今天我们来聊聊如何使用开源的 RTCPilot 项目,构建一个完全自主可控的 Voice Agent 智能体。
什么是 Voice Agent?简单来说,它是一个跑在 WebRTC 低延迟实时音视频通道上的 AI 对话模型。用户可以直接在浏览器或 APP 里,像打电话一样与 AI 进行自然、流畅的语音交流。它的核心特点可以概括为“能听、能想、能说”,并支持全双工、可打断的实时交互。这意味着在 AI 回答的过程中,你可以随时插话提出新问题,体验更接近真人对话。
其完整的技术流程是:首先进行语音采集,随后通过 WebRTC 传输到云端;在云端,音频流被实时转写成文字(ASR),接着送入大语言模型(LLM)进行流式推理;生成的文本再通过流式语音合成(TTS)转换为语音,最后经由 WebRTC 回传并在客户端播放。这整套技术栈,在国内各大云厂商(如声网、火山引擎、科大讯飞)的宣传中,常被称作“实时语音交互基础设施 + 大模型语音化引擎”,旨在将任意文本大模型快速转变为可实时对话的 Voice Agent。
不过,依赖云平台有时意味着更高的成本和更少的控制权。因此,我们将目光转向开源方案,尝试使用 RTCPilot 来实现一个功能完整的 Voice Agent。这个方案完全开源,可以部署在你自己的服务器上,无需依赖任何外部云服务。
RTCPilot 与 Voice Agent 的融合
RTCPilot 本身是一个基于 C++17 开发的、跨平台的 WebRTC 音视频会议 SFU 服务,支持集群部署,其核心是处理高并发的网络流媒体转发。然而,为了让其支持 Voice Agent,我们需要引入一系列新的模块:音频编解码、自动语音识别(ASR)服务、文本转语音(TTS)服务。这一增加,使得系统的性质发生了根本变化——从一个网络密集型(I/O密集型)的 SFU,转变为一个计算密集型(CPU密集型)的 MCU 服务。
下图清晰地展示了 RTCPilot 在集成 Voice Agent 功能前后的架构演变:
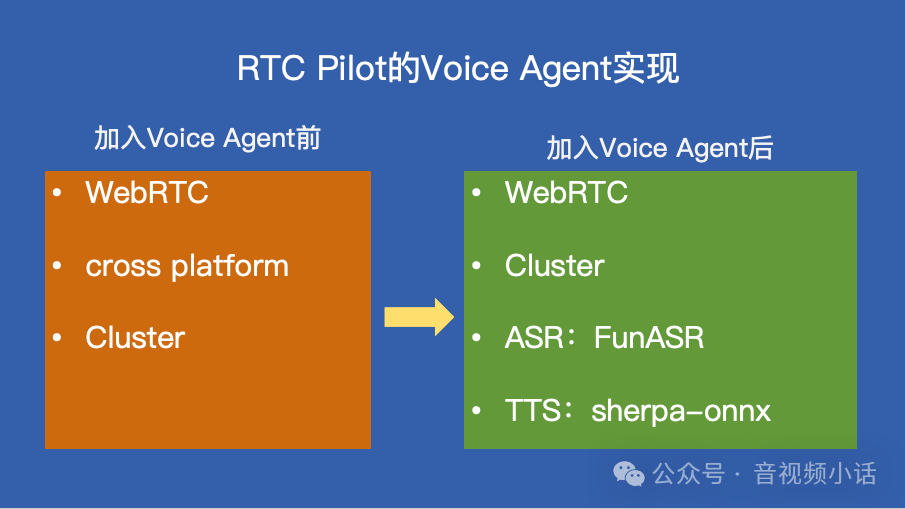
从架构上讲,将 ASR、TTS 和编解码这些重型计算任务与 SFU 网络转发服务解耦,放在独立的 MCU 节点中是更合理的做法。当前在 RTCPilot 中的一体化实现,更多是出于简化部署、方便广大开发者快速上手的考量,算是一种务实的折衷方案。
项目现状与获取方式
目前,支持 Voice Agent 功能的代码独立存放在 RTCPilot 项目的 voiceagent 分支中。我仍在评估是否以及如何将其合并到主线代码库,因为这涉及到架构上的重大调整。此外,由于集成了特定的编解码库,当前 voiceagent 分支暂未支持 Windows 11 平台,后续需要进行适配和改进。
如果你对这个项目感兴趣,或者有更好的架构建议,欢迎参与讨论。项目的地址如下:
服务端 (RTCPilot):
https://github.com/runner365/RTCPilot
branch: voiceagent
客户端 (WebRTC示例):
https://github.com/runner365/webrtc_js_client
通过这个开源项目,你不仅能深入理解 WebRTC 在实时通信中的核心作用,还能实践如何将语音识别、大模型推理与语音合成等技术整合,构建属于你自己的交互式人工智能应用。如果你在实现过程中有任何心得或困惑,也欢迎在云栈社区与其他开发者交流探讨。 |  发表于 2026-2-28 01:54:56
|
查看: 253|
回复: 0
发表于 2026-2-28 01:54:56
|
查看: 253|
回复: 0
