
随着大语言模型的飞速发展,单纯依赖人类反馈来提升模型性能,不仅成本日益高昂,其可扩展性也渐露疲态。尤其当模型在某些领域的表现逼近人类水平时,人类提供的监督信号可能已不足以支撑其向更高层次跃迁。与此同时,模型在自主决策与执行复杂任务方面展现出的惊人潜力,使得将模型开发流程中的诸多环节逐步自动化,从一个美好的愿景变为一种可行的探索。
正是在这种挑战与机遇并存的背景下,“自我改进”这一概念正吸引着学术界越来越多的目光。核心目标很明确:让模型学会自主生成数据、评估自身输出,并以此为基础不断迭代优化自身能力。
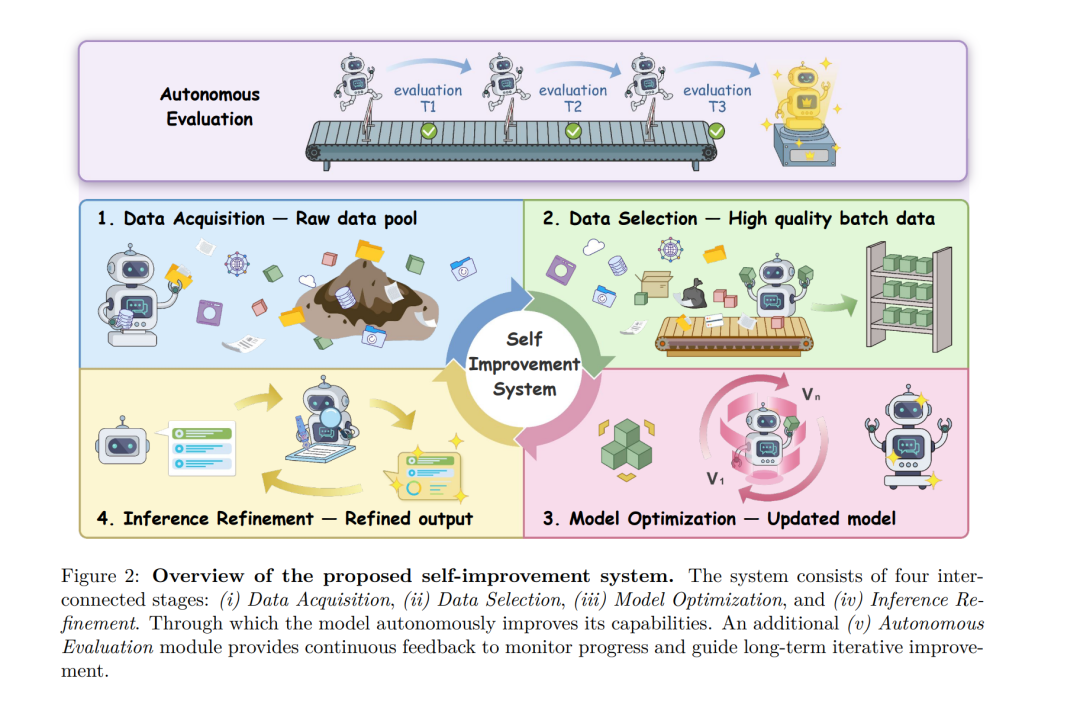
本文试图从一个更为宏观的系统视角来审视具备自我改进能力的语言模型,并尝试整合现有技术,勾勒出一个统一的框架。我们将自我改进系统理解为一个闭环的生命周期,它由四个紧密咬合的核心环节构成:数据获取、数据筛选、模型优化与推理细化。不仅如此,整个系统还由一个独立的“自主评估”层持续监控与引导。在这个框架里,模型自身就是驱动引擎,在各个阶段扮演核心角色:负责收集或生成数据、筛选有效信息、更新自身参数、以及在应用时不断优化输出。自主评估层则像一个永不疲倦的质检员与导航员,为整个系统的持续、稳定进化提供反馈与方向。
基于这一生命周期视角,我们将系统地梳理和分析各个技术组件的代表性方法,探讨当前的局限性,并对通往真正“自我进化”的大语言模型的未来之路进行展望。

引言:为什么需要自我改进?
通过持续扩大模型规模、训练数据量和计算资源,大语言模型的性能实现了令人瞩目的快速提升。长期以来,一个普遍的假设支撑着这一进展:更大规模、更高质量的数据集,特别是经过专家精心标注的人类监督数据,是催生更强模型的关键燃料。在实践中,像基于人类反馈的强化学习这类方法,高度依赖这些昂贵且稀缺的高质量监督信号来对预训练模型进行“对齐”和微调。
然而,随着模型的不断进化,这条严重依赖人类监督的改进路径,逐渐暴露出一些结构性的瓶颈:
- 人类数据的“天花板”:高质量的专家标注数据不仅成本极高,更难以大规模复制。构建庞大监督数据集的边际成本在飞速增长,而人类的专家智慧始终是有限的资源。
- 更深层的“认知边界”困境:如果模型的监督者始终是人类,而人类的智能水平存在上限,那么模型究竟能否真正实现超越?当模型在特定任务上达到甚至超过人类水平时,人类的反馈可能不再能提供足够“信息增量”来推动模型继续进步。这引出了一个根本性问题:当学生(模型)的水平与老师(人类)持平时,它该如何继续学习成长?
上述瓶颈共同将学术界推向了一个极具潜力的新方向:模型自我改进。其核心理念是,让模型不再完全被动地依赖外部的人类信号,而是转而利用自身已经具备的能力,主动生成数据、评估输出,并迭代优化自己的“行为策略”。
从自动化演进的角度看,这不仅是一个理想的方向,更像是一种必然的趋势。随着大语言模型展现出解决复杂工程任务和参与高层决策的能力,我们不禁思考:既然LLM的开发过程(包括数据获取、清洗、模型训练与调优)本身就是一个高度复杂的系统工程,那么将这些职责逐步“委派”给模型自身,不正是一个顺理成章的演进阶段吗?通过将大语言模型视为能够编排自身开发生命周期的智能体,一个“系统侧”的自我改进闭环就有可能建立起来。
如图所示,我们的愿景是实现从“人类驱动”的模型开发范式,向 “自主自我改进系统” 范式的转变。在这个系统中,LLM能够通过自主导向的迭代和内部反馈,不断增强自身的能力。
那么,自我改进具体指什么呢?我们将其定义为:一种无需持续人工干预,模型即可迭代增强自身能力的学习范式。这个范式有两个核心特征:
- 自主性:改进过程不需要持续的人工标注或手动校正。这里的“自我”并不排斥使用外部辅助工具,例如教师模型、验证器、评论家或自动评估器。关键在于,一旦学习循环启动,整个过程必须是完全自动化的。
- 持续性:自我改进不是一次性的微调,而是一个迭代的、自我强化的过程。前一阶段产生的输出或经验,会被重新利用,为后续的更新生成更强、更相关的监督信号。每一轮改进都建立并放大了前一轮的成果,从而实现能力的累积式增长。
在这种定义下,自我改进不仅仅是提升某项任务指标的具体技术,更是一种实现持续、自主成长的结构性能力。从人工智能的长期发展视角来看,这种能力被广泛认为是构建能够超越初始训练范畴、实现终身学习与自适应系统的关键。
受这一愿景启发,我们提出了一个由五个互联组件构成的 “生命周期自我改进系统” 。其中四个组件——数据获取、数据筛选、模型优化和推理细化——共同回答了一个核心问题:为了构建端到端的自我改进系统,我们如何在各个阶段最大限度地利用模型自身来驱动这个过程?具体来说:
- 数据获取:模型自主地从外部收集或内部生成所需的训练数据。
- 数据筛选:模型独立评估并过滤出质量更高、对自身学习更有利的数据。
- 模型优化:模型有效地将筛选后的数据“消化吸收”,转化为其参数内部的能力提升。
- 推理细化:模型在推理(应用)过程中实时提升输出质量,而无需改动其底层参数。
除了这四个核心阶段,系统还需要一个能长期衡量进展、引导方向的机制,以确保自我改进的稳定性和可持续性。为此,我们引入了第五个组件:自主评估。它为模型表现提供持续、及时的反馈,并引导其未来的改进方向。在静态基准测试易过时、人工评估难以规模化的情况下,这种内置的评估机制至关重要。
这五个组件共同将模型置于一个自动化迭代闭环的中心。这一统一框架确保了改进信号能够被一致地生成、筛选、应用、细化和评估,为实现更广泛、更系统的LLM自我改进铺平了道路。
近期已有一些研究从不同侧面探讨了自我改进。例如,有综述关注通过自我训练和强化学习实现的策略进化,也有研究聚焦于提示工程和解码优化等推理侧技术,还有工作强调智能体系统中的记忆、反思和工具使用能力。相比之下,本文采取了更具整合性的系统级视角,将自我改进概念化为一个统一的、闭环的生命周期,旨在将所有开发阶段整合进一个连贯的、支持可扩展自主演化的端到端框架中。
本文后续将首先从技术角度深入剖析自我改进系统的每个核心组件。接着,我们将讨论更宏观的系统级挑战、应用与未来展望。需要说明的是,尽管本文以“模型”为中心进行讨论,但我们也纳入了关于“自我演化智能体”的相关研究。我们认为,从关注单一改进阶段转向构建统一自我改进系统,与从孤立模型转向智能体系统的趋势是相呼应的,共同反映了向更自主、更具交互性的学习系统范式演进的大方向。
对大语言模型自我改进机制的探索,不仅是应对当前数据与标注瓶颈的务实之举,更是迈向更高级别自主人工智能的关键一步。这一领域的研究充满了机遇与挑战,欢迎在云栈社区与更多开发者和研究者一同交流探讨,分享在模型训练与优化过程中的实践经验与前沿思考。
 发表于 2026-4-20 06:05:09
|
查看: 168|
回复: 0
发表于 2026-4-20 06:05:09
|
查看: 168|
回复: 0
