如果你在公司里随机找一个刚入职的 ML 工程师,问他每天打开次数最多的网页是什么,答案大概率有两个:一个是 GitHub,另一个就是 wandb.ai。
Weights & Biases(命令行包名 wandb,社区里直接叫它 W&B 或者“万得币”)这家公司,在过去七年里,把整个机器学习训练流程的工程化做得相当彻底。像是 OpenAI、Meta、NVIDIA、丰田、阿斯利康、Perplexity,还有三星、宝马、西门子——这些团队全把它当成训练大模型时的标配仪表盘。
2025 年 3 月,CoreWeave 用大约 17 亿美元的价格完成了对它的收购。当时正在筹备 IPO 的 wandb,一转头就投入了云厂商的怀抱。这件事的意义我们后面再细说,先把目光拉回到工具本身:它到底解决了什么问题?
从形态上看,它很像几个熟悉的工具合体:
- Git 管着代码版本 → wandb 则管着你的实验版本
- Grafana 盯着服务器指标 → wandb 紧盯的是你的训练指标
- Notion 用于写文档和协作 → wandb 则用来生成和分享实验报告
- Docker Hub 存储镜像 → wandb 用来存数据集和模型权重
这几个功能组合在一起,瞄准了一个非常具体的痛点:你吭哧吭哧训练了一个模型,前前后后跑了 50 次实验。结果等到回头看,完全不记得效果最好的第 23 次实验,学习率究竟设了多少,数据预处理改了啥,当时的代码又是个什么状态。
在 wandb 出现之前,ML 工程师只能靠几样东西硬扛:自己建个 CSV 表格、手写 Markdown 笔记、把终端日志通过 tee 命令重定向到本地文件,再给文件夹按时间戳命名。等实验规模一上来,这套土法三天就得崩溃。
wandb 的思路很朴素——在你的训练代码里添上几行,剩下的脏活累活它全自动接管:
import wandb
wandb.init(project="my-llm", config={"lr": 0.001, "bs": 32})
# 训练循环里
wandb.log({"loss": 0.3, "val_acc": 0.92})
从你敲下这行代码开始,它就会默默启动,自动记录下一切:超参数、训练曲线、GPU 或 CPU 的利用率、当时的 git commit 哈希值、所有依赖库的版本,甚至包括模型在验证集上的输出样本和预测可视化结果。
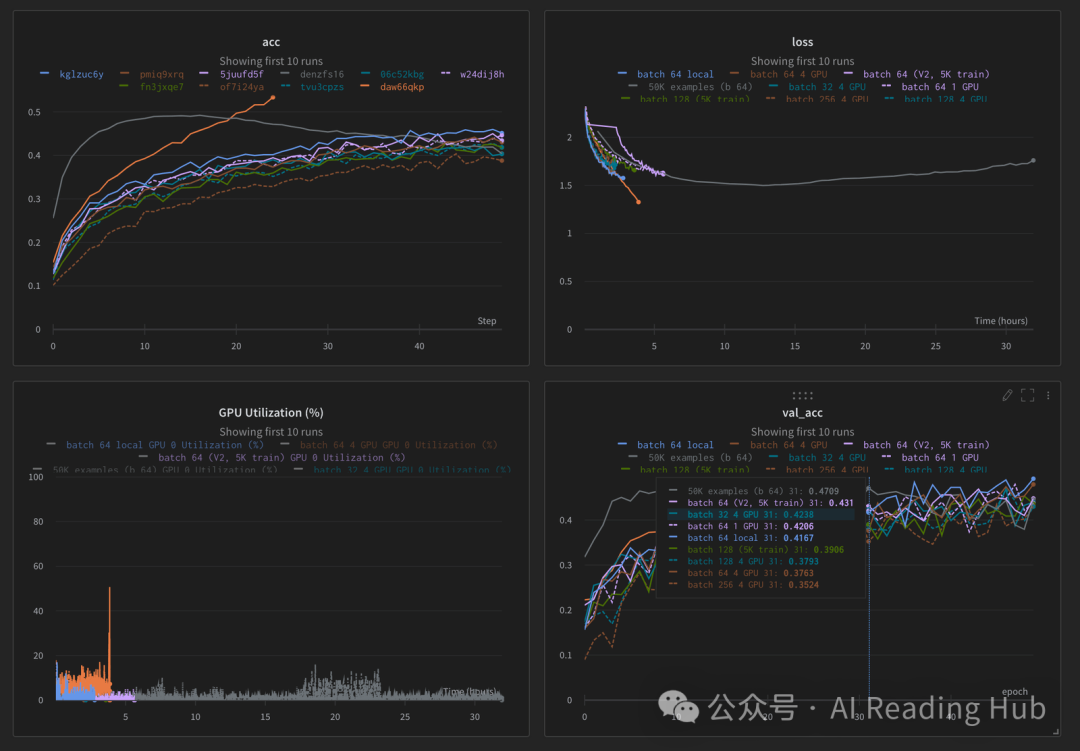
下方就是 wandb 最具代表性的仪表盘(dashboard)界面。多个实验的 loss、accuracy 曲线可以同时叠在一张图里看,谁优谁劣,一目了然。
拆开来看核心模块
wandb 现在的产品矩阵分成了两条线:一条是 Models,主要服务于传统 ML 模型的训练追踪;另一条是 Weave,专门为 LLM 应用量身打造。下面我们按重要性逐个拆解。
1. Experiments:所有人的起点,也是最核心的功能
上面那几行代码开启的就是 Experiments。它的杀手锏不在于“记录”,而在于 横向对比。
当你跑了 100 次超参搜索,可以一键拉出一张并行坐标图。红线代表那些表现拉胯的实验,绿线则是表现亮眼的。你能直观地洞察到某种规律,比如“一旦学习率超过 5e-4,模型效果就开始断崖式下跌”。这种洞察,仅凭浏览一张张 TensorBoard 曲线是永远无法得到的。
同时,它还会把你的机器状态一并采集上来。下图展示的是训练过程中的 GPU 利用率、显存和网络带宽的同步监控。这一部分在 2025 年 6 月 CoreWeave 整合后,功能增强得尤为明显:
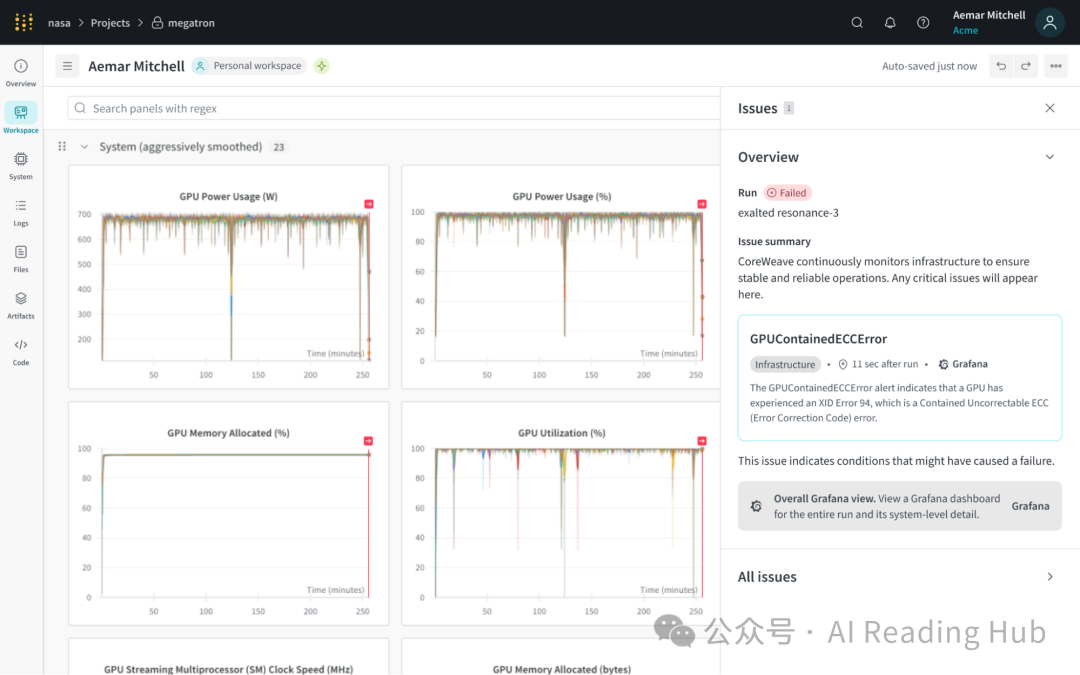
为什么这个监控层如此重要?因为不少情况下,你光盯着模型指标在动、loss 在降,却没注意到底层的 GPU 利用率可能只有 30%。真正的瓶颈也许卡在数据加载的 I/O 上,或者是 PCIe 带宽不足。这类隐藏问题,不通过监控你永远察觉不到,一旦发现并解决,能帮你省下一大笔算力开支。
2. Sweeps:让超参数搜索自动化
过去最折磨人的环节,就是手工写一堆 shell 脚本来调参,像这样:for lr in 0.001 0.0005 0.0001; do ...; done。跑完一组,手动改一组,最后结果散落在十几个不同的文件夹里,对比起来痛不欲生。
Sweeps 模块让你通过一个 YAML 配置文件就搞定这一切:
method: bayes
metric:
name: val_loss
goal: minimize
parameters:
learning_rate:
min: 0.0001
max: 0.01
batch_size:
values: [16, 32, 64]
写好配置后,wandb 就能自己用贝叶斯优化算法,在参数空间中自动挑选下一组要尝试的超参。你可以同时并发启动 10 个 worker 一起跑,所有结果最终都汇到一个面板里。这等于把一次超参调优,从“周末加班手动跑”,变成了“下班前动动手指点一下,第二天早上直接来看结果”。
3. Artifacts:为数据集和模型建立版本档案
你的项目里有没有过这种对话:“上次给老板 demo 用的那版模型权重,到底存在谁的笔记本里了?” Artifacts 就是为了终结这个噩梦而生的。
它能给你的数据集、模型文件、预处理产物全打上版本号,并记录下每一份产物的“血缘”:它来自哪次实验,又被哪些下游实验当作输入。这一层,是从单打独斗的个人脚本,迈向团队协作工程化的关键分水岭。那些跨不过这道坎的 ML 团队,迟早会因为模型版本混乱,酿出一场大事故。
4. Reports:把训练成果变成活生生的网页
Reports 让你能把那些漂亮的曲线图、数据表、分析文字和代码片段直接拼接成一个在线网页。生成一个链接分享出去,团队同事、你的客户、甚至论文审稿人都能直接打开浏览。
它比 PPT 强就强在一点:图表是活的。读者打开后,可以自己随意拖动、缩放、切换不同的实验进行对比。像 Andrej Karpathy、Hugging Face 团队的很多经典技术博客,其背后渲染的底层其实就是 wandb 的 Report。
5. Registry:模型进入生产环境前的最后关卡
Registry 模块把模型的成熟度分成了几个阶段:staging(预发布)、production(生产)、archived(归档)。从谁来审核通过,到谁负责部署上线,再到什么时候需要紧急回滚——整个链路的所有操作都会留下痕迹。这一块主要是给 MLOps 或平台工程团队准备的,一线做模型的工程师可能感触不深,但企业级客户花钱买 wandb,很大一部分原因是为了这一层的合规与审计能力。
6. Weave:押注 LLM 时代的应用追踪新武器
这是 wandb 在 2024 年开始力推的一条新产品线,专为 LLM 应用设计。如果你现在做的是 RAG、Agent 或者 Copilot 这类应用,传统 wandb 关注的 loss 和 accuracy 曲线已经不足以反映你的问题了。你真正想看清的是:用户的每一次提问,在模型内部到底经历了一条怎样的调用链路?
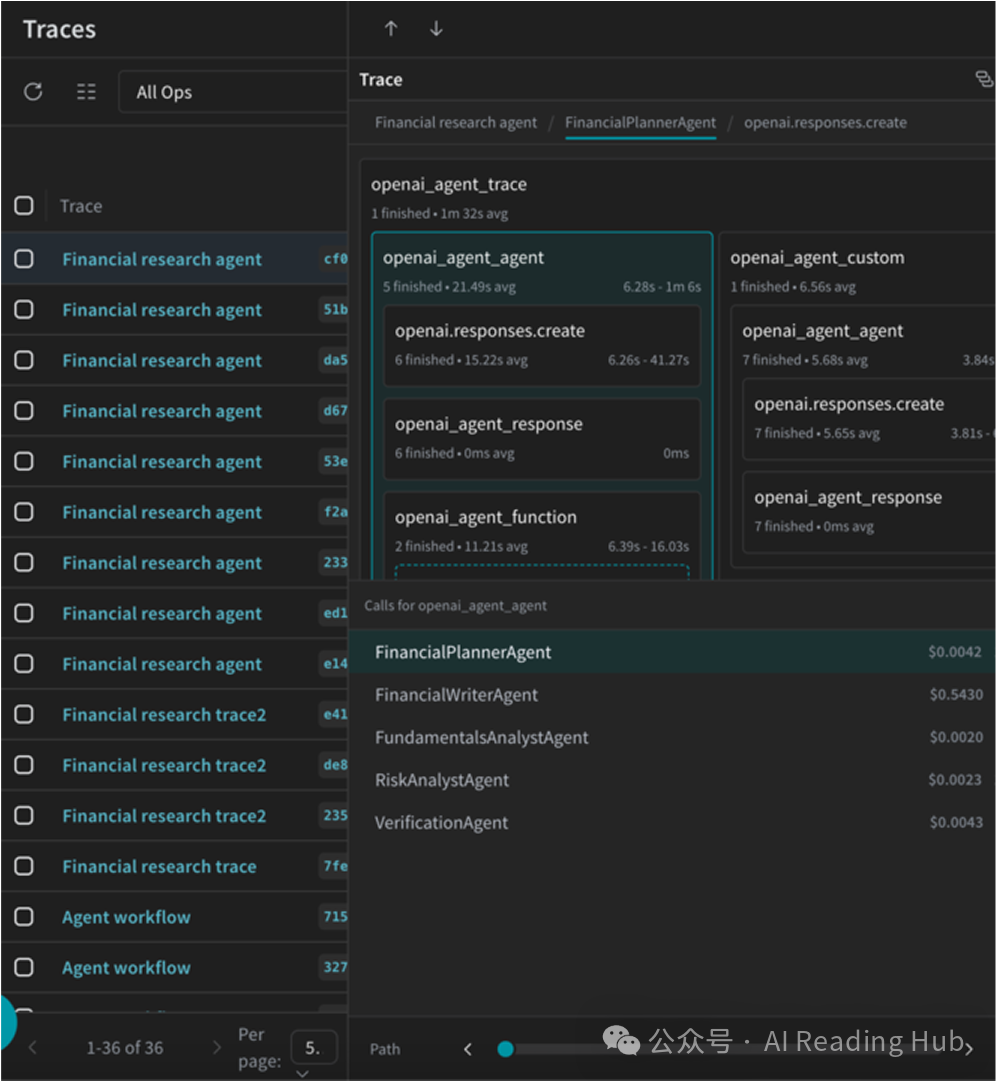
Weave 的做法,是把每一次 LLM 调用变成一棵详尽的 trace 树。在这棵树上,每一个节点都对应一次 prompt 调用、一次工具使用,或者一次模型响应。下图就是个典型的多步 Agent 执行 trace 树:
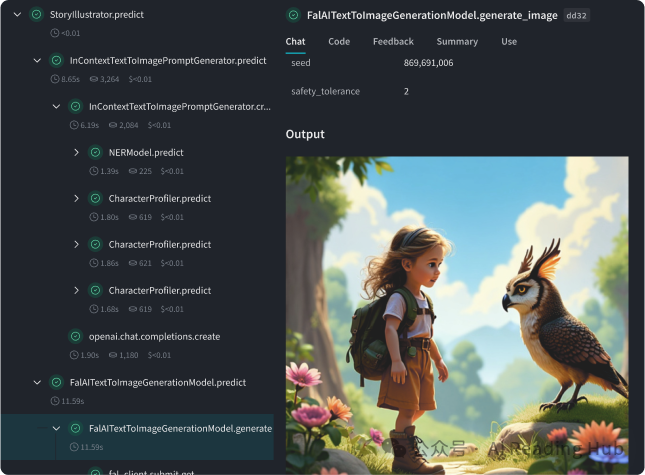
而对于更复杂的 Agent 应用,Weave 提供了专门的 agent rollout 可视化。它能把每一步用了什么工具、消耗了多少 token、走了哪个逻辑分支,都像画迷宫地图一样给你清晰地展示出来:
更进一层,Weave 还内建了在线评估功能。在生产环境中,你可以把每一条真实的用户流量都挂上评估钩子,比如幻觉检测、毒性检测、相关性打分等等,评估结果会直接回传到 Weave 的仪表盘里:
可以说,Weave 这条线,与 LangSmith、Langfuse、Arize Phoenix 是直接竞争对手。具体的对比放在下面的竞品表格里。
横向对比:到底有多少选择?
ML 实验追踪这个赛道并非 wandb 一家独大。我们可以根据功能、价格和自托管难度这三个维度,将主要选项排个队:
| 工具 |
开源 |
自托管 |
免费额度 |
协作能力 |
LLM 追踪 |
适合谁 |
| wandb |
否 (SDK开源, 后端闭源) |
仅企业版支持 |
5GB 存储 + 5 个 seat |
强 |
Weave,强 |
大多数 ML 团队的默认选项 |
| MLflow |
是 (Apache 2.0, Linux Foundation) |
一行 Docker 搞定 |
完全免费 |
弱 |
2024年后补上 |
数据敏感、不想被锁定、自建为先的团队 |
| Neptune.ai |
否 |
企业版支持 |
200GB/月 (最大方) |
中 |
弱 |
看重存储成本、有欧洲合规需求的团队 |
| Comet |
部分开源 |
支持 |
100GB |
中 |
中 |
wandb 的备选方案 (second source) |
| TensorBoard |
是 (Google) |
默认本地 |
本地无限制 |
几乎没有 |
没有 |
单机调试,不需要多人协作 |
| LangSmith |
否 |
企业版支持 |
5k traces/月 |
中 |
这是它的主战场 |
已经深度绑定 LangChain 全家桶的用户 |
| Langfuse |
是 (MIT) |
一行 Docker 搞定 |
50k events/月 |
中 |
这是它的主战场 |
更想自托管 LLM 追踪的团队 |
| Arize Phoenix |
是 |
支持 |
完全免费 |
弱 |
这是它的主战场 |
偏学术研究、希望本地运行的开发者 |
几条选型经验:
- 从零起步的 ML 项目:直接选 wandb。5 分钟就能接入,免费版的额度对个人使用来说绝对足够。
- 企业内有合规/数据出境顾虑:选择 MLflow 自托管。功能上虽说不如 wandb 那么精致,但胜在 100% 的掌控权在自己手里,而且背后有 Linux Foundation 治理,长远来看更放心。
- 只做 LLM 应用,不训练传统模型:优先考虑 Langfuse 自托管或 LangSmith 云服务。相比上 wandb Weave,性价比会更高。
- 大公司的平台团队:常见的做法是 wandb 企业版做主力,搭配 MLflow 兜底,两条腿走路更稳。
TensorBoard 在这场竞赛中,已基本退出了团队协作的舞台,只剩下在单机上快速瞥一眼的场景还在用。
定价:免费档够不够你用?
简单列一下 wandb 当前的定价体系:
- Free:$0/月,提供 5 个seat,5GB 存储,Weave 数据 1GB/月。个人项目、学生作业、打打 Kaggle 比赛,绰绰有余。
- Pro:$60/月起,存储空间升级到 100GB,10 个 seat,超出部分按$0.03/GB 计费。这一定价主要瞄准 50 人以下的早期团队。
- Enterprise:定制报价,涵盖了私有化部署、HIPAA 合规、SSO 单点登录、审计日志等企业级功能。
一个不为人知的小细节:wandb 的存储计费,是按照你上传文件在压缩前的原始大小来计算的。所以,要是你毫无节制地记录大尺寸图片、视频或者 3D 网格模型,5GB 的免费额度可能一周就耗尽了。不过,如果只是记录日常的文本指标和模型权重文件,那能用很久。
为什么 CoreWeave 会愿意花 17 亿买下它?
介绍完工具本身,我们再回过头来审视 2025 年 3 月那笔 17 亿美元的收购,背后的逻辑就清晰多了。
wandb 在 2023 年估值已达 12.5 亿美元,本来准备在 2025 年初以成熟独角兽的身份冲刺 IPO。而 CoreWeave 呢,是一家由 NVIDIA 投资的 GPU 云厂商,靠把 H100/H200 这类顶级算力租给 OpenAI、微软、Meta 等巨头迅速崛起。
但 GPU 云这门生意,有个深层的隐忧:它本质上是一种大宗商品。算力本身很难做出差异化,各家拼到最后,无非是拼单位成本和供应链能力。当 AWS、Google Cloud、Azure 都在卷的时候,CoreWeave 想卖出溢价,就必须向上爬升,进入开发者社区和工具这一层,增加用户粘性。
而 wandb 恰好就是 AI 工程师每天开工必用的入口。控制了入口,就等于控制了“一个模型训练完后,下一步该跑到哪片云上”的决策路径。这一招,和当年微软收购 GitHub 的逻辑几乎如出一辙——开发者在哪写代码,他的工作负载就会自然而然地流向哪片云。
完成收购后,一系列整合动作已经清晰可见:wandb 的训练面板上原生集成了 CoreWeave 的 GPU 实例监控,Weave 也接入了 CoreWeave Sandboxes 来跑并发的 Agent 任务。可以预见,未来“训练结束,一键部署到 CoreWeave”这条链路会越接越深。
对开发者而言,短期看这是好事——产品更新更快,模型训练和监控的能力也更强了。至于长期影响,那是另一个故事:当工具与云强绑定后,未来的迁移成本只会越来越高。这也解释了为什么 MLflow 如今在企业市场反而越卷越凶——因为它提供给企业的,正是一个在任何云上都能跑的对冲选项。
谁应该用 wandb,谁可以再看看?
判断的维度其实就两个核心问题:你是不是需要频繁地对比多个实验?以及,你是不是需要和别人协作?
两个问题的答案都是“是”,那么 wandb 就是当前综合性价比最高的选择,可以说没有之一。
只有第一个是“是”,第二个是“否”(典型的个人或学术单机研究):TensorBoard 搭配几个 CSV 文件就完全够用了,还能省下学一套新工具的时间成本。
只有第二个是“是”,第一个是“否”(团队不训练模型,只用 API 调 LLM 做上层应用):直接上 Langfuse 或 LangSmith 会更合适,用 wandb 未免有些杀鸡用牛刀了。
如果两个答案都是“否”:那你大概率暂时还用不上这一类工具。
最后分享一个有点反直觉的感受:这套工具最大的价值,最终往往会沉淀在个人习惯里——每一次启动训练前,都习惯性地敲下那一行 wandb.init()。这个动作一旦刻进肌肉记忆,几个月后,当你需要回头审视自己半年前的实验时,你一定会感谢当时那个愿意多敲两行代码的自己。
ML 这门手艺在过去十年里,最大的工程化进步就发生在协作这一侧:每个人各写各的 CSV,然后互相对不上的旧时代已经过去了。如今,整个团队在共享的、带有版本管理的实验数据库上进行协作,才是新的默认形态。而 wandb,正是这条进化曲线上,当前打磨得最锋利的那一把刀。
 发表于 2026-6-3 20:15:29
|
查看: 147|
回复: 0
发表于 2026-6-3 20:15:29
|
查看: 147|
回复: 0
