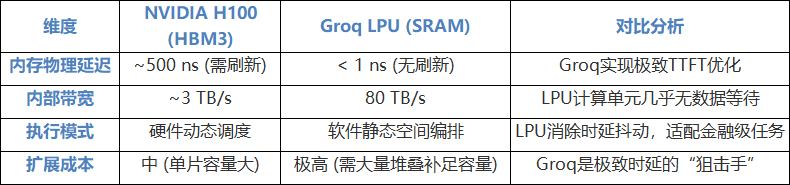
Groq抛弃外部DRAM,集成230MB至500MB的片上SRAM。在物理层,SRAM采用 6管(6T)结构,通过交叉耦合电路维持状态,无需 DRAM(1T1C结构)那样的周期性刷新操作。这意味SRAM消除了由于“刷新延迟”引入的不确定性,其内部带宽高达 80TB/s,是 NVIDIA H100的20倍以上,可使计算单元利用率趋近100%。
· 确定性调度:消除长尾延迟的数学手段
Groq彻底取消了硬件动态调度(如分支预测和乱序执行),代之以空间编排(Spatial Orchestration)。编译器在编译阶段即规划好每个数据包在芯片上的精确运行轨迹。这种“确定性”使得TTFT得到了物理层面的保障,消除了云端推理中常见的延迟抖动。
· 互联协议:Plesiosynchronous 的跨芯片协同
针对 SRAM 容量瓶颈,Groq通过 RealScale网络 与 Plesiosynchronous(近同步)协议 将数百颗芯片连接。该协议能抵消时钟漂移,使整个机柜在逻辑上如同一个超大型单核处理器,实现了亚毫秒级的跨节点通信,极大优化了 MoE 模型的通信效率。
表 1:NVIDIA H100 与 Groq LPU 指标对比
如果说 Groq 是极致时延的狙击手,迈特芯则是针对大容量、高带宽需求设计的“重装步兵”。其通过三维集成技术在成熟工艺上实现了性能对先进工艺的“换道超车”。
1. 核心架构解密:立方脉动计算
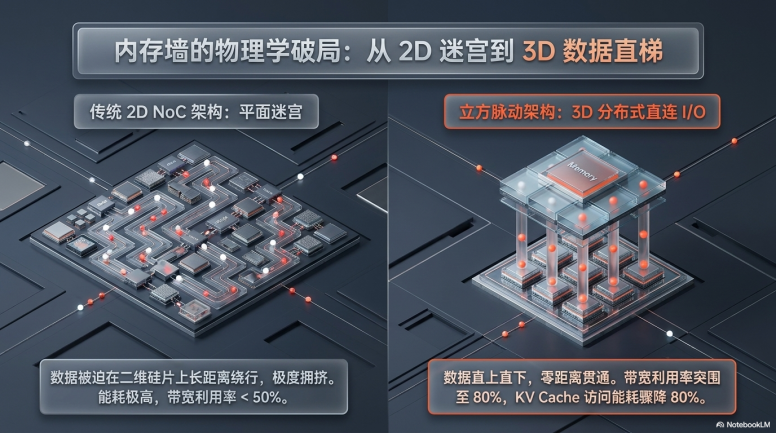
迈特芯架构的核心创新在于将计算阵列从二维平面提升至三维空间的立方脉动计算(Cubic Systolic Array),这不仅是物理堆叠,更是数据流向逻辑的根本重构。
● 维度扩展与路由优化: 传统的二维 NoC(片上网络)在数据传输时必须绕行芯片边缘的I/O接口,导致严重的拥塞与延迟。迈特芯架构利用垂直空间,将处理单元(PE)通过海量TSV(硅通孔)与上方的存储层直接相连。这种“PE-to-3D IO”的直连模式,使数据路径从毫米级缩短至微米级,大幅消除了全局布线的寄生电容。
● 高利用率的计算逻辑: 配合编译器实现的确定性执行(Deterministic Execution)模式,系统通过软件定义调度,确保数据在计算周期内精确到达PE单元。这种设计消除了传统缓存缺失(Cache Miss)带来的不确定性,将计算单元的有效利用率从传统架构的不足50%提升至80%以上。
● 面积效率与收率平衡: 在 93mm² 的单元面积内,迈特芯通过成熟制程实现了极高的计算密度,并保持了80%-90%的晶圆良率,确保了大规模量产的成本优势。
2. 3D-DRAM与近存计算:垂直集成的物理实现
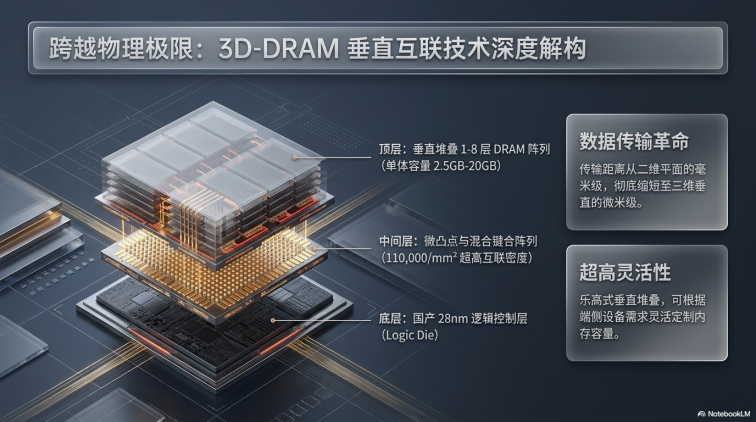
立方脉动架构的物理基础依赖于先进的混合键合(Hybrid Bonding)技术,这是终结“存储墙”的关键路径。
● 超高连接密度: 通过混合键合工艺,迈特芯实现了高达 110,000/mm² 的互联密度。DRAM存储阵列被划分为多个分布式Bank,垂直覆盖在逻辑芯片之上。
● 3D分布式I/O: 传统的 2.5D HBM 方案受限于硅中介层(Interposer)的平面布线,而迈特芯的3D分布式I/O允许逻辑层从芯片任何坐标点通过TSV“垂直存取”数据。这种近存计算(Near-Memory Computing)架构将访问能耗降低了约80%。
● KV Cache性能增益: 在 Transformer 模型的解码阶段,高频率的KV Cache读取是响应速度的瓶颈。3D-DRAM提供的600GBps超高带宽,确保了在autoregressive过程中的向量提取具备极低时延,从而实现了卓越的词元能效比(Token/W)。
三、微珩科技:异构内存子系统与冷热数据分层策略
并非所有的 AI 推理数据都需要同等性能的存储。通过对 Transformer 推理流程的深度解构,微珩科技提出了3D DRAM与2D DRAM融合的异构内存方案,以实现成本、容量与速度的最优解。
1. LLM 推理的冷热数据分层理论
在大模型推理过程中,数据流表现出鲜明的异构特征:
- 热数据 (Hot Data):主要包括正在处理的 Token 激活值、中间隐藏层向量以及频繁更新的 KV Cache。这部分数据需要极高的读写频率和极低的时延,且其数据量与生成的序列长度成正比。
- 冷数据 (Cold Data):主要是模型固有的权重参数。虽然参数总量巨大,但在单次推理过程中,每层权重通常只需读取一次。
微珩科技的方案是将 3D DRAM(高带宽、低延迟、垂直互联)作为高速缓冲层和热数据存储中心,而将传统的2D DRAM(如LPDDR5/DDR5)作为背景权重存储层。这种混合架构不仅大幅缓解了 KV Cache 带来的内存爆炸问题,还利用2D DRAM的低成本优势实现了模型容量的大规模扩展。
2. 异构存储控制与数据调度
微珩科技的技术线路核心在于其高度智能的异构存储控制器。该控制器能够预测模型运行过程中数据访问的模式,自动执行“预取”和“换回”操作。当计算进入 Transformer 的下一层时,控制器会提前将该层的权重从冷存储(2D DRAM)调入热存储(3D DRAM)的逻辑缓冲层,从而实现了类似于“零延迟切换”的效果。这种软硬协同的方案使得系统在处理长文档理解和复杂多轮对话时,能够保持极高的硬件利用效率。
四、微纳核芯:3D-CIM 存算一体架构的范式突破
微纳核芯代表了目前 AI 算力扩展的最前沿路线——3D存算一体(3D-CIM)。该公司认为,要彻底解决冯·诺依曼瓶颈,单纯将内存移近计算(Near-Memory)是不够的,必须将计算直接嵌入存储(In-Memory)。
1. 3D-CIM 架构的物理实现与优势
3D-CIM架构的核心是将计算逻辑直接集成在3D堆叠的存储元胞内部。微纳核芯不再依赖最先进的极紫外(EUV)光刻工艺,而是通过架构层面的根本性变革来提升算力。在物理结构上,3D-CIM利用垂直方向上的电流或电荷操作来实现矩阵乘加(MAC)运算。由于计算就在数据存储的原位发生,系统不再需要传统意义上的数据总线,从而彻底消除了数据搬运能耗。据其公布的数据,3D-CIM架构在算力密度和能效比方面处于全球领先地位,相比传统架构可实现量级上的提升。
2. RV-CIM 指令集与 RISC-V 生态融合
为了让这种新型架构易于开发,微纳核芯牵头制定了 RISC-V 存算一体指令集标准(RV-CIM™)。通过在成熟的 RISC-V 开源生态中引入存算一体专用指令,开发者可以像编写普通代码一样调度存算阵列,极大地降低了算法部署的门槛。
微纳核芯的目标是构建“新摩尔定律”,即不通过单纯缩小晶体管尺寸,而是通过增加计算层的维度来持续扩展算力。其产品线目前瞄准 AI PC、AI 手机以及云端推理服务器,致力于成为后摩尔时代的中国算力基座。
表 2:全球AI推理架构创新多维对比矩阵
迈特芯与微纳核芯的路径证明了,利用先进封装(3D-IC)与架构创新,中国可以在28nm等成熟制程上实现对先进制程芯片的性能超越,这是国产芯片“换道超车”的核心推力。随着MoE架构的普及,迈特芯的立方脉动阵列通过分布式I/O解决了稀疏激活带来的寻址瓶颈,将成为未来重型推理场景的首选。
基于 OpenClaw 代理式智能体应用需求,迈特芯提供了软硬一体化 Turn-key(交钥匙)方案,涵盖 LPU芯片、SoC 主控适配及 MetaClaw 操作系统。其芯片产品矩阵 MC-Mega 系列(3D-DRAM 强化版)大致如下:
- MC-Mega-188 (Base): 配备 2.5GB 3D-DRAM,功耗仅 2W,面向平板、教育玩偶及智能盒子。
- MC-Mega-288 (Pro): 配备 5GB 3D-DRAM,功耗 5W,支持 7B 模型,适配扫地机器人、四足机械狗。
- MC-Mega-488 (Pro+): 配备 10GB/20GB 3D-DRAM,针对边缘 NAS、医院问诊仪,支持 30B 稠密模型。
- MC-Giga 系列: 配备 80GB 3D-DRAM,通过 8 芯片分布式方案,支持 122B 超大模型推理。

其“软硬一体化”的 MetaClaw 系统通过标准化接口可实现 AI 集成的“交钥匙(Turn-key)”体验。
- “南向”模型兼容: LPU 展现出极高的包容度,已深度适配 Qwen(千问)、MiniCPM(面壁)、Gemma(谷歌)、DeepSeek 及 GLM 等主流开源模型。系统灵活支持从 2B 到 120B-MOE 不同量级的稠密与稀疏模型。
- “北向”应用框架: MetaClaw系统支持通过网页、飞书、QQ、钉钉等“分身”实现远程调度。例如,其搭载的 Hermes 自我学习 Skills 插件赋予了智能体根据环境反馈持续进化的能力,这是具身智能走向自主化的核心要素。
- 中间件与协同: LPU 作为协处理器,与 SoC 主控芯片及自研的“龙虾操作系统”紧密耦合。这种“类矿机”式的模块化思维,允许算力根据需求弹性部署,可为合作伙伴缩短70%以上的开发周期。
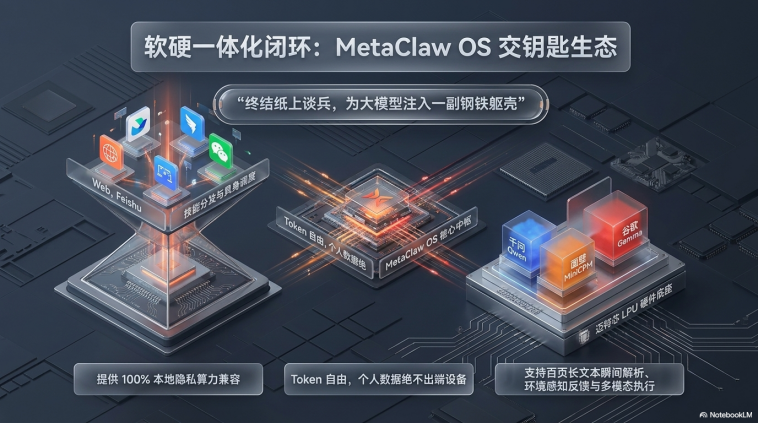
MetaClaw 龙虾应用方案已在教育、健康管家及人形机器人等领域落地,其将虚拟指令转化为物理干预的能力,已在多个垂直场景得到实证:
- MetaBook(本地知识库): 不同于传统的云端 RAG,MetaBook 支持“本地知识库增量更新”。它能瞬时理解百页级别的 PDF/Word/PPT 合同及专业书籍。由于算力位于端侧,知识检索与总结的响应速度提升了一个数量级,且绝对私密。
- 多智能体协同(Multi-Agent): MetaClaw 可演进为 24/7 工作的虚拟管家团队。
- 单虾模式:负责 NAS 管理、IoT 控制及教育批改。
- 多虾协同:多个 Agent 共享记忆与目标,实现从“观察-决策-执行”的完全闭环。
- 具身智能实测:已通过远程指令操控四足机器人(机械狗)进行全天候巡检,结合 OCR 作业批改与情感识别能力,MetaClaw 正在完成从“搜索引擎”向“具身助手”的角色蜕变。
六、未来展望:迈向三维智能算力时代
综合以上 AI 推理芯片技术和应用方案对比分析,我们可以得出以下关键结论:
1. 3D化是行业必经之路: 随着 2D 制程微缩触及物理极限,垂直空间的开发(3D-DRAM、3D-CIM)是突破“存储墙”的唯一正解。
2. 国产方案的机遇期: 迈特芯基于国产 28nm 成熟工艺的3D集成方案,不仅保证了供应链安全,更在能效比上实现了国际领先,为中国 AI 算力底座提供了确定性的路径。
3. 算力成本趋于零: 通过软件定义硬件(如 Groq 的确定性调度)与底层物理融合(如微纳核芯的存算一体),未来五年 AI 推理的单 Token 成本将下降两个数量级。
这场架构革命不仅是半导体物理层面的突围,更是构建真智能时代的决定性脊梁。未来的智能算力将如电力般,在三维芯片的微米间隙中高效涌动。(本文技术分析由 云栈社区 编译,更多前沿讨论请访问社区。)
 发表于 2026-4-29 03:40:36
|
查看: 388|
回复: 0
发表于 2026-4-29 03:40:36
|
查看: 388|
回复: 0
