斯坦福、伯克利与英伟达联合提出了一种全新的 Agent 验证框架——LLM-as-a-Verifier。该方法是一种通用的验证机制,可与任意 Agent Harness 和模型结合,通过扩展验证阶段的计算量(scaling verification compute),显著提升 Agent 整体性能,并在最具影响力的 AI 编程基准 Terminal-Bench 上超越 GPT-5.5 和 Claude Mythos,取得当前最优(SOTA)结果。
项目由斯坦福大学 CS 博士生 Jacky Kwok 负责,主要贡献者包括伯克利 EECS 博士生 Shulu Li,通讯作者为 Ion Stoica(UC 伯克利教授、Databricks 创始人)、Azalia Mirhoseini(斯坦福教授,曾任职于 DeepMind 与 Anthropic)以及 Marco Pavone(英伟达 AI 与自动驾驶研究总监)。
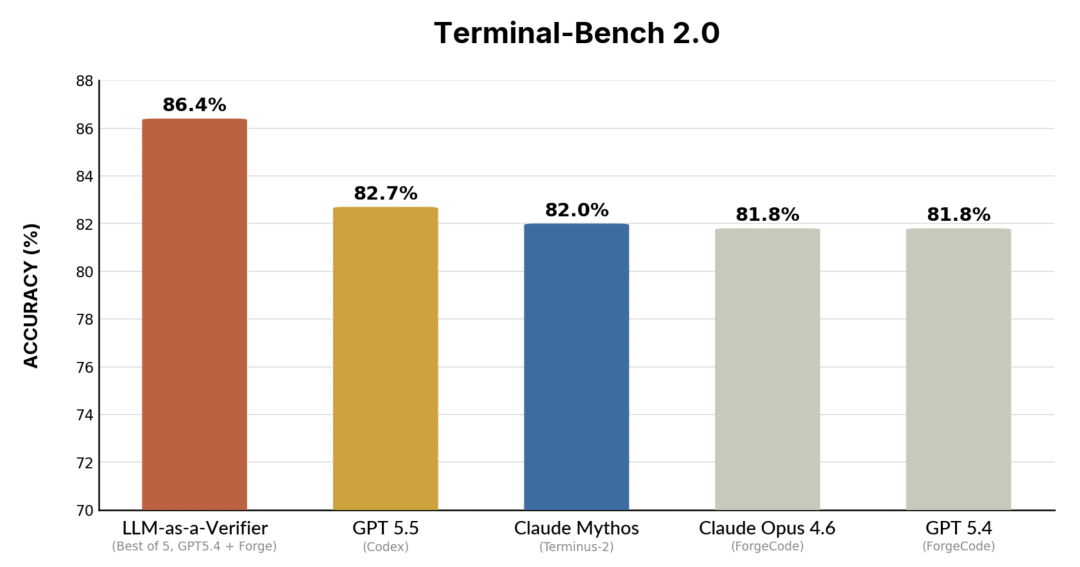
LLM-as-a-Verifier 在 AI Coding 基准 Terminal-Bench 和 SWE-Bench Verified 上均取得了 SOTA 性能。Transformer 论文作者 Lukasz Kaiser 以及 GAN 作者 Bing Xu 也对该工作进行了转发与关注。

- 博客地址:llm-as-a-verifier.notion.site
- 代码地址:llm-as-a-verifier.github.io
方法概述
大多数 Agent Harness 实际上已经“具备”解决问题的能力。当我们多次运行同一个 Agent(例如运行 100 次),它往往能在某一次尝试中生成正确答案。但问题在于,它们无法判断哪一个才是正确的。这一难点在长时序任务(long-horizon tasks)中尤为突出。
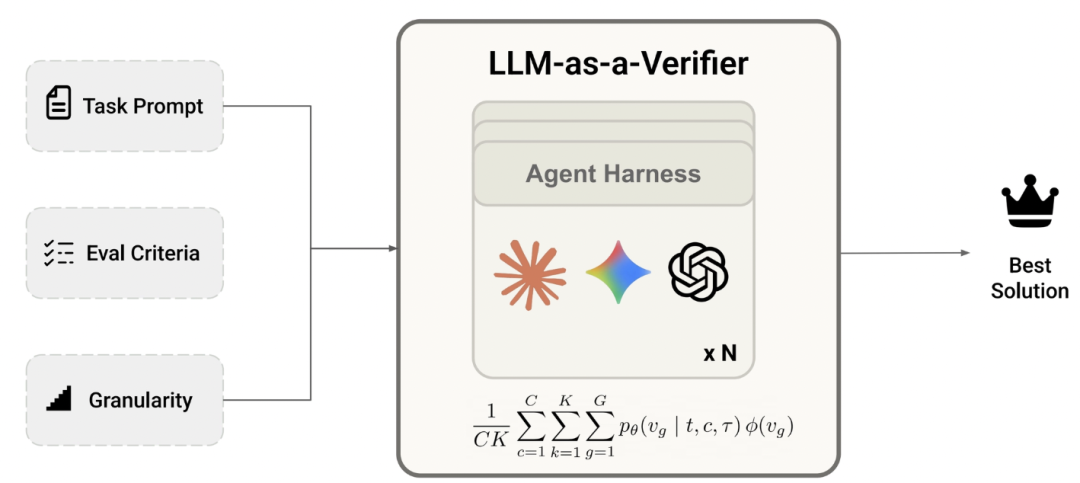
LLM-as-a-Verifier 通过 扩展评分 token 的细粒度(score granularity)、多次评估(repeated verification)以及 评价标准分解(criteria decomposition),显著提升了验证能力,并进一步提高了下游任务的成功率。此外,团队发现随着评分 token 细粒度的提升,正负样本之间的得分区分度会进一步拉大。
核心问题:LLM-as-a-Judge 的局限性
标准的 LLM-as-a-Judge 通过提示模型输出一个评分结果(例如,1 到 8 之间的分数),并选择概率最高的评分作为最终的离散分数。然而,这种方法往往存在评分粒度过于粗糙的问题。在比较长时序 agent 轨迹(trajectories)时,LLM-as-a-Judge 通常会为不同的轨迹分配相同的分数(例如两条轨迹都被评为 4 分),导致平局,无法有效区分它们。这种粗粒度的评分机制在 Terminal-Bench 上出现了 27% 的平局情况,限制了评判的精确性和区分能力。
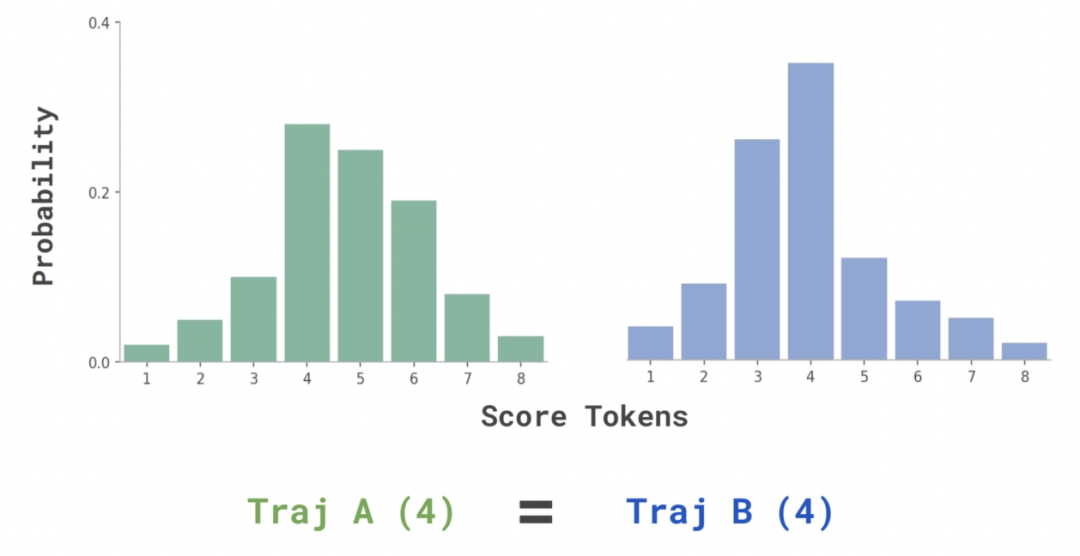
LLM-as-a-Verifier:从判分到验证的范式转变
从定义上讲,judge(裁判者)是对整体情况形成总体判断并给出结论的人;而 verifier(验证者)则是对具体事项进行真实及正确性核验的人,因此需要更细致、更具体的评估。为此,团队提出了 LLM-as-a-Verifier,它通过扩展以下三个维度来提供细粒度反馈:
- 重复验证的次数(repeated verifications)
- 评分 token 的粒度(granularity of score tokens)
- 评估标准的分解(decomposition of evaluation criteria)
给定任务 $t$ 以及两条候选轨迹 $T_i$ 和 $\tau_j$,LLM-as-a-Verifier 构造评分 prompt,并通过从 <score_A> 和 <score_B> 中提取 top-logprobs,得到对应的条件分布:

LLM-as-a-Verifier 将轨迹的奖励表示为:
$$R(t, \tau) = \frac{1}{C K} \sum_{c=1}^{C} \sum_{k=1}^{K} \sum_{g=1}^{G} p_\theta(v_g | t, c, \tau) \cdot \phi(v_g)$$
其中:
- $C$ = 评估标准的数量
- $K$ = 重复验证的次数
- $G$ = 评分 token 的数量(粒度等级)
- $p_\theta(v_g | t, c, \tau)$ = 模型对评分 token 的概率
- $\phi(v_g)$ = 每个评分 token 映射为标量数值的函数
- $V_{\text{score}} = \{v_1, \ldots, v_G\}$ = 离散评分 token 集合
在选择最佳轨迹时,团队采用 循环赛(round-robin tournament):对每一对候选轨迹 $(i, j)$,验证器都会利用上述公式计算其 reward。奖励更高的轨迹获得胜利,而在全部比较中胜场数最多的轨迹,将被选为最终结果。
实验结果
1. 在复杂基准任务上达到 SOTA
在 Terminal-Bench 2.0 和 SWE-Bench Verified 等复杂的长时序基准任务中,LLM-as-a-Verifier 的表现全面超越了前沿模型,均取得了当前最优(SOTA)性能。所有实验结果均来源于官方排行榜。
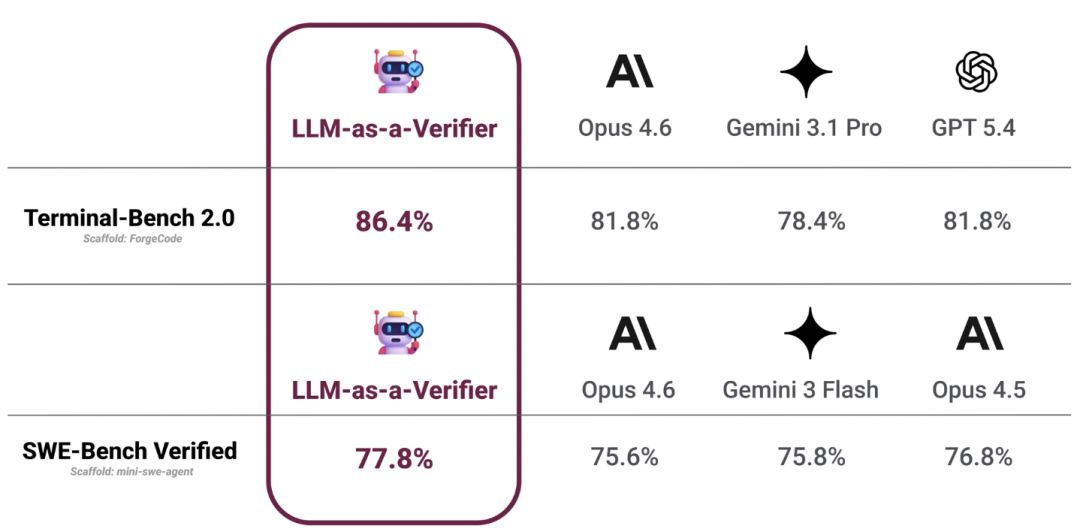
2. 与不同 Agent Harness 无缝集成
LLM-as-a-Verifier 能够在不同的 Agent Harness 框架中实现无缝集成,其通用性验证于以下三个基准任务:
- ForgeCode:验证准确率提升至 86.4%
- Terminus-Kira:准确率提升至 79.4%
- Terminus 2:准确率增加至 71.2%

这表明,无论针对何种 Agent Harness 或模型,该验证方法皆可高效兼容并提升性能。
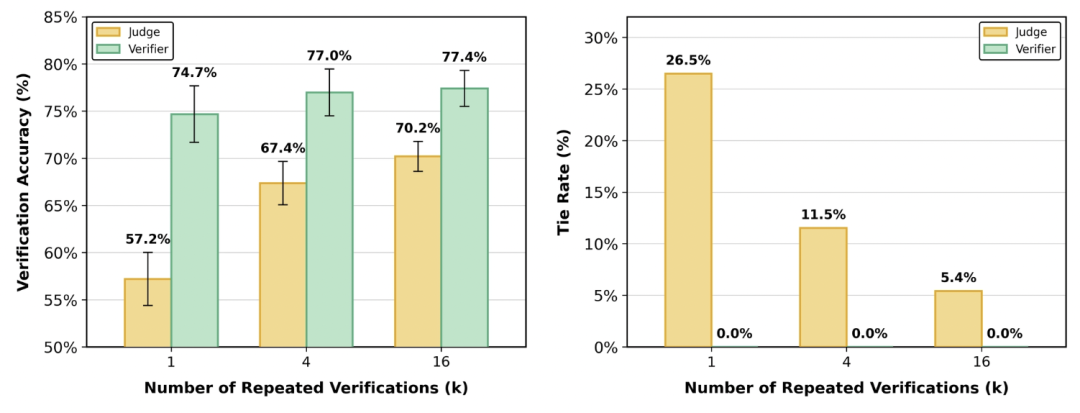
3. 消除平局,提升准确率
LLM-as-a-Verifier 在验证准确率和消除平局方面全面领先于传统的 LLM-as-a-Judge。即使在增加重复验证次数的情况下(如 $k=16$),Verifier 方法依然保持了至少 7% 的验证准确率优势。此外,它完全消除了平局现象。
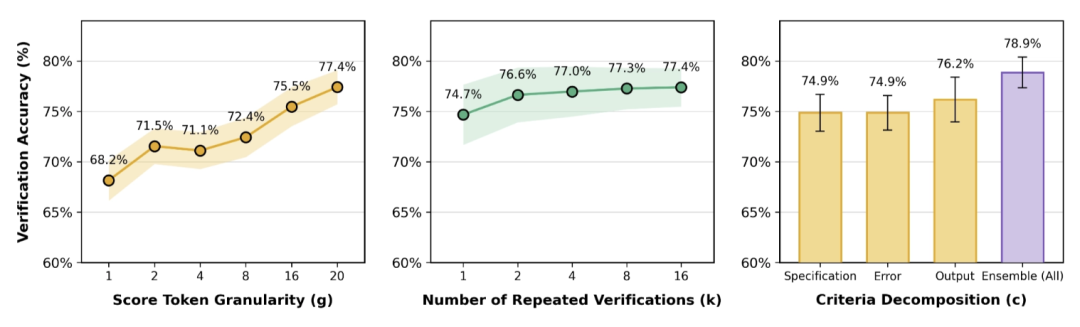
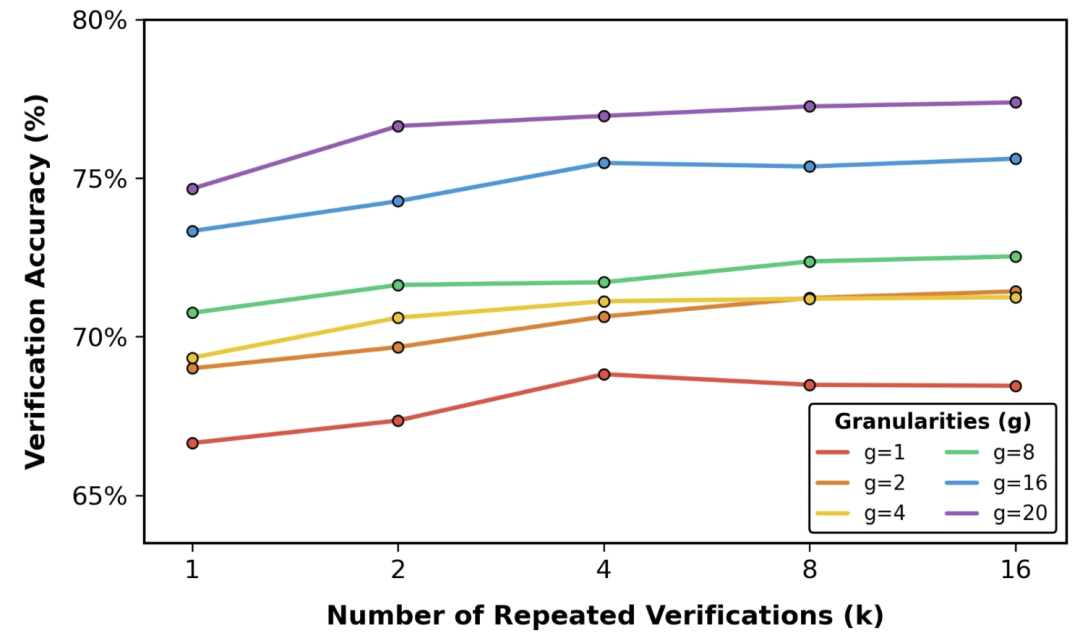
4. 粒度与重复验证的影响
实验结果表明,增加评分 token 的粒度(granularity)以及提高重复验证次数(repeated verifications)均能显著提高验证准确率。此外,在评分 token 维度的细化分级(1→20)中,量化误差得到了极大降低,从而更接近真实奖励。
5. 评价标准分解
LLM-as-a-Verifier 放弃传统的单一评分机制,采用将轨迹验证解构为三个可组合的评估标准:
- 规范合规性 (Specification):轨迹是否符合所有任务要求(路径、命名等)
- 输出格式 (Output Format):验证输出的格式是否符合预期结果
- 错误检测 (Error Checking):轨迹中是否存在明显的错误信号
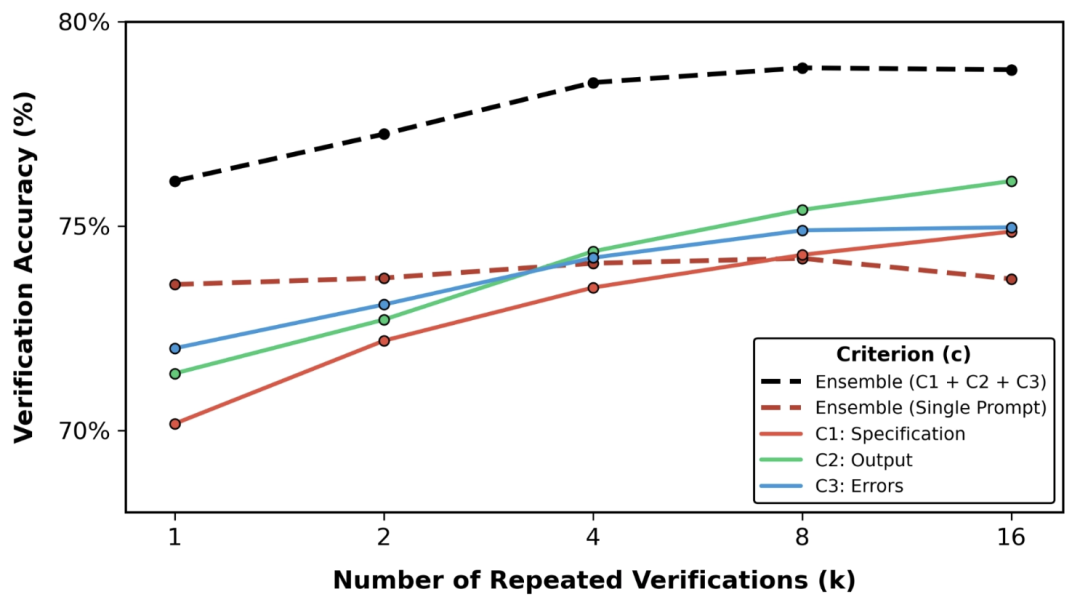
验证计算作为新的扩展维度
「LLM-as-a-Verifier」是一种通用验证机制,能够显著提升 Agent 的整体性能,并在多个 AI 编程基准上取得当前最优(SOTA)表现,超越了其他前沿模型如 Claude Mythos。相比传统的「LLM-as-a-Judge」方法,该框架利用更细致的评分粒度、重复验证以及评估标准分解,实现更高的验证准确率和更精确的区分能力,消除了评分平局现象。
实验结果表明,它能够广泛适配不同的 Agent Harness 和模型,提高多种基准任务中的准确率,同时通过评分机制的细化缓解量化误差,使验证结果更接近真实奖励。LLM-as-a-Verifier 不仅提升了 Agent 性能,还显著增强了模型在长时序任务中的安全性和稳定性。
如果你对 Agent 验证框架和 人工智能 前沿技术感兴趣,欢迎在云栈社区参与讨论,共同探索更多可能性。
 发表于 2026-4-27 02:19:51
|
查看: 261|
回复: 0
发表于 2026-4-27 02:19:51
|
查看: 261|
回复: 0
