给大语言模型“喂”一份文档或一段指令,它就能在毫秒级别将内容转化为永久记忆或专属技能。这听起来像科幻小说,但如今已由 Sakana AI 团队变为现实。
他们提出的核心技术,是利用“超网络”(Hypernetwork)动态生成即插即用的低秩自适应(LoRA)模块。这项技术能将冗长的文档瞬间“内化”为模型的内在记忆,或将简单的任务描述转化为特定的专业技能。其核心思想在于,将昂贵的模型训练成本提前消化,从而实现低延迟、按需的即时更新。
传统知识更新与技能微调正面临效率瓶颈
尽管智能代理在复杂任务中表现出色,但长效记忆与持续适配能力,依然是当前限制大型语言模型(LLMs)发展的主要认知瓶颈。缺乏长效记忆,意味着用户每次开启新会话都必须重新提供背景资料,导致交互摩擦和信息断层,并显著增加响应时间。而缺乏持续适配能力,则让模型无法从过往错误或用户偏好中学习,使每次交互都像初次接触一样繁琐。
业界传统上通过直接更新模型来解决这两个问题。
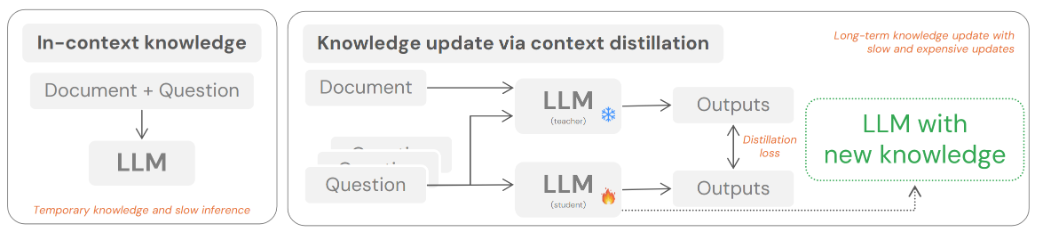
当用户提供长篇文档(如政策文件或私人报告)时,标准做法是将其塞入模型的上下文窗口。这意味着每次提出新问题,模型都需要重新“阅读”一遍同一份文档,导致极高的延迟和显存开销。像键值缓存预填充这类工程优化手段,虽然能缓解部分计算压力,却无法根除每次查询带来的额外成本。一旦文档长度超出模型的原生上下文窗口,这些方法便立刻失效。
另一种方案是“上下文蒸馏”,它将新信息直接编码进模型参数中,使模型无需重读源文件即可调用知识。但这个过程极其缓慢,且计算成本高昂。
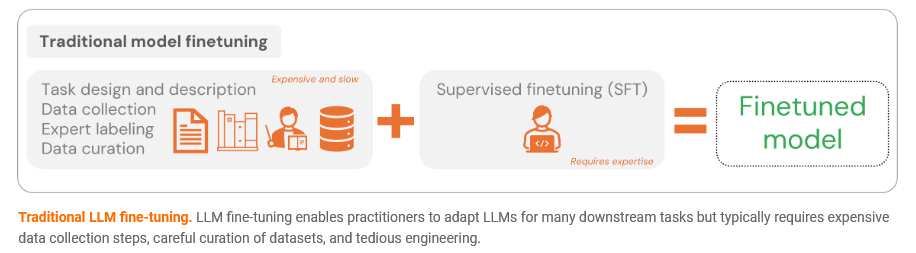
另一方面,开发者常希望模型能掌握新技能或遵循特定格式。传统的解决方案是模型微调,但这需要耗费大量精力进行数据收集、标注和整理,随后还要运行昂贵的训练流水线。这种重复性的数据收集与训练任务,严重拖慢了实验和新功能开发的速度。
超网络:通过提前分摊成本实现“瞬间更新”
无论是微调还是上下文蒸馏,其共同瓶颈都在于“信息传输路径”既慢又贵。研究者提出了一种基于“成本分摊”概念的全新策略。这种方法避开了在部署阶段低效重训模型的传统套路,而是选择在前期一次性训练一个专用的更新生成器,该生成器能在部署阶段被极低成本地高频调用。
其核心是训练一个被称为“超网络”的辅助调制网络。

超网络的独特之处在于,它的输出是另一个神经网络的参数。它能瞬间、廉价地生成极其小巧的LoRA适配器模块。训练完成后,超网络就像一个全自动的“兵工厂”,可以随时为目标语言模型按需定制特定任务的更新补丁。
整个工作流分为两个独立阶段:
- 元训练阶段:投入较高计算成本集中训练超网络,使其学会根据不同类型的输入生成高效的自适应更新。这是一次性的前期算力投资。
- 部署阶段:系统可以极廉价地运行更新。用户只需将文档或任务描述输入训练好的超网络,系统便能通过一次前向传播(通常不到一秒)返回定制好的LoRA模块,彻底摒弃了繁琐昂贵的逐个任务优化流水线。

上表详细对比了两种互补的即时更新接口:Doc-to-LoRA解决昂贵的知识更新蒸馏问题;Text-to-LoRA攻克繁琐的模型适配微调流程。
文档内化与跨模态视觉记忆迁移
将整篇文档提炼成LoRA适配器并融入基础模型权重,能创造出一种持久记忆。传统的上下文蒸馏方法需要针对单篇文档进行长时间、高内存的优化,完全不适用于低延迟对话场景。
超网络技术通过低成本的元学习完成了这一蒸馏步骤。它利用单次前向传播直接将长文档映射为自适应参数模块,无需针对特定文档进行梯度计算。生成的模块相当于一个外挂的“事实存储库”。一旦文档被内化,用户提出无数相关问题时,原始文档都无需再占用宝贵的上下文窗口,系统延迟和显存消耗得以大幅降低。
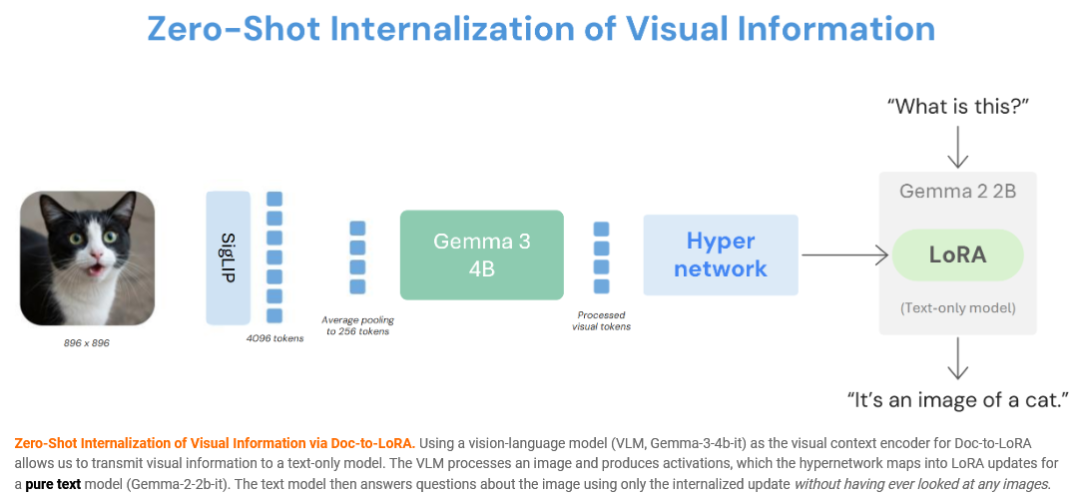
为语言模型廉价注入新知识是研究的核心动力。有趣的是,这种即时内化机制并不局限于纯文本。研究团队进行了一项大胆的“零样本内化”边界测试:探讨纯文本模型能否在不“看见”图像的情况下回答视觉相关问题。
系统利用视觉语言模型(VLM)作为“文档”编码器处理图像并生成特征激活,超网络再将这些激活精准映射为纯文本模型的专属LoRA更新模块。在整个过程中,超网络和基础文本模型都未曾接触过任何视觉标记数据。
实验结果展现了惊艳的跨模态信息传递能力。目标纯文本模型在ImageNet的一个十类子集(Imagenette)测试中达到了75.03%的准确率。
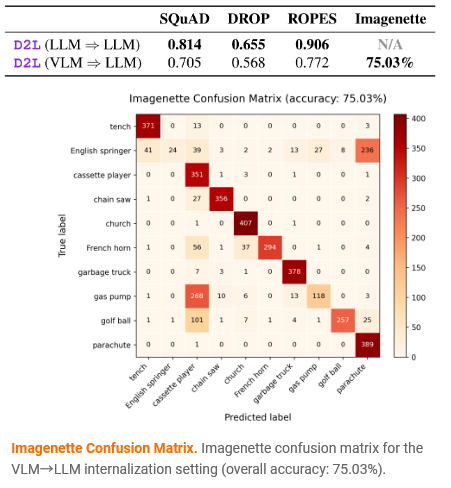
它完全依靠LoRA模块中隐式存储的视觉信息流畅作答。超网络仿佛成了一座跨越数据模态的“数字桥梁”,将一个模型提取的深层信息,精准“搬运”到另一个模型的参数深处。
语言模型如何在“睡眠”中完成技能进化
传统的模型适配微调如同一条需要重度人工干预的生产线,每次增添新技能都要重复收集数据、启动训练。最终得到的往往是绑定单一数据集的专用模块。
针对此难题,研究人员探索出一条捷径。超网络能够仅凭一段自然语言撰写的简短任务描述,就瞬间生成一个可用的适配模块。开发者只需像写说明书一样描述任务,就能让模型立刻掌握并固化新技能。
将超网络打造为全局更新生成器,是一个极具潜力的设计。这套系统用一次性的前期投入,换取了后期无限次的轻量级按需更新。以往繁重的工程流水线,被压缩成一次简单的单向函数运算。
这种即时更新接口为语言模型开启了全新的记忆架构设计空间。模型不再需要把所有记忆数据当作外部文件被动堆砌。它们可以在两次用户交互的间隙“打个盹”,系统利用这段闲置时间将新摄入的信息迅速蒸馏成专属适配模块。模型“醒来”后,便无缝带上了新的行为模式与个性化记忆。
用户可以随时开启长周期对话,而无需担心高延迟。过去的交流细节早在对话间隙被“消化”并刻入参数中。模型更新甚至可以在深夜无人时自动批量进行。这种机制能在免除全量微调成本的前提下,实现大规模的模型个性化定制与持续学习。
展望未来,更新生成器极有潜力演变为一种标准化的底层基础模型接口。开发者可利用海量算力和数据,训练出融合所有模态的超级基础超网络。它能无缝处理任务描述、图像文件等各种监督信息源,像全自动精密工厂一样,持续输出高度模块化的组合适配补丁。
这不禁让人联想到人类大脑:睡一觉醒来,昨天的经历与学习,已经内化为神经元的突触连接结构。
参考资料:
对这类前沿的模型高效更新技术感兴趣,想了解更多实践案例与深度讨论?欢迎来云栈社区的人工智能板块交流分享。
 发表于 2026-3-10 09:29:13
|
查看: 257|
回复: 0
发表于 2026-3-10 09:29:13
|
查看: 257|
回复: 0
