一、背景与需求
作为一名中长线投资者,我每天都会在雪球上关注大量投资相关的帖子。信息过载一直是个令人头疼的问题,再加上一些大V的观点时常反复,我迫切需要一种自动化方案来帮我分析这些KOL的水平,并基于他们的观点辅助交易决策。
系统主要分为两大流程:
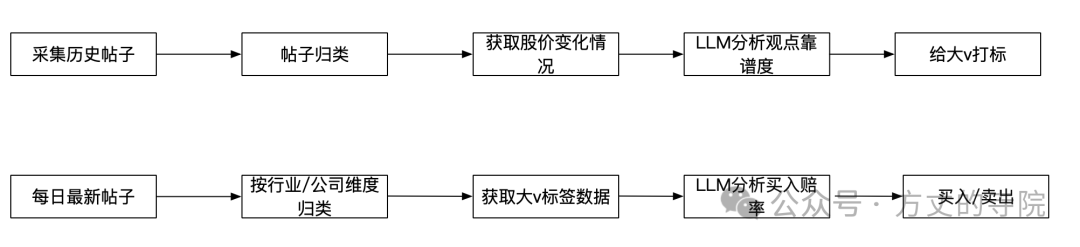
大V评分流程:采集历史帖子 -> 帖子归类 -> 获取对应股价变化情况 -> 使用 LLM 分析观点靠谱度 -> 为各大V打上能力标签。
交易决策流程:抓取每日最新帖子 -> 按行业或公司维度归类 -> 获取大V的标签数据 -> 使用 LLM 分析买入卖出赔率 -> 生成交易信号(买入/卖出)。
二、领域模型
在动手编码前,清晰地定义业务模型至关重要,它能帮助我们更好地进行技术模块划分和代码设计。
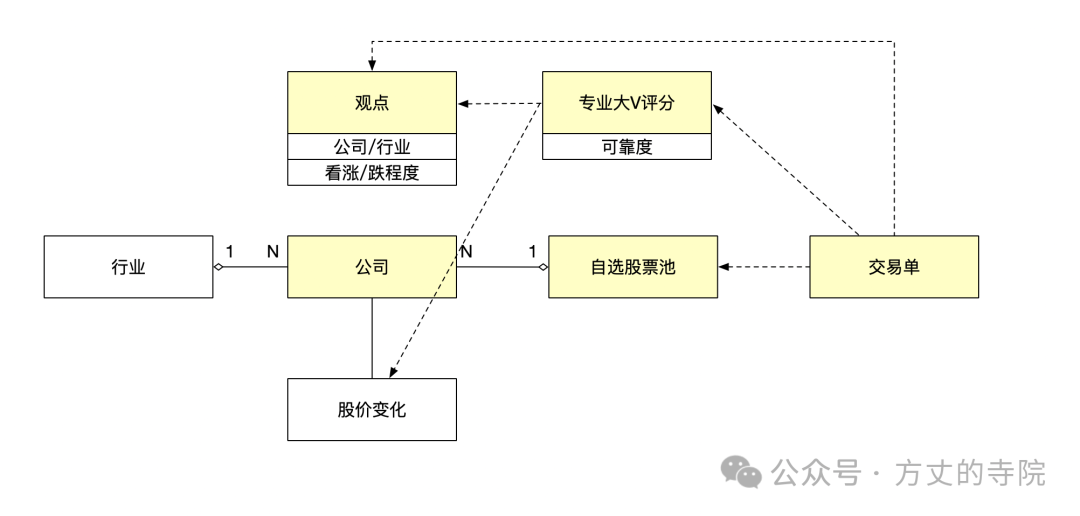
- 自选股票池:我个人长期看好或关注的公司列表。系统生成的交易信号仅针对池内的公司。
- 公司:上市公司主体。
- 行业:公司所属的行业类别,参考上交所/深交所的标准分类。
- 观点:大V发布的原创帖子或评论,其中包含对特定公司或行业的看涨/看跌判断及程度。
- 专业大V评分:基于大V的历史观点,以及该观点发出后一段时间内(例如1-3个月)对应公司实际的股价变化情况,综合计算得出的可信度评分。
- 交易单:一次具体的股票买入或卖出操作记录。
三、技术选型
3.1 开发工具:Cursor
选择 Cursor 主要是利用其强大的 AI 编程辅助能力,可以快速生成和调试代码片段,极大提升开发效率。
3.2 浏览器自动化:browser-use
传统的爬虫方案在应对复杂的反爬机制时往往力不从心。我选择了 browser-use 这个库,原因如下:
- 智能交互:它基于
LLM 来理解网页结构和用户指令,能执行点击、滚动、表单填写等复杂操作,模仿真人行为。
- 异步支持:原生支持
async/await,非常适合处理需要等待页面加载、网络请求的场景。
- CDP集成:直接通过 Chrome DevTools Protocol 与浏览器交互,可以执行任意 JavaScript,有效绕过一些前端检测逻辑。
3.3 大语言模型:OpenAI API
核心的分析与提炼工作交给了大模型。选用 GPT-3.5-turbo 是出于性价比考虑:
- 上下文理解:能够较好理解投资领域的专业术语和论述逻辑。
- 结构化输出:可以严格按照指定的 JSON 格式输出提炼后的观点,方便程序后续处理。
- 成本可控:相比 GPT-4,在处理大量帖子内容时成本更低。
3.4 数据处理:Python 异步编程
整个系统涉及大量的网络 I/O 操作(网页访问、API调用),采用 Python 的 asyncio 框架来实现高并发,避免阻塞,最大化利用资源。
四、系统架构设计
4.1 整体流程
整个 Agent 的工作流可以概括为以下几个步骤:
用户输入(雪球账号密码)
↓
浏览器自动化登录
↓
获取“我的关注”列表帖子(通过浏览器上下文调用API)
↓
基于自选股进行关键词匹配筛选
↓
对筛选后的帖子进行情绪分析(基于关键词库)
↓
LLM 内容提炼(调用 OpenAI API)
↓
结构化输出(JSON 数据 + 可读文本报告)
4.2 核心模块划分
- 登录模块:处理雪球登录全流程,包括账号密码填充、验证码识别(或人工干预)等。
- 数据获取模块:在已登录的浏览器会话中,通过拦截或主动调用雪球内部 API 获取关注用户的原创帖子。
- 内容筛选模块:使用预设的关键词映射表,筛选出与自选股票池相关的帖子。
- 情绪分析模块:通过统计看涨/看跌关键词的频次,对帖子进行初步的情绪倾向(乐观、悲观、中性)和置信度判断。
- 内容提炼模块:将筛选后的帖子原文发送给
LLM,让其提炼核心观点、逻辑和隐含信息。
- 输出格式化模块:将上述所有信息整合,生成便于阅读的文本报告和结构化的 JSON 数据,供后续分析或决策系统使用。
五、核心技术实现
5.1 浏览器自动化登录
技术要点:
- 使用
browser-use 的 BrowserSession 来创建和管理浏览器实例。
- 通过注入 JavaScript 代码来填写表单,比单纯的模拟输入更接近真人操作,降低被检测风险。
- 实现多选择器(如
CSS Selector, XPath)的回退策略,增强元素定位的鲁棒性。
- 设计逻辑处理动态加载内容和可能的验证码场景。
关键设计:
- 采用异步上下文管理器模式(
async with),确保在任何情况下浏览器实例都能被正确关闭和释放资源。
- 加入登录状态验证机制,例如检查页面是否跳转到用户主页或特定元素是否出现,确保登录成功后才执行后续步骤。
5.2 API 数据获取
技术要点:
- 直接通过 CDP 的
Runtime.evaluate 方法,在浏览器页面上下文中执行 fetch 或 XMLHttpRequest 来调用雪球的数据接口。
- 充分利用浏览器已维持的登录态(cookies 和 session),无需手动管理。
- 实现分页逻辑,以获取足够数量的历史帖子。
关键设计:
- 调用
Runtime.evaluate 时设置 awaitPromise: true,以执行异步 JavaScript 并获取其结果。
- 精细解析 API 返回的复杂 JSON 数据结构,提取出帖子 ID、内容、作者、发布时间、关联股票等关键字段。
- 添加过滤逻辑,剔除简单的转发帖和评论,只保留用户的原创内容进行分析。
5.3 智能内容筛选
技术要点:
- 为自选股池中的每个公司构建关键词映射表,包括公司全称、常用简称、股票代码、乃至网络上的别称。
- 实施双重匹配策略:一是检查 API 返回数据中自带的股票代码信息;二是对帖子全文进行文本扫描,匹配公司名称关键词。
- 支持一个帖子同时提及多个关注公司的情况。
关键设计:
- 关键词库设计为可扩展结构,便于随时新增公司或别名。
- 为每个匹配结果打上来源标记(“来自API”或“来自文本匹配”),便于后续评估匹配策略的准确性。
5.4 情绪分析
技术要点:
- 预先定义“看涨关键词库”(如:上涨、看好、买入、目标价)和“看跌关键词库”(如:下跌、看空、卖出、风险)。
- 基于关键词在帖子中出现的频率和种类,判断其情绪倾向。
- 根据匹配到的关键词数量,给出情绪判断的置信度等级(高、中、低)。
关键设计:
- 虽然当前采用简单计数法,但为后续引入基于
LLM 的细粒度情感分析或关键词权重机制预留了接口。
- 情绪分析以“公司”为粒度进行,即使一个帖子提到多个公司,也会为每个公司单独计算情绪得分。
5.5 LLM 内容提炼
技术要点:
- 精心设计 Prompt,明确要求
LLM 扮演“专业的股票内容分析助手”,并给出具体的提炼要点(如:核心观点、依据逻辑、风险提示等)。
- 对帖子原文进行预处理:去除 HTML 标签、截断过长的文本以适配模型上下文长度限制。
- 设计降级策略:当
LLM API 调用失败或超时时,自动回退到基于规则或简单摘要的本地方法。
关键设计:
- 系统提示词:定义模型角色和基础能力框架。
- 用户提示词模板:将公司名称、提炼要求、清理后的原始内容动态填充到模板中。
- 将 API 调用的
temperature 参数设置为较低的 0.3,以获取更加稳定、可重复的输出结果。
5.6 结构化输出
技术要点:
- 生成一份面向人类阅读的文本报告,汇总当日所有相关帖子的分析结论。
- 同时,将所有原始数据、中间分析结果和最终提炼内容以 JSON 格式持久化存储,为后续的模型训练或策略回测提供数据基础。
- 报告按关注的公司进行分类聚合,方便快速浏览特定公司的市场舆情。
关键设计:
- 文本报告包含多个维度:例如,汇总“买入”信号强烈的帖子、摘录提及具体目标价的信息、列出值得深入阅读的重要观点摘要等。
六、技术难点与解决方案
6.1 应对反爬虫机制
问题:雪球等平台对直接的程序化请求(如 Python 的 requests 库)有严格的检测和拦截机制。
解决方案:
- 使用真实浏览器环境:通过
browser-use 驱动 Playwright 控制的真实浏览器,所有行为与真人用户无异。
- 在浏览器上下文中发起请求:数据获取不通过外部网络库,而是通过 CDP 让浏览器本身去执行
fetch,天然携带所有正确的 cookies 和请求头。
- 模拟用户行为:在操作间添加合理的随机等待时间,并穿插一些浏览、滚动等非必要但真实的行为。
6.2 执行浏览器内的异步 API 调用
问题:需要在被控浏览器页面中执行异步 JavaScript 代码(如 fetch),并等待其结果返回到 Python 主程序。
解决方案:
- 利用 CDP 的
Runtime.evaluate 命令,并将 awaitPromise 参数设为 true。
- 将完整的异步调用代码(如一个立即执行的异步函数表达式)作为字符串传递给该方法。
- 该方法会返回一个
RemoteObject,其中包含了 Promise 解决后的值,再将其反序列化为 Python 字典或列表。
6.3 提升内容匹配的准确性
问题:如何精准识别帖子中提及的公司,避免因公司简称重合、指代不明等原因产生误匹配。
解决方案:
- 构建丰富的关键词库:不仅包含官方名称和股票代码,还收集了投资者社区中常用的别称、缩写。
- 双重验证机制:优先采用 API 返回的精准股票代码信息进行匹配,作为“强信号”;辅以全文关键词扫描作为“弱信号”补充和交叉验证。
- 规则约束:对于文本匹配,在支持一定模糊匹配的同时,对股票代码的匹配要求必须精确。
七、实践心得与反思
在这个项目中,LLM 主要在两处发挥了关键作用:
- AI 辅助编程:从自动登录、抓取帖子信息,到从不同财经网站查询公司所属行业,这些功能如果完全手写代码,可能需要一整天。而在 AI 的辅助下,核心逻辑的调试和打通在一两个小时内就能完成。
- 分析帖子质量:这是核心价值所在,让机器能够初步理解和提炼非结构化的文本观点,这是传统规则方法难以做到的。
开发经验教训:
- 从“面条代码”到模块化设计:作为一名习惯用代码控制流程的开发者,我最初直接让 AI 按步骤生成代码,结果得到了耦合紧密、难以复用的“面条式”代码。这不仅效率低,而且无法并行开发。后来我花费时间进行了模块化设计,将自动化登录、数据抓取、内容分析、行业归类、决策生成等拆分为独立模块。这样就能在多个编辑器窗口中同时推进不同模块的开发,速度大幅提升。
- 工具的选择:对于习惯编程的开发者来说,使用
Python 或 Java 这类语言配合框架进行开发,在流程控制和灵活性上可能比完全依赖 Dify/Coze 这类低代码 Agent 平台更得心应手。
待解决的问题:
- 验证码的完全自动化:登录后的验证码识别环节,尽管尝试了多种自动修复方案,但成功率仍不理想,目前部分依赖人工干预。这是一个需要持续改进的点。
- 决策闭环与复盘:目前系统只做到了“分析-决策”的前半段。后续需要建立完整的复盘流程,追踪依据观点生成的交易信号的实际盈亏情况,并用这些数据反过来优化和调整前置的分析与决策模型,形成闭环。
本项目的相关代码已开源在 GitHub:https://github.com/FS1360472174/stock ,欢迎感兴趣的开发者一同交流探讨。如果你也在探索如何将传统开发技能与新兴的 Agent 和 LLM 技术结合,解决实际问题,欢迎来 云栈社区 分享你的经验和见解。 |  发表于 2026-2-28 01:58:45
|
查看: 199|
回复: 0
发表于 2026-2-28 01:58:45
|
查看: 199|
回复: 0
