训练一个大模型,就像教一个学生读书。过去的做法是:把一堆教材一股脑塞给他,让他从头读到尾,读完就算学完了。
但一个好老师不会这么干。好老师会判断——这道题他已经会了,跳过;这道题对他太难,先放一放;这个知识点他最近薄弱,多练几遍。同样的教材,不同的读法,教出的学生完全不一样。
大模型训练也是这个道理。同样一份数据,怎么喂、按什么顺序喂、哪些样本重点喂、哪些一笔带过,直接决定了最终模型的能力上限。这件事有个专业名词,叫“以数据为中心的动态训练”——但它的本质,就是把“静态投喂”变成“智能调度”。
问题是,现有的动态训练方法往往散落在孤立的代码库中,接口不统一且难以复现,阻碍了研究的公平对比与实际应用。
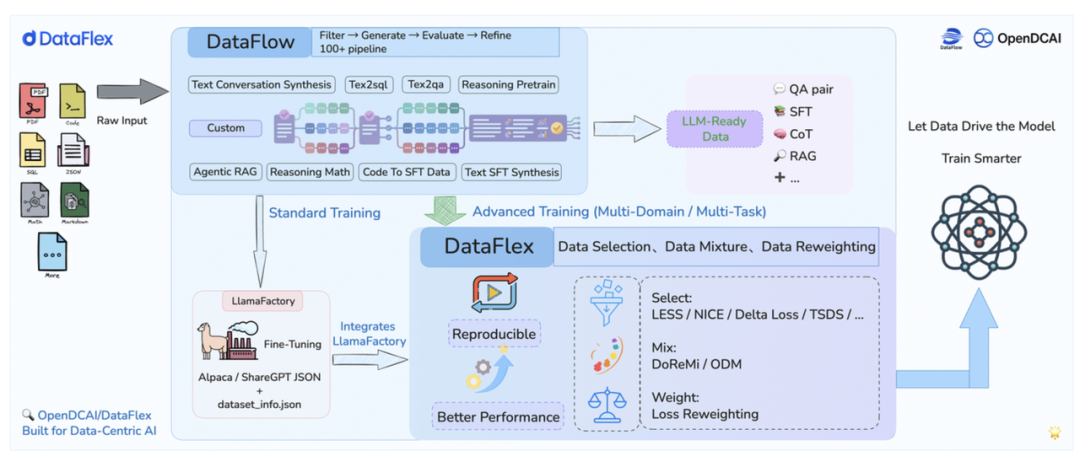
为了打破这一僵局,北京大学、上海算法创新研究院 (IAAR)、LLaMA-Factory 团队、中关村学院、上海人工智能实验室 (OpenDataLab) 以及上海交通大学等多家研究机构与技术团队联合推出了 DataFlex——一个构建在 LLaMA-Factory 之上,以数据为中心的动态训练框架。
DataFlex 通过统一的接口和抽象,实现了对训练过程中数据调度的智能化控制,为研究者和开发者提供了一个集成动态样本选择、动态数据混合、动态样本加权三类核心能力的“数据中心动态训练”系统。它不仅能自动识别并挑选高价值样本,还能动态调整不同数据源的混合比例,从而在提升模型最终性能(如 MMLU 准确率)的同时,显著增强训练效率。
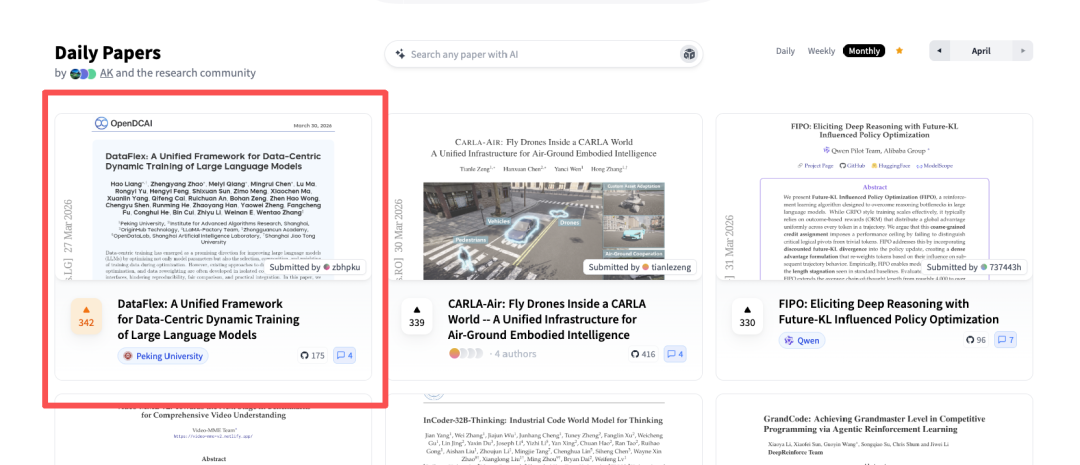
就在近期,DataFlex 凭借其创新的动态训练范式,已迅速冲上 HuggingFace 月榜第一名,成为全球开发者社区关注的焦点。
DataFlex 不仅仅是一个算法集合,更是一套完备的数据驱动型训练体系。
- 作为可复现的研究基准平台:该框架统一实现了动态数据混合、样本选择及加权等主流方法,并同时支持在线与离线研究场景。这从根本上解决了该领域因实现接口不一而导致的复现难题,为不同算法提供了公平、系统的比较环境。
- 作为面向实际应用的优化系统:它将数据筛选、领域配比调整与样本权重更新等环节无缝集成到模型的实时训练闭环中。这一设计使得数据从被动的“静态输入”进化为可主动调度、动态优化的核心变量,最终切实提升了训练过程的效率和模型的最终表现。
官方文档:https://opendcai.github.io/DataFlex-Doc/
GitHub仓库:https://github.com/OpenDCAI/DataFlex
技术报告:https://arxiv.org/abs/2603.26164
一、DataFlex:重塑大模型动态训练的生产力引擎
1. 核心理念:以数据为中心的动态训练

DataFlex的设计初衷,并非简单重复“数据重要”这一共识,而是直面行业真正的工程难题:如何将“模型该看什么数据、按怎样比例看、优先强化哪些样本”这类经验性判断,真正转化为一套可配置、可调度、可复现的标准化能力。它不只盯着参数的梯度更新,更在每一个训练步骤中精确追踪数据的实际贡献。
从“静态投喂”到“动态数据调度”
在传统的大模型训练流程中,数据通常被当作预先准备好的静态资源:数据集一经选定,采样方式便固定下来,整个训练过程主要围绕模型参数的优化展开。然而,当训练数据规模急剧膨胀、来源日趋多元时,决定模型最终效果的,已不再是“有没有更多数据”,而是“训练过程中能否更智能地运用数据”。
数据中心动态训练(Data-Centric Dynamic Training)的核心理念,正是将数据从“被动输入”的角色提升为“主动调度”的对象。系统不仅要决定模型接触哪些数据,还要动态调控不同数据源的混合比例、识别哪些样本值得优先学习、哪些样本应当降低权重。
2. 架构设计:三层解耦,开箱即用
DataFlex 采用轻量且高度可扩展的模块化设计,主要分为三层:
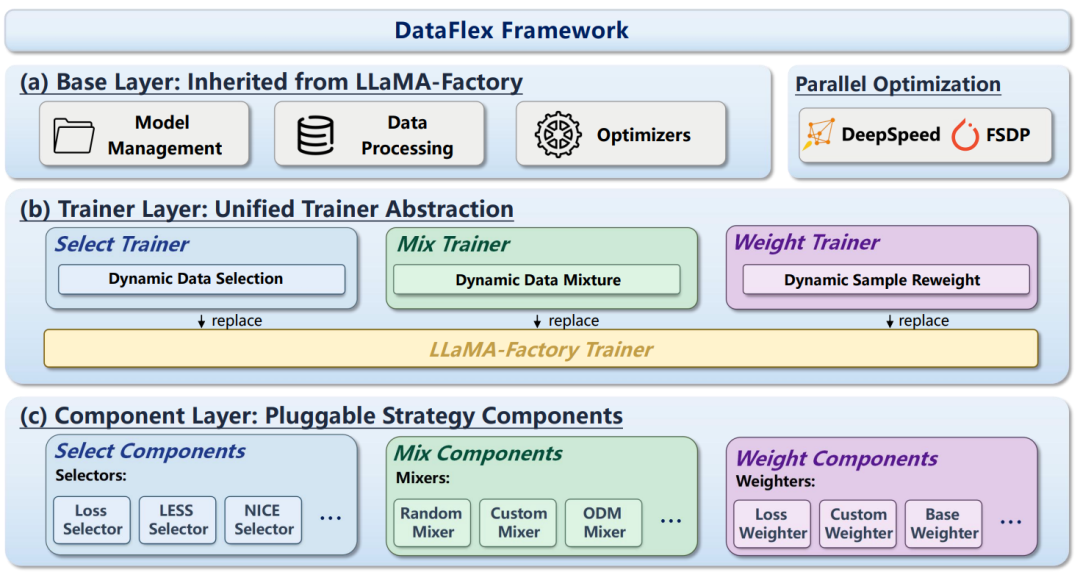
- 基础层:继承自 LLaMA-Factory,复用其成熟的模型管理、优化器和并行控制。
- 训练器层:DataFlex 的核心,引入了统一的动态训练抽象,接管训练循环。
- 组件层:提供可插拔的算法组件(Selectors/Mixers/Weighters),支持开发者以极低的成本注册新算法。
DataFlex 实现了一套标准化的“观察-决策-反馈”闭环,其核心是即插即用的模块化设计:
- 模型感知:系统统一封装了样本 Embedding 提取、Loss 计算与梯度获取等模型相关操作,新算法无需重复实现这些底层逻辑。
- 系统支持:原生兼容 DeepSpeed ZeRO-3 等分布式训练架构,能够在模型参数分片状态下完成全量梯度重建,为并行环境下的动态数据调度扫清工程障碍。
- 即插即用:所有算法(Selector/Mixer/Weighter)均以独立组件形式注册。开发者只需实现核心逻辑并通过 Registry 注册,即可无缝接入训练流程——无需修改任何框架底层代码。
- 零门槛配置:用户仅需在标准 LLaMA-Factory YAML 配置文件中添加简短的
dataflex 字段(指定 train_type、component_name 及调度参数),即可一键启用复杂的动态策略,实现从静态训练到数据中心动态训练的无缝切换。

3. 三大核心训练器:动态训练的主力军
科研上许多极具代表性的动态训练方法,要么缺乏官方仓库,要么其官方实现难以复现。DataFlex 统一了三大以数据为中心的主流优化范式,并通过系统化的重构,这些原本处于“失联”或“半停滞”状态的算法被重新激活,实现工业级的生产能力。
- 动态数据选择训练器(Select Trainer):根据策略(如基于梯度的 LESS、NICE 或基于损失的 Loss Selector)在训练过程中实时筛选最有价值的样本子集。
- 动态数据混合训练器(Mix Trainer):动态调整来自不同领域(如网页、代码、图书)的数据配比,支持 ODM(在线混合)和 DoReMi(离线/两阶段混合)等方法。
- 动态样本加权训练器(Weight Trainer):在反向传播中为不同样本动态分配权重,强化模型对特定“偏好”或困难样本的学习。

4. 操作指南:无缝衔接,极简配置
DataFlex 完全兼容 LlamaFactory 的配置和使用方式:
- 配置兼容:在 LlamaFactory 配置基础上添加 DataFlex 参数
- 命令一致:使用
dataflex-cli 替代 llamafactory-cli
- 功能保持:支持所有 LlamaFactory 的原有功能
- 无缝切换:可以通过
train_type: static 回退到原始训练模式
阅读官方文档可获取完整的参数说明与配置指南,同时建议观看项目团队精心准备的视频教程,直观掌握动态数据选择与混合的实操流程。如果想更深入地探索,GitHub 仓库 README 中详细介绍了从基础使用到进阶开发(如添加自定义算法)的全套技术细节。
二、实验效果:全面超越静态基线
在多项权威基准测试中,DataFlex 展示了其强大的性能提升能力:
- 性能提升:全面超越静态基线 在多项实验中,使用 DataFlex 优化的模型表现出更强的泛化能力:
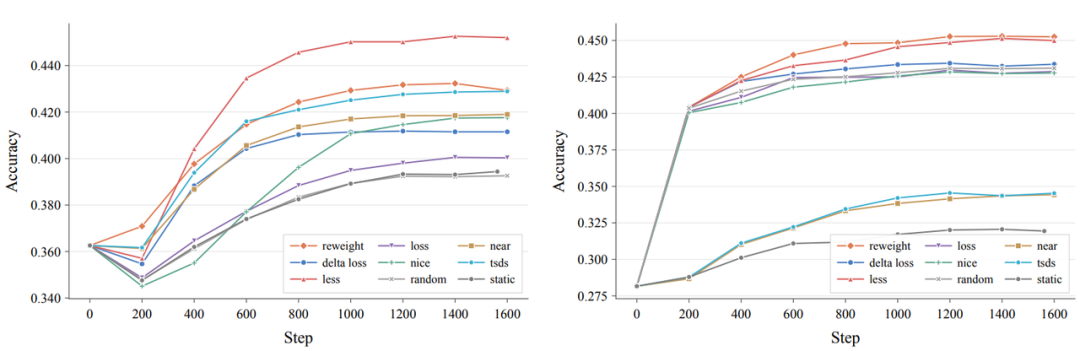
- 数据选择与样本加权:在 Mistral-7B 和 Llama-3.2-3B 上,动态选择方法(特别是 LESS)一致优于全量训练。例如,在 Mistral-7B 上,DataFlex 将 MMLU 准确率从 39.4% 提升至 45.2%。
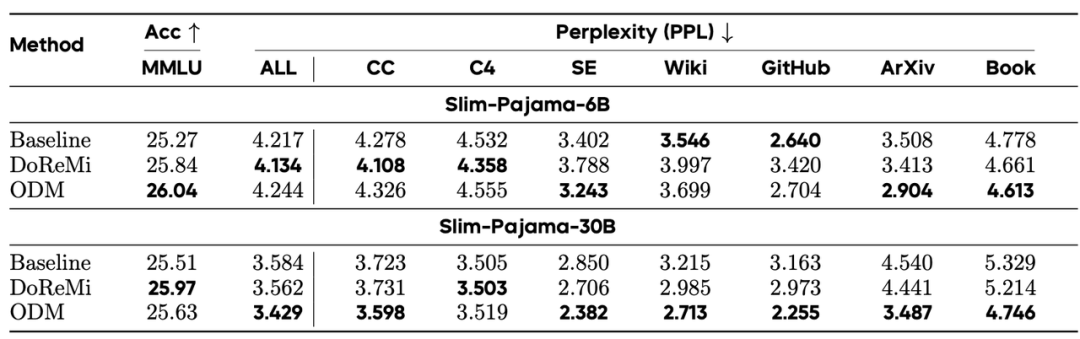
* **领域配比**:在 SlimPajama 数据集上,DoReMi 和 ODM 方法在提升 MMLU 准确率的同时,显著降低了各领域的困惑度(Perplexity)。
- 运行效率:大幅缩短训练耗时 DataFlex 对底层执行流程进行了深度优化:
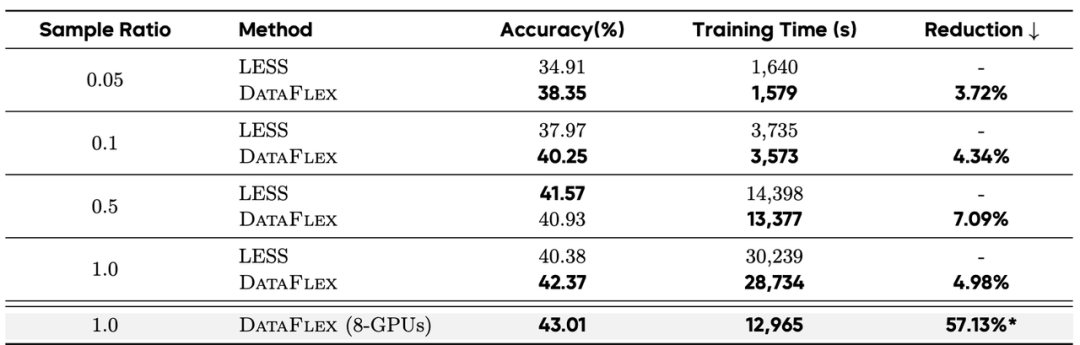
- 在线选择加速:与原始的 LESS 代码库相比,DataFlex 在单 GPU 下可实现约 5% 的耗时缩减。在 8-GPU 并行环境下,DataFlex 能够将原本无法多机运行的任务进行加速,总时长缩短达 57.13%。
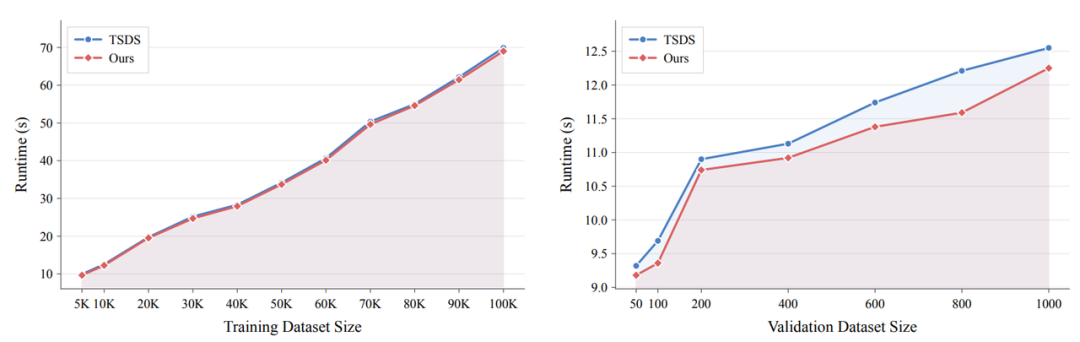
* **离线算子优化**:针对 TSDS 等离线选择算法,DataFlex 重新组织的执行流水线在不同数据规模下均带来了稳定的性能提升。
三、从数据到智能:构建下一代AI的数据底座
当大模型跨越架构探索期,竞争重心已真正转入“数据应用”的深水区。
PKU-DCAI团队致力于在以数据为中心的AI浪潮中,打造下一代AI的数据底座。本次开源的DataFlex,与团队另一核心项目DataFlow一起,共同定义了从数据源头到训练闭环的全新范式。
面对海量而纷杂的真实世界信息,DataFlow专注于构建“高智力密度”的数据提炼流水线。而DataFlex则承接其产出,将数据控制力下沉至模型训练的微观层级——不仅加速收敛,更在系统层面精准调控模型的泛化走向与知识吸收路径,让数据的潜在价值被极致转化为AI的实战能力。
写在最后
DataFlex及其背后代表的“数据调度思维”,让我们看到大模型竞争的下一个赛点:从“模型架构竞赛”转向“数据利用效率竞赛”。当大家用的模型底座逐渐趋同,决定最终性能上限的,可能就是谁能用同一份数据,更高效地训练出更强大的模型。
如果你现在还在为繁重的数据工程感到重复和低效,因前沿算法论文难以复现感到可惜,那DataFlex可能就是你要找的那个解决方案。你不需要从头读几十篇论文,也不需要自己把那些散落的算法代码集成到你的训练流程里。你只需要想清楚你的痛点在哪里,然后去DataFlex的仓库,看看它提供的三种“调度模式”和丰富的策略组件,总有一款可能适合你。
这不是未来的事,这是现在就可以开始的事。
开源只是起点,期待这个能让数据“活”起来的系统,能帮助你更聪明地训练出更强大的模型。如果DataFlex为您的研究或业务带来了启发与实质性的效能提升,期待您在 GitHub 上为仓库点亮一颗宝贵的 Star!
 发表于 2026-4-23 00:59:12
|
查看: 234|
回复: 0
发表于 2026-4-23 00:59:12
|
查看: 234|
回复: 0
